WebRTC的VAD 过程解读
摘要:
在上一篇的文档中,分析unimrcp中vad算法的诸多弊端,但是有没有一种更好的算法来取代呢。目前有两种方式 1. GMM 2. DNN。
其中鼎鼎大名的WebRTC VAD就是采用了GMM 算法来完成voice active dector。今天笔者重点介绍WebRTC VAD算法。在后面的文章中,
我们在刨析DNN在VAD的中应用。下面的章节中,将介绍WebRTC的检测原理。
原理:
首先呢,我们要了解一下人声和乐器的频谱范围,下图是音频的频谱。
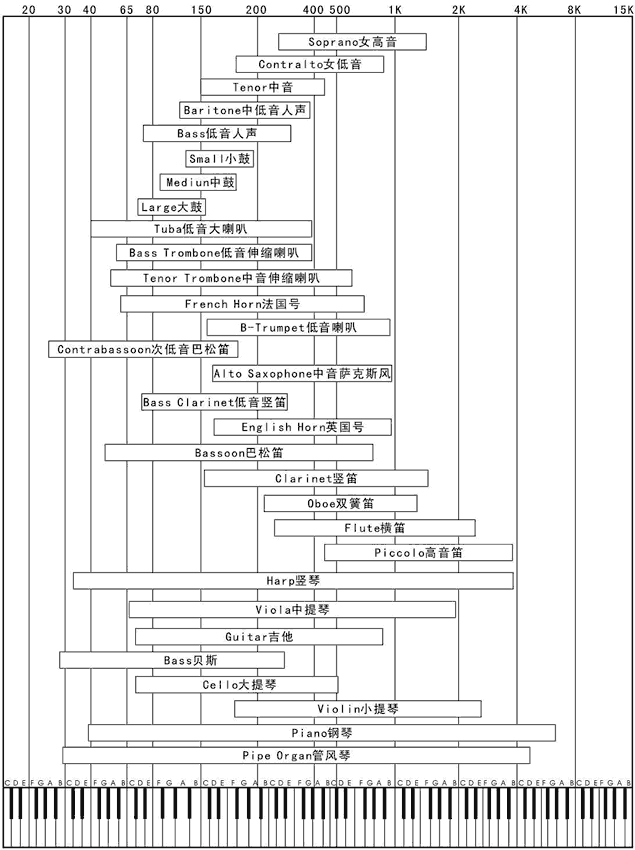
本图来源于网络
根据音频的频谱划分了6个子带,80Hz~250Hz,250Hz~500Hz,500Hz~1K,1K~2K,2K~3K,3K~4K,分别计算出每个子带的特征。
步骤:
1. 准备工作
1.1 WebRTC的检测模式分为了4种:
0: Normal, 1. low Bitrate 2.Aggressive 3. Very Aggressive ,其激进程序与数值大小相关,可以根据实际的使用在初始化的时候可以配置。


// Set aggressiveness mode int WebRtcVad_set_mode_core(VadInstT *self, int mode) { int return_value = 0; switch (mode) { case 0: // Quality mode. memcpy(self->over_hang_max_1, kOverHangMax1Q, sizeof(self->over_hang_max_1)); memcpy(self->over_hang_max_2, kOverHangMax2Q, sizeof(self->over_hang_max_2)); memcpy(self->individual, kLocalThresholdQ, sizeof(self->individual)); memcpy(self->total, kGlobalThresholdQ, sizeof(self->total)); break; case 1: // Low bitrate mode. memcpy(self->over_hang_max_1, kOverHangMax1LBR, sizeof(self->over_hang_max_1)); memcpy(self->over_hang_max_2, kOverHangMax2LBR, sizeof(self->over_hang_max_2)); memcpy(self->individual, kLocalThresholdLBR, sizeof(self->individual)); memcpy(self->total, kGlobalThresholdLBR, sizeof(self->total)); break; case 2: // Aggressive mode. memcpy(self->over_hang_max_1, kOverHangMax1AGG, sizeof(self->over_hang_max_1)); memcpy(self->over_hang_max_2, kOverHangMax2AGG, sizeof(self->over_hang_max_2)); memcpy(self->individual, kLocalThresholdAGG, sizeof(self->individual)); memcpy(self->total, kGlobalThresholdAGG, sizeof(self->total)); break; case 3: // Very aggressive mode. memcpy(self->over_hang_max_1, kOverHangMax1VAG, sizeof(self->over_hang_max_1)); memcpy(self->over_hang_max_2, kOverHangMax2VAG, sizeof(self->over_hang_max_2)); memcpy(self->individual, kLocalThresholdVAG, sizeof(self->individual)); memcpy(self->total, kGlobalThresholdVAG, sizeof(self->total)); break; default: return_value = -1; break; } return return_value; }
1.2 vad 支持三种帧长,80/10ms 160/20ms 240/30ms
采样这三种帧长,是由语音信号的特点决定的,语音信号是短时平稳信号,在10ms-30ms之间被看成平稳信号,高斯马尔可夫等比较信号处理方法基于的前提是信号是平稳的。
1.3 支持频率: 8khz 16khz 32khz 48khz
WebRTC 支持8kHz 16kHz 32kHz 48kHz的音频,但是WebRTC首先都将16kHz 32kHz 48kHz首先降频到8kHz,再进行处理。
1 int16_t speech_nb[240]; // 30 ms in 8 kHz. 2 const size_t kFrameLen10ms = (size_t) (fs / 100); 3 const size_t kFrameLen10ms8khz = 80; 4 size_t num_10ms_frames = frame_length / kFrameLen10ms; 5 int i = 0; 6 for (i = 0; i < num_10ms_frames; i++) { 7 resampleData(audio_frame, fs, kFrameLen10ms, &speech_nb[i * kFrameLen10ms8khz], 8 8000); 9 } 10 size_t new_frame_length = frame_length * 8000 / fs; 11 // Do VAD on an 8 kHz signal 12 vad = WebRtcVad_CalcVad8khz(self, speech_nb, new_frame_length);
