
Softmax详解
Softmax技术分析
在深度学习中,我们经常使用Softmax技术,关于这个技术在学校中我们是从概率学的角度去思考的。最近看见王峰大佬的知乎博文从优化的角度进行了分析,这种思路和我们在数理统计中的方法是一致的!这里我们将基于统计学基础和王峰的博客进行讲解,参考资料见参考文献。
背景介绍
当我们使用一个黑盒子(深度学习模型)预测图片中的物体是什么时,常常预测了它属于每一类对象的概率,这样一个概率向量的和为1,因为我们默认图片一定属于某一类对象。生成这个概率向量的方式一般是使用sigmoid函数,也即Softmax技术。假设输入信息为\(x\),关于黑盒子\(f\left(x\right)\)究竟做了啥,关于对结果的影响我们无从得知,但是\(f\left(x\right)\)在sigmoid函数后做的事情是非常明确的,这些技术都是目的性非常明确的。sigmoid函数激活后的向量是概率向量,所以我们将从事件的角度回顾Softmax的一些本质!
softmax函数、导函数、切线图像
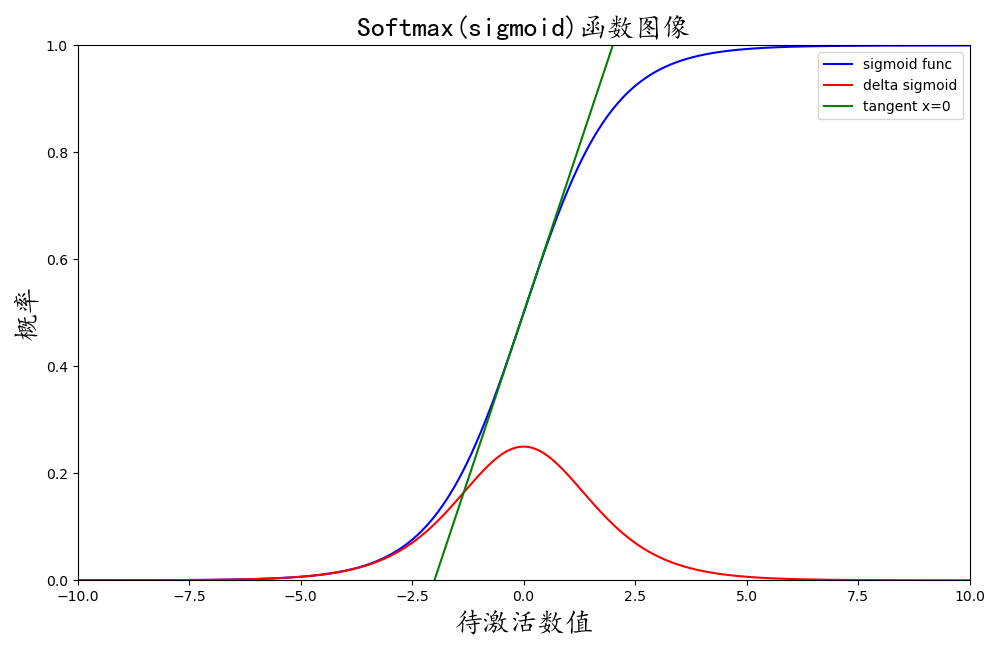
💡 如上图所示:蓝色曲线是Softmax使用的sigmoid函数曲线;红色曲线是sigmoid函数的导函数曲线;绿色直线是在x=0处的切线。sigmoid函数即我们中学生物课本上的生命曲线,这个函数有许多良好的性质,如导函数可以使用sigmoid函数与其与1-sigmoid的乘积表述。
分类问题
\(f\left(x\right)\)的任务就是正确预测\(x\)对应的类别,假如我们令目标事件为:将类别为A的对象预测为类别A,那么\(f\left(x\right)\)实际上就是期望目标事件的概率尽可能大。
直接预测
在统计学中,最开始采用的方法就是简单粗暴直接预测物体的类别编号,即我们要预测一个数值,它的理论取值应该在\(\left\{1,2,\cdots,C\right\}\),其中\(C\)是要预测的类别数。这个方法有一个致命的问题,就是我们的标签是有大小的,有序的。这种性质和实际中的物体之间的关系往往不相符,但是这种标签却人为加入了这样的性质,会导致模型预设了强相关,会增加错判的风险。采用这种方法相当于我们认为\(k\)和\(k+1\)是非常相似的,\(1\)和\(C\)差别很大,也许实际情况恰好相反呢?所以我们自然想到可以独立预测每一类吧!
