Redis集群详解
RedisCluster介绍
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。相对于 Codis 的不同,它是去中心化的,如图所示,该集群有三个 Redis 节点组成,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节点相互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议相互交互集群信息。

Redis Cluster 将所有数据划分为 16384 的 slots,它比 Codis 的 1024 个槽划分的更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,它不像 Codis,它不需要另外的分布式存储来存储节点槽位信息。
当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息。这样当客户端要查找某个 key 时,可以直接定位到目标节点。
这点不同于 Codis,Codis 需要通过 Proxy 来定位目标节点,RedisCluster 是直接定位。客户端为了可以直接定位某个具体的 key 所在的节点,它就需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
另外,RedisCluster 的每个节点会将集群的配置信息持久化到配置文件中,所以必须确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
Cluster 还允许用户强制某个 key 挂在特定槽位上,通过在 key 字符串里面嵌入 tag 标记,这就可以强制 key 所挂在的槽位等于 tag 所在的槽位。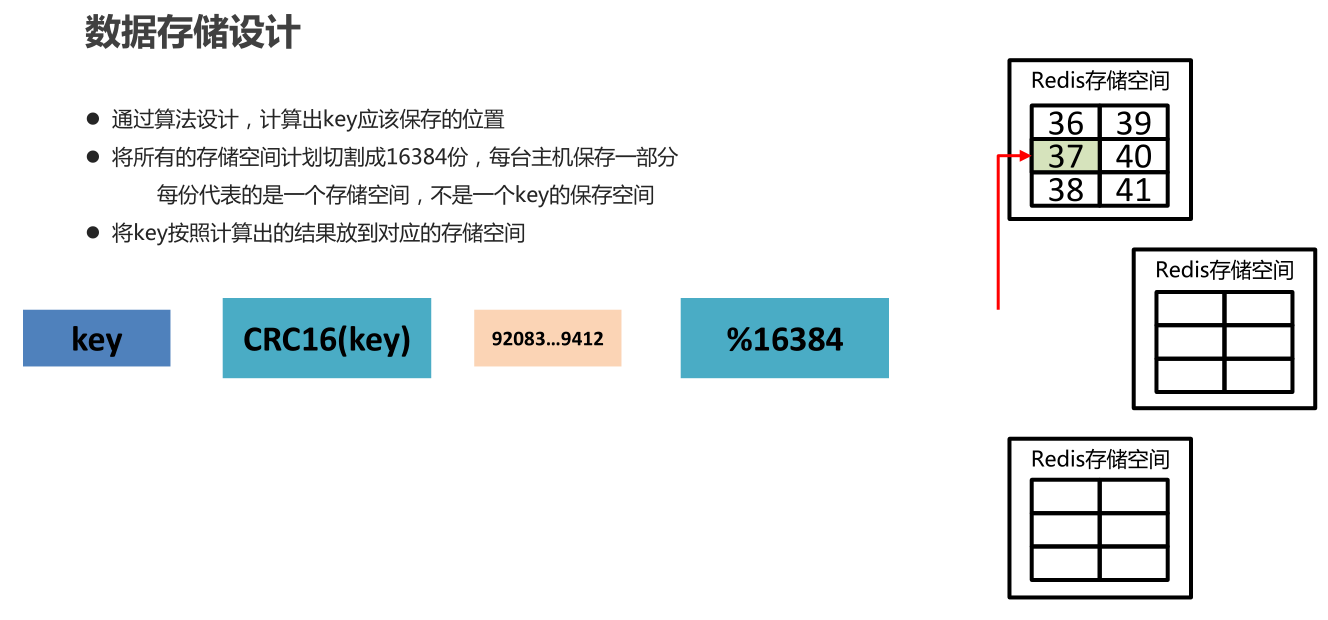
def HASH_SLOT(key) s = key.index "{" if s e = key.index "}",s+1 if e && e != s+1 key = key[s+1..e-1] end end crc16(key) % 16384 end
跳转
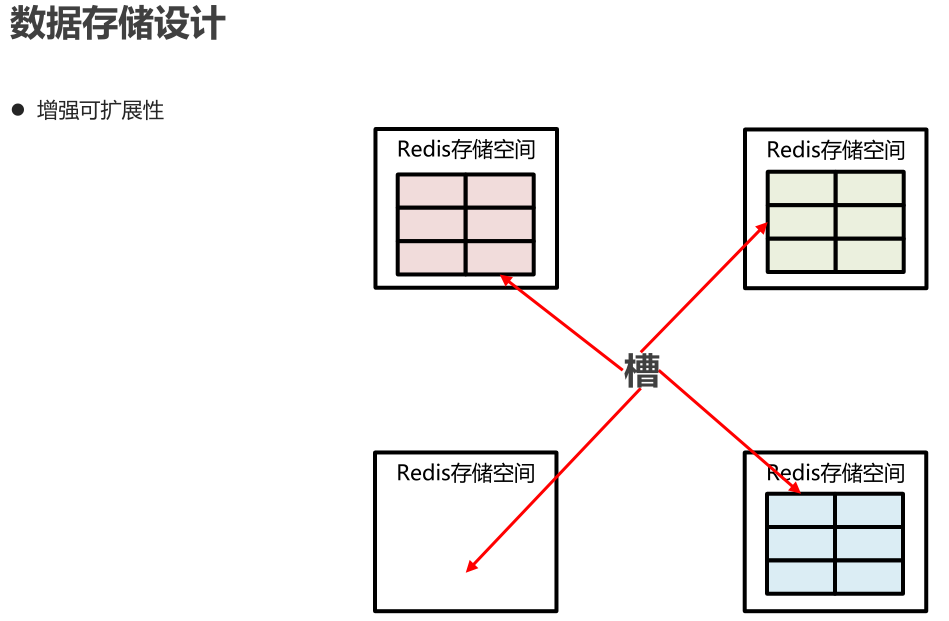
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。
GET x
-MOVED 3999 127.0.0.1:6381
MOVED 指令的第一个参数 3999 是 key 对应的槽位编号,后面是目标节点地址。
MOVED 指令前面有一个减号,表示该指令是一个错误消息。
客户端收到 MOVED 指令后,要立即纠正本地的槽位映射表。后续所有 key 将使用新的槽位映射表。
集群的部署
修改配置文件,打开下面3个配置
添加节点 cluster-enabled yes|no
cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容 cluster-config-file <filename>
节点服务响应超时时间,用于判定该节点是否下线或切换为从节点 cluster-migration-barrier <count>
master连接的slave最小数量 cluster-node-timeout <milliseconds>

