Redis五种数据类型底层实现
Redis数据库结构
Redis 是支持多key-value数据库(表)的,并用 RedisDb 来表示一个key-value数据库(表). redisServer 中有一个 redisDb *db成员变量, RedisServer 在初始化时,会根据配置文件的 db 数量来创建一个 redisDb 数组. 客户端在连接后,通过 SELECT 指令来选择一个 reidsDb,如果不指定,则缺省是redisDb数组的第1个(即下标是 0 ) redisDb. 一个客户端在选择 redisDb 后,其后续操作都是在此 redisDb 上进行的.
下面的initServer函数,会在redis启动的main函数中进行执行,initServer 函数初始化Redis运行时数据,createPidFile函数创建pid文件,其中也包含创建db的过程。
void initServer(void) {
int j;
//设置UNIX信号处理函数,使Redis服务器收到SIGINT信号后退出程序
signal(SIGHUP, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
setupSignalHandlers();
//如果开启了日志,则调用openlog函数与系统日志建立传输连接,以便输出系统日志。
if (server.syslog_enabled) {
openlog(server.syslog_ident, LOG_PID | LOG_NDELAY | LOG_NOWAIT,
server.syslog_facility);
}
/* Initialization after setting defaults from the config system. */
//初始化server中负责存储运行时数据的相关属性
server.aof_state = server.aof_enabled ? AOF_ON : AOF_OFF;
server.hz = server.config_hz;
server.pid = getpid();
server.current_client = NULL;
server.fixed_time_expire = 0;
server.clients = listCreate();
server.clients_index = raxNew();
server.clients_to_close = listCreate();
server.slaves = listCreate();
server.monitors = listCreate();
server.clients_pending_write = listCreate();
server.clients_pending_read = listCreate();
server.clients_timeout_table = raxNew();
server.slaveseldb = -1; /* Force to emit the first SELECT command. */
server.unblocked_clients = listCreate();
server.ready_keys = listCreate();
server.clients_waiting_acks = listCreate();
server.get_ack_from_slaves = 0;
server.clients_paused = 0;
server.events_processed_while_blocked = 0;
server.system_memory_size = zmalloc_get_memory_size();
if (server.tls_port && tlsConfigure(&server.tls_ctx_config) == C_ERR) {
serverLog(LL_WARNING, "Failed to configure TLS. Check logs for more info.");
exit(1);
}
//createSharedObjects 函数创建功效数据集,这些数据可在各场景中共享使用,如0-9999
//常用字符串OK,PONG等
createSharedObjects();
//adjustOpenFilesLimit函数尝试修改环境变量,提高系统允许打开的文件描述符上限,避免由于大量客户端链接导致错误
adjustOpenFilesLimit();
//创建事件循环器
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
if (server.el == NULL) {
serverLog(LL_WARNING,
"Failed creating the event loop. Error message: '%s'",
strerror(errno));
exit(1);
}
server.db = zmalloc(sizeof(redisDb)*server.dbnum);
/* Open the TCP listening socket for the user commands. */
//如果配置了server.port,则开启TCP Socket服务,接收用户请求。如果配置了server.tls_port,则
//开启TLS Socket服务,Redis 6.0开始支持TLS连接。如果配置了server.unixsocket,则开启UNIX Socket服务
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR)
exit(1);
if (server.tls_port != 0 &&
listenToPort(server.tls_port,server.tlsfd,&server.tlsfd_count) == C_ERR)
exit(1);
/* Open the listening Unix domain socket. */
if (server.unixsocket != NULL) {
unlink(server.unixsocket); /* don't care if this fails */
server.sofd = anetUnixServer(server.neterr,server.unixsocket,
server.unixsocketperm, server.tcp_backlog);
if (server.sofd == ANET_ERR) {
serverLog(LL_WARNING, "Opening Unix socket: %s", server.neterr);
exit(1);
}
anetNonBlock(NULL,server.sofd);
}
/* Abort if there are no listening sockets at all. */
if (server.ipfd_count == 0 && server.tlsfd_count == 0 && server.sofd < 0) {
serverLog(LL_WARNING, "Configured to not listen anywhere, exiting.");
exit(1);
}
/* Create the Redis databases, and initialize other internal state. */
//初始化数据库server.db,用于存储数据
for (j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType,NULL);
server.db[j].expires = dictCreate(&keyptrDictType,NULL);
server.db[j].expires_cursor = 0;
server.db[j].blocking_keys = dictCreate(&keylistDictType,NULL);
server.db[j].ready_keys = dictCreate(&objectKeyPointerValueDictType,NULL);
server.db[j].watched_keys = dictCreate(&keylistDictType,NULL);
server.db[j].id = j;
server.db[j].avg_ttl = 0;
server.db[j].defrag_later = listCreate();
listSetFreeMethod(server.db[j].defrag_later,(void (*)(void*))sdsfree);
}
//evictionPoolAlloc 函数初始化LRU/LFU样本池,用于实现LRU/LFU近似算法
evictionPoolAlloc(); /* Initialize the LRU keys pool. */
server.pubsub_channels = dictCreate(&keylistDictType,NULL);
server.pubsub_patterns = listCreate();
server.pubsub_patterns_dict = dictCreate(&keylistDictType,NULL);
listSetFreeMethod(server.pubsub_patterns,freePubsubPattern);
listSetMatchMethod(server.pubsub_patterns,listMatchPubsubPattern);
.......
/* Create the timer callback, this is our way to process many background
* operations incrementally, like clients timeout, eviction of unaccessed
* expired keys and so forth. */
//创建一个时间事件,执行函数为ServerCron,负责处理Redis中的定时任务,如清理过期数据,生成RDB文件等。
