

一. 数值常用操作
python常用关于数值,数学常用的模块:math(数学),random(随机),numpy(科学计数),pandas(数据读写,数据分析)
| 函数 | 描述 | 实例 |
| int(x) | 将x转化为整数 |
# num0 = 3.999999999 |
| float(x) | 将x转化为浮点数 |
# s2 = "3.5" |
| math.ceil(x) | 对数字x向上取整 |
# import math |
| math.floor(x) | 对数字x向下取整 |
# import math |
| round(x [,n]) | 返回浮点数 x 的四舍五入值,如给出 n 值,则代表保留小数点后的位数 |
# num0 = 3.1 |
| random.randint(x,y) | 随机生成一个[x,y]范围的整数 |
# import random # data = random.randint(1,100) |
| random.shuffle(list) | 将序列的所有元素随机排序 |
# import random # data = ["A", "B", "C"] !统计需要返回值,修改不需要 |
| abs(x) | 求数字x的绝对值 |
# num1 = -10 |
| max(a, b, c,...) | 求指定参数的最大值 |
# ret = max(10, 12, 15, 20) |
| min(a, b, c,...) | 求指定参数等最小值 |
# ret = min(10, 12, 15, 20) |
| math.modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示 |
# import math |
| pow(x, y) | x的y次幂运算后的结果,等价于x**y | # print(pow(2,3)) # 8 相当于2**3次方 |
| math.sqrt(x) | 求数字x的平方根 |
# import math |
| random.choice(seq) | 从序列中随机挑选一个成员 |
# data = ["A", "B", "C"] |
| random.random() | 随机生成一个[0,1)范围的实数 |
import random # 生成一个0~1之间的随机实数 [0,1) 不包含1 # data = random.random() |
二. 字符串常用操作
常见的:string字符串本身操作,re模块(RegExp正则),xpath,bs4
| 方法 | 描述 | 实例 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
# s1 = "hello world" |
| string.encode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
# s1 = "中文" |
| string.decode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
# s2 = b'\xa4\xa4\xa4\xe5' |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查 |
# name = "王晓明" |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False |
# name = "王晓明" |
| string.find(str, beg=0, end=len(string)) | 获取字符子串在字符串的下标位置,找不到结果为-1,找到则返回首次出现的下标位置,从0开始[不报错!] |
# name = "王晓明" |
| string.index(str, beg=0, end=len(string)) | 获取字符子串在字符串的下标位置,找不到则报错,找到则返回首次出现的下标位置,从0开始[报错!] |
# name = "王晓明"
|
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
# data = ["北京市", "昌平区", "白沙路"] |
| string.split(str="", num=string.count(str)) |
# s1 = "北京市-昌平区-白沙路" |
|
| string.splitlines([keepends] | 按照行('\r', '\r\n', '\n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。按行分割 |
content = """君不见黄河之水天上来, >>> 君不见黄河之水天上来, |
| string.lower() | 转换 string 中所有大写字符为小写. |
# s1 = "GET" |
| string.upper() | 转换 string 中的小写字母为大写 |
# s1 = "get" |
| string.strip() | 删除 string 字符串两边连续的空格. | |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