2. 通过高斯模型计算子带能量,并且计算静音和语音的概率。
WebRtcVad_CalcVad8khz 函数计算特征量,其特征包括了6个子带的能量。计算后的特征存在feature_vector中。
1 int16_t WebRtcVad_CalculateFeatures(VadInstT *self, const int16_t *data_in, 2 size_t data_length, int16_t *features) { 3 int16_t total_energy = 0; 4 // We expect |data_length| to be 80, 160 or 240 samples, which corresponds to 5 // 10, 20 or 30 ms in 8 kHz. Therefore, the intermediate downsampled data will 6 // have at most 120 samples after the first split and at most 60 samples after 7 // the second split. 8 int16_t hp_120[120], lp_120[120]; 9 int16_t hp_60[60], lp_60[60]; 10 const size_t half_data_length = data_length >> 1; 11 size_t length = half_data_length; // |data_length| / 2, corresponds to 12 // bandwidth = 2000 Hz after downsampling. 13 14 // Initialize variables for the first SplitFilter(). 15 int frequency_band = 0; 16 const int16_t *in_ptr = data_in; // [0 - 4000] Hz. 17 int16_t *hp_out_ptr = hp_120; // [2000 - 4000] Hz. 18 int16_t *lp_out_ptr = lp_120; // [0 - 2000] Hz. 19 20 RTC_DCHECK_LE(data_length, 240); 21 RTC_DCHECK_LT(4, kNumChannels - 1); // Checking maximum |frequency_band|. 22 23 // Split at 2000 Hz and downsample. 24 SplitFilter(in_ptr, data_length, &self->upper_state[frequency_band], 25 &self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); 26 27 // For the upper band (2000 Hz - 4000 Hz) split at 3000 Hz and downsample. 28 frequency_band = 1; 29 in_ptr = hp_120; // [2000 - 4000] Hz. 30 hp_out_ptr = hp_60; // [3000 - 4000] Hz. 31 lp_out_ptr = lp_60; // [2000 - 3000] Hz. 32 SplitFilter(in_ptr, length, &self->upper_state[frequency_band], 33 &self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); 34 35 // Energy in 3000 Hz - 4000 Hz. 36 length >>= 1; // |data_length| / 4 <=> bandwidth = 1000 Hz. 37 38 LogOfEnergy(hp_60, length, kOffsetVector[5], &total_energy, &features[5]); 39 40 // Energy in 2000 Hz - 3000 Hz. 41 LogOfEnergy(lp_60, length, kOffsetVector[4], &total_energy, &features[4]); 42 // For the lower band (0 Hz - 2000 Hz) split at 1000 Hz and downsample. 