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
/* Create an event handler for accepting new connections in TCP and Unix
* domain sockets. */
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
for (j = 0; j < server.tlsfd_count; j++) {
if (aeCreateFileEvent(server.el, server.tlsfd[j], AE_READABLE,
acceptTLSHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.tlsfd file event.");
}
}
if (server.sofd > 0 && aeCreateFileEvent(server.el,server.sofd,AE_READABLE,
acceptUnixHandler,NULL) == AE_ERR) serverPanic("Unrecoverable error creating server.sofd file event.");
/* Register a readable event for the pipe used to awake the event loop
* when a blocked client in a module needs attention. */
if (aeCreateFileEvent(server.el, server.module_blocked_pipe[0], AE_READABLE,
moduleBlockedClientPipeReadable,NULL) == AE_ERR) {
serverPanic(
"Error registering the readable event for the module "
"blocked clients subsystem.");
}
/* Register before and after sleep handlers (note this needs to be done
* before loading persistence since it is used by processEventsWhileBlocked. */
//注册事件循环器的钩子函数,事件循环器在每次阻塞前后都会调用钩子函数
aeSetBeforeSleepProc(server.el,beforeSleep);
aeSetAfterSleepProc(server.el,afterSleep);
/* Open the AOF file if needed. */
//如果开启了OAF,则预先打开AOF文件
if (server.aof_state == AOF_ON) {
server.aof_fd = open(server.aof_filename,
O_WRONLY|O_APPEND|O_CREAT,0644);
if (server.aof_fd == -1) {
serverLog(LL_WARNING, "Can't open the append-only file: %s",
strerror(errno));
exit(1);
}
}
/* 32 bit instances are limited to 4GB of address space, so if there is
* no explicit limit in the user provided configuration we set a limit
* at 3 GB using maxmemory with 'noeviction' policy'. This avoids
* useless crashes of the Redis instance for out of memory. */
//如果Redis运行在32位操作系统上,由于32位操作系统内存空间限制为4GB,所以将Redis使用内存限制为3GB,避免Redis服务器因内存不足而崩溃
if (server.arch_bits == 32 && server.maxmemory == 0) {
serverLog(LL_WARNING,"Warning: 32 bit instance detected but no memory limit set. Setting 3 GB maxmemory limit with 'noeviction' policy now.");
server.maxmemory = 3072LL*(1024*1024); /* 3 GB */
server.maxmemory_policy = MAXMEMORY_NO_EVICTION;
}
//如果以cluster模式启动,则调用clusterInit函数初始化cluster机制。
if (server.cluster_enabled) clusterInit();
//replicationScriptCacheInit 函数初始化server.repl_scriptcache_dict属性
replicationScriptCacheInit();
//初始化LUA机制
scriptingInit(1);
//初始化慢日志机制
slowlogInit();
//latencyMonitorInit 函数初始化延迟监控机制
latencyMonitorInit();
}
RedisDb的整体结构如下图:
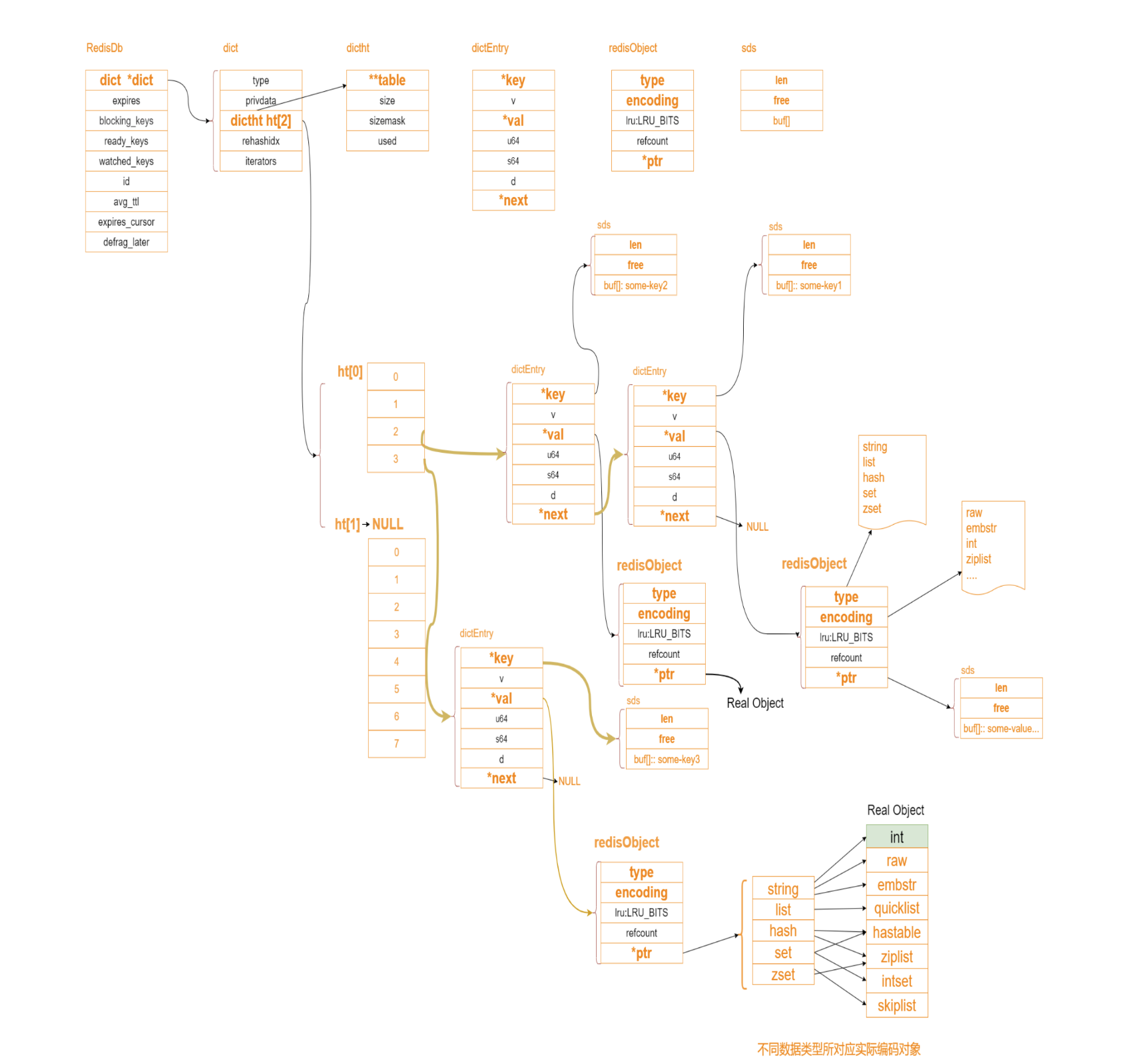
下面就简单介绍上图中几个核心组成部分
RedisDb对象
Redis是内存数据库,除了需要redisObject对基础数据结构封装外,还需要一个结构体对数据库进行封装,用来管理数据库相关数据和实现相关操作,这个结构体就是redisDb。
typedef struct redisDb {
//dict就是字典,相当于java的hashmap
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS 主要就是事务的一些处理 */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
1.dict 就是存的数据库的所有键值对
2.expires过期时间散列表,存放键的过期时间,注意dict和expires中的键都指向同一个键的sds。
3.id是数据库的序号
4.avg_ttl,平均存活时间,用于统计
5.defrag_later逐渐尝试逐个碎片整理的key列表。
6.watched_keys:watch的键和对应的client,主要用于事务
7.blocking_keys:处于阻塞状态的键和对应的client。
8.ready_keys:解除阻塞状态的键和对应的client,与blocking_keys属性相对,为了实现需要阻塞的命令设计。
字典
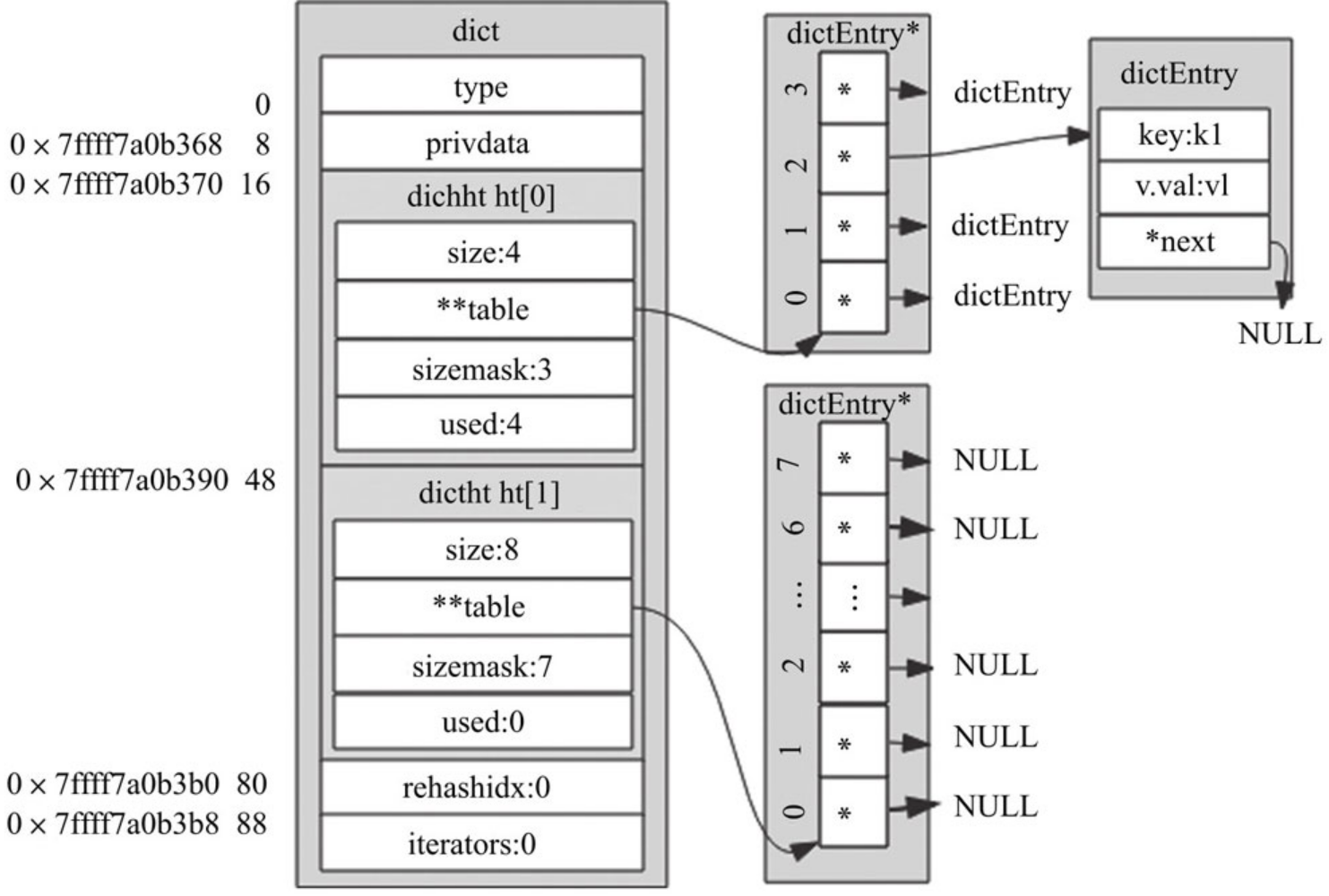
字典其主要作用是对散列表再进行一层封装,当字典需要进行一些特殊操作时要用到里面的辅助字段。具体结构体如下:
typedef struct dict {
dictType *type ; //字典类型
void *privdata;
dictht ht[2]; //hash表,rehash的时候一定有2个table,是为了进行扩容
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
1.privdata字段,私有数据,配合type字段指向的函数一起使用。
2.ht字段,是个大小为2的数组,该数组存储的元素类型为dictht,虽然有两个元素,但一般情况下只会使用ht[0],只有当该字典扩容、缩容需要进行rehash时,才会用到ht[1]
3.rehashidx字段,用来标记该字典是否在进行rehash,没进行rehash时,值为-1,否则,该值用来表示Hash表ht[0] 执行rehash到了哪个元素,并记录该元素的数组下标值。
4.iterators字段,用来记录当前运行的安全迭代器数,当有安全迭代器绑定到该字典时,会暂停rehash操作。Redis很多场景下都会用到迭代器,例如:执行keys命令会创建一个安全迭代器,此时iterators会加1,命令执行完毕则减1,而执行sort命令时会创建普通迭代器,该字段不会改变
Hash表
hash表的源码结构如下:
typedef struct dictht {
dictEntry **table; //这里指向的就是hash表地址
unsigned long size;
unsigned long sizemask;
unsigned long used; //代表有多少个元素
} dictht;
1.**tabl e指针数组,用于存储键值对
2.size table数组大小
3.掩码 = size -1
4.table数组已存元数个数,包含next单例表的数据
Hash表节点
hash表中的元素是用dictEntry结构体来封装的,主要作用是存储键值对,具体结构体如下:
typedef struct dictEntry {
void *key;
union {
void *val; //RedisObject
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //建立链表关系
} dictEntry;
Hash表中元素结构体和我们前面自定义的元素结构体类似,整体占用24字节,key字段存储的是键值对中的键。v字段是个联合体,存储的是键值对中的值,在不同场景下使用不同字段。例如,用字典存储整个Redis数据库所有的键值对时,用的是*val字段,可以指向不同类型的值;再比如,字典被用作记录键的过期时间时,用的是s64字段存储;当出现了Hash冲突时,next字段用来指向冲突的元素,通过头插法,形成单链表。
RedisObject对象