s1 = "python37 python37" |
| string.capitalize() | 把字符串的第一个字符大写 |
# s1 = "10hello world" |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
# # s1 = "12352.334" # 这种也为False |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
num = input("请输入数字") if num.isdigit(): pass |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False | # s1 = "" # 空字符串,False # ret = s1.isspace() # print(ret) |
| string.title() | 返回"标题化"的 string,就是把字符串那种所有单词的首字母转换成大写 |
# s1 = "get go" |
| string.lstrip() | 删除 string 字符串左边开头的空格 |
# s2 = " hello wolrd " |
| string.rstrip() | 删除 string 字符串右边末尾的空格. |
# s2 = " hello wolrd " |
| max(str) |
str1 = "ABC" |
|
| min(str) |
str1 = "ABC" |
注:

name = "张三" age = 16 print("%s今年%d了" % (name, age)) "{} {}".format("hello", "world") # # 不设置指定位置,按默认顺序 "{0} {1}".format("hello", "world") # 设置指定位置 "{1} {0} {1}".format("hello", "world") # 设置指定位置 "姓名:{name}, 性别:{sex}".format(name="小明", sex="男") # 指定变量 "姓名:{name}, 性别:{sex}".format(**{"name": "小明", "sex": "男"}) # 星星打散字典进行key指定值 "姓名:{0[0]}, 性别:{0[1]}".format(['",', '男']) # 基于列表索引指定参数,"0" 是必须的 "{:.2f}".format(3.1415926) # 浮点数格式化 "{:.2%}".format(0.14) # 百分比格式化 "{} 对应的位置是 {{0}}".format("小明")
f字符串【常用!!】:也叫字面量格式化字符串,是python3.6版本以后推出的格式化方式。
以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,python会将变量或表达式计算后的值替换到字符串中。
name = "小名" print(f"我叫{name}") # 我叫小名 # 输出复核类型数据,直接在{}里面写上中括号即可 data = {"name": "小明", "sex": "男"} print(f"姓名:{data['name']}, 性别:{data['sex']}") # 姓名:小明, 性别:男 x = 1 y = 0.14 print(f"{x:.2f} {y:.2%}") # 1.00 14.00% # python3.8以后,新增了一个表达式结果输出的省略写法 x = 10 y = 20 print(f"{x+y}") # 30 print(f"{x+y=}") # x+y=30 # 整数补0 x = 8 print(f"{x:02d}") # 01
三. 列表常用操作
| 函数 | 描述 | 实例 |
| len(list) | 列表元素个数 |
# data = [1,2,3] |
| max(list) | 返回列表元素最大值 |
# data = [11,2,13] |
| min(list) | 返回列表元素最小值 |
# ret = min(data) |
| list(seq) | 将元组、集合、转换为列表 |
#ret = "hi" #list(ret). #['h', 'i'] |
| 方法 | 描述 | 实例 |
| list.insert(index, obj) | 将对象插入列表中指定下标位置,插入以后,原下标对应的成员往后排序 |
# data = ["A", "B", "C"] |
| list.append(obj) | 在列表末尾追加成员 |
# data = ["A", "B", "C"] |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
# data = [11,2,13] |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值。合并列表,把第二个列表的成员合并到第一个列表 |
# data = ["A", "B", "C"] |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
# data = ["A", "B", "C"] # ret = data.index("A")
|
