面试题:你知道跳表吗
ConcurrentSkipListMap基础介绍
很明显它底层是以跳表为基础结构的map集合,并且同时支持并发操作,大家应该都知道支持并发最出名的map应该是ConcurrentHashMap,那么它相比于ConcurrentHashMap有什么优点呢?通过前面学习我们知道跳表是一个有序的链表,而ConcurrentSkipListMap底层是跳表结构,所以很明显他比ConcurrentHashMap最大的优势应该就是有序。
底层数据结构介绍
那么ConcurrentSkipListMap是如何以跳表的数据结构实现map的呢,要想了解这些就必须先弄清楚他底层的数据结构以及组成的方式,底层数据结构的关键类以及组成结构介绍如下图:
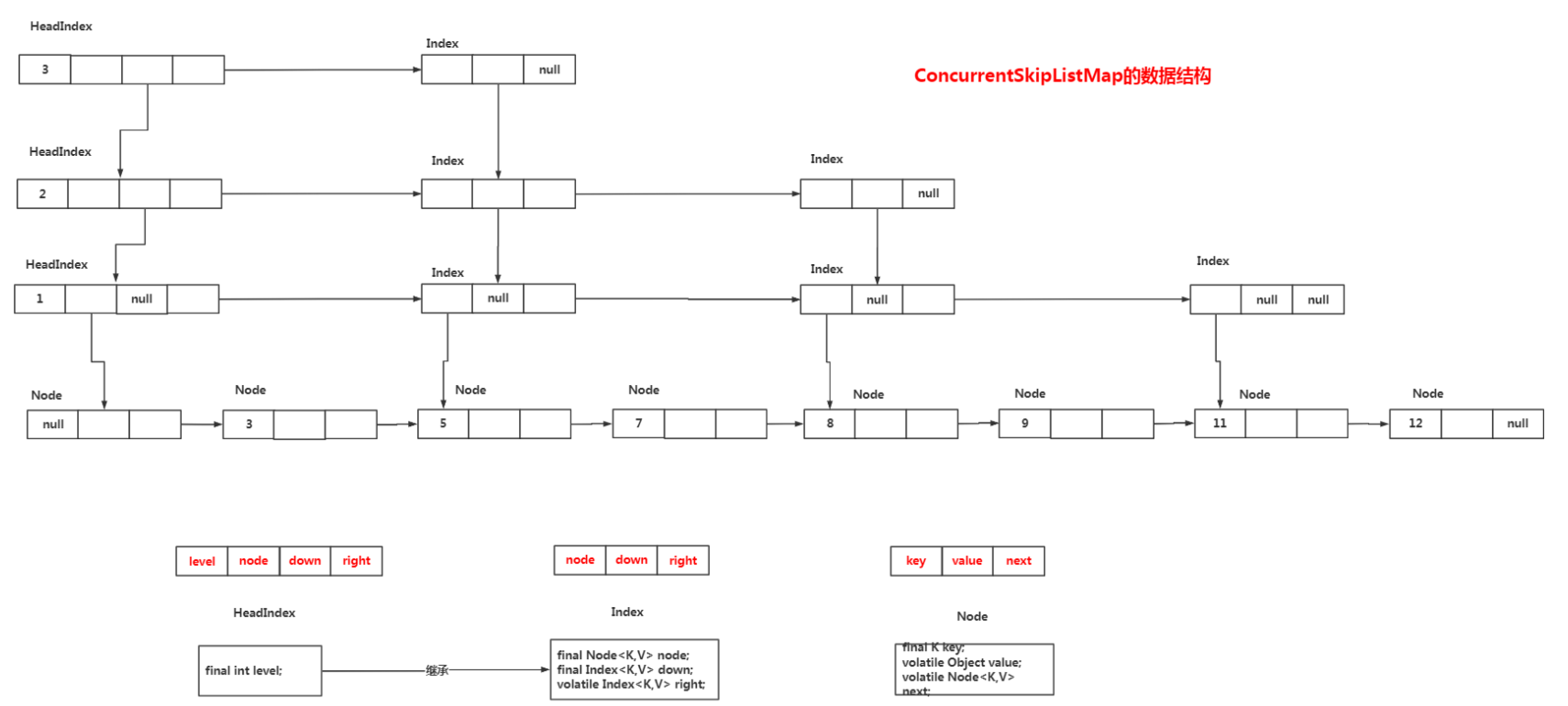
整体结构如上图,主要包含Index、HeadIndex、Node三个内部类,简单介绍下他们:
Index:有三个属性node、 down、right,node指向的是具体保存的数据节点,down和right分别指向右和下,ConcurrentSkipListMap中有这个类来组成跳表的网结构;
HeadIndex:继承至Index,多了一个属性level,它处在跳表网结构最前面一个,表示是每层链表的头结点,多一个level属性在后面跳表操作中有大用处;
Node:node是真正保存数据的结构,有三个属性key、value、next,key和value分别为put进来的key和value,next表示下一个节点。
综上ConcurrentSkipListMap是通过Node来保存数组并且形成最完整数据的链表结构,通过Index、HeadIndex来组成跳表的网结构,结构中每个节点保存一个Node可以指向完整链表中一个节点。
findPredecessor方法分析
在分析其他几个方法之前一定要提这个方法,在上一篇用Java实现跳表的文章中也有这个方法(实际上是我抄这里实现的),这里这个方法的作用以上一个差不多,具体源码如下图:
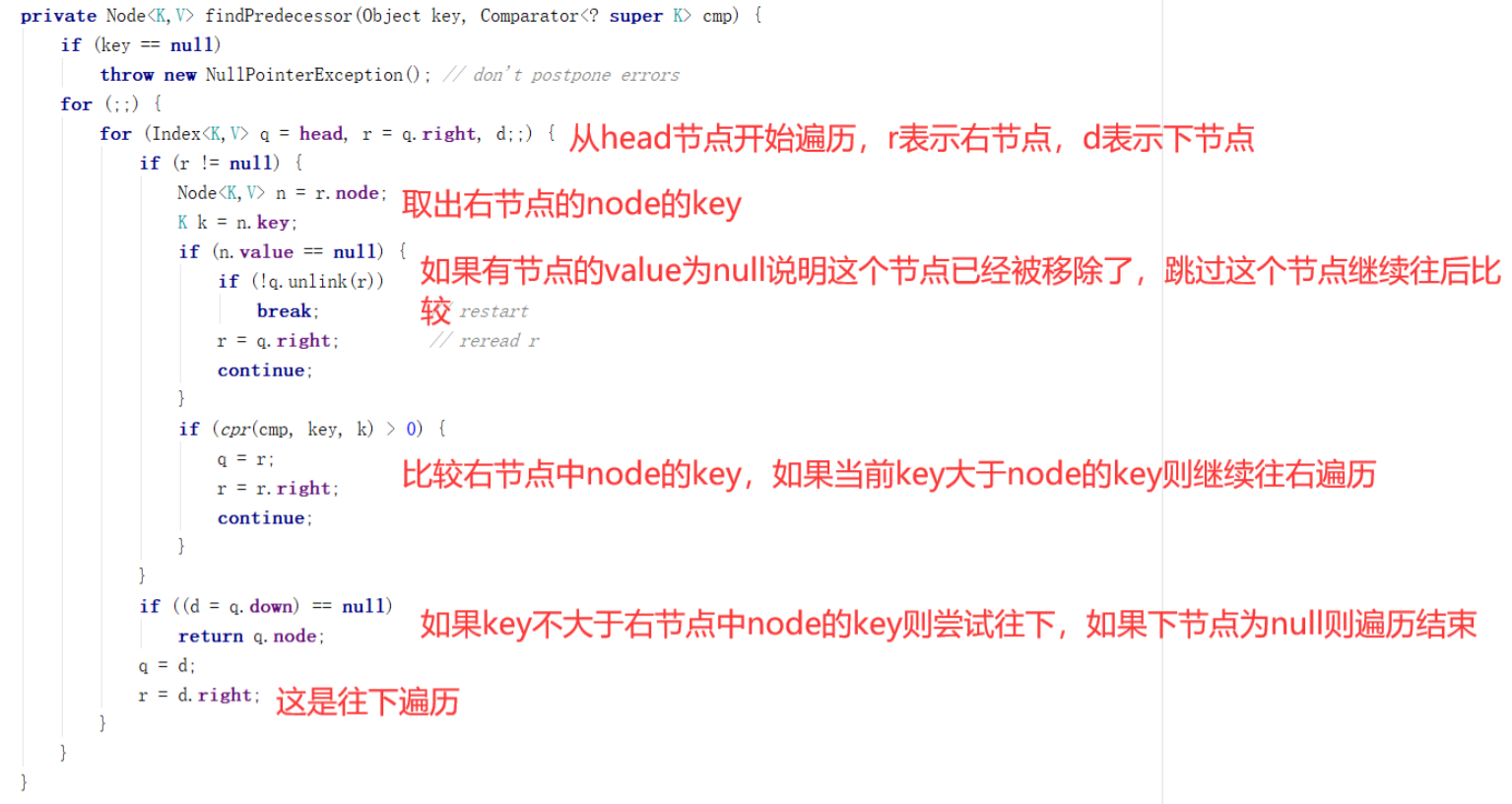
这个方法就是从左到右从上到下的遍历Index组成的跳表网结构,找到前置Index,所谓的前置Index的意思是这个Index的右节点中的key小于等于传进来key,也就是说findPredecessor方法返回的node是在Index网中能够找到的最大但小于当前key的node了。也就是findPredecessor返回的node是在Index能够找到在完整链表中最接近的key了。
findPredecessor还有一个作用是清理无效的index,可以看上图其中有一步如果node中的value等于null则会调用unlink把无用的Index从链表中移除。
put方法分析
通过上一篇跳表的学习,可以得出put方法主要分两步:
1、找到key在完整链表中的位置,然后put进去;
2、判断是否升级,如果升级就把升级节点添加到跳表网中;