为了便于操作,Redis采用redisObjec结构来统一五种不同的数据类型,这样所有的数据类型就都可以以相同的形式在函数间传递而不用使用特定的类型结构。同时,为了识别不同的数据类型,redisObjec中定义了type和encoding字段对不同的数据类型加以区别。简单地说,redisObjec就是string、hash、list、set、zset的父类,可以在函数间传递时隐藏具体的类型信息,所以作者抽象了redisObjec结构来到达同样的目的。
具体结构如下图:
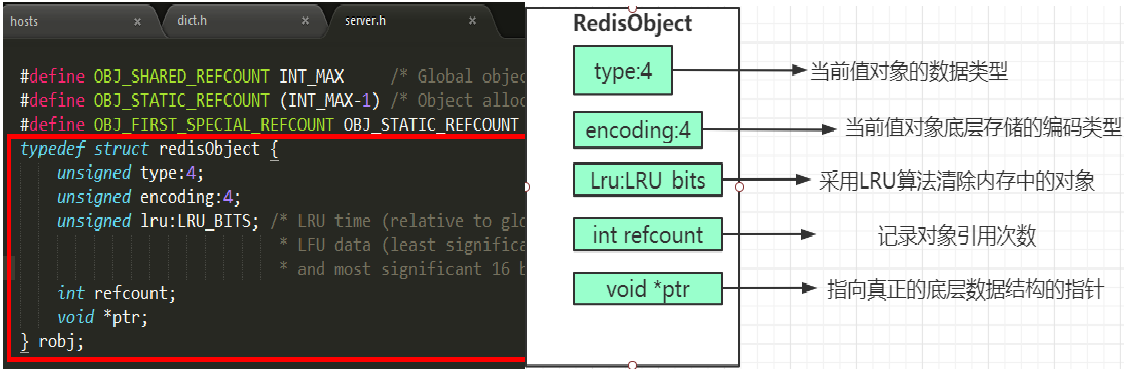
源码如下:
typedef struct redisObject {
unsigned type:4; //4 bit String hash list zset 8个bit位一个子节
unsigned encoding:4; //查看底层编码
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; //引用计数法,没有对象引用的时候,就为0,被释放掉了
void *ptr;
} robj;
1)type:type表示Redis对象的类型,占用4位,目前包含如下类型。
#define OBJ_STRING 0 /* 字符串对象*/
#define OBJ_LIST 1 /* 列表对象 */
#define OBJ_SET 2 /* 集合对象 */
#define OBJ_ZSET 3 /* 有序集合对象 */
#define OBJ_HASH 4 /* 散列表对象 */
#define OBJ_MODULE 5 /* 模块对象 */
#define OBJ_STREAM 6 /* 流对象 */
2)encoding:encoding表示对象内部存储的编码,在一定条件下,对象的编码可以在多个编码之间转化,长度占用4位,包含如下编码。
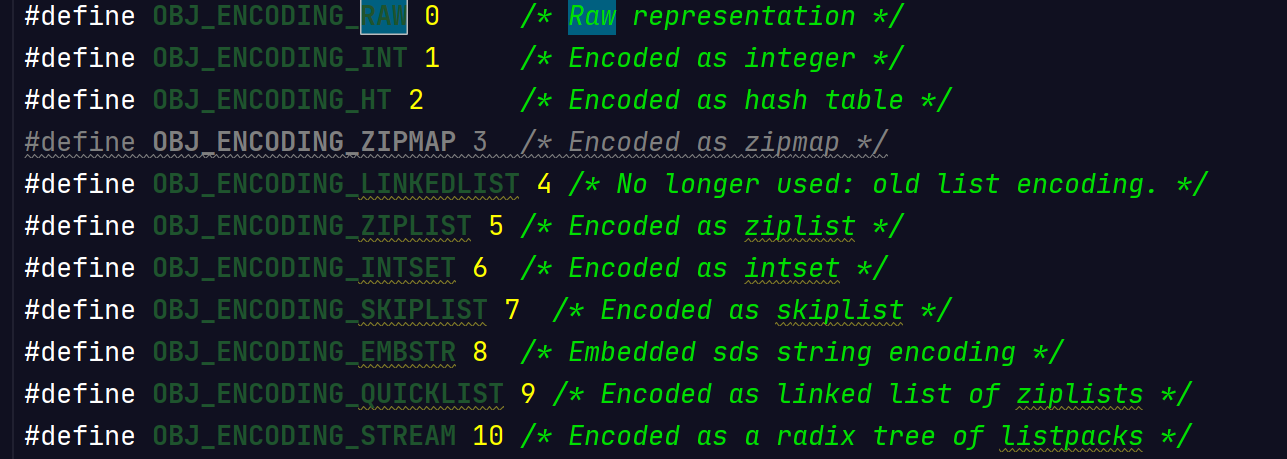
| 编码常量 | 常量值 | 编码对应的底层数据结构 |
|---|---|---|
| OBJ_ENCODING_RAW | 0 | 简单动态字符串 |
| OBJ_ENCODING_INT | 1 | long类型的整数 |
| OBJ_ENCODING_HT | 2 | 字典 |
| OBJ_ENCODING_ZIPMAP | 3 | 压缩映射 |
| OBJ_ENCODING_LINKEDLIST | 4 | 双端链表 |
| OBJ_ENCODING_ZIPLIST | 5 | 压缩列表 |
| OBJ_ENCODING_INTSET | 6 | 整数集合 |
| OBJ_ENCODING_SKIPLIST | 7 | 跳跃表和字典 |
| OBJ_ENCODING_EMBSTR | 8 | embstr编码的简单动态字符串 |
| OBJ_ENCODING_QUICKLIST | 9 | 快表 |
| OBJ_ENCODING_STREAM | 10 | 流 |
3)lru:lru占用24位,当用于LRU时表示最后一次访问时间,当用于LFU时,高16位记录分钟级别的访问时间,低8位记录访问频率0到255,默认配置8位可表示最大100万访问频次,详细参见object命令。
4)refcount:refcount表示对象被引用的计数,类型为整型,实际应用中参考意义不大。
5)ptr:ptr是指向具体数据的指针,比如一个字符串对象,该指针指向存放数据sds的地址。
阅读的源码主要是参考redis 6.0.8
String数据结构
在介绍string的数据结构之前先介绍一下Redis的SDS,Redis 中字符串对象的底层实现之一就使用了 SDS,像 AOF 模块中的 AOF 缓冲区,以及客户端状态中的输入缓冲区,也是由SDS实现的。
SDS
C语言中,用“\0”表示字符串的结束,如果字符串中本身就有“\0”字符,字符串就会被截断,即非二进制安全;因此Redis没有使用C原生的string,而自己创建了SDS。SDS既然是字符串,那么首先需要一个字符串指针;为了方便上层的接口调用,该结构还需要记录一些统计信息,如当前数据长度和剩余容量等,源码如下:
struct sds {
int len; // buf中已占用字节数
int free; // buf中剩余可用字节数
char buf[]; // 数据空间
};
1.len 表示 SDS 的长度,使我们在获取字符串长度的时候可以在 O(1)情况下拿到,而不是像 C 那样需要遍历一遍字符串。
2.free 可以用来计算 free 就是字符串已经分配的未使用的空间,有了这个值就可以引入预分配空间的算法了,而不用去考虑内存分配的问题。
3.buf 表示字符串数组,真存数据的。
SDS结构示意如图所示,在64位系统下,字段len和字段free各占4个字节,紧接着存放字符串。
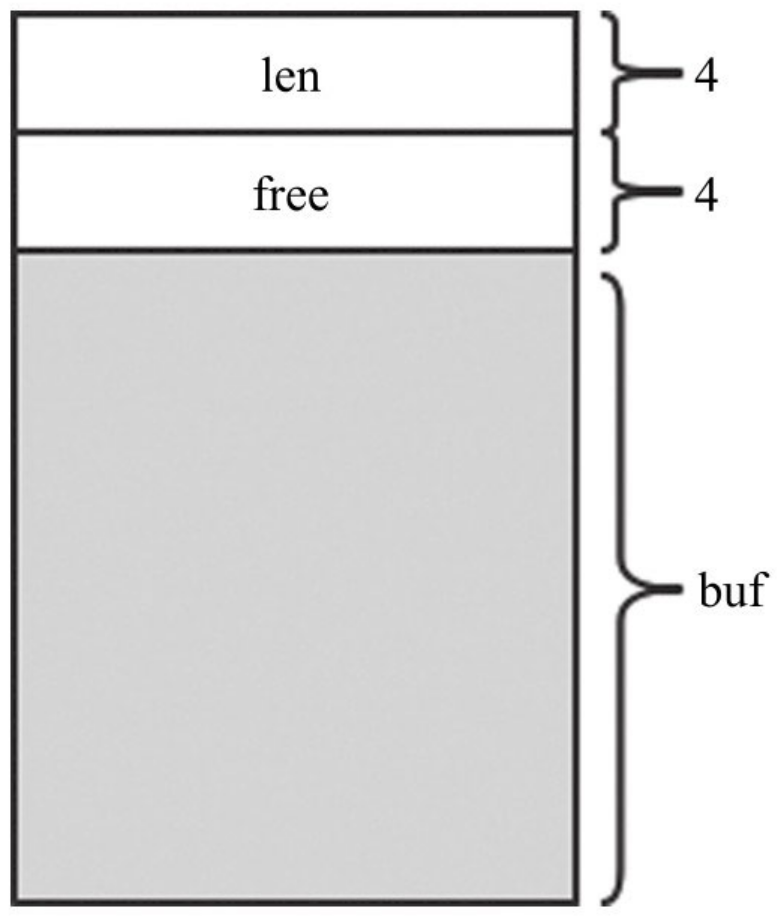
Redis 3.2之前的SDS也是这样设计的。这样设计有以下几个优点。
1)有单独的统计变量len和free(称为头部)。可以很方便地得到字符串长度。
2)内容存放在柔性数组buf中,SDS对上层暴露的指针不是指向结构体SDS的指针,而是直接指向柔性数组buf的指针。上层可像读取C字符串一样读取SDS的内容,兼容C语言处理字符串的各种函数。
3)由于有长度统计变量len的存在,读写字符串时不依赖“\0”终止符,保证了二进制安全。
但是同样会有一定的问题:
不同长度的字符串是否有必要占用相同大小的头部?一个int占4字节,在实际应用中,存放于Redis中的字符串往往没有这么长,每个字符串都用4字节存储未免太浪费空间了。
后面的版本进行了优化,源码如下:
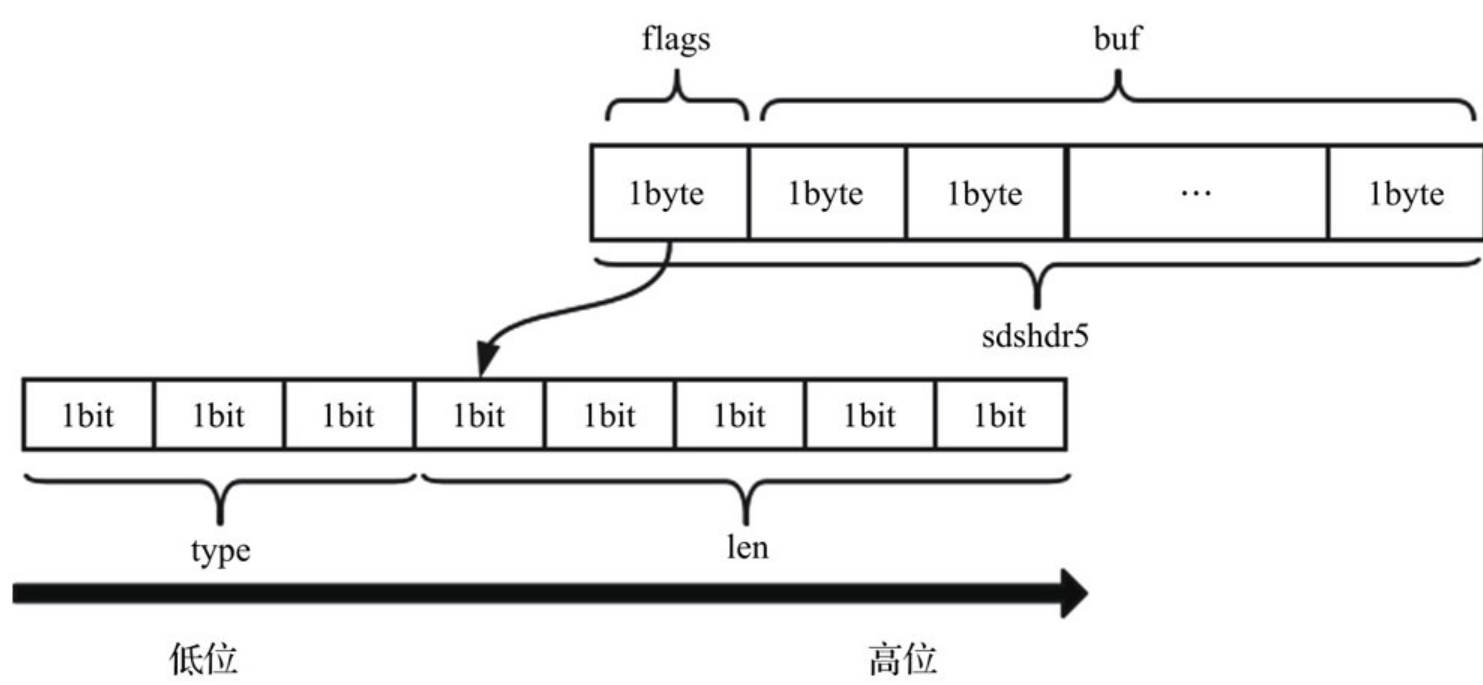
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; //低3位存储类型,高5位存储长度
char buf[]; //柔性数组,存放实际内容
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; //已使用长度,用1字节存储
uint8_t alloc; //总长度,用1字节存储
unsigned char flags; //低3位存储类型,高5位预留
char buf[]; //柔性数组,存放实际内容
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; // 已使用长度,用2字节存储
uint16_t alloc; // 总长度,用2字节存储
unsigned char flags; //低3位存储类型,高5位预留
char buf[]; //柔性数组,存放实际内容
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; //已使用长度,用4字节存储
uint32_t alloc; //总长度,用4字节存储
unsigned char flags; //低3位存储类型,高5位预留
char buf[]; //柔性数组,存放实际内容
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; //已使用长度,用8字节存储
uint64_t alloc; //总长度,用8字节存储
unsigned char flags; //低3位存储类型,高5位预留
char buf[]; //柔性数组,存放实际内容
};
sds sdsnewlen(const void *init, size_t initlen) {
void *sh; //sds指针
sds s;
char type = sdsReqType(initlen); //根据字符串长度选择不同的类型
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
//且对于sdshdr5类型,在创建空字符串时会强制转换为sdshdr8。原因可能是创建空字符串后,其内容可能会频繁更新而引发扩容,故创建时直接创建为sdshdr8。
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
//根据type计算sds长度(头部)
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1);//+1 是了结束符\0
if (sh == NULL) return NULL;
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0'; //添加结束标志符
return s; //返回buf
}
sdshdr5、(2^5=32byte)
sdshdr8、(2 ^ 8=256byte)
sdshdr16、(2 ^ 16=65536byte=64KB)
sdshdr32、 (2 ^ 32byte=4GB)
sdshdr64,2的64次方byte=17179869184G用于存储不同的长度的字符串。
如果字符串长度小于32的话,则用sdshdr5进行存储,flags占1个字节,其低3位(bit)表示type,高5位(bit)表示长度,能表示的长度区间为0~31, flags后面就是字符串的内容。结构如下:
而长度大于31的字符串,1个字节依然存不下。我们按之前的思路,将len和free单独存放。sdshdr8、sdshdr16、sdshdr32和sdshdr64的结构相同,sdshdr16结构如图所示。
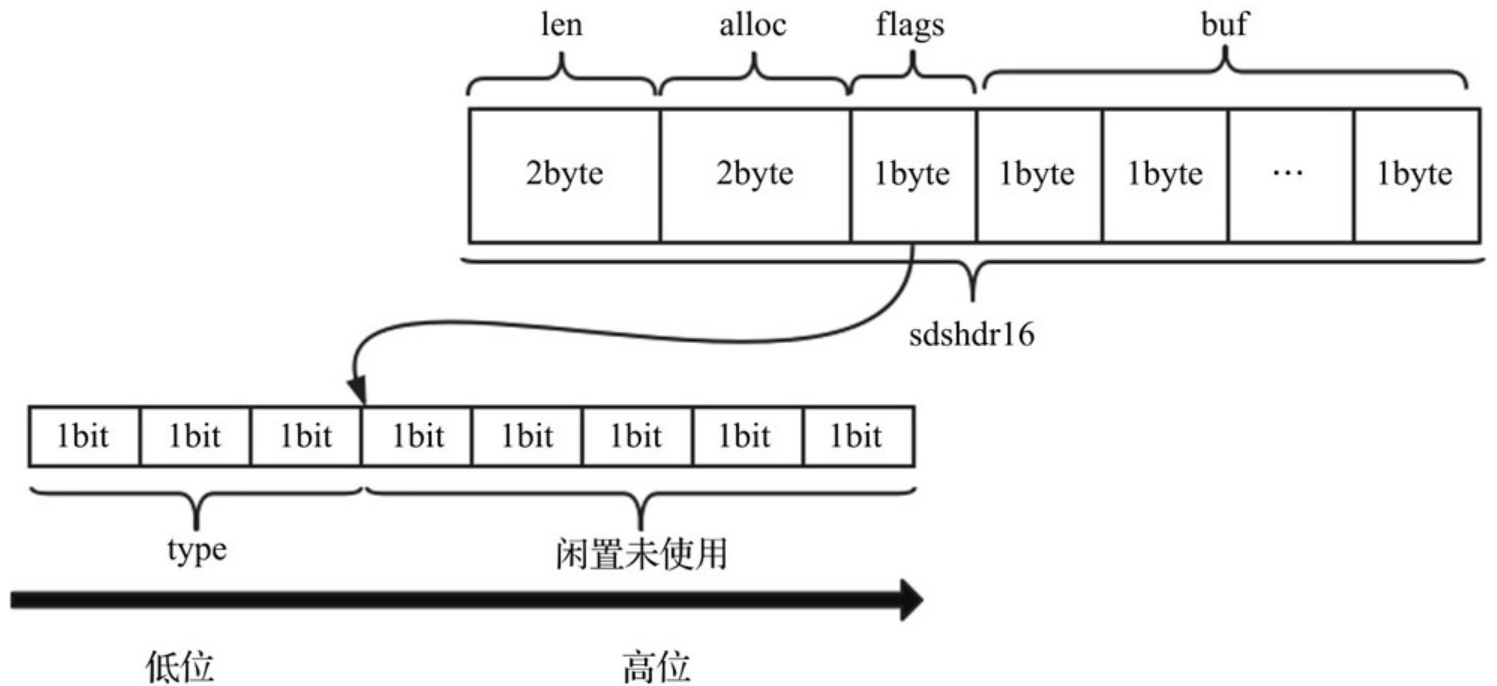
其中“表头”共占用了S[2(len)+2(alloc)+1(flags)]个字节。flags的内容与sdshdr5类似,依然采用3位存储类型,但剩余5位不存储长度。
| C语言 | SDS | |
|---|---|---|
| 字符串长度处理 | 需要从头开始遍历,直到遇到 '\0' 为止,时间复杂度O(N) | 记录当前字符串的长度,直接读取即可,时间复杂度 O(1) |
| 内存重新分配 | 分配内存空间超过后,会导致数组下标越级或者内存分配溢出 | 1.SDS 修改后,len 长度小于 1M,那么将会额外分配与 len 相同长度的未使用空间。如果修改后长度大于 1M,那么将分配1M的使用空间。2.有空间分配对应的就有空间释放。SDS 缩短时并不会回收多余的内存空间,而是使用 free 字段将多出来的空间记录下来。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配。 |