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
# data = ["A", "B", "C", "D"] |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
# data = ["A", "B", "C", "D"] |
| list.reverse() | 反转排列列表中元素 |
# data = [1,2,3] |
| list.sort( key=None, reverse=False) |
对原列表进行排序 基于大小于号进行先后排序的,所以列表中存在不同类型数据时。会报错 |
|
| list.copy() | 复制列表 |
# data1 = ["A", "B"] |
| list.clear() | 清空列表 |
# data = ["A", "B"] |
注:
浅拷贝和深拷贝
定义:是编程语言中针对引用类型数据提供的一种表层/深层复制数据的功能。
示例:
二层以上列表,字典和集合存在引用赋值问题。以二层以上列表为例
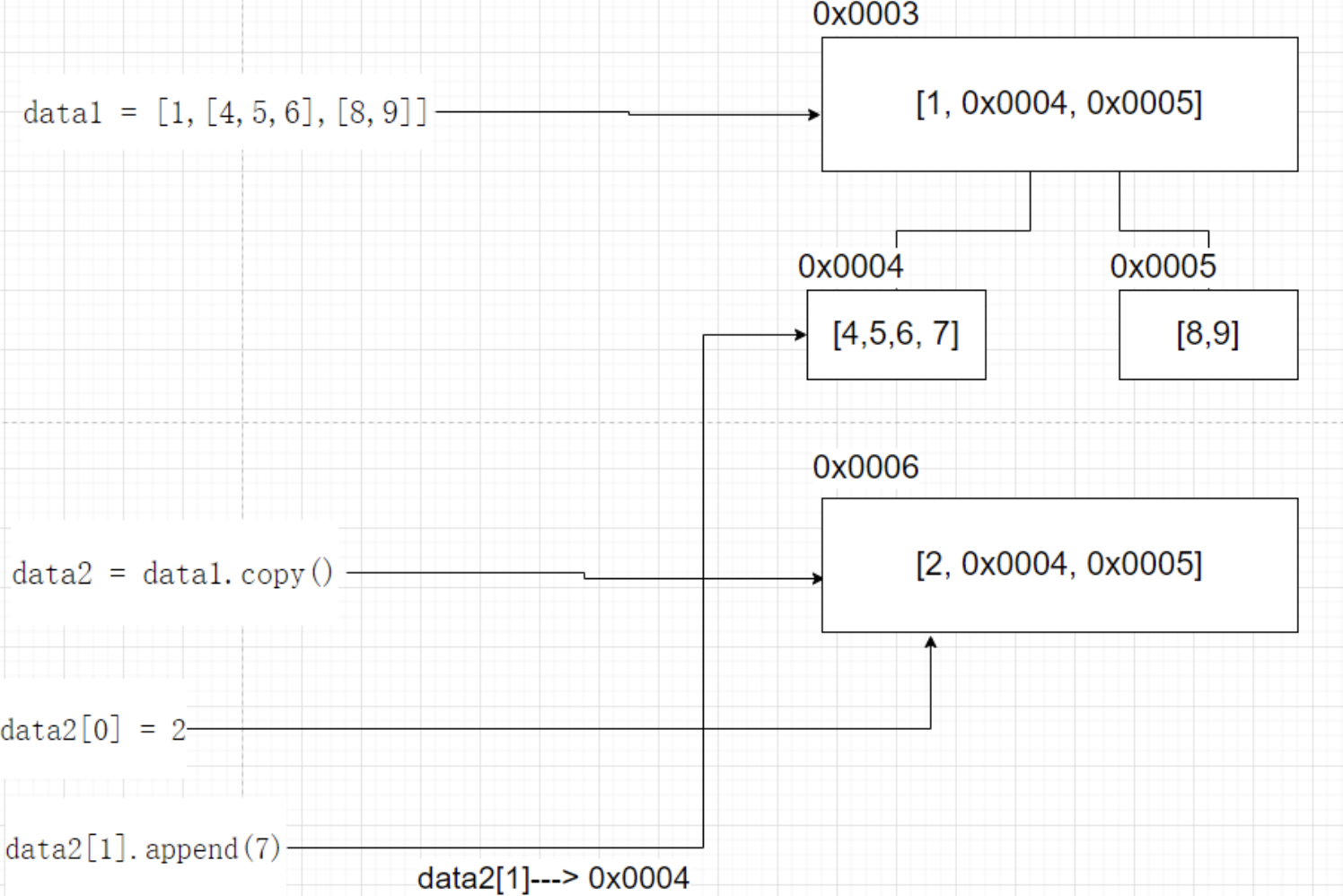
# 二级以上的列表[二维列表] data1 = [1,[4,5,6],[8,9]] data2 = data1.copy() print(id(data2), data2) # 2085906686784 [1, [4, 5, 6], [8, 9]] data2[0] = 2 data2[1].append(7) print(id(data2), data2) # 2085906686784 [2, [4, 5, 6, 7], [8, 9]] print(id(data1), data1) # 2085906687168 [1, [4, 5, 6, 7], [8, 9]]
针对上面的引用的情况,我们有时候的确需要根据一个已有的数据,复制一个独立的数据出来。
这种情况,我们可以使用拷贝方法
# 二级以上的列表[二维列表] data1 = [1, [4, 5, 6], [8, 9]] data2 = copy.deepcopy(data1) print(id(data2), data2) # 2085906686784 [1, [4, 5, 6], [8, 9]] data2[0] = 2 data2[1].append(7) print(id(data2), data2) # 2085906686784 [2, [4, 5, 6, 7], [8, 9]] print(id(data1), data1) # 2085906687168 [1, [4, 5, 6], [8, 9]]
# 二级容器
data1 = {"a":[1,2,3,4],"b":{"c":1,"d":2}}
data2 = copy.deepcopy(data1)
data1["b"]["ee"] = "大风车"
print(data1) #{'a': [1, 2, 3, 4], 'b': {'c': 1, 'd': 2, 'ee': '大风车'}}
print(data2) #{'a': [1, 2, 3, 4], 'b': {'c': 1, 'd': 2}}
总结:
可变数据类型:字典,集合,列表,才会需要使用深拷贝而已。
不可变数据类型:数值(整型,浮点型,布尔型)、字符串类型、元组,不需要使用深拷贝。
可变类型数据中提供的copy操作就是浅拷贝,只有需要深拷贝的时候,才需要copy.deepcopy()
浅拷贝和深拷贝的不同是针对二级以上的可变类型数据
浅复制无法解决二级可变类型数据的引用问题
三. 元组常用操作
元组的基本操作与列表是一样的。对于操作来说,元组只有count和index操作。
四. 集合常用操作
特点:去重,无序
| 方法 | 描述 | 实例 |
| add() | 为集合添加元素 |
# data1 = {"A", "B"} #成员如果已经存在,则会被去重 |
| 移除集合中所有元素 |
# data1 = {"A", "B"} |
|
| remove() | 移除指定元素 |
# data1 = {"A", "B", "C", "D"} |
| pop() | 随机移除元素 |
data1 = {"A", "B", "C", "D"} |
| difference() | 返回多个集合差集 |
set1 = {"A", "B", "C", "D"}
|
| intersection() | 返回集合交集 |
set1 = {"A", "B", "C", "D"}
|
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
set1 = {"A", "B", "C", "D"}
|
| symmetric_difference() | 返回两个集合中不重复的元素集合(对称差集)。 |
set1 = {"A", "B", "C", "D"}
|
| union() | 两个集合的并集 |
set1 = {"A", "B", "C", "D"}
|
| update() | 给集合添加元素 |
