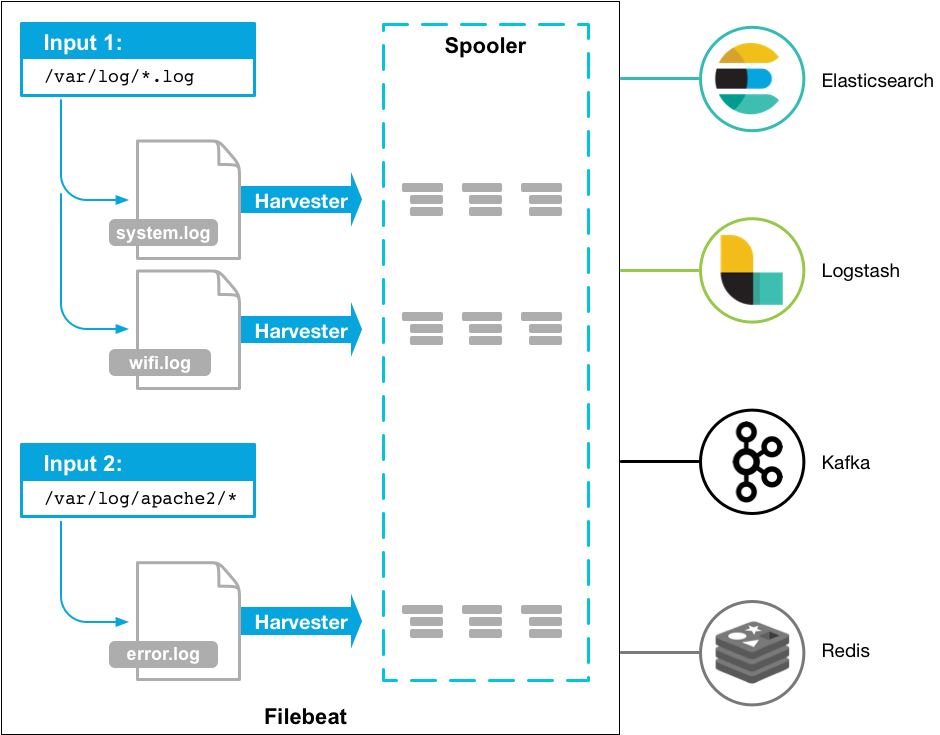
Filebeat
Filebeat介绍
Filebeat是本地文件的日志数据采集器,可监控日志目录或特定日志文件(tail file),并将它们转发给Elasticsearch或Logstatsh进行索引、kafka等。带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。
官方网址:https://www.elastic.co/guide/en/beats/filebeat/current/index.html
部署与运行
下载(或使用资料中提供的安装包,版本为:filebeat-6.5.4):https://www.elastic.co/downloads/beats
tar -zvxf filebeat-6.2.3-linux-x86_64.tar.gz cd filebeat-6.2.3-linux-x86_64 ./filebeat -e -c wgr.yml
[root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]# cat wgr.yml filebeat.prospectors: - type: stdin enabled: true setup.template.settings: index.number_of_shards: 3 output.console: pretty: true enable: true [root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]#
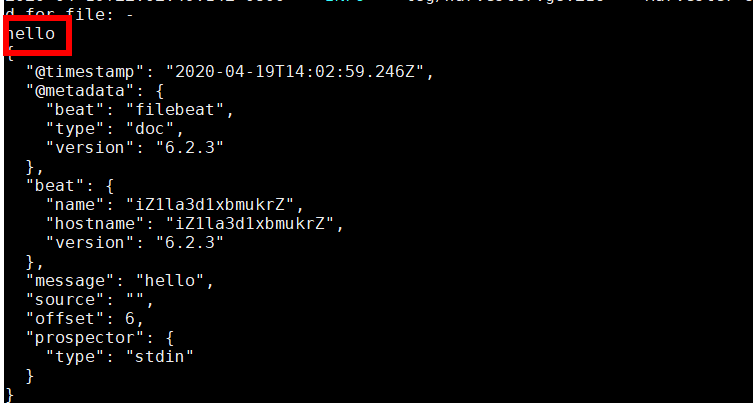
读取文件
[root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]# cat wgr.yml filebeat.prospectors: - type: log enabled: true paths: - /root/*.log setup.template.settings: index.number_of_shards: 3 output.console: pretty: true enable: true [root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]#
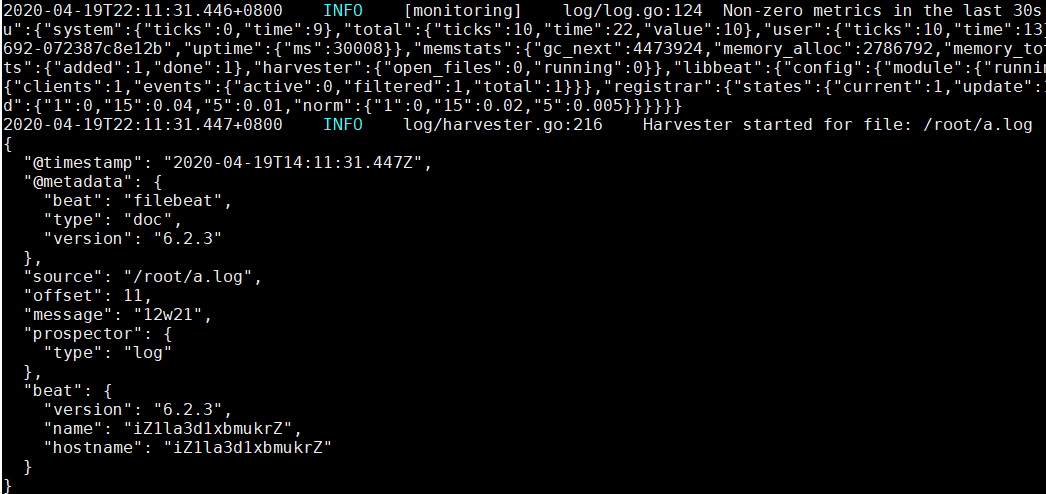
自定义字段
[root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]# cat wgr.yml filebeat.prospectors: - type: log enabled: true paths: - /root/*.log tags: ["web"] fields: from: topcheer fields_under_root: true setup.template.settings: index.number_of_shards: 3 output.console: pretty: true enable: true [root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]#
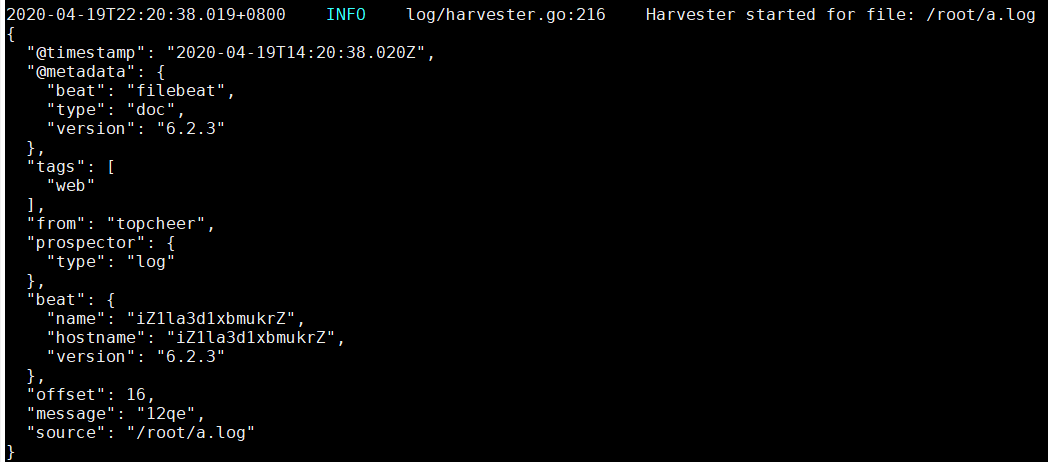
输出到Elasticsearch
2020-04-19T22:33:43.424+0800 INFO crawler/crawler.go:48 Loading Prospectors: 1 2020-04-19T22:33:43.425+0800 INFO log/prospector.go:111 Configured paths: [/root/*.log] 2020-04-19T22:33:43.425+0800 INFO crawler/crawler.go:82 Loading and starting Prospectors completed. Enabled prospectors: 1 