

python模块主要分为以下三类:
系统内置模块
(开源)三方模块
自定义模块
⚠️ 自定义模块的命名不能和系统内置的模块重名,否则不能导入系统内置模块
一 数学相关模块
| math模块 |
decimal模块
|
random模块
|
secrets模块
|
|
| 应用场景 | 和计算相关 |
Decimal可以避免浮点型计算结果丢失精度的问题 |
伪随机数模块,并非真正的随机 |
希望得到更加安全的随机数。python3.6版本以后,secrets模块用于生成高度加密的随机数,适于管理密码、账户验证、安全凭据及机密数据。 |
| 常见方法 |
ceil(x) 对数值x进行向上取整 floor(x) 对数值x进行向下取整 |
from decimal import getcontext, Decimal |
random() 产生一个[0.0, 1.0) 范围内的随机浮点数 randint(a, b) 产生指定范围[a,b]内的随机整数 choice(seq) 从序列seq中随机抽取一个成员 choices(seq, k) 从序列seq中随机抽取k个成员,以列表格式返回结果 shuffle() 打乱列表中成员的排列循序 sample(s, k) 打乱一个不可变序列并随机提取k个成员返回新列表
|
import secrets, string |
| 实例 |
"""ceil 向上取整""" # 如果小数位精度太小,会出现精度丢失问题
|
from decimal import getcontext, Decimal """如果要float浮点类型与decimal类型进行计算,则必须统一类型""" |
import random |
import secrets, string """生成安全Token(令牌),适用于密码重置、密保 URL 等应用场景""" |
