
pytorch每日学习01-----张量量化
torch.quantize_per_tensor(input, scale, zero_point, dtype) → Tensor
torch.quantize_per_channel(input, scales, zero_points, axis, dtype) → Tensor
- 以上两个方法是将将浮点张量转换为具有给定比例和零点的量化张量。
Quantization(量化)介绍
量化是指用于执行计算并以低于浮点精度的位宽存储张量的技术。量化模型对张量使用整数而不是浮点值执行部分或全部运算。这使得可以采用更紧凑的模型表示,并可以在许多硬件平台上使用高性能矢量化操作。与典型的FP32型号相比,PyTorch支持INT8量化,从而可将模型大小减少4倍,并将内存带宽要求减少4倍。与FP32计算相比,对INT8计算的硬件支持通常快2到4倍。
- 量化主要是一种加速推理的技术,并且量化算子仅支持前向操作,只有在进行forward的时候才可以采用量化操作进行加速,在进行backward时不可以进行使用量化操作来进行加速。
PyTorch支持多种量化深度学习模型的方法。在大多数情况下,该模型在FP32中训练,然后将模型转换为INT8。此外,PyTorch还支持量化意识训练,该训练使用伪量化模块对前向和后向传递中的量化误差进行建模。注意,整个计算是在浮点数中进行的。在量化意识训练结束时,PyTorch提供转换功能,将训练后的模型转换为较低的精度。
在较低级别,PyTorch提供了一种表示量化张量并对其执行操作的方法。它们可用于直接构建以较低的精度执行全部或部分计算的模型。提供了更高级别的API,这些API包含了将FP32模型转换为较低精度并减少精度损失的典型工作流程。
-
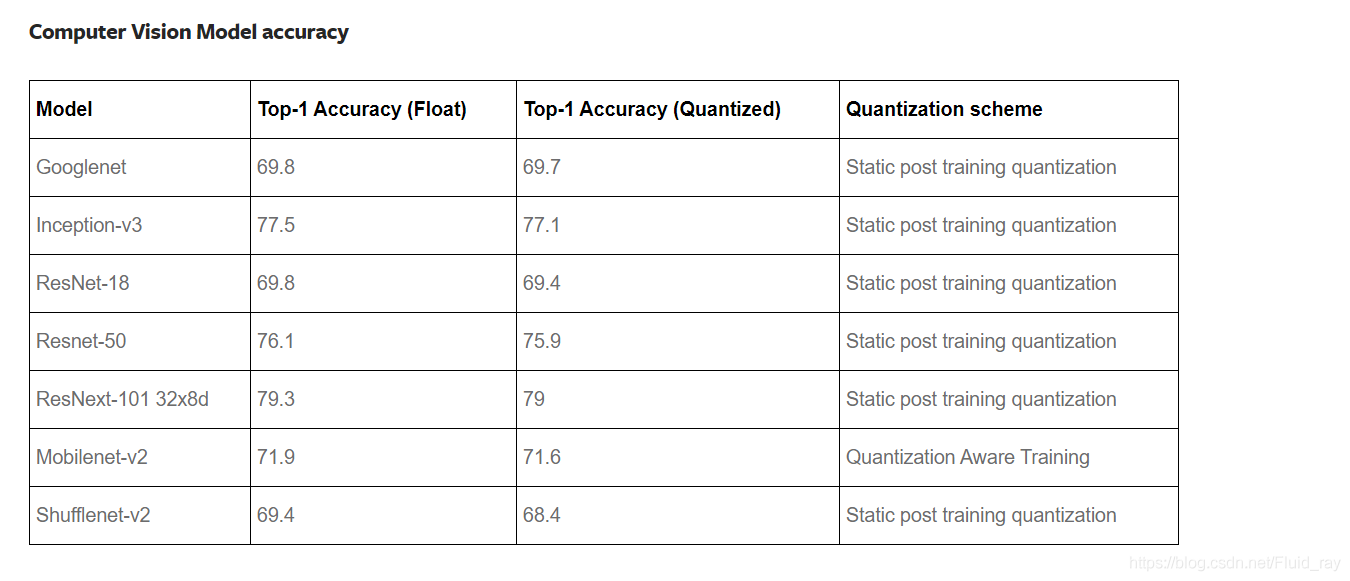
总的来说,量化就是将机器中使用的浮点tensor转化为整数tensor使得计算变得更加的快,也可以减少资源的消耗,而且这种方法不会使准确度下降很多。如下表:

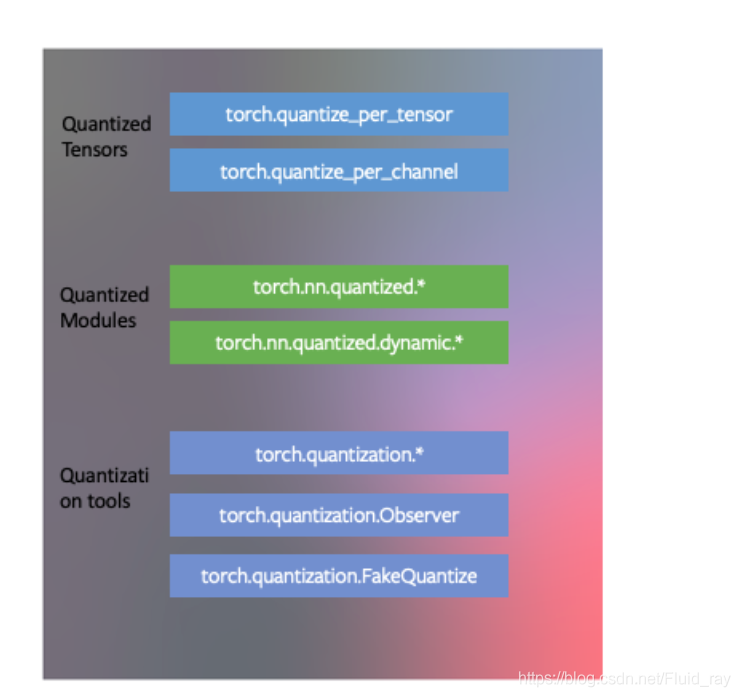
进行量化的方法有以下三个大类(存在于torch.quantization名称空间中),今天讲第一个大类:
开始介绍方法
-
torch.quantize_per_tensor()是按照tensor来进行转化的,每个tensor中所有数据进行一样的操作
-
torch.quantize_per_channel()是对每个channel都有一组对应的缩放和零点,对每个channel进行不同的变化。
-
torch.quantize_per_tensor()官方例子:
>>> torch.quantize_per_tensor(torch.tensor([-1.0, 0.0, 1.0, 2.0]), 0.1, 10, torch.quint8) tensor([-1., 0., 1., 2.], size=(4,), dtype=torch.quint8, quantization_scheme=torch.per_tensor_affine, scale=0.1, zero_point=10) >>> torch.quantize_per_tensor(torch.tensor([-1.0, 0.0, 1.0, 2.0]), 0.1, 10, torch.quint8).int_repr() tensor([ 0, 10, 20, 30], dtype=torch.uint8)
参数介绍
- input:要量化的tensor。
- scale:应用在量化公式的缩放大小。
- zero_point:以整数值表示的偏移量,该值映射为浮点数零。
- dtype:返回张量的所需数据类型。必须是量化的dtypes之一:torch.quint8,torch.qint8,torch.qint32
对张量进行量化的时候使用的如下公式(Q为量化后的张量, x为输入):
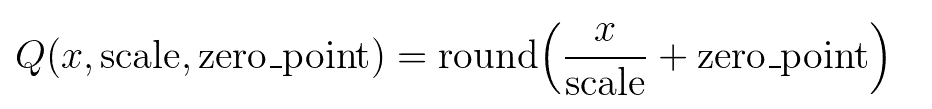
函数映射讲解
-
这个地方很多文章的讲的不是很细致,所以我刚开始只看他们的文章也没有怎么看懂,然后自己动手写了一下又想了一下,才搞懂了是怎么回事,果然还是得动手写啊。
观看如下例子:
-
会发现根本没有什么变化,那么到底进行了这个转化有什么意义?其实是有意义的,我们再看下面的例子:

-
会发现100变成了24.5,而其他的并没有改变。其实我们这里的a中的元素,就拿1来说吧,它缩放过后,也就是\(\frac{1}{0.1} +10=20\) ,但是这里并没有这个结果,我们使用如下方法:

-
发现上面的数经过我们的公式进行缩放以后,确实得到下面这几个数,其实tensor.int_repr()是将给定量化的Tensor(注意只能是量化的tensor),此方法返回以uint8_t作为数据类型的CPU Tensor,该数据类型存储给定Tensor的基础uint8_t值。
-
所以其实我们上面使用torch.quantize_per_tensor()已经进行了操作,它在内部存储中已经是我们想要的形式了,只不过是显示的时候还是按照原来的样子显示而已。
那么到底表示什么意思呢?
-
上面的b中的元素(不是a)表示了离中心点(例子中为10)的距离,注意此距离还要进行缩放,例如b中第二个元素为1,它表示了距离中心点10为10,因为它还要进行除以0.1的缩放操作,这样就能理解为什么存放的还是1。
-
但是a中的100为什么变成了b中的24.5?因为8位无符号数范围为\(0\sim255\),最大为255(即b.int_repr()中最大的值为255),距离中心点(10)最大的距离只能是245,然后还要乘以0.1,所以就是24.5。同理,8位无符号数最小的数是0,所以距离10最远是-10即(b.int_repr()中最小的值是-10),再乘以缩放的话,b中的最小值是-1,如下所示:

-
所以此方法的作用就是存放了表示离中心点的距离(截取最大最小,中间的保留),注意还要进行缩放。
理解了上面那个,那其实torch.quantize_per_channel就很好理解了,对每个channel指定缩放和中心,并且分别进行这样的处理与变化。如下所示:
x = torch.tensor([[-1.0, 0.0], [1.0, 2.0]])
torch.quantize_per_channel(x, torch.tensor([0.1, 0.01]), torch.tensor([10, 0]), 0, torch.quint8)
tensor([[-1., 0.],
[ 1., 2.]], size=(2, 2), dtype=torch.quint8,
quantization_scheme=torch.per_channel_affine,
scale=tensor([0.1000, 0.0100], dtype=torch.float64),
zero_point=tensor([10, 0]), axis=0)
torch.quantize_per_channel(x, torch.tensor([0.1, 0.01]), torch.tensor([10, 0]), 0, torch.quint8).int_repr()
tensor([[ 0, 10],
[100, 200]], dtype=torch.uint8)
参数介绍:
-
input:要量化的tensor。
-
scales:浮点数要使用的一维张量,大小应与input.size(axis)相匹配。
-
zero_points:要使用的偏移量的整数1D张量,大小应与input.size(axis)相匹配。
-
axis:指定在哪个维度使用per-channel量化。
-
dtype:返回张量的所需数据类型。必须是量化的dtypes之一:torch.quint8,torch.qint8,torch.qint32
原文链接:https://blog.csdn.net/Fluid_ray/article/details/109900056