2020-04-19T22:33:43.425+0800 INFO log/harvester.go:216 Harvester started for file: /root/a.log 2020-04-19T22:33:44.547+0800 INFO elasticsearch/client.go:690 Connected to Elasticsearch version 5.6.12 2020-04-19T22:33:44.559+0800 INFO template/load.go:55 Loading template for Elasticsearch version: 5.6.12 2020-04-19T22:33:44.833+0800 INFO template/load.go:89 Elasticsearch template with name 'filebeat-6.2.3' loaded 2020-04-19T22:34:13.425+0800 INFO [monitoring] log/log.go:124 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":10,"time":12},"total":{"ticks":50,"time":54,"value":50},"user":{"ticks":40,"time":42}},"info":{"ephemeral_id":"8a0c59b6-3c04-4217-af16-87450daa8965","uptime":{"ms":30010}},"memstats":{"gc_next":4194304,"memory_alloc":1611744,"memory_total":7392648,"rss":16904192}},"filebeat":{"events":{"added":7,"done":7},"harvester":{"open_files":1,"running":1,"started":1}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":5,"batches":2,"total":5},"read":{"bytes":1268},"type":"elasticsearch","write":{"bytes":14868}},"pipeline":{"clients":1,"events":{"active":0,"filtered":2,"published":5,"retry":2,"total":7},"queue":{"acked":5}}},"registrar":{"states":{"curren

采集nginx日志
[root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]# cat wgr.yml filebeat.prospectors: - type: log enabled: true paths: - /data/nginx/logs/*.log tags: ["nginx"] setup.template.settings: index.number_of_shards: 3 output.elasticsearch: hosts: ["47.131.231.241:9200"] [root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]#

Module
前面要想实现日志数据的读取以及处理都是自己手动配置的,其实,在Filebeat中,有大量的Module,可以简化我们的配置,直接就可以使用,如下:
