Loki
一、概述

背景
Loki的第一个稳定版本于2019年11月19日发布,是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。 Grafana 对 Loki 的描述如下:
Loki: like Prometheus, but for logs. Loki is a horizontally-scalable, highly-available, multi-tenant log aggregation system inspired by Prometheus. It is designed to be very cost effective and easy to operate. It does not index the contents of the logs, but rather a set of labels for each log stream.
简单说,Loki 是专门用于聚集日志数据,重点是高可用性和可伸缩性。与竞争对手不同的是,它确实易于安装且资源效率极高。
血衫目前运维大概上百个节点,虽然系统是统一的基线版本且使用docker运行应用,平时相安无事,但变更后的问题排查仍有点心有余悸。对一个火热的日志系统elk也有浅尝辄止,奈何对于非核心应用,多耗散一份算力意味着成本增加和利润的减少,elk对于小团队来说,还是过于笨重。趁着近日的疫情无法外出,调研后将 Loki 上线了生产,可以说是完美契合了中小团队对日志平台的需求。
介绍
与其他日志聚合系统相比,Loki具有下面的一些特性:
- 不对日志进行全文索引(vs ELK技)。通过存储压缩非结构化日志和仅索引元数据,Loki 操作起来会更简单,更省成本。
- 通过使用与 Prometheus 相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率更高。
- 特别适合储存 Kubernetes Pod 日志; 诸如 Pod 标签之类的元数据会被自动删除和编入索引。
- 受 Grafana 原生支持。