独立朴素预测
现在我们希望独立预测每一类,所以我们需要预测一个\(C\)维向量,不难想到,每一个元素我们预测为0到1之间的一个数表征属于这一类的概率即可。
假设\(y\)为真实类别的下标,\(z = f\left(x\right) \in \mathbb{R}^{C}\),则优化目标为让目标事件的概率最大:
-
首先,\(z_{y}>z_{i}\quad \forall \, i\neq y\)
-
基于上面的条件,我们可以些为:
\[argmax \, \sum_{i=1,i\neq y}^{C}max(z_{y}-z_{i}, 0) = argmin \, \sum_{i=1,i\neq y}^{C}max(z_{i}-z_{y}, 0) \]
独立后的hinge预测
公式(1)比较简单,虽然计算方便,但是其解也并不好,因为上面的方式\(z_{i}\)刚刚小于\(z_{y}\),优化就停止了(默认沿着梯度反方向优化)。这样的化边界是紧密相连的,很容易在训练数据集上过拟合,即在测试集上预测错误。如同经典的SVM算法,我们希望类间距离要尽可能的大,防止越界。这里我们相应的给每个类别一个固定的间隔\(M\),迫使模型学习到这种性质:
hinge loss函数参考:https://zhuanlan.zhihu.com/p/35708936
LogSumExp平滑max
在传统的SVM二分类任务中,公式(2)被大量使用,确实是取得了良好的效果,但是在如今的多分类时代它就有很多问题了!当类别\(C\)非常大时,大量的非目标类得分会被优化,每次优化时的梯度不等且比较大(训练初期,比较混淆,错误预测的概率会比较大),极易发生梯度爆炸。根据王峰的博客,要解决这个也不难,我们转变思路将与每一类于目标类进行比较换成得分最大的非目标类与目标类进行比较。则优化函数可以写为:
从世俗的角度公式(2)与(3)是一样的,但是这里没有了求和符号,梯度在优化的时候每次最多是\(\pm 1\)进入网络。这样就有效控制了梯度幅度,同时又导致另外一个问题,每一次我们迭代优化的得分实际很少,因为我们只对一类得分进行了修正,影响力是有限的。这样就会导致模型收敛的很慢。下面是王峰的论点:
在优化这个损失函数时,每次最多只会有一个+1的梯度和一个-1的梯度进入网络,梯度幅度得到了限制。但这样修改每次优化的分数过少,会使得网络收敛极其缓慢,这时就又要祭出smooth大法了。那么max函数的smooth版是什么?有同学会脱口而出:softmax!恭喜你答错了...
这里出现了一个经典的歧义,softmax实际上并不是max函数的smooth版,而是one-hot向量(最大值为1,其他为0)的smooth版。其实从输出上来看也很明显,softmax的输出是个向量,而max函数的输出是一个数值,不可能直接用softmax来取代max。max函数真正的smooth版本是LogSumExp函数(LogSumExp - Wikipedia),对此感兴趣的读者还可以看看这个博客:寻求一个光滑的最大值函数 - 科学空间|Scientific Spaces。
如何保证公式(3)的优点同时又不犯同样的错误呢?如上面所说,我们需要对\(\underset{i\neq y}{max}\left \{ z_{i} \right \}\)做出修改,这里是使用max的smooth方案进行优化:
这里我们需要回答两个问题,为什么梯度不爆炸?为什么可以让更多的类得到修正,保证收敛?下面我们来回答这两个问题。
首先,对LogSumExp函数进行求导,对\(\forall j \in \left\{1,2,\cdots,C\right\}\),有偏导为:
这里我们写出每一类的导函数就有:
这个导数向量就不陌生了吧,这不就是Softmax的结果吗?对于问题1,我们的梯度之和为1,所以没有梯度爆炸;对于问题2,每一类都分配了梯度,所以更容易收敛。公式(9)要注意这里关于目标类的倒数为\(-1\)。
LogSumExp一定程度上起到了监督学习间隔M的作用,我们在公式(4)中也显式地添加了M参数,但是在实际中,学者们对上面的结果进行了进一步的smooth。
Softmax交叉熵损失