43 frequency_band = 2; 44 in_ptr = lp_120; // [0 - 2000] Hz. 45 hp_out_ptr = hp_60; // [1000 - 2000] Hz. 46 lp_out_ptr = lp_60; // [0 - 1000] Hz. 47 length = half_data_length; // |data_length| / 2 <=> bandwidth = 2000 Hz. 48 SplitFilter(in_ptr, length, &self->upper_state[frequency_band], 49 &self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); 50 51 // Energy in 1000 Hz - 2000 Hz. 52 length >>= 1; // |data_length| / 4 <=> bandwidth = 1000 Hz. 53 LogOfEnergy(hp_60, length, kOffsetVector[3], &total_energy, &features[3]); 54 55 // For the lower band (0 Hz - 1000 Hz) split at 500 Hz and downsample. 56 frequency_band = 3; 57 in_ptr = lp_60; // [0 - 1000] Hz. 58 hp_out_ptr = hp_120; // [500 - 1000] Hz. 59 lp_out_ptr = lp_120; // [0 - 500] Hz. 60 SplitFilter(in_ptr, length, &self->upper_state[frequency_band], 61 &self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); 62 63 // Energy in 500 Hz - 1000 Hz. 64 length >>= 1; // |data_length| / 8 <=> bandwidth = 500 Hz. 65 LogOfEnergy(hp_120, length, kOffsetVector[2], &total_energy, &features[2]); 66 67 // For the lower band (0 Hz - 500 Hz) split at 250 Hz and downsample. 68 frequency_band = 4; 69 in_ptr = lp_120; // [0 - 500] Hz. 70 hp_out_ptr = hp_60; // [250 - 500] Hz. 71 lp_out_ptr = lp_60; // [0 - 250] Hz. 72 SplitFilter(in_ptr, length, &self->upper_state[frequency_band], 73 &self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); 74 75 // Energy in 250 Hz - 500 Hz. 76 length >>= 1; // |data_length| / 16 <=> bandwidth = 250 Hz. 77 LogOfEnergy(hp_60, length, kOffsetVector[1], &total_energy, &features[1]); 78 79 // Remove 0 Hz - 80 Hz, by high pass filtering the lower band. 80 HighPassFilter(lp_60, length, self->hp_filter_state, hp_120); 81 82 // Energy in 80 Hz - 250 Hz. 83 LogOfEnergy(hp_120, length, kOffsetVector[0], &total_energy, &features[0]); 84 85 return total_energy; 86 }
WebRtcVad_GaussianProbability计算噪音和语音的分布概率,对于每一个特征,求其似然比,计算加权对数似然比。如果6个特征中其中有一个超过了阈值,就认为是语音。
1 int32_t WebRtcVad_GaussianProbability(int16_t input, 2 int16_t mean, 3 int16_t std, 4 int16_t *delta) { 5 int16_t tmp16, inv_std, inv_std2, exp_value = 0; 6 int32_t tmp32; 7 8 // Calculate |inv_std| = 1 / s, in Q10. 9 // 131072 = 1 in Q17, and (|std| >> 1) is for rounding instead of truncation. 10 // Q-domain: Q17 / Q7 = Q10. 11 tmp32 = (int32_t) 131072 + (int32_t) (std >> 1); 12 inv_std = (int16_t) DivW32W16(tmp32, std); 13 14 // Calculate |inv_std2| = 1 / s^2, in Q14. 15 tmp16 = (inv_std >> 2); // Q10 -> Q8. 16 // Q-domain: (Q8 * Q8) >> 2 = Q14. 17 inv_std2 = (int16_t) ((tmp16 * tmp16) >> 2); 18 // TODO(bjornv): Investigate if changing to 19 // inv_std2 = (int16_t)((inv_std * inv_std) >> 6); 20 // gives better accuracy. 