[root@iZbp143t3oxhfc3ar7jey0Z redis-4.0.12]# vim redis.conf [root@iZbp143t3oxhfc3ar7jey0Z redis-4.0.12]# sed "s/6379/6380/g" redis.conf > redis-6380.conf [root@iZbp143t3oxhfc3ar7jey0Z redis-4.0.12]# sed "s/6379/6381/g" redis.conf > redis-6381.conf [root@iZbp143t3oxhfc3ar7jey0Z redis-4.0.12]# sed "s/6379/6382/g" redis.conf > redis-6382.conf [root@iZbp143t3oxhfc3ar7jey0Z redis-4.0.12]# sed "s/6379/6383/g" redis.conf > redis-6383.conf [root@iZbp143t3oxhfc3ar7jey0Z redis-4.0.12]# sed "s/6379/6384/g" redis.conf > redis-6384.conf [root@iZbp143t3oxhfc3ar7jey0Z redis-4.0.12]# sed "s/6379/6385/g" redis.conf > redis-6385.conf
然后依次启动6个服务,我这只演示一个
[root@iZbp143t3oxhfc3ar7jey0Z redis-4.0.12]# redis-server /root/redis-4.0.12/redis.conf 22126:C 12 Apr 16:20:54.640 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 22126:C 12 Apr 16:20:54.640 # Redis version=4.0.12, bits=64, commit=00000000, modified=0, pid=22126, just started 22126:C 12 Apr 16:20:54.640 # Configuration loaded 22126:M 12 Apr 16:20:54.641 * No cluster configuration found, I'm 8de9ebab0e21b4343faaf0aca24f925e1b540607 _._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 4.0.12 (00000000/0) 64 bit .-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in cluster mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 6379 | `-._ `._ / _.-' | PID: 22126 `-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 22126:M 12 Apr 16:20:54.644 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. 22126:M 12 Apr 16:20:54.644 # Server initialized 22126:M 12 Apr 16:20:54.644 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. 22126:M 12 Apr 16:20:54.644 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled. 22126:M 12 Apr 16:20:54.645 * Ready to accept connections 22126:M 12 Apr 17:02:29.127 # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH 22126:M 12 Apr 17:02:29.205 # IP address for this node updated to 127.0.0.1 22126:M 12 Apr 17:02:34.115 # Cluster state changed: ok 22126:M 12 Apr 17:02:34.720 * Slave 127.0.0.1:6383 asks for synchronization
把6个服务都加入到集群中
[root@iZbp143t3oxhfc3ar7jey0Z ~]# ps -ef|grep redis root 7810 6131 0 11:40 pts/0 00:00:00 redis-cli root 8135 22046 0 17:10 pts/6 00:00:00 redis-cli -c root 8382 21936 0 17:15 pts/3 00:00:02 redis-server *:6382 [cluster] root 8624 6131 0 17:20 pts/0 00:00:01 redis-server *:6379 [cluster] root 9937 22082 0 17:46 pts/7 00:00:00 grep --color=auto redis root 22207 21864 0 16:22 pts/1 00:00:05 redis-server *:6380 [cluster] root 22233 21900 0 16:22 pts/2 00:00:05 redis-server *:6381 [cluster] root 22277 21972 0 16:23 pts/4 00:00:04 redis-server *:6383 [cluster] root 22294 22009 0 16:23 pts/5 00:00:04 redis-server *:6384 [cluster] [root@iZbp143t3oxhfc3ar7jey0Z ~]# [root@iZbp143t3oxhfc3ar7jey0Z bin]# redis-trib create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 Adding replica 127.0.0.1:6383 to 127.0.0.1:6379 Adding replica 127.0.0.1:6384 