| 二进制安全 | 二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符,比如 '\0' 等。前面提到过,C中字符串遇到 '\0' 会结束,那 '\0' 之后的数据就读取不上了 | 根据 len 长度来判断字符串结束的,二进制安全的问题就解决了 |
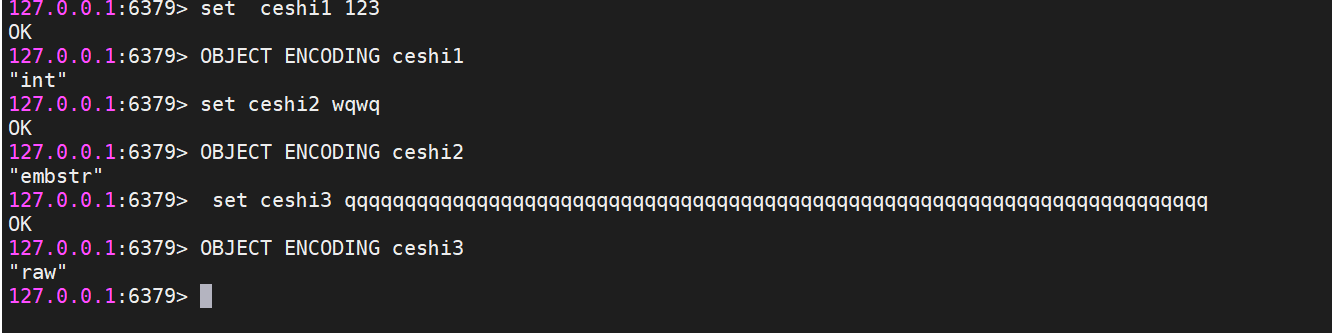
字符串类型
字符串的key经过Hash之后作为dict的键,只能是string类型,字符串的value是dict的值,用结构体robj来表示。Redis的字符串可以分为3种类型,测试结果如下图:
INT 编码格式
当字符串键值的内容可以用一个64位有符号整形来表示时,Redis会将键值转化为long型来进行存储,此时即对应 OBJ_ENCODING_INT 编码类型。内部的内存结构表示如下:
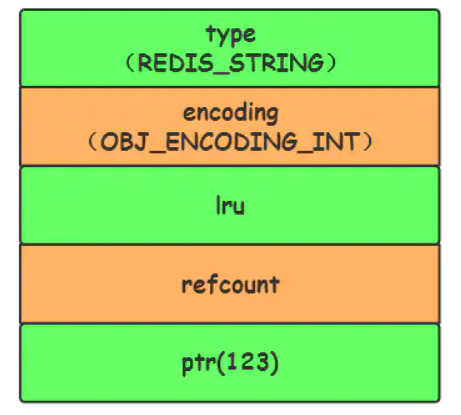
Redis 启动时会预先建立 10000 个分别存储 0~9999 的 redisObject 变量作为共享对象,这就意味着如果 set字符串的键值在 0~10000 之间的话,则可以 直接指向共享对象 而不需要再建立新对象,此时键值不占空间!
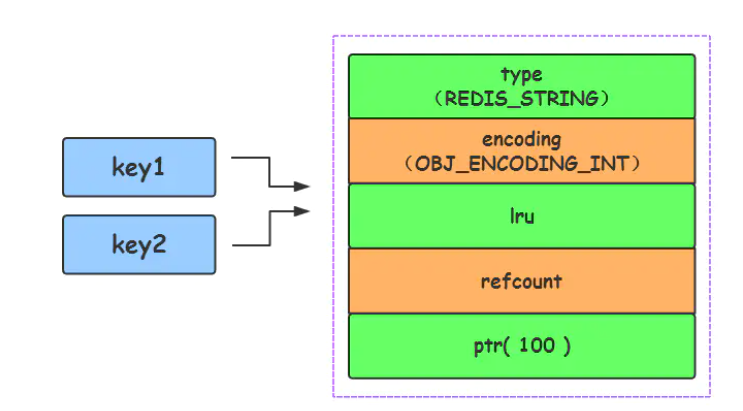
EMBSTR编码格式
对于长度小于 44的字符串,Redis 对键值采用OBJ_ENCODING_EMBSTR 方式,EMBSTR 顾名思义即:embedded string,表示嵌入式的String。从内存结构上来讲 即字符串 sds结构体与其对应的 redisObject 对象分配在同一块连续的内存空间,字符串sds嵌入在redisObject对象之中一样。
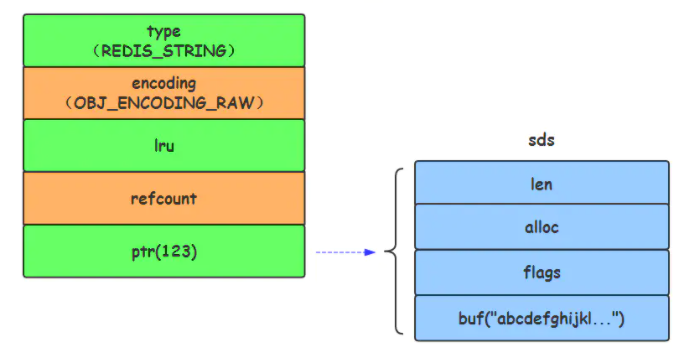
RAW 编码格式
当字符串的键值为长度大于44的超长字符串时,Redis 则会将键值的内部编码方式改为OBJ_ENCODING_RAW格式,这与OBJ_ENCODING_EMBSTR编码方式的不同之处在于,此时动态字符串sds的内存与其依赖的redisObject的内存不再连续了
上面3种类型的具体选择的源码如下:
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
if (!sdsEncodedObject(o)) return o;
//如果数据对象被多处引用,不能再进行编码操作
if (o->refcount > 1) return o;
//获取长度,
len = sdslen(s);
//如果字符串长度小于或等于20
if (len <= 20 && string2l(s,len,&value)) { //string2l,判断字符串能不能转成int,然后redisObject的指针指向这个value的值
//首先尝试使用内存的共享数据,避免重复创建相同数据对象而浪费内存它是一个整数数组,存放0-9999
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
//如果发现不能使用共享数据,并且原编码格式为RAW的,则换成数值类型
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
//如果发现不能使用共享数据,并且原编码格式为EMBSTR的,则会创建新的redisObject,编码为OBJ_ENCODING_INT,ptr指向longlong类型
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o);
return createStringObjectFromLongLongForValue(value);
}
}
}
//尝试转成OBJ_ENCODING_EMBSTR,如果字符串长度小于等于OBJ_ENCODING_EMBSTR_SIZE_LIMIT,定义为44,
// 那么调用createEmbeddedStringObject将encoding改为OBJ_ENCODING_EMBSTR;对象分配在同一块连续的内存空间,
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
//说明只能使用RAW编码,此时动态字符串sds的内存与其依赖的redisObject的内存不再连续了
trimStringObjectIfNeeded(o);
/* Return the original object. */
return o;
}
Hash数据结构
Redis提供了一系列散列相关的命令给用户使用,例如hset、hget等。然而,这些散列指令对应的底层value的存储并不总是散列表,Redis提供了ziplist以及散列表(hashtable)两种方案进行存储。当需要存储的key-value结构同时满足下面两个条件时,采用ziplist作为底层存储,否则需要转换为散列表存储。值得注意的是,ziplist的存储顺序与插入顺序一致,而散列表的存储则不一致。
-
hash-max-ziplist-entries:使用压缩列表保存时哈希集合中的最大元素个数(默认值512)。
-
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度默认值64)。
Hash类型键的字段个数 小于 hash-max-ziplist-entries 并且每个字段名和字段值的长度 小于 hash-max-ziplist-value 时,
Redis才会使用 OBJ_ENCODING_ZIPLIST来存储该键,前述条件任意一个不满足则会转换为 OBJ_ENCODING_HT的编码方式,
ziplist升级到hashtable可以,反过来降级不可以。
下面为实验内容:
127.0.0.1:6379> CONFIG GET hash*
1) "hash-max-ziplist-entries"
2) "512"
3) "hash-max-ziplist-value"
4) "64"
127.0.0.1:6379> CONFIG set hash-max-ziplist-entries 3
OK
127.0.0.1:6379> CONFIG set hash-max-ziplist-value 8
OK
127.0.0.1:6379> CONFIG GET hash*
1) "hash-max-ziplist-entries"
2) "3"
3) "hash-max-ziplist-value"
4) "8"
127.0.0.1:6379> hset user name test
(integer) 1
127.0.0.1:6379> OBJECT encoding user
"ziplist"
127.0.0.1:6379> hset user name test12345
(integer) 0
127.0.0.1:6379> OBJECT encoding user
"hashtable"
127.0.0.1:6379> HMSET user2 name lisi age 20 score 100
OK
127.0.0.1:6379> OBJECT encoding user2
"ziplist"
127.0.0.1:6379> HMSET user2 name lisi age 20 score 100 birth 19990101
OK
127.0.0.1:6379> OBJECT encoding user2
"hashtable"
127.0.0.1:6379>
转换的源码如下:
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
if ((c->argc % 2) == 1) {
addReplyError(c,"wrong number of arguments for HMSET");
return;
}
//查找key,找不到的话就新建一个
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
//尝试转换底层编码
hashTypeTryConversion(o,c->argv,2,c->argc-1);
for (i = 2; i < c->argc; i += 2)
//依次写入filed value
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
char *cmdname = c->argv[0]->ptr;
if (cmdname[1] == 's' || cmdname[1] == 'S') {
/* HSET */
addReplyLongLong(c, created);
} else {
/* HMSET */
addReply(c, shared.ok);
}
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
server.dirty++;
}
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
for (i = start; i <= end; i++) {
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT);
break;
}
}
}
ziplist
压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序性数据结构,我们可以从源码的注释中看到官方对它的定义。
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time. However, because every operation requires a reallocation of the memory used by the ziplist, the actual complexity is related to the amount of memory used by the ziplist.