Loki 由以下3个部分组成:
loki是主服务器,负责存储日志和处理查询。promtail是代理,负责收集日志并将其发送给 loki 。Grafana用于 UI 展示。
ELK存在的问题
现有的很多日志采集的方案都是采用全文检索对日志进行索引(如ELK方案),优点是功能丰富,允许复杂的操作。但是,这些方案往往规模复杂,资源占用高,操作苦难。很多功能往往用不上,大多数查询只关注一定时间范围和一些简单的参数(如host、service等),使用这些解决方案就有点杀鸡用牛刀的感觉了。!
因此,Loki的第二个目的是,在查询语言的易操作性和复杂性之间可以达到一个权衡。
成本
全文检索的方案也带来成本问题,简单的说就是全文搜索(如ES)的倒排索引的切分和共享的成本较高。后来出现了其他不同的设计方案如:OKlog(https://github.com/oklog/oklog),采用最终一致的、基于网格的分布策略。这两个设计决策提供了大量的成本降低和非常简单的操作,但是查询不够方便。因此,Loki的第三个目的是,提高一个更具成本效益的解决方案。
整体架构
Loki的架构如下:
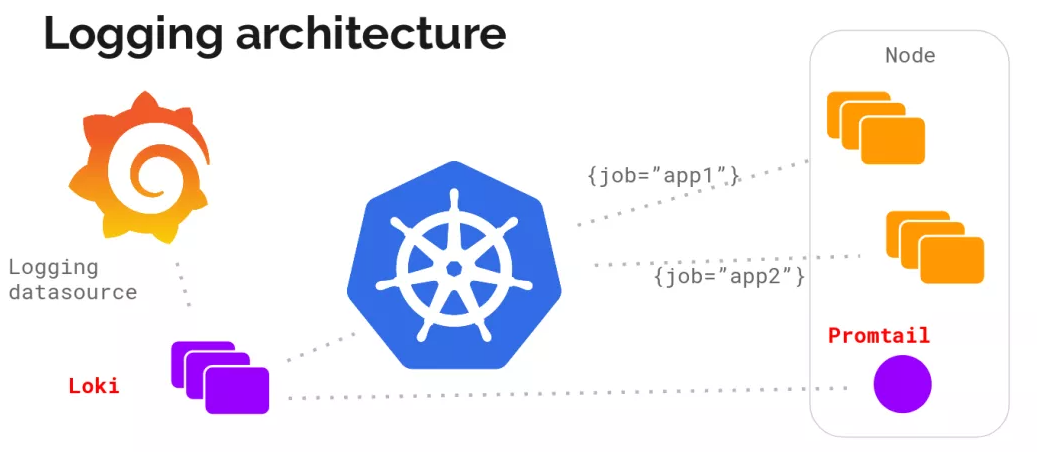
不难看出,Loki的架构非常简单,使用了和prometheus一样的标签来作为索引,也就是说,你通过这些标签既可以查询日志的内容也可以查询到监控的数据,不但减少了两种查询之间的切换成本,也极大地降低了日志索引的存储。Loki将使用与prometheus相同的服务发现和标签重新标记库,编写了pormtail, 在k8s中promtail以daemonset方式运行在每个节点中,通过kubernetes api等到日志的正确元数据,并将它们发送到Loki。下面是日志的存储架构:
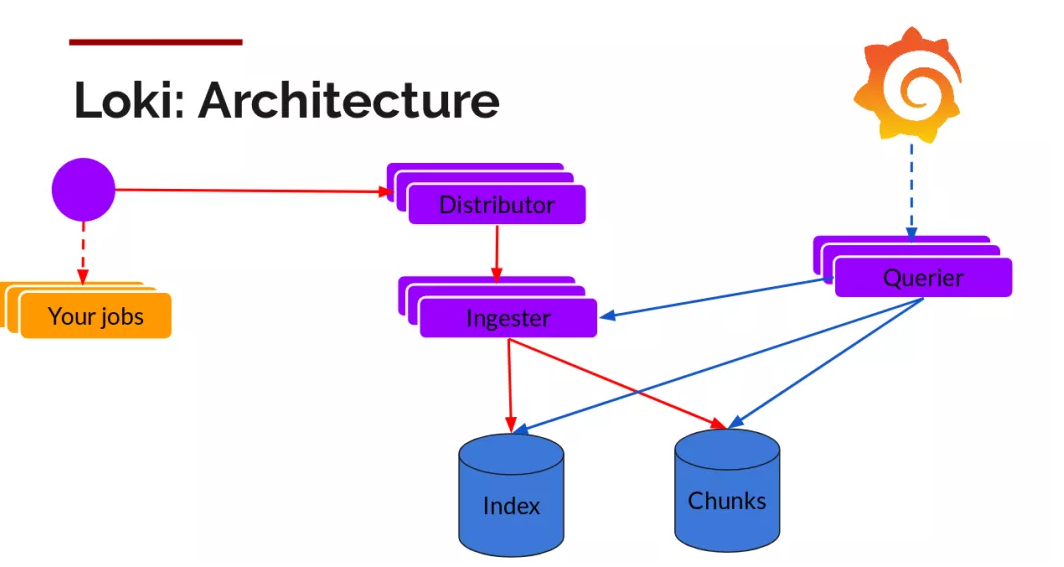
读写
日志数据的写主要依托的是Distributor和Ingester两个组件,整体的流程如下:
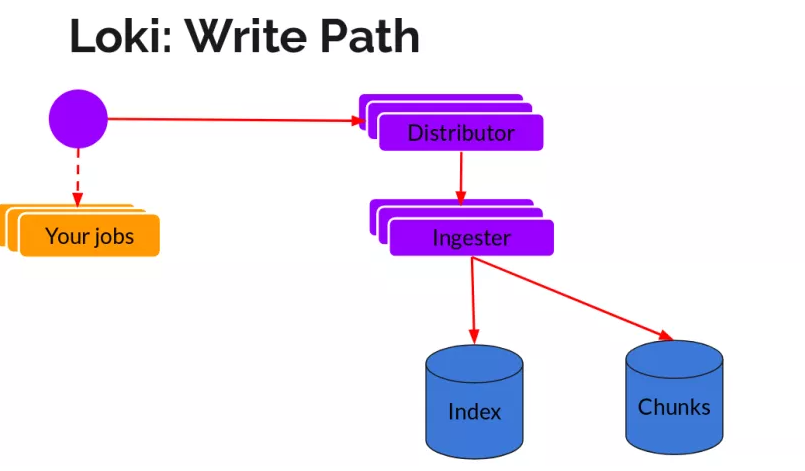
