Prometheus警报
添加新警报和模板
为了有更多的警报可以路由,让我们快速添加一些其他警报规则到node_alerts.yml警报规则文件中。
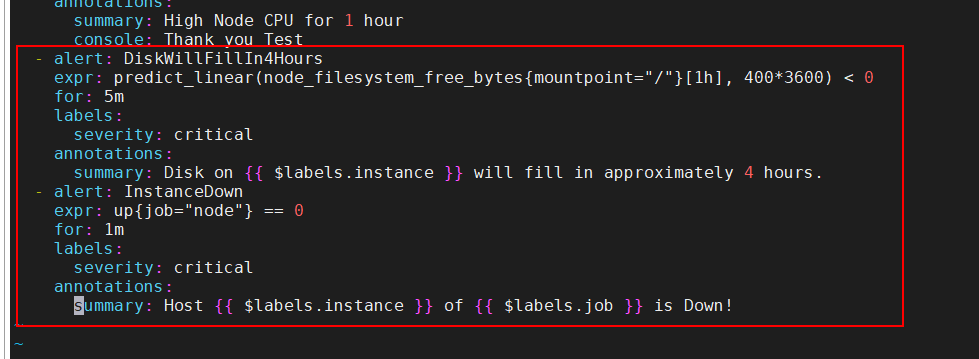
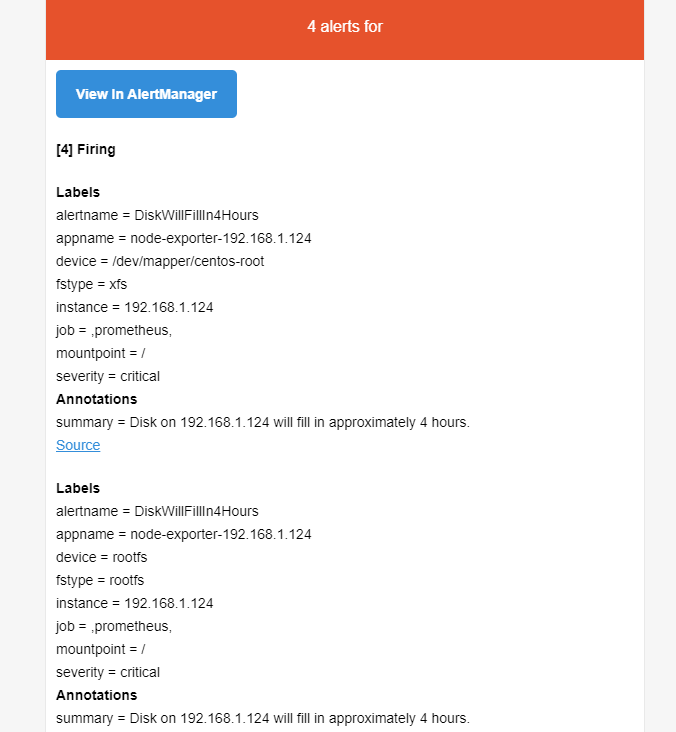
第一个警报复制了我们在第4章看到的predict_linear磁盘预测。这里,如果线性回归预测/根文件系统的磁盘空间将在4小时内耗尽,则会触发警报。你可能还会注意到,我们已在summary注解中添加了一些模板值。
模板(template)是一种在警报中使用时间序列数据的标签和值的方法,可用于注解和标签。模板使用标准的Go模板语法,并暴露一些包含时间序列的标签和值的变量。标签以变量$labels形式表示,指标的值则是变量$value。提示 变量$labels和$value分别是底层Go变量.Labels和.Value的名称。要在summary注解中引用instance标签,我们使用{{$labels.instance}}。如果想要引用时间序列的值,那么我们会使用{{$value}}。
注意:这里的400是我先在prometheus测出来负数填进去的,下面为它的邮件
Prometheus警报
我们应始终牢记:Prometheus服务器也可能出问题。让我们添加一些规则来识别问题并对它们发出警告。我们将在rules目录中创建一个新文件prometheus_alerts.yml以保存它们。因为这符合我们的glob规则,它也会被Prometheus加载。
创建prometheus_alerts.yml文件
[root@localhost rules]# cat prometheus_alertes.yml
groups:
- name: prometheus_alerts
rules:
- alert: PrometheusConfigReloadFailed
expr: prometheus_config_last_reload_successful == 0
for: 1m
labels:
severity: warning
annotations:
description: Reloading Prometheus configuration has failed on {{ $labels.instance }}.
- alert: PrometheusNotConnectedToAlertmanagers
expr: prometheus_notifications_alertmanagers_discovered < 2
for: 1m
labels:
severity: warning
annotations:
description: Prometheus {{ $labels.instance }} is not connected to any Alertmanagers
[root@localhost rules]#
在这里,我们添加了两个新规则。第一个是PrometheusConfigReloadFailed,它让我们知道Prometheus配置重新加载是否失败。如果上次重新加载失败,则使用指标prometheus_config_last_reload_successful,且指标的值为0。
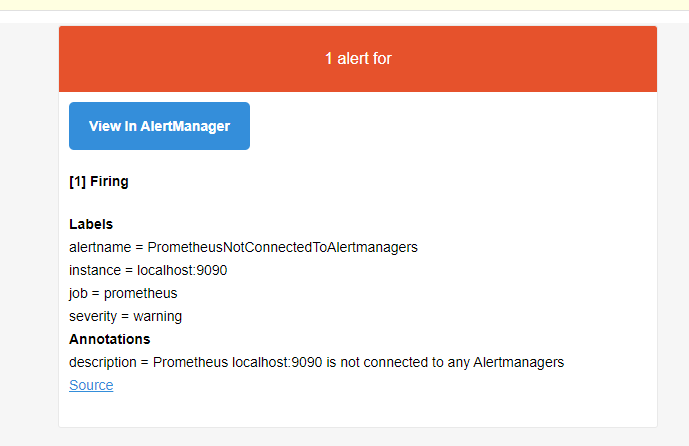
第二条规则确保Prometheus服务器可以发现Alertmanager。这使用prometheus_notifications_alertmanagers_discovered指标,该指标是服务器找到的Alertmanager计数。如果小于2,则表面Prometheus没有发现任何Alertmanager,并且这个警报将会触发。由于没有任何Alertmanager,因此它只会显示在Prometheus控制台的/alerts页面上。
注意:默认值为1,这里为了触发预警,写成了2

可用性警报
最后的警报可以帮助我们确定主机和服务的能力。第一个警报利用了我们使用Node Exporter收集的systemd指标。如果我们在节点上监控的服务不再活动,则会生成一个警报。
[root@localhost rules]# cat service_alertes.yml
groups:
- name: service_alerts
rules:
- alert: NodeServiceDown
expr: node_systemd_unit_state{state="active"} != 1
for: 10s
labels:
severity: critical
annotations:
summary: Service {{ $labels.name }} on {{ $labels.instance }} is no longer active!
description: 监控中心向您报告:- " 挨踢的,您的服务挂了?"
[root@localhost rules]#
如果带有active标签的node_systemd_unit_state指标值为0,则会触发此警报,表示服务故障至少60秒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号