21 22 tmp16 = (input << 3); // Q4 -> Q7 23 tmp16 = tmp16 - mean; // Q7 - Q7 = Q7 24 25 // To be used later, when updating noise/speech model. 26 // |delta| = (x - m) / s^2, in Q11. 27 // Q-domain: (Q14 * Q7) >> 10 = Q11. 28 *delta = (int16_t) ((inv_std2 * tmp16) >> 10); 29 30 // Calculate the exponent |tmp32| = (x - m)^2 / (2 * s^2), in Q10. Replacing 31 // division by two with one shift. 32 // Q-domain: (Q11 * Q7) >> 8 = Q10. 33 tmp32 = (*delta * tmp16) >> 9; 34 35 // If the exponent is small enough to give a non-zero probability we calculate 36 // |exp_value| ~= exp(-(x - m)^2 / (2 * s^2)) 37 // ~= exp2(-log2(exp(1)) * |tmp32|). 38 if (tmp32 < kCompVar) { 39 // Calculate |tmp16| = log2(exp(1)) * |tmp32|, in Q10. 40 // Q-domain: (Q12 * Q10) >> 12 = Q10. 41 tmp16 = (int16_t) ((kLog2Exp * tmp32) >> 12); 42 tmp16 = -tmp16; 43 exp_value = (0x0400 | (tmp16 & 0x03FF)); 44 tmp16 ^= 0xFFFF; 45 tmp16 >>= 10; 46 tmp16 += 1; 47 // Get |exp_value| = exp(-|tmp32|) in Q10. 48 exp_value >>= tmp16; 49 } 50 51 // Calculate and return (1 / s) * exp(-(x - m)^2 / (2 * s^2)), in Q20. 52 // Q-domain: Q10 * Q10 = Q20. 53 return inv_std * exp_value; 54 }
3. 最后更新模型方差
3.1 通过WebRtcVad_FindMinimum 求出最小值更新方差,计算噪声加权平均值。
3.2 更新模型参数,噪音模型均值更新、语音模型均值更新、噪声模型方差更新、语音模型方差更新。
1 // Update the model parameters. 2 maxspe = 12800; 3 for (channel = 0; channel < kNumChannels; channel++) { 4 5 // Get minimum value in past which is used for long term correction in Q4. 6 feature_minimum = WebRtcVad_FindMinimum(self, features[channel], channel); 7 8 // Compute the "global" mean, that is the sum of the two means weighted. 9 noise_global_mean = WeightedAverage(&self->noise_means[channel], 0, 10 &kNoiseDataWeights[channel]); 11 tmp1_s16 = (int16_t) (noise_global_mean >> 6); // Q8 12 13 for (k = 0; k < kNumGaussians; k++) { 14 gaussian = channel + k * kNumChannels; 15 16 nmk = self->noise_means[gaussian]; 17 smk = self->speech_means[gaussian]; 18 nsk = self->noise_stds[gaussian]; 19 ssk = self->speech_stds[gaussian]; 20 21 // Update noise mean vector if the frame consists of noise only. 22 nmk2 = nmk; 23 if (!vadflag) { 24 // deltaN = (x-mu)/sigma^2 25 // ngprvec[k] = |noise_probability[k]| / 26 // (|noise_probability[0]| + |noise_probability[1]|) 27 28 // (Q14 * Q11 >> 11) = Q14. 29 delt = (int16_t) ((ngprvec[gaussian] * deltaN[gaussian]) >> 11); 30 // Q7 + (Q14 * Q15 >> 22) = Q7. 31 nmk2 = nmk + (int16_t) ((delt * kNoiseUpdateConst) >> 22); 32 } 33 34 // Long term correction of the noise mean. 35 // Q8 - Q8 = Q8. 