上面公式(6)非目标类的梯度为1,目标类的梯度为-1,梯度幅度得到了有效的控制。为了获得更好的效果,学者在此基础上进一步进行了smooth。如何在LogSumExp的基础上,模型可以进一步优化?也就是\(z_{y}\)的概率值超过了LogSumExp函数值后仍能够继续优化,关于M我们不再使用这个超参数,而是期望模型自动学习到一个间隔M,因为超参数的调参是比较麻烦的,我们的模型trick本身就有较强的间隔M提取能力,如果再人为添加一个硬性间隔参数M,一方面是调参麻烦,另一方面是这个参数起到的效果可能不大。
这里我们使用softplus函数来进行smooth。原来的softplus函数为:
这里将LogSumExp函数带入指数函数的同时,将\(z_{y}\)也带入,更新后的softmax损失函数为:
注意,对于形如\(max(x,0)\)的函数,我们使用了softplus函数进行平滑,这里的\(x\)即为公式(4)中的${\color{Red} \log\left ( \sum_{i=1,i\neq y}^{C}\exp \left ( z_{i} \right ) \right )-z_{y}} $部分,只是我们删除了人为的硬边界M,那么是否可以加一个M超参数呢?我想理论上是可以的,但是学术界没有这么干,要么是不work;要么是性价比太低!如果你有特殊需求倒是可以加!
公式(8)进一步化简有:
上式(13)就是交叉熵损失的公式,真数部分就是softmax的处理结果,这大家应该很熟悉了,至此就推导处理softmax交叉熵处理公式了。这个公式也是我们在CV中进行分类、bbox回归常用的的损失函数。从2.1的基础概率问题说起,到2.5推导出softmax损失,至此,我们知道AI模型使用softmax+BCE的好处了。
二分类与多分类
传统的统计学习方法,我们要实现多分类,一般是基于二分类进行1 vs 1或1 vs all来暴力查询边界。
使用softmax进行二分类
如果使用softmax进行二分类,则有损失函数为:
这样就可以推导出两类之间每次迭代的梯度都是相反且等幅的。
二分类问题实际上可以等价地看作:是否是类别A的问题,要么是,要么不是。上面的梯度相反、等幅,我觉得是可以理解的。关于王峰的表述:
在SVM时代,因为SVM是一个二分类器,如果我们要进行多分类,就需要使用1 vs 1或者1 vs all的技巧来训练。其中1 vs 1需要寻找两两组合的 \(\frac{C\times (C-1)}{2}\) 个分界面;而1 vs all需要训练\(C\)个分类器,寻找的是某个类别与其他所有类别之间的分界面。具体的情况可以看看这篇博客:支持向量机SVM整理 - CSDN博客 。
神经网络时代用得最多的是Softmax交叉熵损失函数,它是从逻辑回归这个二分类器上演化出来的,具体是如何演化的可以看看这个教程:http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92。注意这里提到了因为Softmax操作是有冗余的,所以在二分类情况下Softmax交叉熵损失等价于逻辑回归。但实际上Softmax是给每个类别都分配了权重向量,而逻辑回归和SVM都是只有一个向量来表示这两个类别之间的分界面。
这里王峰不太认可用其做二分类问题,但是我认为梯度和权值向量(边界)是同的维度,不能因为这个相反、等幅就否定其用于二分类,实际上这种情形两个维度间是等价的!虽然在梯度上是相反等幅的,但是在边界上是只和数据本身、以及\(z_{i}\)的计算有关的,并没有再引入其他不合理限制。
使用softmax用于多分类
使用softmax计算每一类的概率,得到概率向量\(P\),每一个元素取值为:
由公式(15)我们知道有如下的性质:
- 非负性:\(0\leqslant p_{i}\leqslant 1\);
- 正则性:\(\sum_{i=1}^{C}p_{i}=1\)。
而softmax交叉熵损失关于输入\(z\)的导数又是什么?下面先看损失函数的改写:
由(13)可以改写为:
则导函数为:
注:关于这部分求导,也可以参考GHM算法
公式(17)就非常有趣了,我们能发现关于梯度有以下性质:
- 性质1:所有类别的梯度之和为0;
