

leetcode刷题之LRU缓存
LRU Cache
LRU Cache介绍
关于此缓存机制的介绍,参考国外大佬的文章
LRU Cache(Least Recently Used cache)是最流行的缓存驱逐策略之一。同时也是一个非常常见的面试问题。
LRU 策略
LRU Cache会跟踪缓存中的项目的被访问顺序。按照请求顺序存储项目。因此,最近使用的项目将位于缓存的顶部,而最近最少用的项目将位于缓存的尾部。在LRU的策略之中,当缓存已满时,最长时间未使用的项目将被淘汰逐出缓存。
依照上述。LRU缓存的原理、思路其实很简单,如果缓存的容量是n,意味着最近使用的n个或n个以内的项目存储于该缓存中。当缓存占满,每次添加新项目,都会把最末尾的项目删去,再往顶部放入最新项目。
举例
为了更加方便的看出对缓存的数据的储存以及淘汰等操作,举例说明
首先给定容量为3的一个LRU缓存空间,然后依次请求访问也即压入数据A、B、C。我们可以看到缓存的变化。缓存从顶至底放入数据,由于C最后放入,所以位于缓存最顶部。
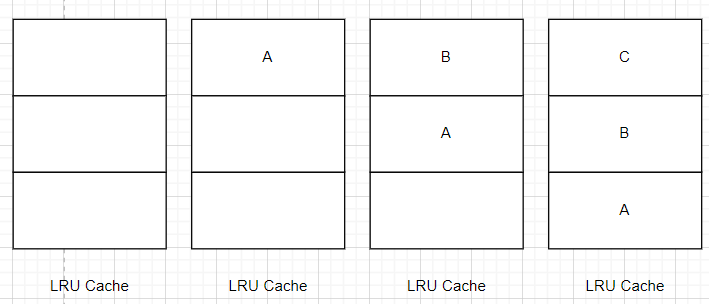
接着,请求访问B,B便会被至于缓存的顶部,表示最近访问
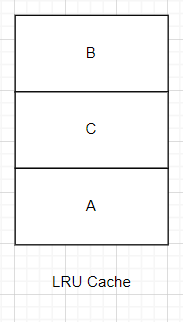
接着是请求访问D,于是缓存就放入了数据D,在放入之前要把最底端的数据移除,即A移除,以此保证LRU容量的恒定。
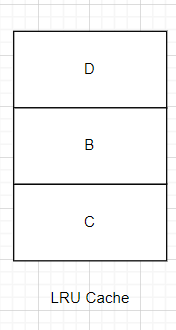
LRU的工作原理上面例子就清楚了,接下来看如何实现
实现LRU Cache
对于LRU缓存的实现,就是leetcode上的这道题。
说一下思路:
题目谈到key-value(关键字和值)的存在,让我们想起了java的hashmap和python的dict
都是以键值对的形式储存
先说hashmap,由于hashmap无法记录访问数据项目访问的前后顺序,这里考虑使用双链表来记录顺序。
用链表不用数组是因为对数据修改的时间复杂度为O(n)
使用hashmap和双链表结合就避免了这个问题。
代码如下:
python就不需要像这样用哈希表和链表结合,python有字典而且是有序字典
用orderedDict()作为LRU缓冲区
利用orderedDict()的特殊方法popitem()可以实现对最前或者最后数据的操作
popitem()的选项last为ture时表示的是栈状态,把刚放入的pop出去;last为false表示的是队列的状态,把最早放入的pop出去
__EOF__
本文链接:https://www.cnblogs.com/damoxilai/p/15784859.html
关于博主:网安小萌新一名,希望从今天开始慢慢提高,一步步走向技术的高峰!
版权声明:达摩西来
声援博主:达摩西来



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!