Redis的字符串源码
Redis的字符串源码
1.字符串的原理
1.1 SDS的介绍
什么是二进制安全?通俗地讲,C语言中,用“\0”表示字符串的结束,如果字符串中本身就有“\0”字符,字符串就会被截断,即非二进制安全;若通过某种机制,保证读写字符串时不损害其内容,则是二进制安全。redis就重新设计了动态的字符串SDS。
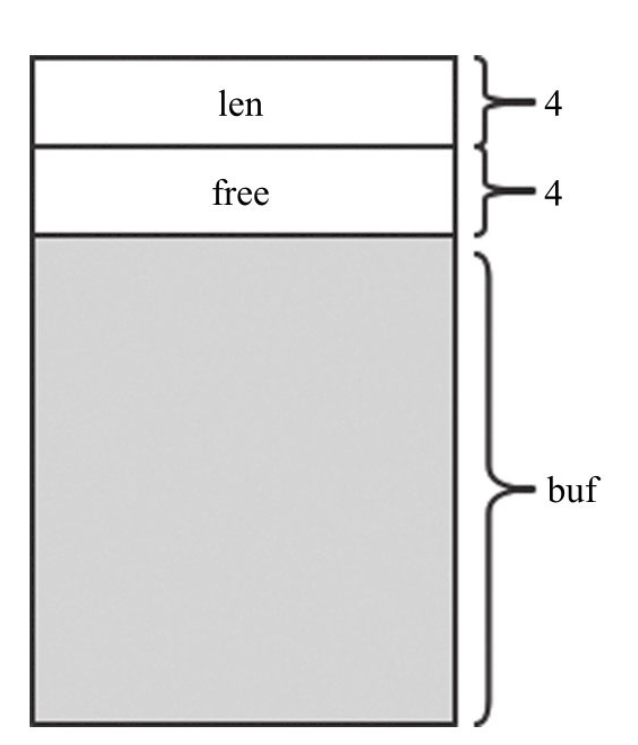
3.2版本是这样设计的,优点如下:
字段len和字段free各占4个字节,紧接着存放字符串。
1)有单独的统计变量len和free(称为头部)。可以很方便地得到字符串长度。
2)内容存放在柔性数组buf中,SDS对上层暴露的指针不是指向结构体SDS的指针,而是直接指向柔性数组buf的指针。上层可像读取C字符串一样读取SDS的内容,兼容C语言处理字符串的各种函数。
3)由于有长度统计变量len的存在,读写字符串时不依赖“\0”终止符,保证了二进制安全。
之所以用柔性数组存放字符串,是因为柔性数组的地址和结构体是连续的,这样查找内存更快(因为不需要额外通过指针找到字符串的位置);可以很方便地通过柔性数组的首地址偏移得到结构体首地址,进而能很方便地获取其余变量。
但是会浪费资源,具体原因如下:
不同长度的字符串是否有必要占用相同大小的头部?一个int占4字节,在实际应用中,存放于Redis中的字符串往往没有这么长,每个字符串都用4字节存储未免太浪费空间了。我们考虑三种情况:短字符串,len和free的长度为1字节就够了;长字符串,用2字节或4字节;更长的字符串,用8字节。
为了解决上面的问题,于是就这样设计了
5种类型(长度1字节、2字节、4字节、8字节、小于1字节)的SDS至少要用3位来存储类型(23=8),1个字节8位,剩余的5位存储长度,可以满足长度小于32的短字符串。我们用如下结构来存储长度小于32的短字符串:
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used 已使用长度,用2个字节存储*/
uint16_t alloc; /* excluding the header and null terminator 总长度,用2个字节存储*/
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
sdshdr5结构中,flags占1个字节,其低3位(bit)表示type,高5位(bit)表示长度,能表示的长度区间为0~31), flags后面就是字符串的内容。
sdshdr5、(2^5=32byte)
sdshdr8、(2 ^ 8=256byte)
sdshdr16、(2 ^ 16=65536byte=64KB)
sdshdr32、 (2 ^ 32byte=4GB)
sdshdr64,2的64次方byte=17179869184G用于存储不同的长度的字符串。
1)len:表示buf中已占用字节数。