36 ndelt = (feature_minimum << 4) - tmp1_s16; 37 // Q7 + (Q8 * Q8) >> 9 = Q7. 38 nmk3 = nmk2 + (int16_t) ((ndelt * kBackEta) >> 9); 39 40 // Control that the noise mean does not drift to much. 41 tmp_s16 = (int16_t) ((k + 5) << 7); 42 if (nmk3 < tmp_s16) { 43 nmk3 = tmp_s16; 44 } 45 tmp_s16 = (int16_t) ((72 + k - channel) << 7); 46 if (nmk3 > tmp_s16) { 47 nmk3 = tmp_s16; 48 } 49 self->noise_means[gaussian] = nmk3; 50 51 if (vadflag) { 52 // Update speech mean vector: 53 // |deltaS| = (x-mu)/sigma^2 54 // sgprvec[k] = |speech_probability[k]| / 55 // (|speech_probability[0]| + |speech_probability[1]|) 56 57 // (Q14 * Q11) >> 11 = Q14. 58 delt = (int16_t) ((sgprvec[gaussian] * deltaS[gaussian]) >> 11); 59 // Q14 * Q15 >> 21 = Q8. 60 tmp_s16 = (int16_t) ((delt * kSpeechUpdateConst) >> 21); 61 // Q7 + (Q8 >> 1) = Q7. With rounding. 62 smk2 = smk + ((tmp_s16 + 1) >> 1); 63 64 // Control that the speech mean does not drift to much. 65 maxmu = maxspe + 640; 66 if (smk2 < kMinimumMean[k]) { 67 smk2 = kMinimumMean[k]; 68 } 69 if (smk2 > maxmu) { 70 smk2 = maxmu; 71 } 72 self->speech_means[gaussian] = smk2; // Q7. 73 74 // (Q7 >> 3) = Q4. With rounding. 75 tmp_s16 = ((smk + 4) >> 3); 76 77 tmp_s16 = features[channel] - tmp_s16; // Q4 78 // (Q11 * Q4 >> 3) = Q12. 79 tmp1_s32 = (deltaS[gaussian] * tmp_s16) >> 3; 80 tmp2_s32 = tmp1_s32 - 4096; 81 tmp_s16 = sgprvec[gaussian] >> 2; 82 // (Q14 >> 2) * Q12 = Q24. 83 tmp1_s32 = tmp_s16 * tmp2_s32; 84 85 tmp2_s32 = tmp1_s32 >> 4; // Q20 86 87 // 0.1 * Q20 / Q7 = Q13. 88 if (tmp2_s32 > 0) { 89 tmp_s16 = (int16_t) DivW32W16(tmp2_s32, ssk * 10); 90 } else { 91 tmp_s16 = (int16_t) DivW32W16(-tmp2_s32, ssk * 10); 92 tmp_s16 = -tmp_s16; 93 } 94 // Divide by 4 giving an update factor of 0.025 (= 0.1 / 4). 95 // Note that division by 4 equals shift by 2, hence, 96 // (Q13 >> 8) = (Q13 >> 6) / 4 = Q7. 97 tmp_s16 += 128; // Rounding. 98 ssk += (tmp_s16 >> 8); 99 if (ssk < kMinStd) { 100 ssk = kMinStd; 101 } 102 self->speech_stds[gaussian] = ssk; 103 } else { 104 // Update GMM variance vectors. 105 // deltaN * (features[channel] - nmk) - 1 106 // Q4 - (Q7 >> 3) = Q4. 107 tmp_s16 = features[channel] - (nmk >> 3); 108 // (Q11 * Q4 >> 3) = Q12. 109 tmp1_s32 = (deltaN[gaussian] * tmp_s16) >> 3; 110 tmp1_s32 -= 4096; 111 112 // (Q14 >> 2) * Q12 = Q24. 113 tmp_s16 = (ngprvec[gaussian] + 2) >> 2; 114 tmp2_s32 = (tmp_s16 * tmp1_s32); 115 // tmp2_s32 = OverflowingMulS16ByS32ToS32(tmp_s16, tmp1_s32); 116 // Q20 * approx 0.001 (2^-10=0.0009766), hence, 117 // (Q24 >> 14) = (Q24 >> 4) / 2^10 = Q20. 