- 性质2:目标类别梯度的绝对值和其他所有类别的梯度之和相等;
- 性质3:目标类别梯度与其他类别的梯度和相反。
由性质2,我们知道此算法梯度是幅度受限的,不容易梯度爆炸;同时由性质1说明了在目标类别与非目标类别间,梯度是均衡的;由性质三也可得到,任意非目标类别在目标类别中找到与之相反的梯度幅度,或者说目标类别的梯度是非目标类别梯度相反数的叠加。
对比二分类中的情况,softmax多分类相当于获得了\(C-1\)个二分类模型。
关于总结,参考王峰的表述:
这与SVM的1 vs 1方式比较类似,区别在于SVM训练的是分界面而不是类别向量,所以SVM需要训练\(\frac{C\times (C-1)}{2}\)个分界面,但Softmax只需要训练\(C\)个类向量即可。这些类别的分界面可以由\(w_{i} - w_{j}\)来求得,仍然可以得到类似的\(\frac{C\times (C-1)}{2}\)个分界面。所以Softmax是比SVM 1 vs 1更省空间也更省计算量的多分类器。最关键的是,Softmax的多个分类器是同时训练的,因此其效率远远超过了需要训练多次的SVM。
另一个区别在于权重的分配,Softmax的各个二分类器之间的权重分配遵循了“较难的二分类器给予较大权重”的原则,其中难易的准则是由当前样本的分类情况来决定的,如果某个非目标分数较高则认为当前样本对于这个类别的区分能力较差,要着重优化这个非目标分数。而且Softmax概率是经过了指数函数的,因此较难的二分类器可以获得远超已经分得比较好的分类器的权重。
总结一下,Softmax交叉熵损失函数在进行多分类时可以理解为是在训练多个二分类器的组合,只不过因为Softmax训练的是类别向量而不是分界面,所以其训练效率得到了很大的提升。Softmax交叉熵损失函数的多条优良的性质以及它在多个二分类器之间的权重分配方式有助于我们设计其他的损失函数,同时也能启发一下多个损失函数之间加权方式的研究,毕竟Softmax看似是多分类,实际上是有着巧妙设计的权重的多个二分类器,那么其他的多损失函数说不定也能利用一下类似的权重分配方式呢?
上面的目标函数是可以简化的,为了说明这种smooth的过程所以采用上面的表示方式,后面在苏剑林的提醒下,王峰又改进了公式,以便于说明smooth的程度控制。这部分也说明了为什么我们要扔掉M参数。
Softmax的smooth程度控制
从公式(3)到公式(13),我们分别使用了LogSumExp对内层的max函数进行了smooth,使用softplus函数对外层的max函数进行了smooth。我们知道数据分布的间隔是有限的,如果模型使用了较大的间隔会导致训练不好,较小的间隔又会导致数据迁移能力差,模型不够鲁棒。这里我们就来看一下,softmax交叉熵损失的缺点。(下面我们引用王峰的案例)

这里大佬默认了就是将one-hot取max,只希望将最大的值无限接近1。注意LSE是在模仿取最大值

放大10倍后,最大的数概率接近1,达到峰哥的目标!也就是说明,在输入值较大时,算法比较理想。

在输入进一步缩小时,max的效果就更差了!
这里的LogSumExp是明显有点smooth过了,所以峰哥在那一部分就没有加M!
所以, \(x\)的幅度既不能过大、也不能过小,过小会导致近对目标函数近似效果不佳的问题;过大则会使类间的间隔趋近于0(\(x\)过大时,间隔的影响会被减弱,相当于数量级衰减),影响泛化性能。如何控制输入到一个合理的范围呢?
程度控制
传统的处理方法是加一个温度项(参考增强学习、知识蒸馏、可靠性等领域),使得损失函数变为:
公式(18)实际上是对输入\(x\)进行了缩放,\(T\)越小,则Softmax越接近one-hot max,即越让概率接近1;\(T\)越大,相当于输入越小,则概率越混淆,近似效果越差。那么是否我们使用较小的\(T\),放大输入就可以解决问题了呢?
实际上,使用一个叫较小的\(T\),是不work的!因为我们添加参数是一个线性变换,前面也是线性变换,相当于把之前的线性变换拆开来了,充分训练之后,输入还是非常小。为了解决这个问题,我们自然想到动态调整温度项,这与可靠性统计中的思路是一致的,即我们使用动态参数!