2)alloc:表示buf中已分配字节数,不同于free,记录的是为buf分配的总长度。
3)flags:标识当前结构体的类型,低3位用作标识位,高5位预留。
4)buf:柔性数组,真正存储字符串的数据空间。
1.2 SDS的操作
释放
为了优化性能(减少申请内存的开销), SDS提供了不直接释放内存,而是通过重置统计值达到清空目的的方法——sdsclear。该方法仅将SDS的len归零,此处已存在的buf并没有真正被清除,新的数据可以覆盖写,而不用重新申请内存。
void sdsclear(sds s) {
sdssetlen(s, 0); //统计值len归零
s[0] = '\0'; //清空buf
}
拼接
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len); //直接拼接,保证二进制安全
sdssetlen(s, curlen+len);
s[curlen+len] = '\0'; //加上结束符
return s;
}
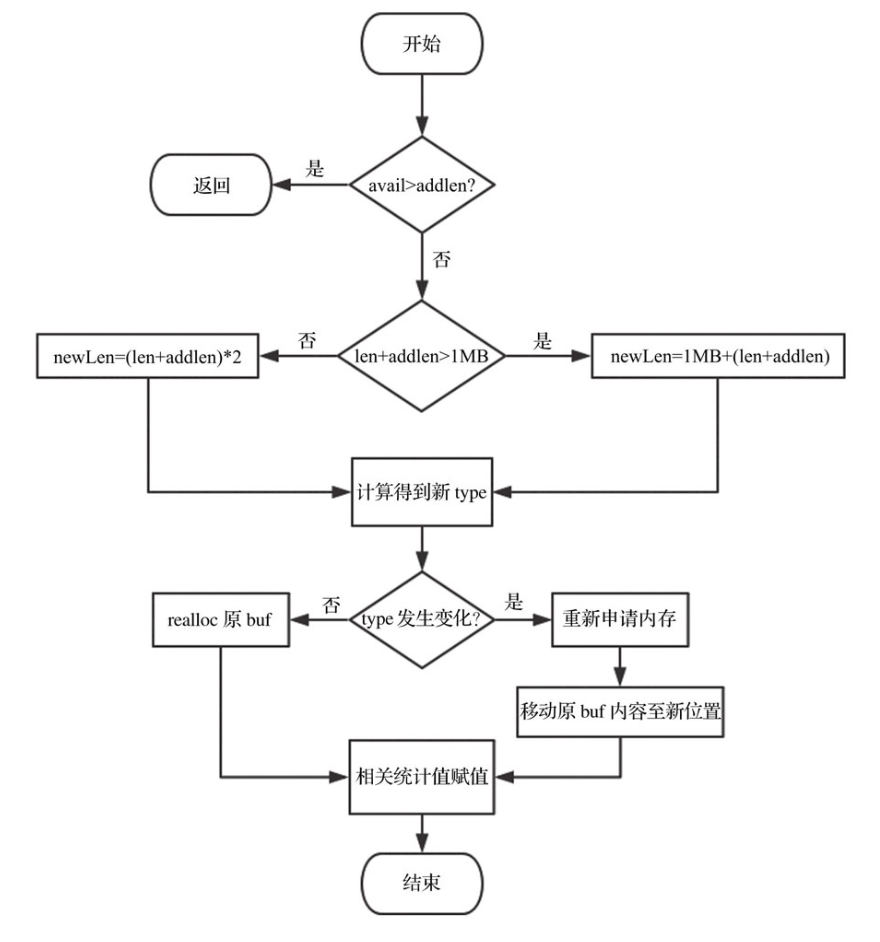
调用了sdsMakeRoomFor函数,源码如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
//获取当前空间的长度
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
//1.若sds中剩余空闲长度avail大于新增内容的长度addlen,直接在柔性数组buf末尾追加即可,无须扩容
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s; //无需扩容,直接返回s
//2. 若sds中剩余空闲长度avail小于或等于新增内容的长度addlen,则分情况讨论:新增后总长度len+addlen<1MB的,按新长度的2倍扩容;新增后总长度len+addlen>1MB的,按新长度加上1MB扩容
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
//3)最后根据新长度重新选取存储类型,并分配空间。此处若无须更改类型,通过realloc扩大柔性数组即可;否则需要重新开辟内存,并将原字符串的buf内容移动到新位置。
//强制把type5转成type8
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
//无需更改类型
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) {
s_free(sh);
return NULL;
}
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
//更新alloc属性
sdssetalloc(s, newlen);
return s;
}
2.字符串的源码