[root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]# ./filebeat modules list Enabled: nginx Disabled: apache2 auditd icinga kafka logstash mysql osquery postgresql redis system traefik [root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]# ./filebeat modules disable nginx Disabled nginx [root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]# ./filebeat modules enable nginx Enabled nginx [root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]#
可以发现,nginx的module已经被启用。
nginx module 配置
[root@iZ1la3d1xbmukrZ modules.d]# cat nginx.yml - module: nginx # Access logs access: enabled: true var.paths: ["/data/nginx/logs/access.log*"] # Set custom paths for the log files. If left empty, # Filebeat will choose the paths depending on your OS. #var.paths: # Error logs error: enabled: true var.paths: ["/data/nginx/logs/error.log*"] # Set custom paths for the log files. If left empty, # Filebeat will choose the paths depending on your OS. #var.paths: [root@iZ1la3d1xbmukrZ modules.d]#
配置filebeat
[root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]# cat wgr.yml filebeat.prospectors: setup.template.settings: index.number_of_shards: 3 output.elasticsearch: hosts: ["47.111.251.239:9200"] filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false [root@iZ1la3d1xbmukrZ filebeat-6.2.3-linux-x86_64]#
测试
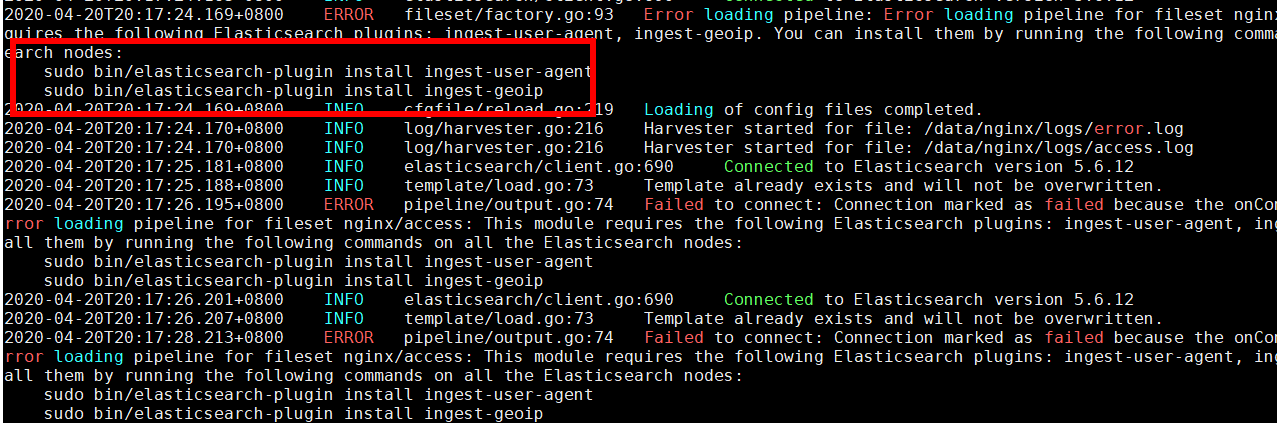
#解决:需要在Elasticsearch中安装ingest-user-agent、ingest-geoip插件 #在资料中可以找到,ingest-user-agent.tar、ingest-geoip.tar、ingest-geoip-conf.tar 3个文件 #其中,ingest-user-agent.tar、ingest-geoip.tar解压到plugins下 #ingest-geoip-conf.tar解压到config下 #问题解决。
移到容器内部
[root@iZ1la3d1xbmukrZ ~]# docker cp /root/ingest-geoip 47919e4d2ecc:/usr/share/elasticsearch/plugins/ [root@iZ1la3d1xbmukrZ ~]# docker cp /root/ingest-user-agent 47919e4d2ecc:/usr/share/elasticsearch/plugins/ [root@iZ1la3d1xbmukrZ ~]# docker cp /root/ingest-geoip 47919e4d2ecc:/usr/share/elasticsearch/config/
测试发现,数据已经写入到了Elasticsearch中,并且拿到的数据更加明确了:
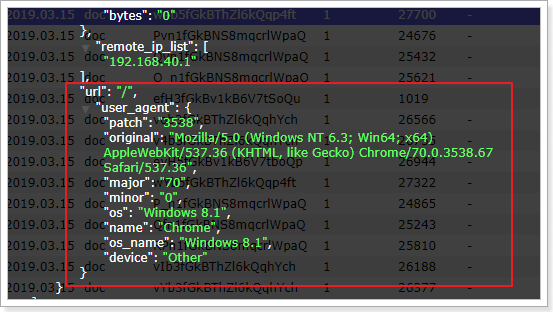
字段解释
paths:指定要监控的日志,目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:
/var/log/* /*.log
则只会去/var/log目录的所有子目录中寻找以".log"结尾的文件,而不会寻找/var/log目录下以".log"结尾的文件。
encoding:指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的。
input_type:指定文件的输入类型log(默认)或者stdin。
exclude_lines:在输入中排除符合正则表达式列表的那些行。
include_lines:包含输入中符合正则表达式列表的那些行(默认包含所有行),include_lines执行完毕之后会执行exclude_lines。
exclude_files:忽略掉符合正则表达式列表的文件(默认为每一个符合paths定义的文件都创建一个harvester)。
fields:向输出的每一条日志添加额外的信息,比如"level:debug",方便后续对日志进行分组统计。默认情况下,会在输出信息的fields子目录下以指定的新增fields建立子目录,
fields_under_root:如果该选项设置为true,则新增fields成为顶级目录,而不是将其放在fields目录下。自定义的field会覆盖filebeat默认的field。
ignore_older:可以指定Filebeat忽略指定时间段以外修改的日志内容,比如2h(两个小时)或者5m(5分钟)。
close_older:如果一个文件在某个时间段内没有发生过更新,则关闭监控的文件handle。默认1h。
force_close_files:Filebeat会在没有到达close_older之前一直保持文件的handle,如果在这个时间窗内删除文件会有问题,所以可以把force_close_files设置为true,只要filebeat检测到文件名字发生变化,就会关掉这个handle。
scan_frequency:Filebeat以多快的频率去prospector指定的目录下面检测文件更新(比如是否有新增文件),如果设置为0s,则Filebeat会尽可能快地感知更新(占用的CPU会变高)。默认是10s。
document_type:设定Elasticsearch输出时的document的type字段,也可以用来给日志进行分类。
harvester_buffer_size:每个harvester监控文件时,使用的buffer的大小。
max_bytes:日志文件中增加一行算一个日志事件,max_bytes限制在一次日志事件中最多上传的字节数,多出的字节会被丢弃。默认是10MB。
multiline:适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。这个配置的下面包含如下配置:
pattern:多行日志开始的那一行匹配的pattern
negate:是否需要对pattern条件转置使用,不翻转设为true,反转设置为false。
match:匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
max_lines:合并的最多行数(包含匹配pattern的那一行),默认为500行。
timeout:到了timeout之后,即使没有匹配一个新的pattern(发生一个新的事件),也把已经匹配的日志事件发送出去
tail_files:如果设置为true,Filebeat从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,而不是从文件开始处重新发送所有内容。
backoff:Filebeat检测到某个文件到了EOF之后,每次等待多久再去检测文件是否有更新,默认为1s。
max_backoff:Filebeat检测到某个文件到了EOF之后,等待检测文件更新的最大时间,默认是10秒。
backoff_factor:定义到达max_backoff的速度,默认因子是2,到达max_backoff后,变成每次等待max_backoff那么长的时间才backoff一次,直到文件有更新才会重置为backoff。比如:
如果设置成1,意味着去使能了退避算法,每隔backoff那么长的时间退避一次。