二 时间日期模块
| 时间模块time | 日期时间模块datetime | 日历模块calendar | |
| 应用场景 | 转化日期格式 |
datatime模块是python内置的加强版time模块,提供更多关于日期(date)、时间(time)、日期时间(datetime)、时间差(timedelta)、时区信息(timezone)等操作 | 关于年月周几的操作 |
| 常见方法 |
time() 获取本地时间戳,精度在微秒级别 sleep(seconds) 程序睡眠等待指定秒数(seconds=秒) perf_counter() 性能计数器,用于计算程序运行的总秒数,从代码第一行开始从0计时。 process_time() 性能计算器,用于计算程序运行当前进程时的总秒数,不计算time.sleep()耗时。 timezone 获取当前时区与中时区的时间差。东加西减
|
datetime 日期时间对象,常用的属性有hour, minute, second, microsecond timedelta 时间差,即两个时间点之间的距离或长度
|
monthcalendar(year, month) 按指定年月返回列表格式的日历信息,左起周一 |
| 常用操作 |
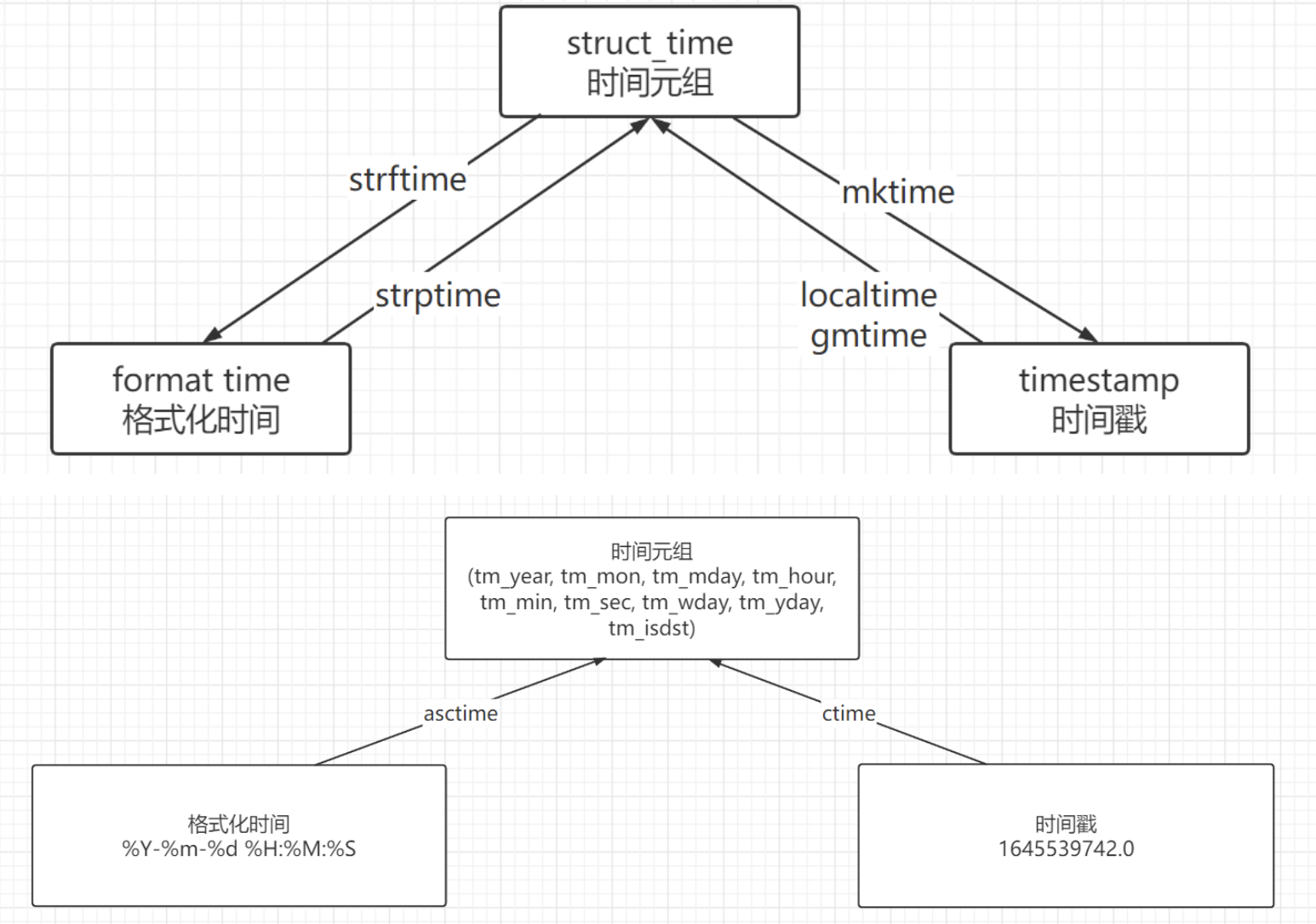
import time """时间元祖->时间戳""" |
now(tz=None)获取当前本地系统时间的datetime对象,可指定时区 YYYY-mm-dd HH:MM:SS.ffffff fromtimestamp(t, tz=None) 通过时间戳t获取datetime对象,可指定时区 YYYY-mm-dd HH:MM:SS