源码
具体的源码如下
/* Try to encode a string object in order to save space */
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
/* Make sure this is a string object, the only type we encode
* in this function. Other types use encoded memory efficient
* representations but are handled by the commands implementing
* the type. */
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
/* We try some specialized encoding only for objects that are
* RAW or EMBSTR encoded, in other words objects that are still
* in represented by an actually array of chars. */
if (!sdsEncodedObject(o)) return o;
/* It's not safe to encode shared objects: shared objects can be shared
* everywhere in the "object space" of Redis and may end in places where
* they are not handled. We handle them only as values in the keyspace. */
//如果数据对象被多处引用,不能再进行编码操作
if (o->refcount > 1) return o;
/* Check if we can represent this string as a long integer.
* Note that we are sure that a string larger than 20 chars is not
* representable as a 32 nor 64 bit integer. */
//获取长度,
len = sdslen(s);
//如果字符串长度小于或等于20
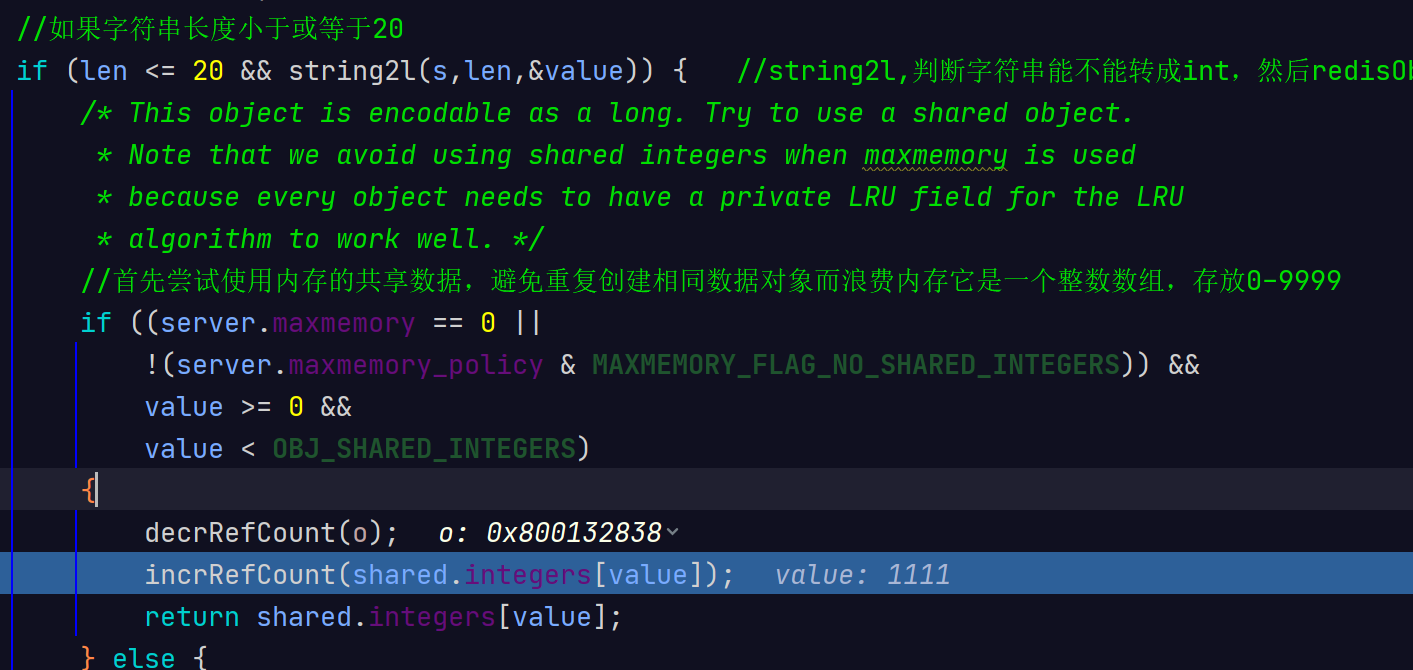
if (len <= 20 && string2l(s,len,&value)) { //string2l,判断字符串能不能转成int,然后redisObject的指针指向这个value的值
/* This object is encodable as a long. Try to use a shared object.