to 127.0.0.1:6380 Adding replica 127.0.0.1:6382 to 127.0.0.1:6381 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: 8de9ebab0e21b4343faaf0aca24f925e1b540607 127.0.0.1:6379 slots:0-5460 (5461 slots) master M: 3f2adf61d4cb795a425bc6371b68fc9a92a5068b 127.0.0.1:6380 slots:5461-10922 (5462 slots) master M: 274ad8fd63a1a18c68e5deb063d78a9a8a7ab3e9 127.0.0.1:6381 slots:10923-16383 (5461 slots) master S: b7011bc56dc685ceb734f3888bd6edc786b349f8 127.0.0.1:6382 replicates 274ad8fd63a1a18c68e5deb063d78a9a8a7ab3e9 S: 106d83662a79958e0f24c9e1e3d9a51235c5fd63 127.0.0.1:6383 replicates 8de9ebab0e21b4343faaf0aca24f925e1b540607 S: bcd235ffe5ebebfb96293fea0b4115a729a58fff 127.0.0.1:6384 replicates 3f2adf61d4cb795a425bc6371b68fc9a92a5068b Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join.... >>> Performing Cluster Check (using node 127.0.0.1:6379) M: 8de9ebab0e21b4343faaf0aca24f925e1b540607 127.0.0.1:6379 slots:0-5460 (5461 slots) master 1 additional replica(s) M: 3f2adf61d4cb795a425bc6371b68fc9a92a5068b 127.0.0.1:6380 slots:5461-10922 (5462 slots) master 1 additional replica(s) M: 274ad8fd63a1a18c68e5deb063d78a9a8a7ab3e9 127.0.0.1:6381 slots:10923-16383 (5461 slots) master 1 additional replica(s) S: bcd235ffe5ebebfb96293fea0b4115a729a58fff 127.0.0.1:6384 slots: (0 slots) slave replicates 3f2adf61d4cb795a425bc6371b68fc9a92a5068b S: 106d83662a79958e0f24c9e1e3d9a51235c5fd63 127.0.0.1:6383 slots: (0 slots) slave replicates 8de9ebab0e21b4343faaf0aca24f925e1b540607 S: b7011bc56dc685ceb734f3888bd6edc786b349f8 127.0.0.1:6382 slots: (0 slots) slave replicates 274ad8fd63a1a18c68e5deb063d78a9a8a7ab3e9 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
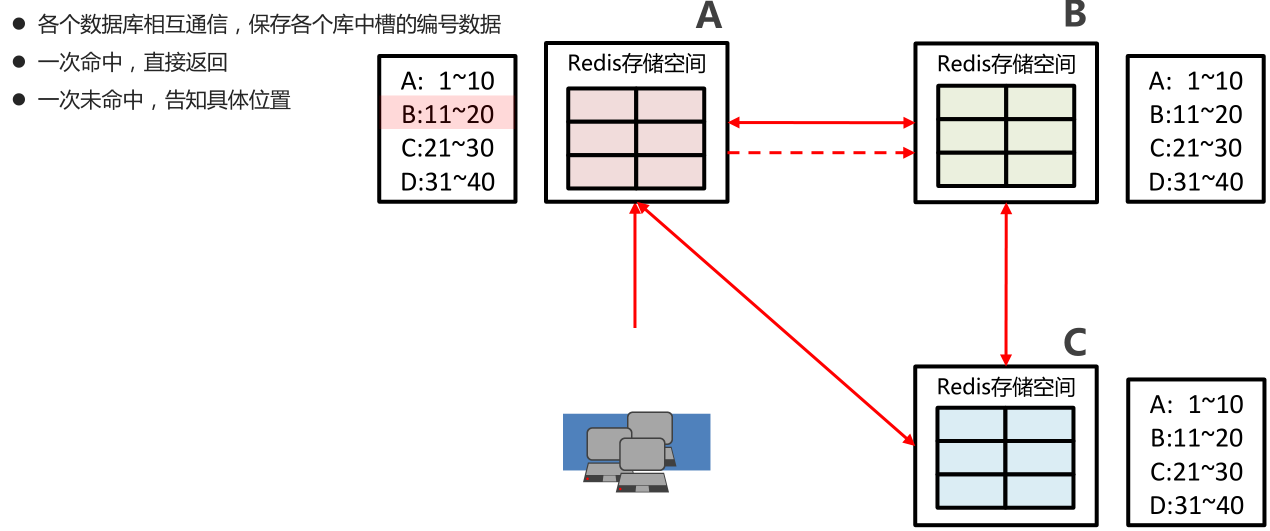
可能下线 (PFAIL-Possibly Fail) 与确定下线 (Fail)
因为 Redis Cluster 是去中心化的,一个节点认为某个节点失联了并不代表所有的节点都认为它失联了。所以集群还得经过一次协商的过程,只有当大多数节点都认定了某个节点失
联了,集群才认为该节点需要进行主从切换来容错。
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。比如一个节点发现某个节点失联了 (PFail),它会将这条信息向整个集群广播,其它节点也就可
以收到这点失联信息。如果一个节点收到了某个节点失联的数量 (PFail Count) 已经达到了集群的大多数,就可以标记该节点为确定下线状态 (Fail),然后向整个集群广播,强迫其它节
点也接收该节点已经下线的事实,并立即对该失联节点进行主从切换。
集群变更感知
当服务器节点变更时,客户端应该即时得到通知以实时刷新自己的节点关系表。那客户端是如何得到通知的呢?这里要分 2 种情况:
1.目标节点挂掉了,客户端会抛出一个 ConnectionError,紧接着会随机挑一个节点来重试,这时被重试的节点会通过 moved error 告知目标槽位被分配到的新的节点地址。
2.运维手动修改了集群信息,将 master 切换到其它节点,并将旧的 master 移除集群。这时打在旧节点上的指令会收到一个 ClusterDown 的错误,告知当前节点所在集群不可
用 (当前节点已经被孤立了,它不再属于之前的集群)。这时客户端就会关闭所有的连接,清空槽位映射关系表,然后向上层抛错。待下一条指令过来时,就会重新尝试初始化节点信息。
演示当关闭掉一个从节点的时候
关掉节点
主节点的显示日志

其他节点显示的日志

当节点重新启动的时候,就会把fail的标记给修改掉
当关闭主节点的时候
自己当了主节点

显示节点信息

当重新启动6379的时候,发现自己从主节点变成了从节点


使用的时候,要加一个c
[root@iZbp143t3oxhfc3ar7jey0Z data]# redis-cli 127.0.0.1:6379> set name wgr (error) MOVED 5798 127.0.0.1:6380 127.0.0.1:6379> exit [root@iZbp143t3oxhfc3ar7jey0Z data]# redis-cli -c 127.0.0.1:6379> set name wgr -> Redirected to slot [5798] located at 127.0.0.1:6380 OK 127.0.0.1:6380>


 浙公网安备 33010602011771号
浙公网安备 33010602011771号