也就是说,ziplist 是一种特殊编码的双向链表,目标是为了提高内存的存储效率。它的每个节点可用于存储字符串或整数值,其中整数是按真正的整数进行编码,而不是一系列字符。它允许在列表的任意一端以 O(1) 的时间复杂度提供 push 和 pop 操作。但是,它的每个操作都需要进行内存重分配,实际的复杂性与 ziplist 使用的内存大小有关,也就是和它的存储的节点个数有关。
Ziplist 压缩列表是一种紧凑编码格式,总体思想是多花时间来换取节约空间,即以部分读写性能为代价,来换取极高的内存空间利用率,
因此只会用于 字段个数少,且字段值也较小 的场景。压缩列表内存利用率极高的原因与其连续内存的特性是分不开的。当一个 hash对象 只包含少量键值对且每个键值对的键和值要么就是小整数要么就是长度比较短的字符串,那么它用 ziplist 作为底层实现。
下面是源码结构的说明:
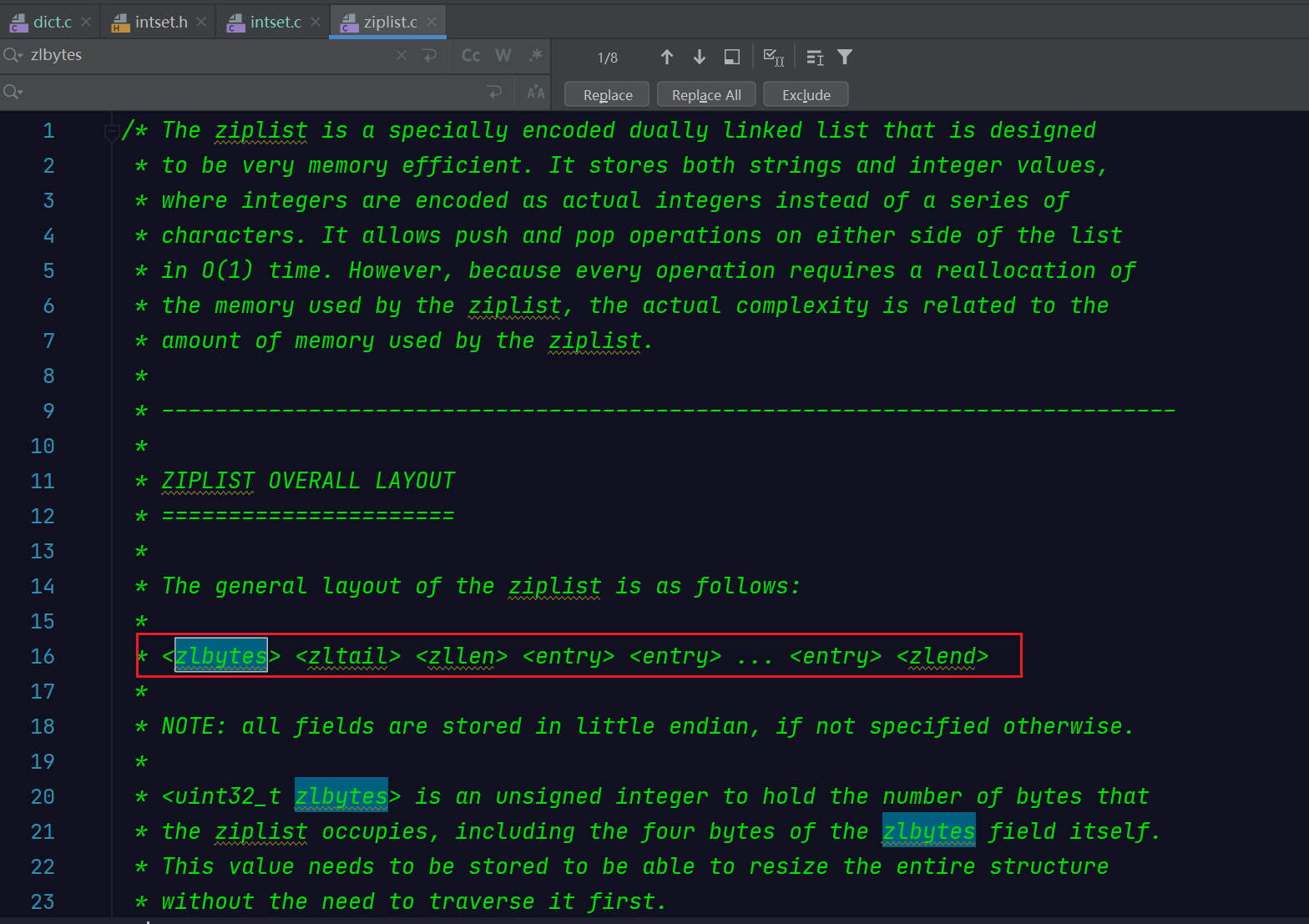
| 属性 | 说明 |
|---|---|
| zlbytes | uint32_t,记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分配或者计算zlend 的位置时使用。 |
| zltail | uint32_t,记录压缩列表表尾节点距离起始地址的字节数,可以无需遍历整个列表就可以确定表尾节点的地址,方便进行 pop 等操作。 |
| zllen | uint16_t,记录压缩列表包含的节点数量,但当数量超过 2^16 - 2 时,这个值被设为 2^16 - 1,我们需要遍历整个列表,才能知道它包含多少个节点。 |
| entry | 压缩列表的各个节点,真正存放数据的地方,节点的长度由保存的内容决定。 |
| zlend | uint8_t,标记压缩列表的末端,值固定等于 255。 |
entry就是ziplist中保存的节点,它的格式如下:
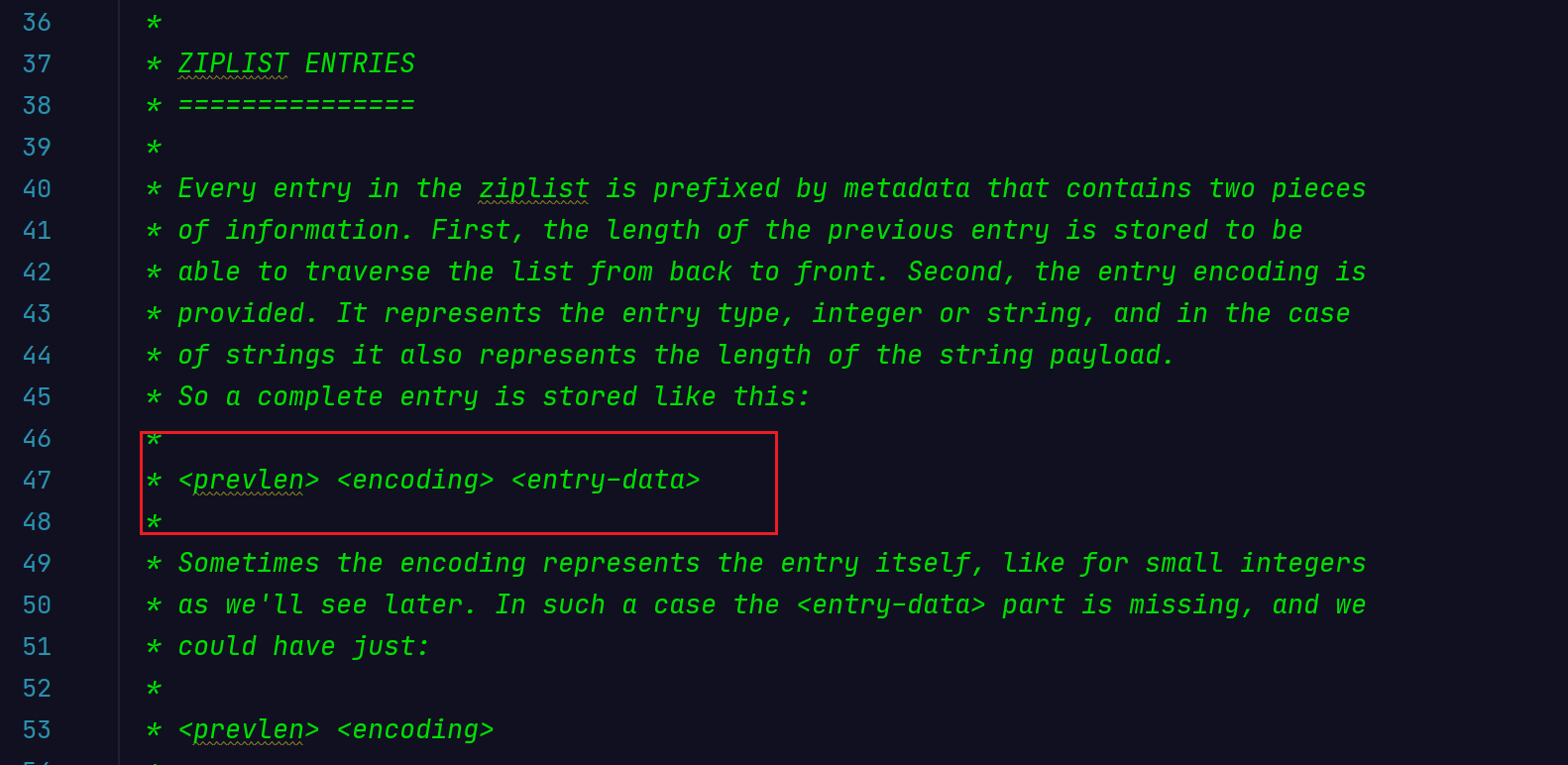
| 属性 | 说明 |
|---|---|
| prevlen | 记录了压缩列表前一个节点的长度,此属性的长度为 1 字节或 5 字节,当前一个节点的长度小于 254 字节,长度为 1 字节;当大于等于 254 字节时,为 5 字节,其中第一个字节固定为254,后 4 个字节记录其长度。 |
| encoding | 记录了节点的 content 属性所保存数据的类型以及长度。当保存的是字符串时,前两位为 00、01 或者 10;当保存的是整数值时,前两位为 11。 |
| entry-data | 负责保存节点的值。 |
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
一个ziplist中,不同节点元素的编码格式可以不同,编码格式规范如下:
| 类型 | 编码 | 编码长度 | 内容 |
|---|---|---|---|
| 字符串 | |00pppppp| | 1字节 | 长度小于等于 63 字节( 6 位)的字符串,“pppppp”表示无符号6位长度 |
| |01pppppp|qqqqqqqq| | 2字节 | 长度小于等于 16383 字节( 14 位)的字符串 | |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5字节 | 长度大于等于 16384 字节的字符串。只有后面的 4 个字节代表长度,最大表示到 2^32-1。第一个字节的低 6 位没有使用,被设为零 | |
| 整数 | |11000000| | 1字节 | int16_t 类型的整数(两字节) |
| |11010000| | 1字节 | int32_t 类型的整数( 4 字节) | |
| |11100000| | 1字节 | int64_t 类型的整数( 8 字节) | |
| |11110000| | 1字节 | 24 位有符合整数( 3 字节) | |
| |11111110| | 1字节 | 8 位有符号整数( 1 字节) | |
| |1111xxxx| | 1字节 | 这种编码没有 content 属性,xxxx 即代表了保存的整数值,但 0000 与 1111 与其他表示冲突,所以只能使用 0001 到 1110 之间,也即 1 到 13,但为了表示从 0 开始,xxxx - 1才是其真实保存的数值,也就是 该编码实际表示的数值为 0 ~ 12。 |
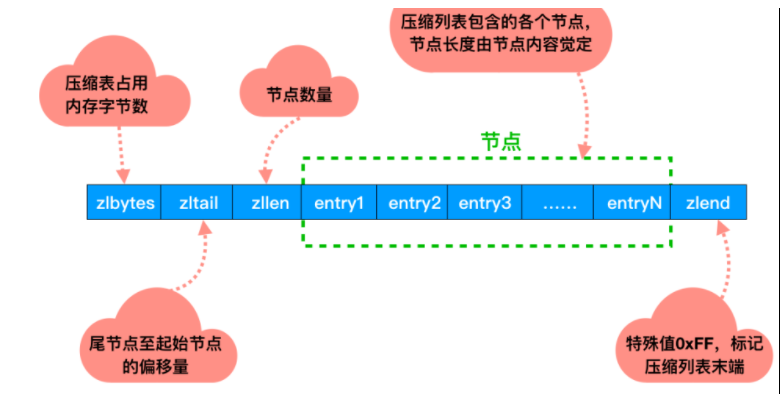
ziplist它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存。只用在字段个数少,字段值小的场景里面下面2张图为它的组成结构:

hashtable
Redis 中的哈希对象的底层实现之一就是字典,当包含的键值对比较多,或者键值对中的元素都是比较长的字符串时,Redis 就会使用字典作为哈希对象的底层实现。如图所示:每个key, value指针都是指向redisObject的结构体,该结构体记录了存储结构的类型以及其编码方式等信息。
字典是Redis的重要数据结构。除了散列类型,Redis数据库也使用了字典结构,上面已经描述过了,此处略过。既然使用了Hash表,就会出现下面几个问题?
