Redis的HyperLogLog
思考一个常见的业务问题:如果你负责开发维护一个大型的网站,有一天老板找产品经理要网站每个网页每天的 UV 数据,然后让你来开发这个统计模块,你会如何实现?
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV
数据。
但是 UV 不一样,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一ID 来标识。
你也许已经想到了一个简单的方案,那就是为每一个页面一个独立的 set 集合来存储所有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可
以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。没错,这是一个非常简单的方案。
但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人
的。为这样一个去重功能就耗费这样多的存储空间,值得么?其实老板需要的数据又不需要太精确,105w 和 106w 这两个数字对于老板们来说并没有多大区别,So,有没有更好的解决方案呢?
Redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不
精确,标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了。HyperLogLog 数据结构是 Redis 的高级数据结构,它非常有用,但是令人感到意外的是,使用过它的人非常少。
使用方法
HyperLogLog 提供了两个指令 pfadd 和 pfcount,根据字面意义很好理解,一个是增加计数,一个是获取计数。pfadd 用法和 set 集合的 sadd 是一样的,来一个用户 ID,就将用
户 ID 塞进去就是。pfcount 和 scard 用法是一样的,直接获取计数值。
127.0.0.1:6379> FLUSHDB OK 127.0.0.1:6379> pfadd hll 001 (integer) 1 127.0.0.1:6379> pfadd hll 001 (integer) 0 127.0.0.1:6379> pfadd hll 002 (integer) 1 127.0.0.1:6379> pfadd hll 003 (integer) 1 127.0.0.1:6379> pfadd hll 002 (integer) 0 127.0.0.1:6379> PFCOUNT hll (integer) 3 127.0.0.1:6379>
HyperLogLog类型的基本操作
添加数据
pfadd key element [element ...]
统计数据
pfcount key [key ...]
合并数据
pfmerge destkey sourcekey [sourcekey...]
root@d4cad7fb69c2:/data# redis-cli 127.0.0.1:6379> PFADD hll1 foo bar zap a (integer) 1 127.0.0.1:6379> PFADD hll2 a b c foo (integer) 1 127.0.0.1:6379> PFMERGE hll3 hll1 hll2 OK 127.0.0.1:6379> PFCOUNT hll3 (integer) 6 127.0.0.1:6379>
说明:
- 用于进行基数统计,不是集合,不保存数据,只记录数量而不是具体数据
- 核心是基数估算算法,最终数值存在一定误差
- 误差范围:基数估计的结果是一个带有 0.81% 标准错误的近似值
- 耗空间极小,每个hyperloglog key占用了12K的内存用于标记基数
- pfadd命令不是一次性分配12K内存使用,会随着基数的增加内存逐渐增大
- Pfmerge命令合并后占用的存储空间为12K,无论合并之前数据量多少
pfmerge 适合什么场合用 ?
HyperLogLog 除了上面的 pfadd 和 pfcount 之外,还提供了第三个指令 pfmerge,用于将多个 pf 计数值累加在一起形成一个新的 pf 值。
比如在网站中我们有两个内容差不多的页面,运营说需要这两个页面的数据进行合并。其中页面的 UV 访问量也需要合并,那这个时候 pfmerge 就可以派上用场了。
注意事项
HyperLogLog 这个数据结构不是免费的,不是说使用这个数据结构要花钱,它需要占据一定 12k 的存储空间,所以它不适合统计单个用户相关的数据。如果你的用户上亿,可以算
算,这个空间成本是非常惊人的。但是相比 set 存储方案,HyperLogLog 所使用的空间那真是可以使用千斤对比四两来形容了。
不过你也不必过于当心,因为 Redis 对 HyperLogLog 的存储进行了优化,在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占
用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间。
HyperLogLog 实现原理
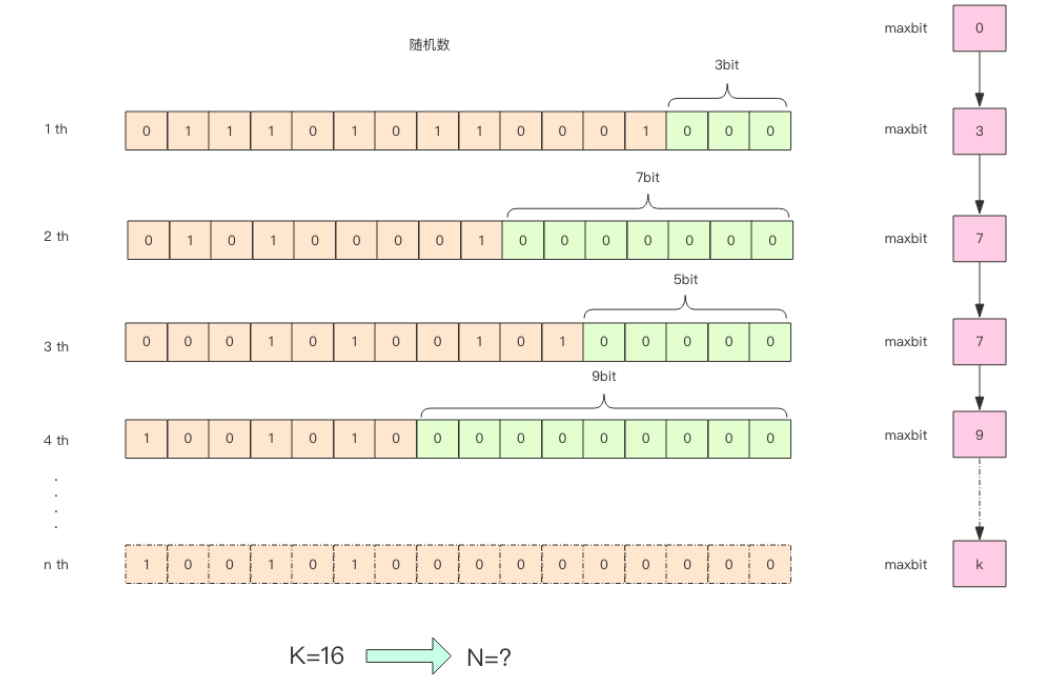
pf 的内存占用为什么是 12k ?
算法中使用了 1024 个桶进行独立计数,不过在 Redis 的 HyperLogLog实现中用到的是 16384 个桶,也就是 2^14,每个桶的 maxbits 需要 6 个 bits 来存储,最
大可以表示 maxbits=63,于是总共占用内存就是 2^14 * 6 / 8 = 12k 字节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号