关于放缩的研究参考:https://arxiv.org/abs/1704.06369 或者 参考中文博士论文:https://happynear.wang/paper/dissertation.pdf 定理3.1。下面我们简单叙述一下,细节可以查看博士论文。
首先论文阐述了两个事实:
- 分类后的结果特征呈现带状放射性分布
- 传统的softmax分类结果是只优化类间,对类内没有限制,使得类内距离大于类间距离(广义的度量)。
MNIST数据集分类结果
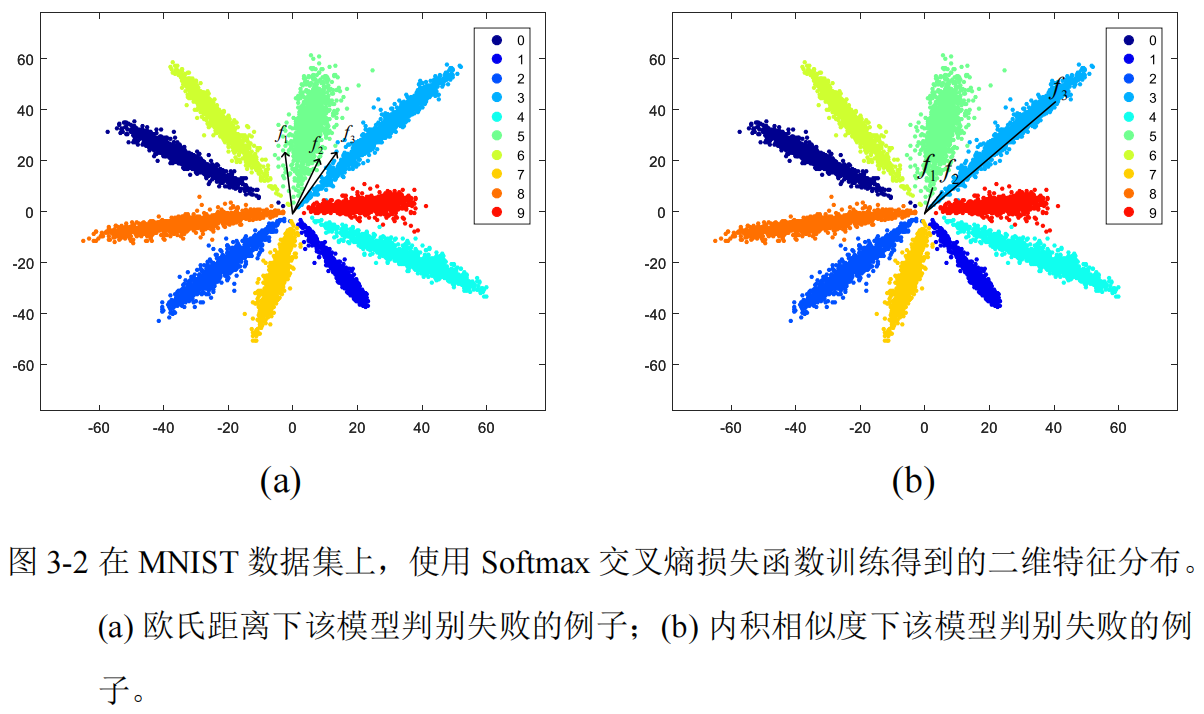
增大目标类的输入可以获得更大的概率
损失函数:
损失函数
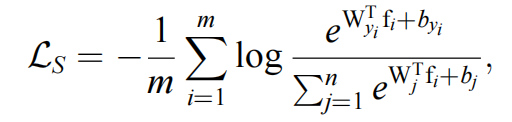
其中,属于每个类别的概率为:
类别概率
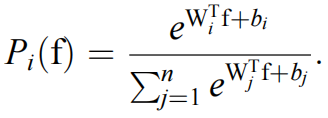
当模型判定类别为\(i\)时,它的输入是最大的:
预测类别有最大的输入

增大预测的数值可以增大预测概率:
增大输入的特征幅度可以增大预测概率

这里我们要注意,命题3.1是在无偏置项\(b_{i}\)下才成立!