strptime(date_string, format) 对字符串date_string按format格式化字符串转成datetime对象 YYYY-mm-dd HH:MM:SS strftime(fmt) 对datetime对象根据fmt格式化转成字符串 YYYY-mm-dd HH:MM:SS from datetime import datetime from datetime import timedelta |
"""获取指定年月的信息列表 (年份,月份) 左起周一""" |
附:
三 数据转换模块
在数据存储和读取过程中,一般需要数据转换,因为不管网络传输也好,还是保存数据到文件也罢,都只支持保存字符串或者二进制bytes类型数据,因此很多时候,针对python中如列表,元组,字典等数据类型,我们都需要进行格式转换。
# 序列化 把不可直接存储的数据格式变成可存储数据格式,这个过程就是序列化过程。例如:字典/列表/对象等 => 字符串。 # 反序列化 把可存储数据格式进行格式还原,这个过程就是反序列化过程。例如:字符串还原成字典/列表/对象等。
| json模块 | pickle模块 | |
| 说明 |
是一种轻量级的数据交换格式,易于人阅读和编写,常用于不同平台,不同编程语言之间进行数据传输,也常用于对编程开发过程中的数据存储结构或项目配置文件。 注意:在python中默认就是符合json语法的字符串数据。json提供了json字符串与其他数据格式之间的序列化和反序列化操作 |
pickle类型处理数据后的数据是二进制的,所以对于数据相对于json格式而言,更加紧凑(避免json空行占空间),性能更好。 |
| 语法 | 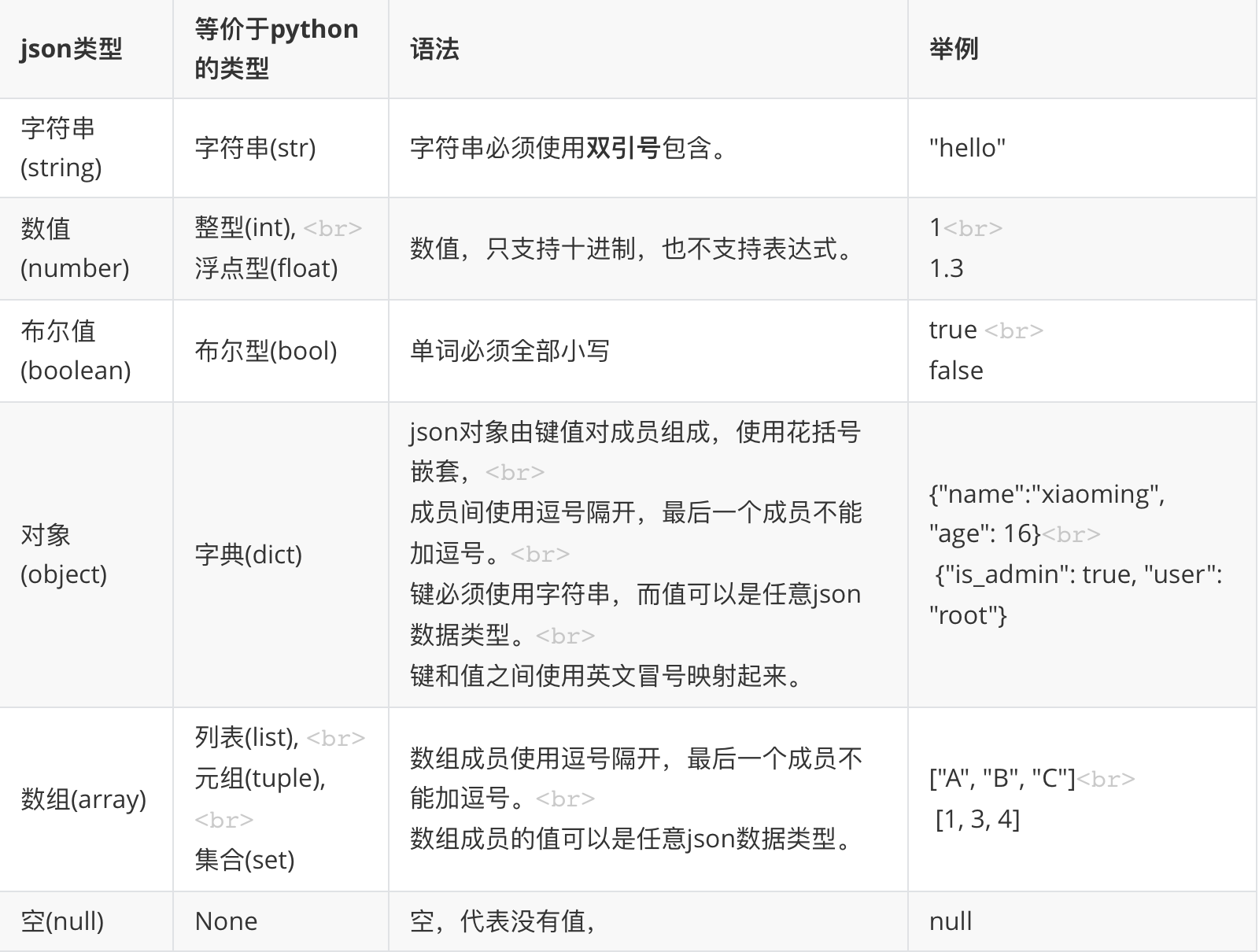 |
|