Distributor
一旦promtail收集日志并将其发送给loki,Distributor就是第一个接收日志的组件。由于日志的写入量可能很大,所以不能在它们传入时将它们写入数据库。这会毁掉数据库。我们需要批处理和压缩数据。
Loki通过构建压缩数据块来实现这一点,方法是在日志进入时对其进行gzip操作,组件ingester是一个有状态的组件,负责构建和刷新chunck,当chunk达到一定的数量或者时间后,刷新到存储中去。每个流的日志对应一个ingester,当日志到达Distributor后,根据元数据和hash算法计算出应该到哪个ingester上面。
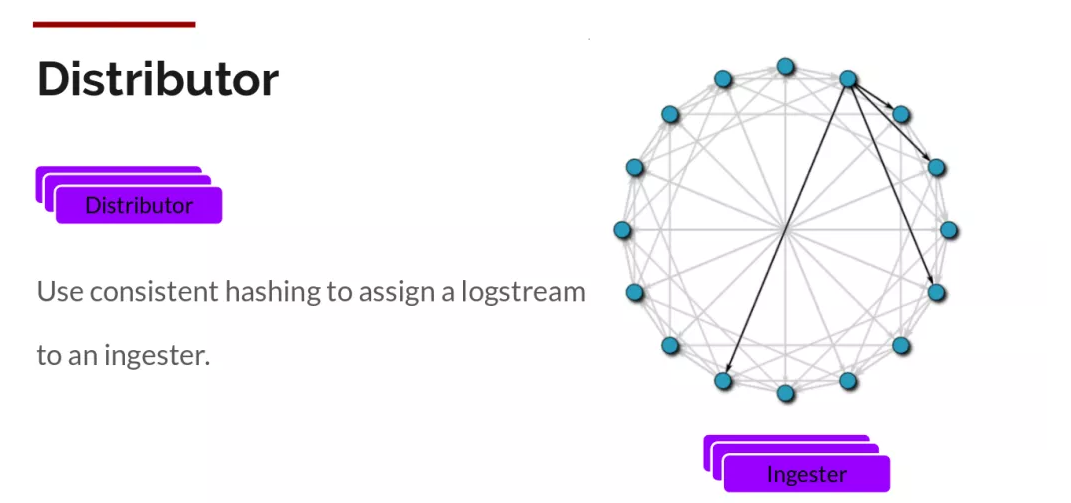
此外,为了冗余和弹性,我们将其复制n(默认情况下为3)次。
Ingester
ingester接收到日志并开始构建chunk:
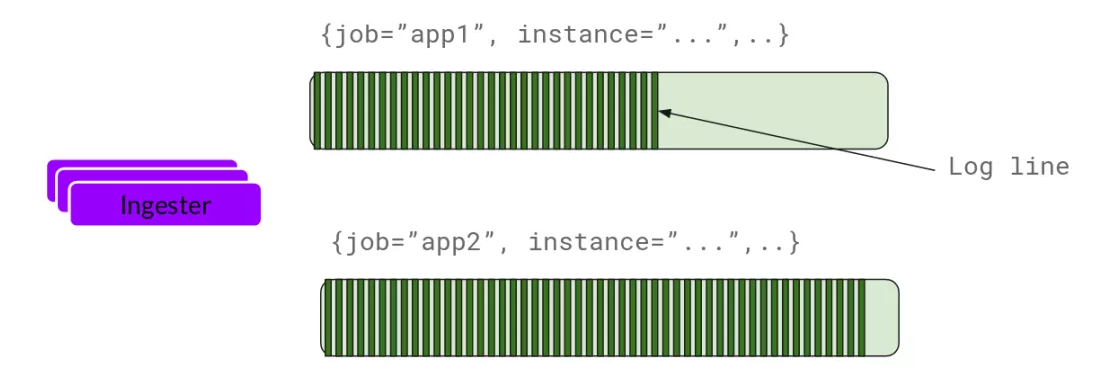
基本上就是将日志进行压缩并附加到chunk上面。一旦chunk“填满”(数据达到一定数量或者过了一定期限),ingester将其刷新到数据库。我们对块和索引使用单独的数据库,因为它们存储的数据类型不同。

刷新一个chunk之后,ingester然后创建一个新的空chunk并将新条目添加到该chunk中。
Querier
读取就非常简单了,由Querier负责给定一个时间范围和标签选择器,Querier查看索引以确定哪些块匹配,并通过greps将结果显示出来。它还从Ingester获取尚未刷新的最新数据。
对于每个查询,一个查询器将为您显示所有相关日志。实现了查询并行化,提供分布式grep,使即使是大型查询也是足够的。
二、安装
本文以一台centos 7.6主机来演示一下loki,ip地址为:192.168.1.145
Docker-compose.yml 可以参考Loki的文档介绍,开箱即用。
docker-compose.yaml
[root@rocketmq-nameserver2 ~]# cat docker-compose.yml