先来分析第一步,和之前跳表实现一样,只要弄懂了findPredecessor方法之后,其他方法就简单多了,put方法也是通过调用findPredecessor获取到能够获取的在完整链表中最接近的Node,然后往后遍历,如果右节点中的key大于插入的key或者为null则new一个Node作为当前节点的右节点,老的右节点作为新节点的右节点,这样新节点就成功加入到链表中了,源码中代码很长主要是考虑线程安全问题,利用两层for循环、多次验证、CAS修改来保证,这里就不贴出来了。
然后是第二步就是跳表结构的升级,ConcurrentSkipListMap中跳表网的升级分为两步:
1、随机获取升级的层数,然后创建每一层的Index节点,先组成竖向链表;
2、把竖向链表中每个节点添加到横向链表中对应的位置;
第一步的源码分析如下图:
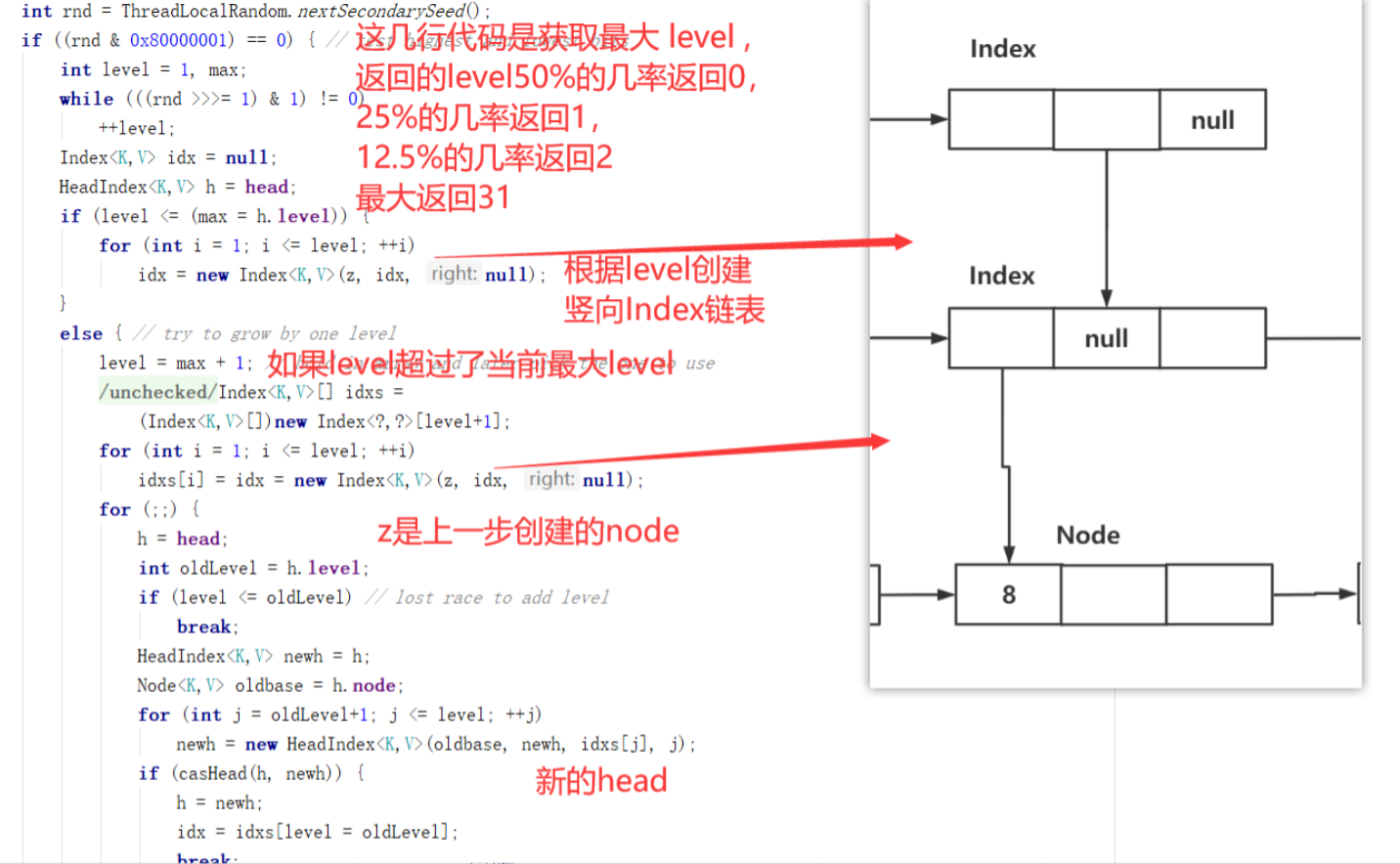