# data1 = {"A", "B"} |
| copy() | 浅拷贝一个集合 | |
| discard() | 删除集合中指定的元素 |
# data1 = {"A", "B", "C", "D"} |
| issubset() | 判断一个集合是否是另一个集合的子集 |
set2 = {"A", "D"} # 判断set2是否是set3的子集 |
| issuperset() | 判断一个集合是否是另一个集合的超集(父集) |
set1 = {"A", "B", "C", "D"} |
注:
集合的交叉并补


""" 1 差集 集合1.difference(集合2) 集合1 - 集合2 """ # set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"} # set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"} # # 运算符 # # 算set1的差集 # print(set1 - set2) # {'王宝强', '周杰伦'} # # 算set2的差集 # print(set2 - set1) # {'刘德华', '周润发'} # # # 方法 # # 算set1的差集 # print(set1.difference(set2)) # {'周杰伦', '王宝强'} # # 算set2的差集 # print(set2.difference(set1)) # {'周润发', '刘德华'} """ 2 并集 集合1.union(集合2) 集合1 | 集合2 """ # set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"} # set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"} # # 运算符 # print(set1 | set2) # {'周杰伦', '刘德华', '李宇春', '王宝强', '斯嘉丽', '周润发'} # # 方法 # print(set1.union(set2)) # {'周杰伦', '周润发', '李宇春', '斯嘉丽', '王宝强', '刘德华'} """ 3 交集 集合1.intersection(集合2) 集合1 & 集合2 """ # set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"} # set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"} # # 运算符 # print(set1 & set2) # {'斯嘉丽', '李宇春'} # # 方法 # print(set1.intersection(set2)) # {'斯嘉丽', '李宇春'} """ 4 对称差集:返回两个集合中不重复的元素集合, 补集情况涵盖在其中 集合1.symmetric_difference(集合2) 集合1 ^ 集合2 """ # set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"} # set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"} # print(set1 ^ set2) # {'刘德华', '周杰伦', '周润发', '王宝强'} # print(set1.symmetric_difference(set2)) # {'刘德华', '周杰伦', '周润发', '王宝强'} """ 5 补集 基于对称差集就可以很方便的得到补集""" # # (A ^ B) & B = A的补集 # # (A ^ B) & A = B的补集 # set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"} # set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"} # # set1的补集 # print((set1 ^ set2) & set2) # {'周润发', '刘德华'} # # set2的补集 # print((set1 ^ set2) & set1) # {'周杰伦', '王宝强'} """ 6 父/子集 issuperset 判断一个集合是否是另一个集合的超集(父集) issubset 判断一个集合是否是另一个集合的子集 """ set1 = {"A", "B", "C", "D"} set2 = {"A", "D"} set3 = {"A", "C"} # 判断set1是否是set2的父集 print( set1.issuperset(set2)) # True # 判断set3是否是set1的子集 print( set3.issubset(set1)) # True # 判断set2是否是set3的父集 print( set2.issuperset(set3)) # False # 判断set2是否是set3的子集 print( set2.issubset(set3)) # False
五. 字典常用操作
| 函数 | 描述 | 实例 |