version: "3"
networks:
loki:
services:
loki:
image: grafana/loki:2.0.0
ports:
- "3100:3100"
command: -config.file=/etc/loki/local-config.yaml
networks:
- loki
promtail:
image: grafana/promtail:2.0.0
volumes:
- /var/log:/var/log
command: -config.file=/etc/promtail/config.yml
networks:
- loki
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
networks:
- loki
[root@rocketmq-nameserver2 ~]#
说明:这里启动了3个容器,都是运行在网桥loki上,方便相互通讯。
然后直接使用 docker-compose 启动即可:
docker-compose up -d
查看服务状态
[root@rocketmq-nameserver2 ~]# docker-compose ps
Name Command State Ports
---------------------------------------------------------------------------------
root_grafana_1 /run.sh Up 0.0.0.0:3000->3000/tcp
root_loki_1 /usr/bin/loki -config.file ... Up 0.0.0.0:3100->3100/tcp
root_promtail_1 /usr/bin/promtail -config. ... Up
[root@rocketmq-nameserver2 ~]#
三、使用
安装完成后,访问节点的 3000 端口访问 grafana,默认用户名和密码都是admin
http://192.168.1.145:3000/
选择添加数据源:
选择loki

源地址配置http://loki:3100即可
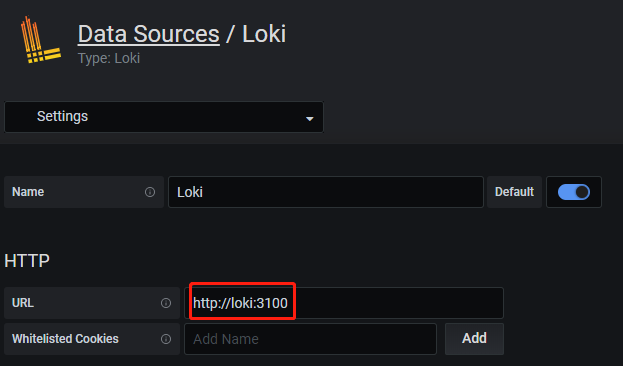
注意:这里的 http://loki:3100,表示访问容器名为loki的3100端口。
点击保存
保存完成后,切换到 grafana 左侧区域的Explore
即可进入到Loki的页面
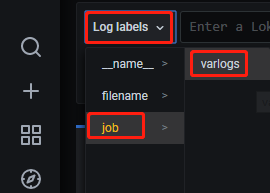
点击Log labels就可以把当前系统采集的日志标签给显示出来,可以根据这些标签进行日志的过滤查询:
选择job-->varlogs
点击右上角的Run Query,效果如下:
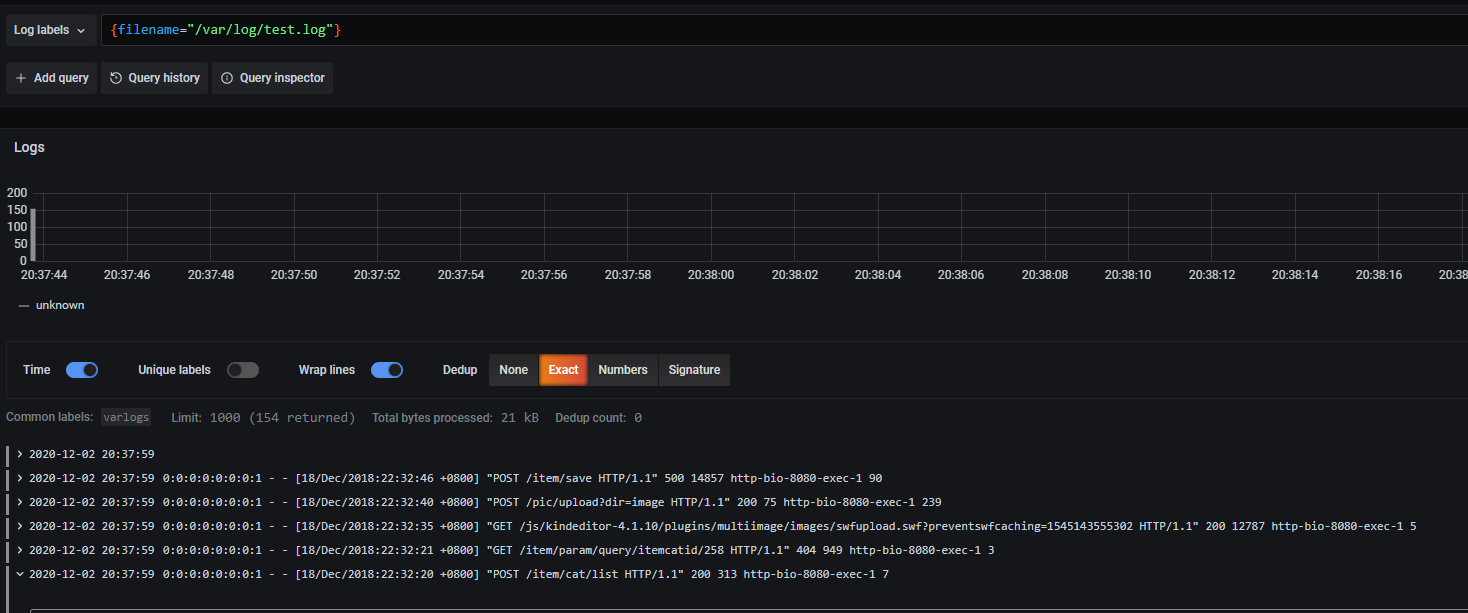
这里展示的是promtail容器里面/var/log目录中的日志
promtail容器/etc/promtail/config.yml
root@430b09afe69b:/# cat /etc/promtail/config.yml
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*log
这里的job就是varlog,文件路径就是/var/log/*log
四、配置
从上面的步骤已经可以一窥使用方法了,如果要使用起来,我们还需要了解如下信息:
Loki 的配置
Loki的详细配置,可查看官方文档:https://github.com/grafana/loki/blob/master/docs/README.md
配置相关文档: https://github.com/grafana/loki/blob/v1.3.0/docs/configuration/README.md
promtail的配置
promtail 是 Loki 的官方支持的日志采集端,在需要采集日志的节点上运行采集日志,再统一发送到 Loki 进行处理。我们编写的大多是这一部分。