比如如上图如果在插入key等于8这个节点时的升级,这一步通过随机出来的level和第一步创建的node(图中的z)组成上图右侧的Index链表结构,Index中的node都指向最底层的Node对象。
第二步就是把上一步创建的竖向Index链表链接到跳表网中去,具体源码如下图:
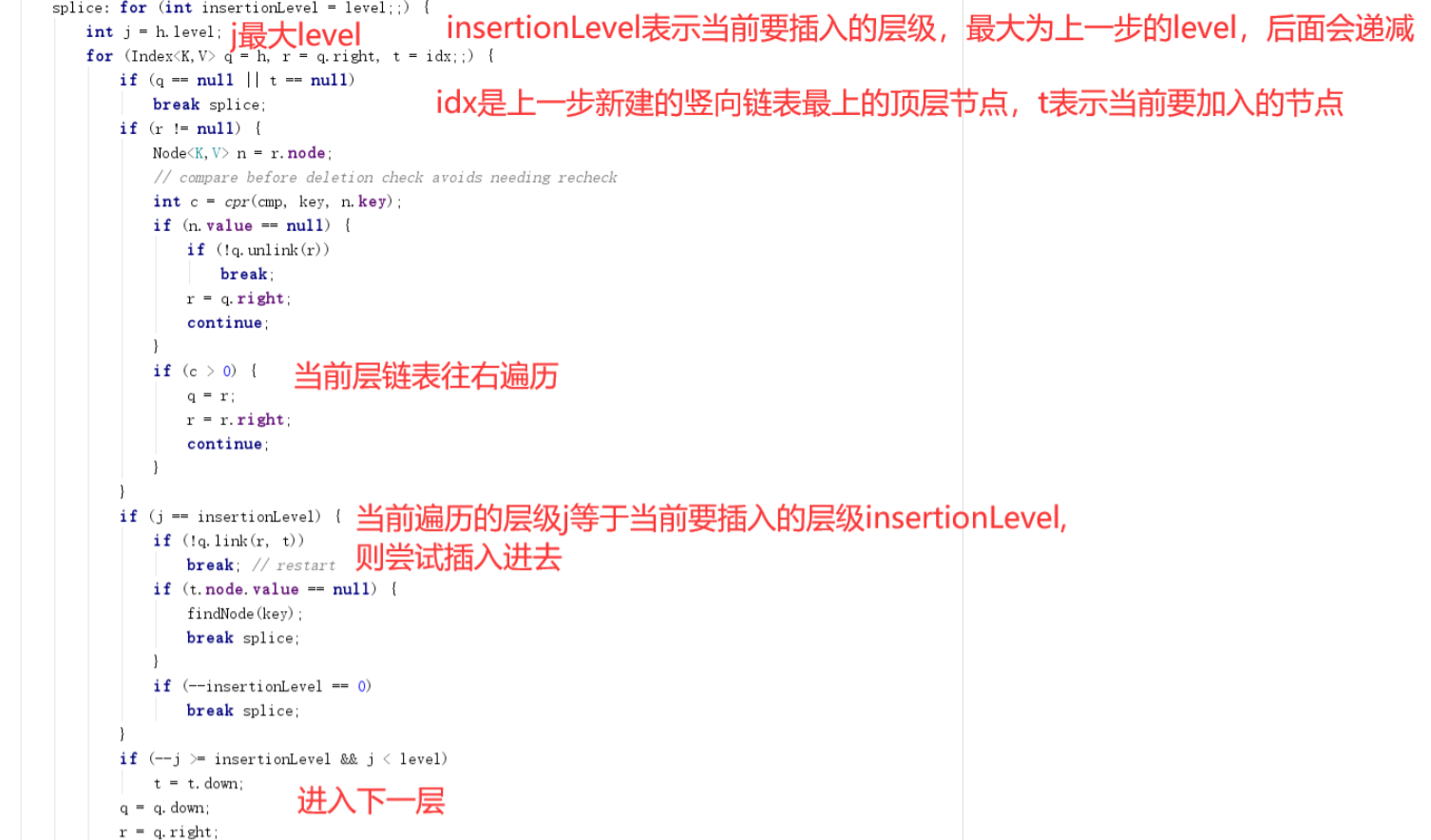
这里实际上最主要过程是从head开始从右和下找到上一步创建的最顶层的节点应该插入的位置,然后插入链表,然后往下再次插入下一个,整体还是比较简单的,代码复杂还是因为线程安全问题。
删除方法
有了findPredecessor方法get方法比较简单就不在赘述了,直接来看删除方法,几个remove方法底层依赖doRemove方法,我们直接看doRemove方法源码如下图:
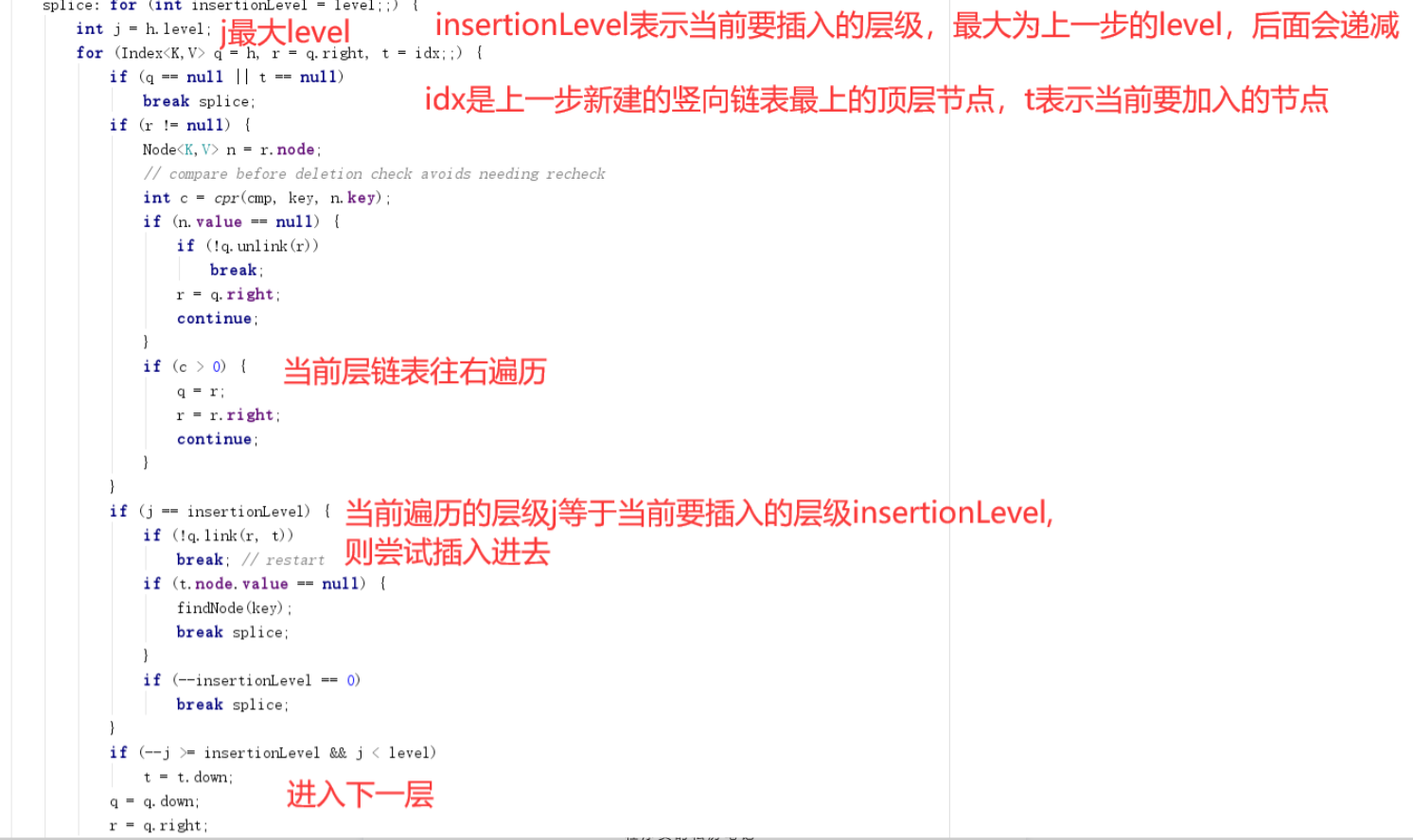
删除方法还是比较简单的,实际上就只有两步:找到key对应的node、把node中的value设置null,实际上到这里就成功了,在ConcurrentSkipListMap中很多代码在发现node的value为null都会尝试把它移除的。
总结
ConcurrentSkipListMap因为是保存的一对键值对,所以要用专门的一个类Node来保存,反而实现起来比我实现的跳表用到的算法简单很多,用Node来保存数据并组成完整数据的链表,并且这个链表相对独立,并不参与构建跳表结构。
通过Index来实现跳表结构,每个Index都保存一个Node,每个竖向的链表都指向底层链表中同一个node引用,所以删除方法只要把node中的value设置为null,当其他线程遍历到持有这个Node的Index时发现value为null,就移除Index,通过这样设计删除算法就简单了很多。
原文链接:https://kuaibao.qq.com/s/20201026A036DH00?refer=cp_1026

 浙公网安备 33010602011771号
浙公网安备 33010602011771号