| dict.clear() | 删除字典内所有元素 |
# data = {'age': 18, 'name': '小红'} |
| dict.get(key, default=None) | 返回指定键的值,如果键不在字典中返回 default 设置的默认值,不会报错! |
# 使用get不会报错 aaabbcccd 这种形式的字符串压缩成 a3b2c3d1形式 b={}
|
| dict.items() | 把字典转换成二级对等容器,以列表格式返回。 |
# data = {'name': 'xiaoming', 'age': 17} |
| dict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
# local_data = {"PASSWORD":"123", "URL": "127.0.0.1", "ENV": "dev"} |
| dict.pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
# data = {'name': 'xiaoming', 'age': 17} |
| dict.copy() | 返回字典的浅复制 | |
| dict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
# list_data = ["a", "b"] |
| dict.keys() | 返回一个由字典的键组成的伪列表对象 |
# data = {'name': 'xiaoming', 'age': 17} |
| dict.values() | 返回一个由字典的值组成的伪列表对象 |
# data = {'name': 'xiaoming', 'age': 17} |
| dict.setdefault(key, None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
data = {'name': 'xiaoming', 'age': 17}
#{'name': 'xiaoming', 'age': 17, 'money': 0.0} |
| dict.popitem() | 返回并删除字典中的最后一对键和值。 |
data = {'name': 'xiaoming', 'age': 17} |
六 实例操作
#1 字典转二级对等容器
data = {'name': 'xiaoming', 'age': 17}
print(list(data.items())) # [('name', 'xiaoming'), ('age', 17)]
#常用items的作用是让for循环遍历字典,得到每一个成员的键值对 # data = {'name': 'xiaoming', 'age': 17} # for key, value in data.items(): # print(f"key={key}, value={value}") # key=name, value=xiaoming # key=age, value=17 """2 如果在循环中,希望对于列表/元组,也想要类似字典这样,不仅要返回值,还要返回下标,可以使用""" # data = ["A", "B", "C", "D", "E"] # # data = ("A", "B", "C", "D", "E") # # data = "ABCDECV" # for index, item in enumerate(data): # enumerate可以让循环提取列表/元组/字符串的下标和值 # print(f"index={index}, item={item}")
# index=0, item=A # index=1, item=B ...
3 删除列表中偶数成员
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
列表本身是可变类型,所以内部成员会发生改变,但是内部成员的下标不是固定的,而是通过排列得到的,
所以当我们使用循环基于正序进行成员删除时,每删除一个成员,后面的所有成员都会往前排列,占据被删除的成员下标。所以尽量不要正序删除成员。
法一:
# data = [2, 1, 5, 3, 6, 4, 7, 8, 9, 10]
# length = len(data)
# for i in range(length-1, -1, -1): #9-1=8,8-1=7 ... 1-1=0,0-1 =-1。-1是结尾但不包含。所以i值为9,8,7,...3,2,1,0
# if data[i] % 2 == 0:
# data.pop(i)
#
# print(data) # [1, 5, 3, 7, 9]
法二:
# data = [2, 1, 5, 3, 6, 4, 7, 8, 9, 10]
# new_data = []
# for i in data:
# if i % 2 != 0:
# new_data.append(i)
#
# print(new_data) # [1, 5, 3, 7, 9]


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现