大数据架构
大数据架构和技术选型
大数据架构
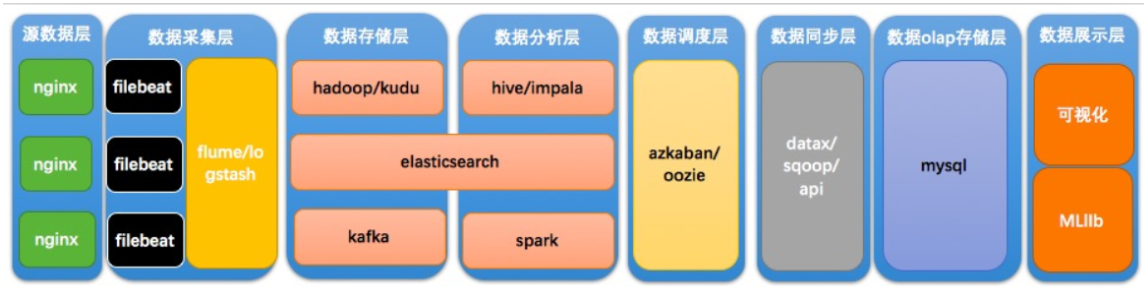
源数据层:
1、sdk日志埋点
2、日志文件:爬虫日志、业务日志
3、关系型数据库:mysql、oracle等
数据采集层:
1、离线:flume、Sqoop、Nifi
2、实时:filebeat、nginx+lua
补充:当数据量达到5亿左右的时候,filebeat+logstash采集数据到hdfs,数据会出现丢失的情况,所以此种方案不适合用于大数据存储到hdfs
数据存储层:
1、hdfs用于存储离线大数据量
2、kudu用于存储mysql关系数据库更新变化的数据
3、es存储一些log日志,比如说我们需要快速的定位某一个业务的log情况
4、kafka作为消息中间件,存储filebeat或者是flume采集的日志
数据分析层:
1、es,分析一些log
2、hive适用于分析一些离线大数据(基于磁盘IO分析)
3、impala、presto适用于分析一些准实时日志(要求快速出数据,基于内存分析)
4、spark core+spark sql 适用于分析一些离线数据,自定义解析规则
5、spark streaming适用于分析一些实时(不是完全实时)数据
6、flink、jstorm进行分析完全实时的数据
数据调度层:
1、airflow:使用于大集群,阿里的调度系统就是根据airflow二次开发,配置复杂,python脚本实现
2、azkaban:cpu和内存要求不高,主从配置支持的不算太好,适用于小集群,以job的文件实现,配置简单
3、oozie:通常hue集成,单独的使用oozie的情况下,配置及其复杂,不建议使用,所有的任务是以mr的形式进行的,可支持复杂的依赖调度
4、jobX:cpu使用高,bug还没修复,所以造成agent的cpu维持在1个左右,配置简单,只支持依赖调度,并行调度不支持
5、crontab:一般用于每分钟调度一次的任务,不支持依赖调度、并行调度(配置复杂,通过脚本自定义控制),没有可视化界面,不能准确的判断任务是否成功或者是失败.......
6、NiFi
7、自定义,公司自己开发使用的
数据同步层:
1、sqoop用的是1.x系列版本
2、datax
3、kettle
4、NiFi
数据olap存储层:
mysql、es、tidb、redis、hbase、clickhouse
补充:有时间的话去研究一下tidb和clickhouse
数据展示层:
PowerBI、帆软等BI可视化工具、前端定制开发。
技术选型
实时分析
可以使用lua或者filebeat将nginx数据采集到kafka,数据经过spark streaming或者是jstorm进行分析后,尽可能的存入一些高吞吐量的数据库(非关系型),但是有时必须要存入一些关系型数据库,比如说mysql,但是spark streaming发现仅仅通过一个map操作,每个执行的batch的时间,就超过我们所设置的batch时间,这时候我们需要一个措施,增加一个缓冲层,不直接mysql或者是redis,先写入kafka,然后通过kafka推送到独立的写入服务,这样会发现实时处理服务的时间明显的降低。
离线分析
采集这块用flume的tailf形式,或者使用sqoop和nifi。
数据分析使用Hive、SparkSql,数据存储使用HDFS。
最终将数据导出到mysql等常用的关系型数据库当中。
组件版本号
Cloudera Manager:6.2.1
CDH:6.2.1
Hadoop:3.0.0-cdh6.2.1
HBase:2.1.0-cdh6.2.1
Hive:2.1.1-cdh6.2.1
Kafka:2.1.0-cdh6.2.1
Kudu:1.9.0-cdh6.2.1
Oozie:5.1.0-cdh6.2.1
Spark:2.4.0-cdh6.2.1
Sqoop:1.4.7-cdh6.2.1
ZooKeeper:3.4.5-cdh6.2.1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号