118 tmp1_s32 = tmp2_s32 >> 14; 119 120 // Q20 / Q7 = Q13. 121 if (tmp1_s32 > 0) { 122 tmp_s16 = (int16_t) DivW32W16(tmp1_s32, nsk); 123 } else { 124 tmp_s16 = (int16_t) DivW32W16(-tmp1_s32, nsk); 125 tmp_s16 = -tmp_s16; 126 } 127 tmp_s16 += 32; // Rounding 128 nsk += tmp_s16 >> 6; // Q13 >> 6 = Q7. 129 if (nsk < kMinStd) { 130 nsk = kMinStd; 131 } 132 self->noise_stds[gaussian] = nsk; 133 } 134 } 135 136 // Separate models if they are too close. 137 // |noise_global_mean| in Q14 (= Q7 * Q7). 138 noise_global_mean = WeightedAverage(&self->noise_means[channel], 0, 139 &kNoiseDataWeights[channel]); 140 141 // |speech_global_mean| in Q14 (= Q7 * Q7). 142 speech_global_mean = WeightedAverage(&self->speech_means[channel], 0, 143 &kSpeechDataWeights[channel]); 144 145 // |diff| = "global" speech mean - "global" noise mean. 146 // (Q14 >> 9) - (Q14 >> 9) = Q5. 147 diff = (int16_t) (speech_global_mean >> 9) - 148 (int16_t) (noise_global_mean >> 9); 149 if (diff < kMinimumDifference[channel]) { 150 tmp_s16 = kMinimumDifference[channel] - diff; 151 152 // |tmp1_s16| = ~0.8 * (kMinimumDifference - diff) in Q7. 153 // |tmp2_s16| = ~0.2 * (kMinimumDifference - diff) in Q7. 154 tmp1_s16 = (int16_t) ((13 * tmp_s16) >> 2); 155 tmp2_s16 = (int16_t) ((3 * tmp_s16) >> 2); 156 157 // Move Gaussian means for speech model by |tmp1_s16| and update 158 // |speech_global_mean|. Note that |self->speech_means[channel]| is 159 // changed after the call. 160 speech_global_mean = WeightedAverage(&self->speech_means[channel], 161 tmp1_s16, 162 &kSpeechDataWeights[channel]); 163 164 // Move Gaussian means for noise model by -|tmp2_s16| and update 165 noise_global_mean = WeightedAverage(&self->noise_means[channel], 166 -tmp2_s16, 167 &kNoiseDataWeights[channel]); 168 } 169 170 // Control that the speech & noise means do not drift to much. 171 maxspe = kMaximumSpeech[channel]; 172 tmp2_s16 = (int16_t) (speech_global_mean >> 7); 173 if (tmp2_s16 > maxspe) { 174 // Upper limit of speech model. 175 tmp2_s16 -= maxspe; 176 177 for (k = 0; k < kNumGaussians; k++) { 178 self->speech_means[channel + k * kNumChannels] -= tmp2_s16; 179 } 180 } 181 182 tmp2_s16 = (int16_t) (noise_global_mean >> 7); 183 if (tmp2_s16 > kMaximumNoise[channel]) { 184 tmp2_s16 -= kMaximumNoise[channel]; 185 186 for (k = 0; k < kNumGaussians; k++) { 187 self->noise_means[channel + k * kNumChannels] -= tmp2_s16; 188 } 189 } 190 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号