官方配置说明: https://github.com/grafana/loki/blob/v1.3.0/docs/clients/promtail/configuration.md
除了使用Promtail,社区还有很多采集日志的组件,比如fluentd、fluent bit等,都是比较优秀的。
五、选择器
对于查询表达式的标签部分,将其包装在花括号中{},然后使用键值对的语法来选择标签,多个标签表达式用逗号分隔,比如:
{app="mysql",name="mysql-backup"}
目前支持以下标签匹配运算符:
=等于!=不相等=~正则表达式匹配!~不匹配正则表达式
比如:
{name=~"mysql.+"}
{name!~"mysql.+"}
适用于Prometheus标签选择器规则同样也适用于Loki日志流选择器。
六、过滤器
编写日志流选择器后,您可以通过编写搜索表达式来进一步过滤结果。搜索表达式可以只是文本或正则表达式。
查询示例:
{job="mysql"} |= "error"
{name="kafka"} |~ "tsdb-ops.*io:2003"
{instance=~"kafka-[23]",name="kafka"} != kafka.server:type=ReplicaManager
过滤器运算符可以被链接,并将顺序过滤表达式-结果日志行将满足每个过滤器。例如:
{job="mysql"} |= "error" != "timeout"
已实现以下过滤器类型:
- |= 行包含字符串。
- != 行不包含字符串。
- |~ 行匹配正则表达式。
- !~ 行与正则表达式不匹配。
regex表达式接受RE2语法。默认情况下,匹配项区分大小写,并且可以将regex切换为不区分大小写的前缀(?i)。
更多内容可参考官方说明
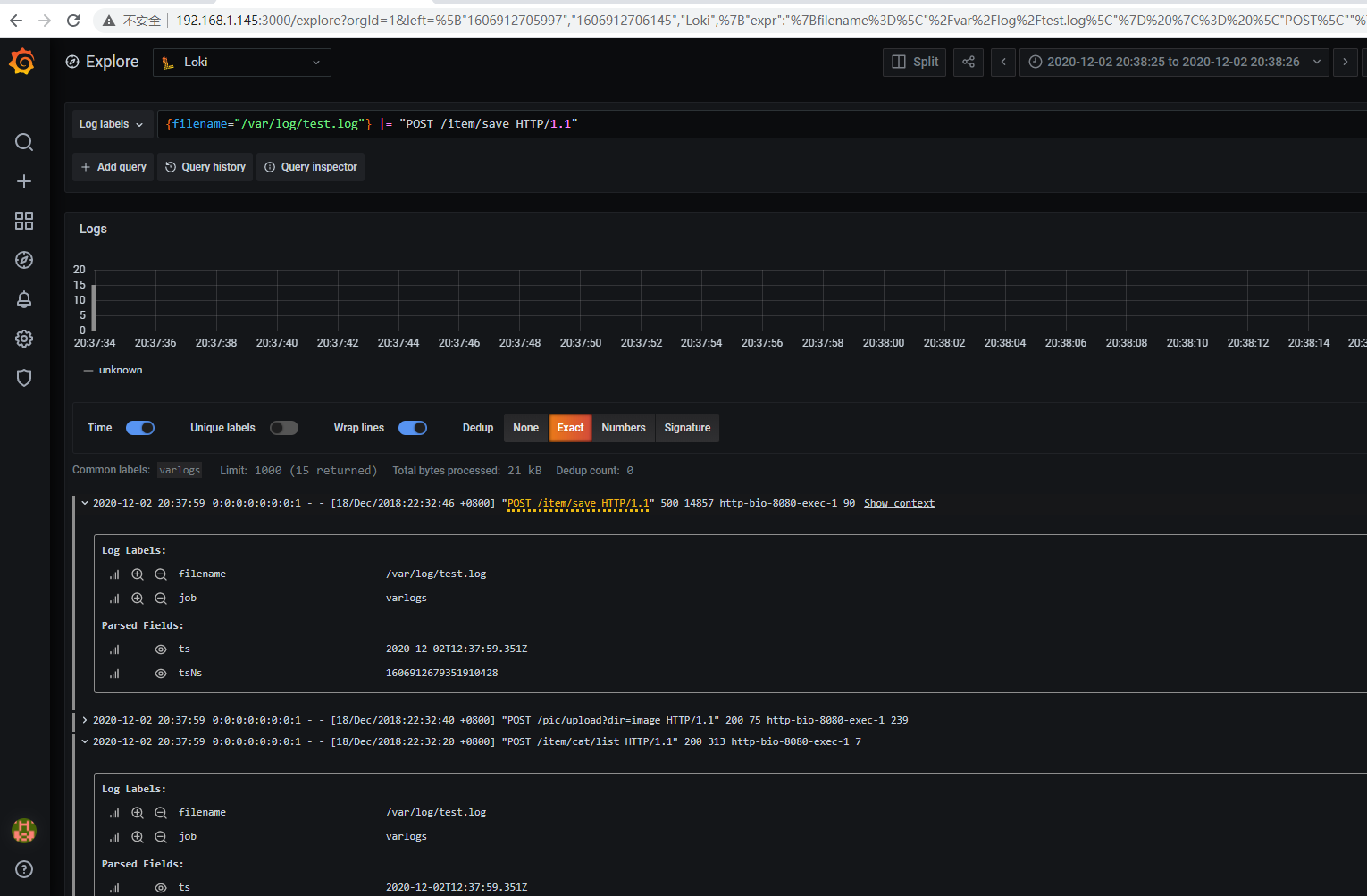
举例,我需要查询包含关键字packages
{job="varlogs"} |= "packages"
效果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号