- 使用了什么Hash算法?
- Hash冲突怎么解决?
- Hash表怎么进行扩容?
Hash算法
dictHashKey宏调用dictType.hashFunction函数计算键的Hash值:
#define dictHashKey(ht, key) (ht)->type->hashFunction(key)
Reids中字典基本使用了SipHash算法,该算法能有效的防止Hash表碰撞攻击,并提供不错的性能。
Redis 4.0之前使用的哈希算法为 MurmurHash 算法;其索引值的计算,依赖于哈希值和 sizemask 属性。当给定一个 KV 值时,其索引值的计算过程如下:
- 首先根据类型特定函数中设置的哈希函数,计算出 key 的哈希值:hash = dict -> type -> hashFunction(key)
- 然后再根据哈希值和 sizemask 属性,计算出索引值:index = hash & dict -> ht[x].sizemask
它的计算速度非常快,而且计算处理的结果有很好的离散性,Redis 4.0后用的SipHash算法,应该是出于安全的考虑。
哈希冲突
不同的键输入经Hash计算后的值具有强随机分布性,但也有小概率是相同的值,此时会导致键最终计算的索引值相同,也就是说,此时两个不同的键会关联上同一个数组下标,我们称这些键出现了冲突。
为了解决Hash冲突,所以数组中的元素除了应把键值对中的“值”存储外,还应该存储“键”信息和一个next指针,next指针可以把冲突的键值对串成单链表,“键”信息用于判断是否为当前要查找的键。
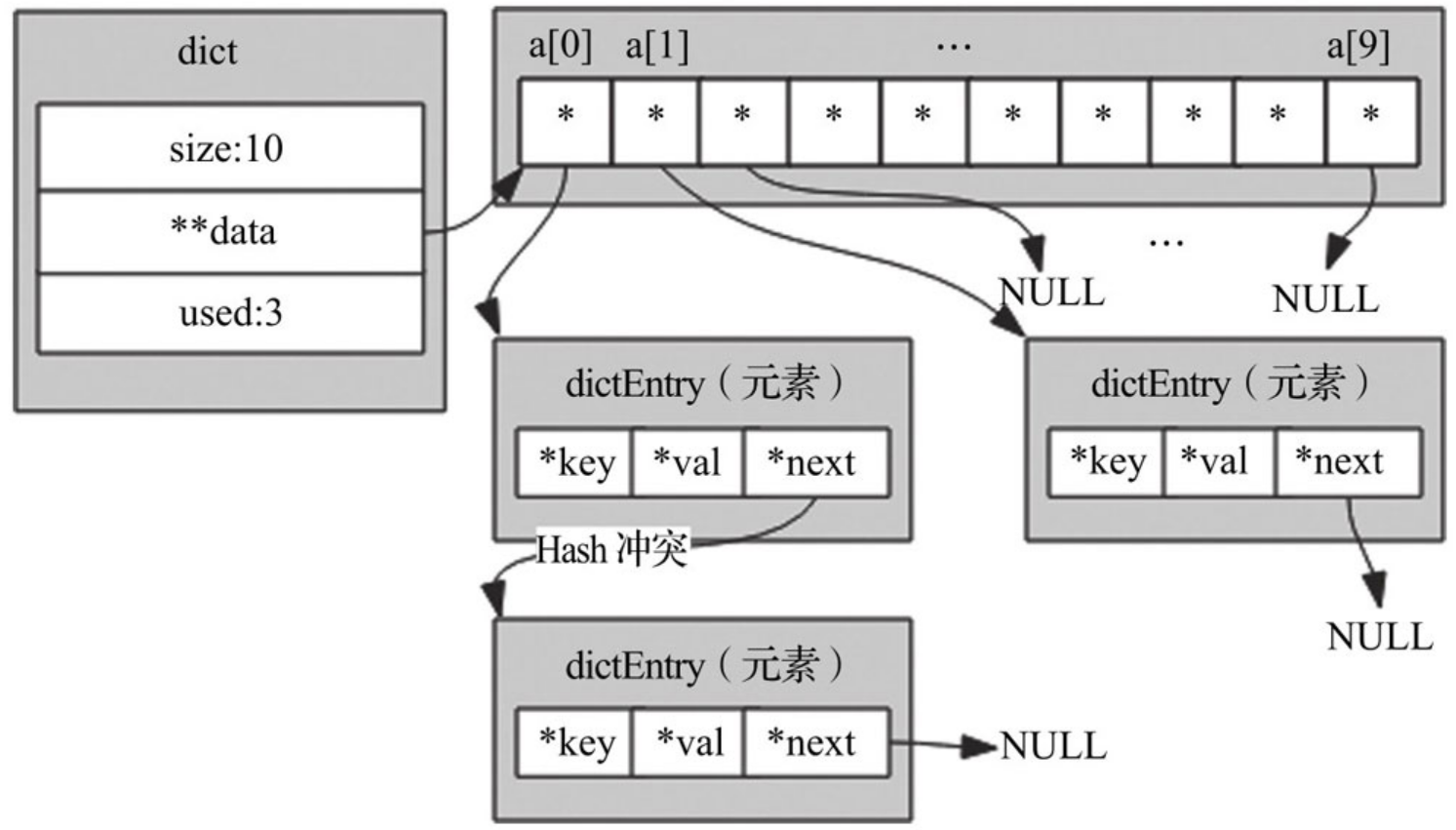
第1步:键通过Hash、取余等操作得到索引值,根据索引值找到对应元素。
第2步:判断元素中键与查找的键是否相等,相等则读取元素中的值返回,否则判断next指针是否有值,如存在值,则读取next指向元素,回到第2步继续执行,如不存在值,则代表此键在字典中不存在,返回NULL。
扩容
Redis使用了一种渐进式扩容方式,这样设计,是因为Redis是单线程。如果再一个操作内将h[0]所有数据都迁移到ht[1],那么可能会引起线程长时间的堵塞。所以,redos字典扩容是在每次操作数据时都执行一次扩容单步操作,扩容单步操作将ht[0].table[rehashidx]的数据迁移到ht[1]。等到ht[0]的所有数据都迁移到ht[1],便将ht[0]指向ht[1],完成扩容。
扩容需要满足2个条件:
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
1.d->ht[0].used >= d->ht[0].size: Hash表存储的键值对数量大于或等于Hash表数组的长度。
2.开启了dict_can_resize 或者负载因子大于dict_force_resize_ratio。dict_can_resize开启后,负载因子等于1就会进行扩容
扩容源码如下:
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size); //重新计算扩容后的值,必须为2的N次幂
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
//构建一个新的hash表dictht
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
//ht[0].table == NULL 代表字典的Hash表数组还没有初始化,将新的dictht赋值给ht[0],那么它就可以存数据了。
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
//否则就将新的dictht赋值给ht[1],将rehashidx=0,就代表要进行rehash操作,要迁移ht[0]的数据
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n; //扩容后的新内存放入ht[1]中
d->rehashidx = 0; //非默认的-1,表示需进行rehash
return DICT_OK;
}
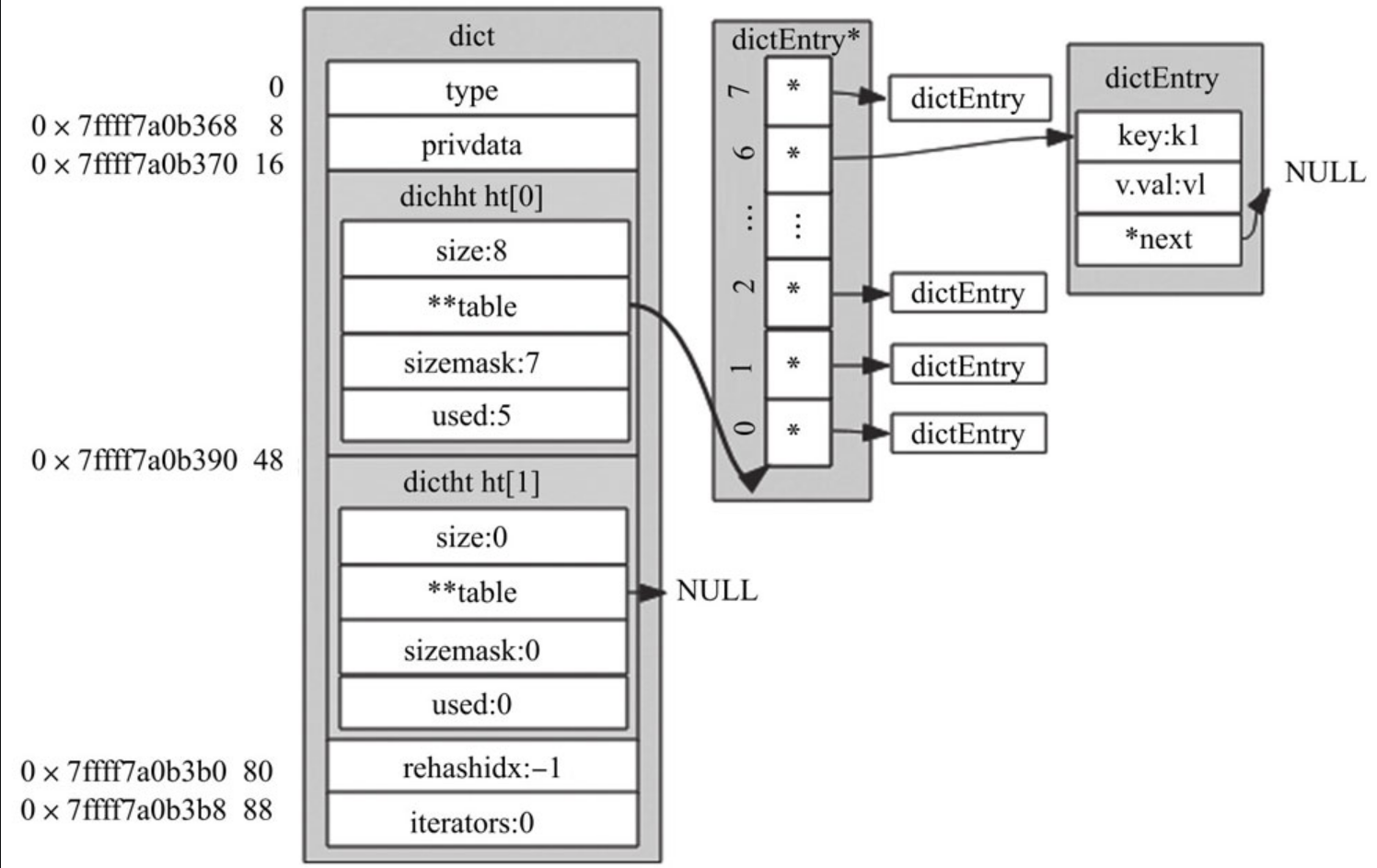
扩容主要流程为:① 申请一块新内存,初次申请时默认容量大小为4个dictEntry;非初次申请时,申请内存的大小则为当前Hash表容量的一倍。② 把新申请的内存地址赋值给ht[1],并把字典的rehashidx标识由-1改为0,表示之后需要进行rehash操作。
扩容后,字典容量及掩码值会发生改变,同一个键与掩码经位运算后得到的索引值就会发生改变,从而导致根据键查找不到值的情况。解决这个问题的方法是,新扩容的内存放到一个全新的Hash表中(ht[1]),并给字典打上在进行rehash操作中的标识(即rehashidx! =-1)。此后,新添加的键值对都往新的Hash表中存储;而修改、删除、查找操作需要在ht[0]、ht[1]中进行检查,然后再决定去对哪个Hash表操作。除此之外,还需要把老Hash表(ht[0])中的数据重新计算索引值后全部迁移插入到新的Hash表(ht[1])中,此迁移过程称作rehash。
渐进式rehash
rehash除了扩容时会触发,缩容时也会触发。Redis整个rehash的实现,主要分为如下几步完成。
1)给Hash表ht[1]申请足够的空间;扩容时空间大小为当前容量2,即d->ht[0].used2;当使用量不到总空间10%时,则进行缩容。缩容时空间大小则为能恰好包含d->ht[0].used个节点的2^N次方幂整数,并把字典中字段rehashidx标识为0。
2)进行rehash操作调用的是dictRehash函数,重新计算ht[0]中每个键的Hash值与索引值(重新计算就叫rehash),依次添加到新的Hash表ht[1],并把老Hash表中该键值对删除。把字典中字段rehashidx字段修改为Hash表ht[0]中正在进行rehash操作节点的索引值。
3)rehash操作后,清空ht[0],然后对调一下ht[1]与ht[0]的值,并把字典中rehashidx字段标识为-1。
Redis可以提供高性能的线上服务,而且是单进程模式,当数据库中键值对数量达到了百万、千万、亿级别时,整个rehash过程将非常缓慢,如果不优化rehash过程,可能会造成很严重的服务不可用现象。Redis优化的思想很巧妙,利用分而治之的思想了进行rehash操作,大致的步骤如下。
执行插入、删除、查找、修改等操作前,都先判断当前字典rehash操作是否在进行中,进行中则调用dictRehashStep函数进行rehash操作(每次只对1个节点进行rehash操作,共执行1次)。除这些操作之外,当服务空闲时,如果当前字典也需要进行rehsh操作,则会调用incrementallyRehash函数进行批量rehash操作(每次对100个节点进行rehash操作,共执行1毫秒)。在经历N次rehash操作后,整个ht[0]的数据都会迁移到ht[1]中,这样做的好处就把是本应集中处理的时间分散到了上百万、千万、亿次操作中,所以其耗时可忽略不计。
rehash的条件
- 服务器目前没有活动着的保存 RDB、AOF 重写或者 Redis 加载的模块派生的子进程,比如执行 BGSAVE 或者 BGREWRITEAOF 等命令时,并且负载因子大于等于 1,执行扩展操作。
- 如果存在(1)中所述的进程,比如服务器正在执行 BGSAVE 或者 BGREWRITEAOF 命令,并且负载因子大于等于 5,执行扩展操作。
- 哈希表的负载因子小于 0.1 时,会执行收缩操作。其中,哈希表的负载因子计算方式为:load_factor = ht[0].used / ht[0].size。
List数据结构
在低版本的Redis中,list采用的底层数据结构是ziplist+linkedList;高版本的Redis中底层数据结构是quicklist(它替换了ziplist+linkedList),而quicklist也用到了ziplist。quicklist 实际上是 zipList 和 linkedList 的混合体,它将 linkedList按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。这么做的主要原因是,当元素长度较小时,采用ziplist可以有效节省存储空间,但ziplist的存储空间是连续的,当元素个数比较多时,修改元素时,必须重新分配存储空间,这无疑会影响Redis的执行效率,故而采用一般的双向链表。
配置如下:
127.0.0.1:6379> CONFIG GET list*
1) "list-max-ziplist-size"
2) "-2"
3) "list-compress-depth"
4) "0"
127.0.0.1:6379> LPUSH key redis
(integer) 1
127.0.0.1:6379> object encoding key
"quicklist"
127.0.0.1:6379> LPUSH key mongo
(integer) 2
127.0.0.1:6379> object encoding key
"quicklist"
127.0.0.1:6379>
(1) ziplist压缩配置:list-compress-depth 0
表示一个quicklist两端不被压缩的节点个数。这里的节点是指quicklist双向链表的节点,而不是指ziplist里面的数据项个数。
参数list-compress-depth的取值含义如下:
0: 是个特殊值,表示都不压缩。这是Redis的默认值。
1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
依此类推…
由于 0 是个特殊值,很容易看出 quicklist 的头节点和尾节点总是不被压缩的,以便于在表的两端进行快速存取。Redis 对于 quicklist 内部节点的压缩算法,采用的 LZF (一种无损压缩算法)。
(2) ziplist中entry配置:list-max-ziplist-size -2
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,
每个值含义如下:
-5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
-4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
-3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
-2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
-1: 每个quicklist节点上的ziplist大小不能超过4 Kb
quicklist
源码如下:
//quicklistNode是quicklist中的一个节点,其结构如下:
typedef struct quicklistNode {
struct quicklistNode *prev; //prev、next指向该节点的前后节点