spool_size:spooler的大小,spooler中的事件数量超过这个阈值的时候会清空发送出去(不论是否到达超时时间),默认1MB。
idle_timeout:spooler的超时时间,如果到了超时时间,spooler也会清空发送出去(不论是否到达容量的阈值),默认1s。
registry_file:记录filebeat处理日志文件的位置的文件
config_dir:如果要在本配置文件中引入其他位置的配置文件,可以写在这里(需要写完整路径),但是只处理prospector的部分。
publish_async:是否采用异步发送模式(实验功能)。
工作原理
Filebeat涉及两个组件:查找器prospector和采集器harvester,来读取文件(tail file)并将事件数据发送到指定的输出。
启动Filebeat时,它会启动一个或多个查找器,查看你为日志文件指定的本地路径。对于prospector所在的每个日志文件,prospector启动harvester。每个harvester都会为新内容读取单个日志文件,并将新日志数据发送到libbeat,后者将聚合事件并将聚合数据发送到你为Filebeat配置的输出。
当发送数据到Logstash或Elasticsearch时,Filebeat使用一个反压力敏感(backpressure-sensitive)的协议来解释高负荷的数据量。当Logstash数据处理繁忙时,Filebeat放慢它的读取速度。一旦压力解除,Filebeat将恢复到原来的速度,继续传输数据。
1.1采集器Harvester
Harvester负责读取单个文件的内容。读取每个文件,并将内容发送到the output,每个文件启动一个harvester, harvester负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态。
如果文件在读取时被删除或重命名,Filebeat将继续读取文件。这有副作用,即在harvester关闭之前,磁盘上的空间被保留。默认情况下,Filebeat将文件保持打开状态,直到达到close_inactive状态
关闭harvester会产生以下结果:
1)如果在harvester仍在读取文件时文件被删除,则关闭文件句柄,释放底层资源。
2)文件的采集只会在scan_frequency过后重新开始。
3)如果在harvester关闭的情况下移动或移除文件,则不会继续处理文件。
要控制收割机何时关闭,请使用close_ *配置选项
1.2查找器Prospector
Prospector负责管理harvester并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。每个prospector都在自己的Go协程中运行。
Filebeat目前支持两种prospector类型:log和stdin。每个prospector类型可以定义多次。日志prospector检查每个文件来查看harvester是否需要启动,是否已经运行,或者该文件是否可以被忽略(请参阅ignore_older)。
只有在harvester关闭后文件的大小发生了变化,才会读取到新行。
注:Filebeat prospector只能读取本地文件,没有功能可以连接到远程主机来读取存储的文件或日志。
启动和停止
开启filebeat
cd FILEBEAT_HOME
nohup ./bin/filebeat -f config/test.conf >>/FILEBEAT_HOME/logs/filebeat.log &
后台启动filebeat,配置对应的参数
启动多个filebeat配置,新建一个目录(conf)存放多个filebeat的配置文件,
#nohup ./bin/filebeat -f conf/* >>/FILEBEAT_HOME/logs/filebeat.log &
注意:一台服务器只能启动一个filebeat进程。
停止filebeat
ps -ef |grep filebeat
kill -9 $pid
注意: 非紧急情况下,杀掉进程只能用优雅方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号