归一化输入可以控制类间距离大于类内距离
先看正常分类下第0类的概率分布:
第0类的概率值
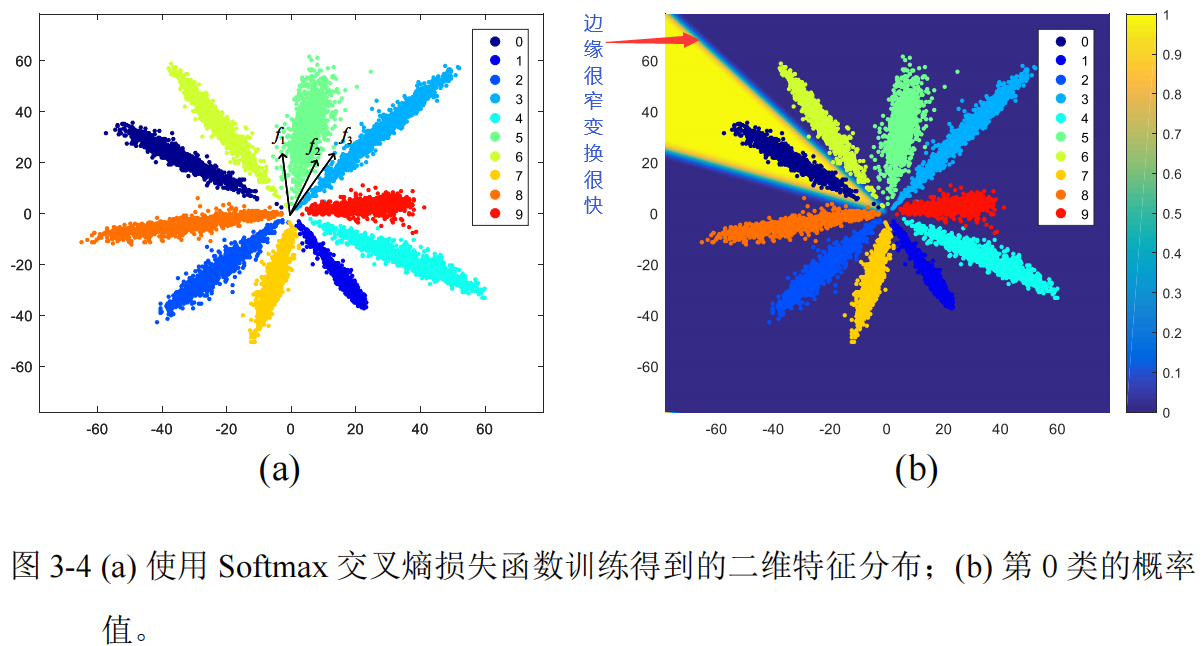
如图所示,黄色标识了属于当前类的概率区域,浅蓝色是边界,深蓝色是非当前类概率区域。我们可以明显看出边界是很窄的,这意味着两个类别之间的间隔比较小,很容易越界!另外:对于目标类别的梯度我们由公式(17)知道,梯度为\(p_{0} - 1\),所有梯度在上面的三个区域中,边界区域取最大值!总之,Softmax 交叉熵损失函数仅仅只负责将各类别分开即可,而不是进一步优化类内方差,这种现象本文称其为 Softmax 交叉熵损失函数的饱和问题。
那么如何约束 Softmax 交叉熵损失函数来进一步收缩类内距离呢?一个比较直观的方法是扩大边界的范围,使得概率在边界处缓慢地增加,这样梯度就不会迅速地降为接近于 0 的数,从而不断地向类中心收缩。
使用2范数对输入进行归一化
防止除数为0的2范数归一化
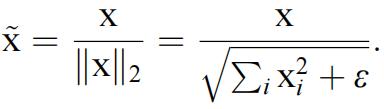
这里的X代表了输入\(x\)或者它的权值\(w\),也即都可以这样归一化!
关于输入特征、权值的偏导数:

通过上式作者还证明了输入与它的梯度是相互垂直的!
内积层的余弦替换

这部分详情参考论文https://happynear.wang/paper/dissertation.pdf
最终的方案为:
余弦Softmax损失函数

这里关于特征、权值幅度的平方\(s\)参数是论文的一个核心!在前面我们已经说明了放大后可以获得更大的目标概率,而\(L_{2}\)归一化会有效限制类内间距实现了平衡!
AMSoftmax
这里就不展开说明了,具体参考王峰的博客:Softmax理解之margin
关于margin自动化配置参考:https://zhuanlan.zhihu.com/p/62229855