struct quicklistNode *next;
unsigned char *zl; //zl指向该节点对应的ziplist结构
unsigned int sz; //sz代表整个ziplist结构的大小;
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */ //encoding代表采用的编码方式:1代表是原生的,2代表使用LZF进行压缩;
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */ //container为quicklistNode节点zl指向的容器类型:1代表none,2代表使用ziplist存储数据
unsigned int recompress : 1; /* was this node previous compressed? */ //recompress代表这个节点之前是否是压缩节点
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
// 被压缩的ziplist结构
typedef struct quicklistLZF {
/// 压缩后的ziplist大小
unsigned int sz; /* LZF size in bytes*/
// 是个柔性数组,存放被压缩后ziplist的字节数组
char compressed[];
} quicklistLZF;
//quicklist有如下几种核心结构:
typedef struct quicklist {
quicklistNode *head; //首节点
quicklistNode *tail; //尾结点
unsigned long count; /* total count of all entries in all ziplists */ //元数的总和
unsigned long len; /* number of quicklistNodes */ //quicklist Node(节点)个数
int fill : QL_FILL_BITS; //指明每个quicklistNode中ziplist长度
unsigned int compress : QL_COMP_BITS; //考虑quicklistNode节点个数较多时,我们经常访问的是两端的数据,为了进一步节省空间,Redis允许对中间的quicklistNode节点进行压缩,通过修改参数list-compress-depth进行配置
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
//quicklistIter是quicklist中用于遍历的迭代器
typedef struct quicklistIter {
const quicklist *quicklist; //quicklist指向当前元素所处的quicklist
quicklistNode *current; //current指向元素所在quicklistNode
unsigned char *zi; // zi指向元素所在的ziplist
long offset; //offset表明节点在所在的ziplist中的偏移量
int direction; //direction表明迭代器的方向
} quicklistIter;
//Redis提供了quicklistEntry结构以便于使用,当我们使用quicklistNode中ziplist中的一个节点时,Redis提供了quicklistEntry结构以便于使用,该结构如下:
typedef struct quicklistEntry {
const quicklist *quicklist; //quicklist指向当前元素所在的quicklist
quicklistNode *node; //node指向当前元素所在的quicklistNode结构
unsigned char *zi; //zi指向当前元素所在的ziplist
unsigned char *value; //value指向该节点的字符串内容
long long longval; //longval为该节点的整型值
unsigned int sz; //sz代表该节点的大小,与value配合使用
int offset; //offset表明该节点相对于整个ziplist的偏移量,即该节点是ziplist第多少个entry
} quicklistEntry;
quicklist是一个由ziplist充当节点的双向链表。quicklist的构建如图:
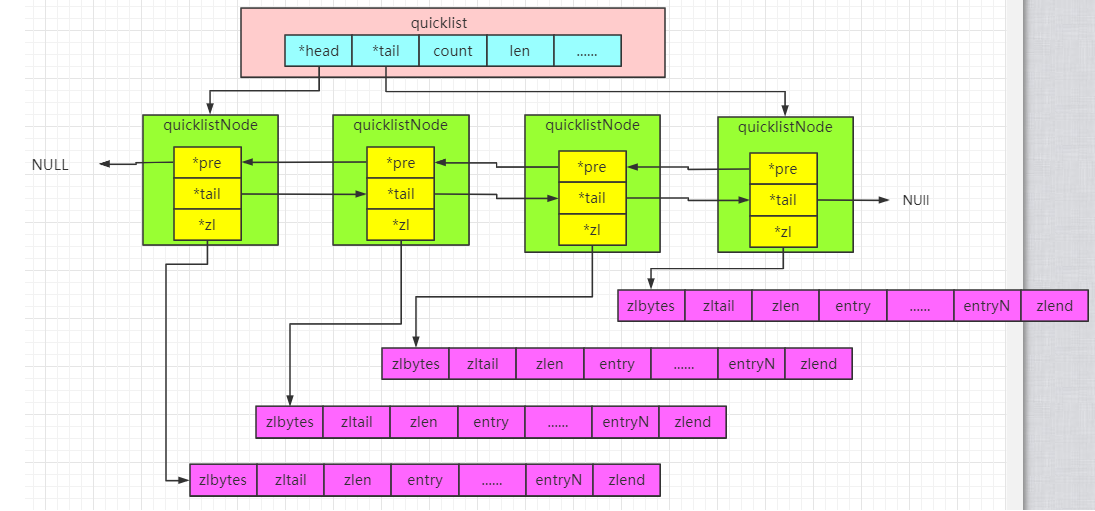
Set数据结构
Redis用intset或hashtable存储set。如果元素都是整数类型,就用intset存储。如果不是整数类型,就用hashtable(数组+链表的存来储结构)。key就是元素的值,value为null。如果一个集合全是整数,则使用字典过于浪费内存,为此,Redis专门设计了intset数据结构,专门用来保存整数集合数据。
在两种情况下,底层编码会发生转换。一种情况为当元素个数超过一定数量之后(默认值为512),即使元素类型仍然是整型,也会将编码转换为hashtable。另一种情况为当增加非整型变量时,例如在集合中增加元素’a’后,testSet的底层编码从intset转换为hashtable。
实验过程如下:
127.0.0.1:6379> CONFIG GET set*
1) "set-proc-title"
2) "yes"
3) "set-max-intset-entries"
4) "512"
127.0.0.1:6379> CONFIG SET set-max-intset-entries 3
OK
127.0.0.1:6379> CONFIG GET set*
1) "set-proc-title"
2) "yes"
3) "set-max-intset-entries"
4) "3"
127.0.0.1:6379> sadd set1 123
(integer) 1
127.0.0.1:6379> OBJECT encoding set1
"intset"
127.0.0.1:6379> sadd set1 a b c d
(integer) 4
127.0.0.1:6379> OBJECT encoding set1
"hashtable"
127.0.0.1:6379> sadd set3 1212
(integer) 1
127.0.0.1:6379> OBJECT encoding set3
"intset"
127.0.0.1:6379> sadd set3 121233
(integer) 1
127.0.0.1:6379> OBJECT encoding set3
"intset"
127.0.0.1:6379> sadd set3 12124343
(integer) 1
127.0.0.1:6379> OBJECT encoding set3
"intset"
127.0.0.1:6379> sadd set3 12124343545
(integer) 1
127.0.0.1:6379> OBJECT encoding set3
"hashtable"
127.0.0.1:6379>
intset
如果一个集合全部为整数,则使用字典过于浪费内存。为此redis设计了inset数据结构,专门用来保存整数数据集合。整数集合是 Redis 用来保存整数值的集合抽象数据结构,集合中不会出现重复的元素,并且是按值的大小从小到大有序地排列。
// 整数集合实现
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
- encoding 属性的值有 3 个
- INTSET_ENC_INT16:代表元素为 16 位的整数
- INTSET_ENC_INT32:代表元素为 32 位的整数
- INTSET_ENC_INT64:代表元素为 64 位的整数
-
length:元素个数。即一个intset中包括多少个元素。
-
contents 属性的类型声明为 int8_t,但它不保存任何 int8_t 类型的值,而是取决于 encoding 属性。

插入元素到intset源码如下:
/* Insert an integer in the intset */
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
//1.获取插入元数编码
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
//2.如果插入元数编码的级别高于intset编码,则需要升级intset编码格式
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
} else {
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
//。调用intsetSearch函数查找元素,使用的是典型的二分查找法
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}
//为intset重新分配内存空间,主要是分配插入元素所需空间
is = intsetResize(is,intrev32ifbe(is->length)+1);
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
//5.插入元素,更新length属性
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
升级
当整数集合中元素的类型都是 int16_t 类型的值时,如果你需要添加一个 int32_t 类型的整数,会发生什么呢?这时就会执行升级操作,来保证大类型可以被放入数组。升级可表述为以下几步:
- 按照升级后的类型和元素数量,分配内存空间。
- 将元素的类型升级为新元素的类型,在保证有序性不变的前提下,放在新的位置上。
- 将新元素添加到数组中(因为新元素的长度肯定最大,所以总是在头或尾两个位置上)
升级的好处,就是可以尽可能的节约内存,提升灵活性。
升级源码如下:
static intset * intsetUpgradeAndAdd(intset *is, int64_t value) {
uint8_t curenc = intrev32ifbe(is->encoding);
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
int prepend = value < 0 ? 1 : 0;
/* First set new encoding and resize */
//1.设置intest新的编码,并分配新的内存空间
is->encoding = intrev32ifbe(newenc);
is = intsetResize(is,intrev32ifbe(is->length)+1);
/* Upgrade back-to-front so we don't overwrite values.
