
朴素贝叶斯分类算法
1.理解分类与监督学习、聚类与无监督学习。
(1)简述分类与聚类的联系与区别。
联系:
①聚类分析是研究如何在没有训练的条件下把样本划分为若干类。
②在分类中,对于目标数据库中存在哪些类是知道的,要做的就是将每一条记录分别属于哪一类标记出来。
③聚类需要解决的问题是将已给定的若干无标记的模式聚集起来使之成为有意义的聚类,聚类是在预先不知道目标数据库到底有多少类的情况下,希望将所有的记录组成不同的聚类,并且使得在这种分类情况下,以某种度量(例如:距离)为标准的相似性,在同一聚类之间最小化,而在不同聚类之间最大化。
④与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据样本有类别标记
区别:分类是事先定义好类别 ,类别数不变 。分类器需要由人工标注的分类训练语料训练得到,属于有指导学习范畴。聚类则没有事先预定的类别,类别数不确定。 聚类不需要人工标注和预先训练分类器,类别在聚类过程中自动生成 。分类适合类别或分类体系已经确定的场合,比如按照国图分类法分类图书;聚类则适合不存在分类体系、类别数不确定的场合,一般作为某些应用的前端,比如多文档文摘、搜索引擎结果后聚类(元搜索)等。
(2)简述什么是监督学习与无监督学习。
① 监督学习:从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。监督学习就是最常见的分类(注意和聚类区分)问题,通过已有的训练样本(即已知数据及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优表示某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。也就具有了对未知数据分类的能力。监督学习的目标往往是让计算机去学习我们已经创建好的分类系统(模型)。
监督学习是训练神经网络和决策树的常见技术。这两种技术高度依赖事先确定的分类系统给出的信息,对于神经网络,分类系统利用信息判断网络的错误,然后不断调整网络参数。对于决策树,分类系统用它来判断哪些属性提供了最多的信息。
常见的有监督学习算法:回归分析和统计分类。最典型的算法是KNN和SVM。
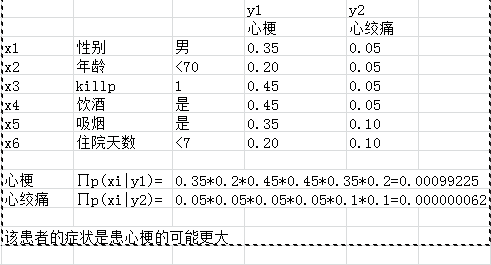
实例演练:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号