* Note that we avoid using shared integers when maxmemory is used
* because every object needs to have a private LRU field for the LRU
* algorithm to work well. */
//首先尝试使用内存的共享数据,避免重复创建相同数据对象而浪费内存它是一个整数数组,存放0-9999
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
//如果发现不能使用共享数据,并且原编码格式为RAW的,则换成数值类型
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
//如果发现不能使用共享数据,并且原编码格式为EMBSTR的,则会创建新的redisObject,编码为OBJ_ENCODING_INT,ptr指向longlong类型
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o);
return createStringObjectFromLongLongForValue(value);
}
}
}
/* If the string is small and is still RAW encoded,
* try the EMBSTR encoding which is more efficient.
* In this representation the object and the SDS string are allocated
* in the same chunk of memory to save space and cache misses. */
//尝试转成OBJ_ENCODING_EMBSTR,如果字符串长度小于等于OBJ_ENCODING_EMBSTR_SIZE_LIMIT,定义为44,
// 那么调用createEmbeddedStringObject将encoding改为OBJ_ENCODING_EMBSTR;对象分配在同一块连续的内存空间,
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
/* We can't encode the object...
*
* Do the last try, and at least optimize the SDS string inside
* the string object to require little space, in case there
* is more than 10% of free space at the end of the SDS string.
*
* We do that only for relatively large strings as this branch
* is only entered if the length of the string is greater than
* OBJ_ENCODING_EMBSTR_SIZE_LIMIT. */
//说明只能使用RAW编码,此时动态字符串sds的内存与其依赖的redisObject的内存不再连续了
trimStringObjectIfNeeded(o);
/* Return the original object. */
return o;
}
一开始执行set命令的时候,字符串如下:

外面还嵌套while循环,取解析set wgr 1111这3个字符串,这3个会被封装redisObject对象,那个时候就已经能知道它的encoding,后面会根据这个进行判断,选择不同的类型
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
上面源码会在setCommand处被调用
如果是数值型,小于9999,走如下代码:
如果是数值型,大于9999,走如下代码:
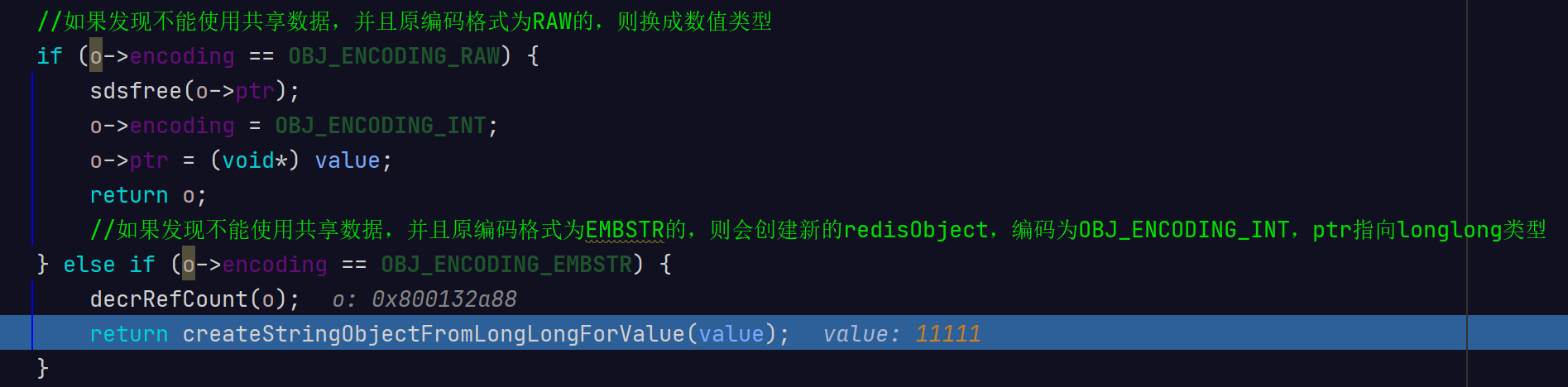
当字符串的键值为长度小于44的超长字符串时
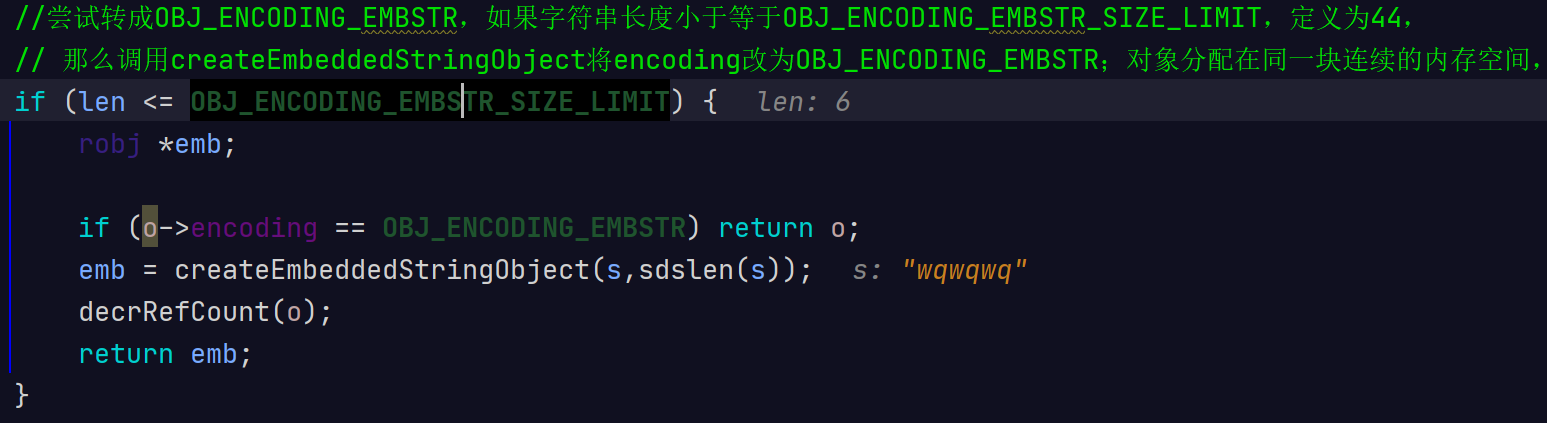
当字符串的键值为长度大于44的超长字符串时

注:此处的44是怎么得来的,是因为缓存行一般为64个字节,当我们拿到redisObject对象的时候,type占4个bit位,encoding占4个bit位,lru占3个字节,ptr占8个字节,refcount为8个字节,选择为16个字节,剩下48个字节,按照字符串类型,应该是sdshdr8,它本身还要4个字节存储元数据信息。这样的话,就可以把数据和redisobject存储在一起,减少一次内存的io。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号