* Note that the "prepend" variable is used to make sure we have an empty
* space at either the beginning or the end of the intset. */
//2.将intset的元素移动到新的位置上
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
/* Set the value at the beginning or the end. */
//插入新的元素
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
hashtable
上面已经描述过了,此处略过。
Zset数据结构
有序集合在生活中较常见,如根据成绩对学生进行排名、根据得分对游戏玩家进行排名等。对于有序集合的底层实现,我们可以使用数组、链表、平衡树等结构。数组不便于元素的插入和删除;链表的查询效率低,需要遍历所有元素;平衡树或者红黑树等结构虽然效率高但实现复杂。Redis采用了一种新型的数据结构——跳跃表。跳跃表的效率堪比红黑树,然而其实现却远比红黑树简单。
当有序集合中包含的元素数量超过服务器属性 server.zset_max_ziplist_entries 的值(默认值为 128 ),或者有序集合中新添加元素的 member 的长度大于服务器属性 server.zset_max_ziplist_value 的值(默认值为 64 )时,redis会使用跳跃表作为有序集合的底层实现,否则会使用ziplist作为有序集合的底层实现。
实验过程如下:
127.0.0.1:6379> CONFIG GET zset*
1) "zset-max-ziplist-entries"
2) "128"
3) "zset-max-ziplist-value"
4) "64"
127.0.0.1:6379> CONFIG SET zset-max-ziplist-entries 3
OK
127.0.0.1:6379> CONFIG SET zset-max-ziplist-value 6
OK
127.0.0.1:6379> CONFIG GET zset*
1) "zset-max-ziplist-entries"
2) "3"
3) "zset-max-ziplist-value"
4) "6"
127.0.0.1:6379> ZADD zset1 80 a 70 b 60 c
(integer) 3
127.0.0.1:6379> OBJECT encoding zset1
"ziplist"
127.0.0.1:6379> ZADD zset1 50 d
(integer) 1
127.0.0.1:6379> OBJECT encoding zset1
"skiplist"
127.0.0.1:6379> zadd zset2 80 aaaa
(integer) 1
127.0.0.1:6379> OBJECT encoding zset2
"ziplist"
127.0.0.1:6379> zadd zset2 80 aaaabbbbcc
(integer) 1
127.0.0.1:6379> OBJECT encoding zset2
"skiplist"
127.0.0.1:6379>
zset添加元素的主要逻辑位于t_zset.c的zaddGenericCommand函数中。zset插入第一个元素时,会判断下面两种条件:
- zset-max-ziplist-entries的值是否等于0;
- zset-max-ziplist-value小于要插入元素的字符串长度。满足任一条件Redis就会采用跳跃表作为底层实现,否则采用压缩列表作为底层实现方式。
一般情况下,不会将zset-max-ziplist-entries配置成0,元素的字符串长度也不会太长,所以在创建有序集合时,默认使用压缩列表的底层实现。当满足任一条件时,Redis便会将zset的底层实现由压缩列表转为跳跃表。代码如下。
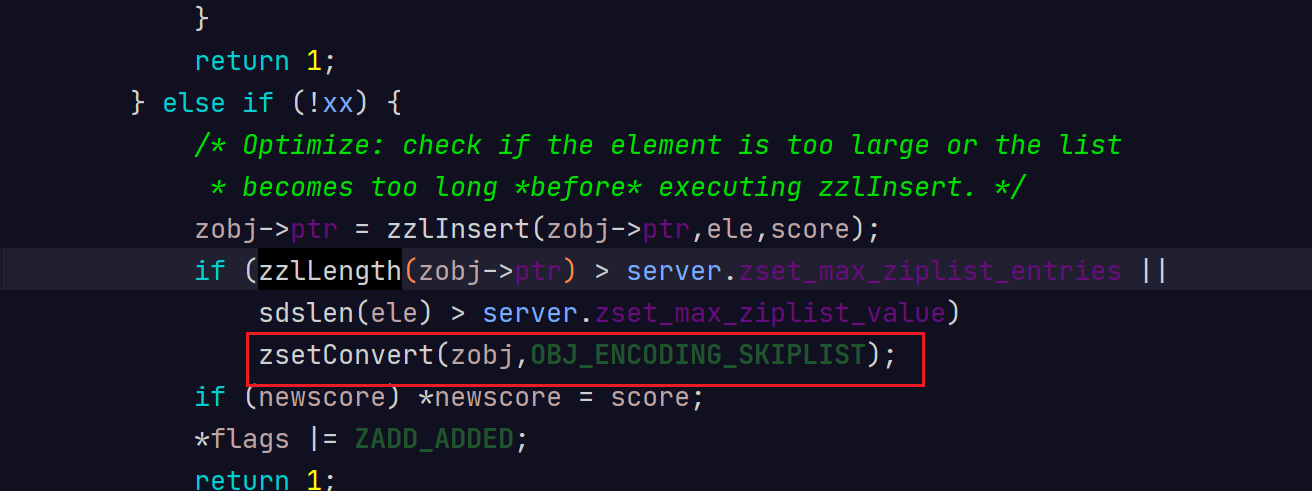
ziplist
上面已经描述过了,此处略过。
skiplist
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,来达到快速访问节点的目的。相比平衡树,其实现简单,而且在大部分情况下的效率能和平衡树相媲美。它具有下面的特点;
- 上层链表是相邻下层链表的子集
- 头节点层数小于其他节点的层数
- 每个节点都有一个随机的层数
它的源码定义如下:
/* ZSETs use a specialized version of Skiplists */typedef struct zskiplistNode {
sds ele; //用于存储字符串类型的数据
double score; //用于存储排序的分值
struct zskiplistNode *backward; //后退指针,只能指向当前节点最底层的前一个节点,头节点和第一个节点——backward指向NULL,从后向前遍历跳跃表时使用。
//随机层
struct zskiplistLevel {
struct zskiplistNode *forward; //指向本层下一个节点,尾节点的forward指向NULL
unsigned long span; //forward指向的节点与本节点之间的元素个数。span值越大,跳过的节点个数越多。
} level[];
} zskiplistNode;
//跳跃表节点链表
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //header:指向跳跃表头节点。 //tail:指向跳跃表尾节点。
unsigned long length; //跳跃表长度,表示除头节点之外的节点总数。
int level; //跳跃表的高度。
} zskiplist;
多个跳跃表节点组成了跳跃表,程序可以以 O(1) 的时间复杂度获取表头、表尾指针以及节点的数量;跳跃表中以 score 属性的大小进行排序,score 相同,则以成员 ele 属性的字典序排列;新增节点的层数根据幂次定律取得一个介于 1 和 32 之间的值。
下面为它的结构图:
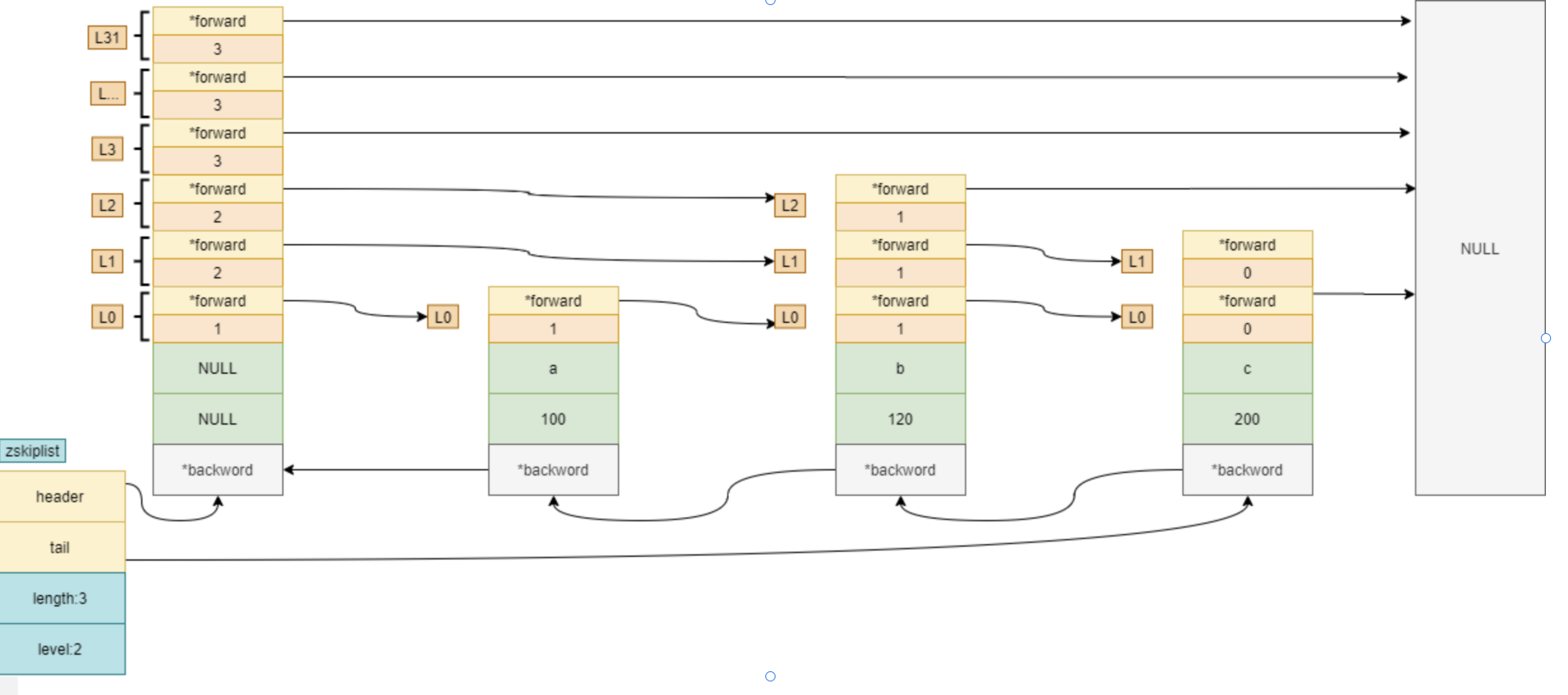
1)跳跃表由很多层构成。
2)跳跃表有一个头(header)节点,头节点中有一个64层的结构,每层的结构包含指向本层的下个节点的指针,指向本层下个节点中间所跨越的节点个数为本层的跨度(span)。
3)除头节点外,层数最多的节点的层高为跳跃表的高度(level),图3-3中跳跃表的高度为3。
4)每层都是一个有序链表,数据递增。
5)除header节点外,一个元素在上层有序链表中出现,则它一定会在下层有序链表中出现。
6)跳跃表每层最后一个节点指向NULL,表示本层有序链表的结束。
7)跳跃表拥有一个tail指针,指向跳跃表最后一个节点。
8)最底层的有序链表包含所有节点,最底层的节点个数为跳跃表的长度(length)(不包括头节点),图3-3中跳跃表的长度为7。
9)每个节点包含一个后退指针,头节点和第一个节点指向NULL;其他节点指向最底层的前一个节点。
跳跃表每个节点维护了多个指向其他节点的指针,所以在跳跃表进行查找、插入、删除操作时可以跳过一些节点,快速找到操作需要的节点。归根结底,跳跃表是以牺牲空间的形式来达到快速查找的目的。跳跃表与平衡树相比,实现方式更简单,只要熟悉有序链表,就可以轻松地掌握跳跃表。值得注意的是,zset在转为跳跃表之后,即使元素被逐渐删除,也不会重新转为压缩列表。
优点:
- skiplist没有过度占用内存,内存使用率在合理范围内。
- 有序集合常常需要执行ZRANGE或者ZREVRANGE等遍历操作,使用skiplist可以更高效的实现这些操作
- skiplist实现简单
痛点:
- 跳表是一个最典型的空间换时间解决方案,而且只有在数据量较大的情况下才能体现出来优势。而且应该是读多写少的情况下才能使用,所以它的适用范围应该还是比较有限的
- 维护成本相对要高 - 新增或者删除时需要把所有索引都更新一遍;最后在新增和删除的过程中的更新,时间复杂度也是O(log n)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号