| 常用操作 | 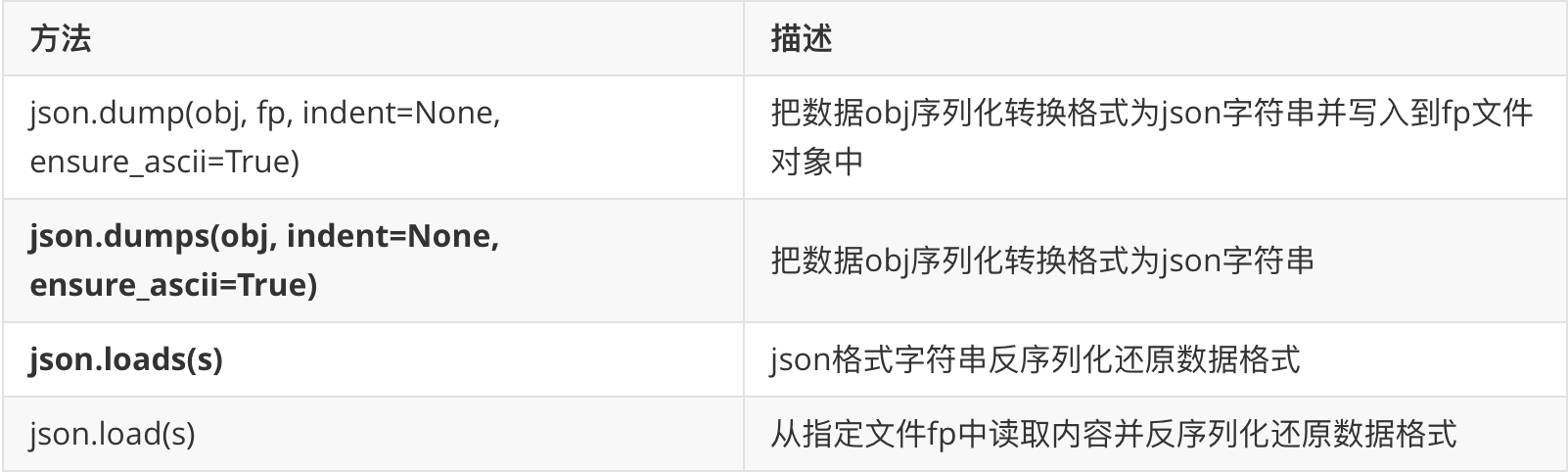 |
 |
| 实例 |
import json """从指定文件中读取json数据并反序列化""" |
import pickle |
| 对比 |
1. json模块常用于将Python数据转换为通用的json格式传递给其它系统或客户端,常见于web开发,测试开发,运维开发。 3. 都是内置模块,所以都有更优的替代方案。 |
|
四 安全加密模块
哈希函数:哈希的本质,就是把任意长度的输入内容,通过Hash算法变成不可逆的固定长度的输出内容(哈希值,散列值,消息摘要),输出内容通常用16进制的字符串表示。哈希的过程是单向的,只有加密,没有解密。因此你可以把字符串进行哈希获取哈希值,但无法从哈希值逆转获取原始字符串。
哈希碰撞/冲突:两个不同的数据经过Hash函数计算得到的Hash值一样。哈希碰撞无法被完全避免。只能采用各种方法来尽量避免,降低发生的概率。
| hashlib模块 | hmac模块 | |
| 说明 | 哈希碰撞无法被完全避免。只能采用各种方法来尽量避免,降低发生的概率。python里面提供了内置函数hash()。 | 黑客可以通过彩虹表(一种密码破解的工具)根据哈希值反推原始登陆密码,那么用户在服务器中的数据就变得不安全。所以,需要使用hmac等安全级别更高的加密模块。hmac是一种基于Hash函数和密钥进行消息认证的方法,使用hmac函数比标准hash函数更安全,只要改动秘钥(盐值),同样的数据,也会产生不同的哈希值。 |
| 实例 |
import hashlib """sha1加密..""" |
"""hmac 基于hash算法与密钥的加密技术""" |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现