Hadoop介绍和安装(一)
简介
主要记录了Hadoop各个组件的基本原理,处理过程和关键的知识点等,包括HDFS、YARN、MapReduce等。
铺垫
-
人产生数据的速度越来越快,机器则更加快,more data usually beats better algorithms,所以需要另外的一种处理数据的方法。
-
硬盘的容量增加了,但性能没有跟上,解决办法是把数据分到多块硬盘,然后同时读取。但带来一些问题:
硬件问题:复制数据解决(RAID)
分析需要从不同的硬盘读取数据:MapReduce
而Hadoop提供了
- 可靠的共享存储(分布式存储)
- 抽象的分析接口(分布式分析)
大数据
概念
不能使用一台机器进行处理的数据
大数据的核心是样本=总体
特性
- 大量性(volume): 一般在大数据里,单个文件的级别至少为几十,几百GB以上
- 快速性(velocity): 反映在数据的快速产生及数据变更的频率上
- 多样性(variety): 泛指数据类型及其来源的多样化,进一步可以把数据结构归纳为结构化(structured),半结构化(semi-structured),和非结构化(unstructured)
- 易变性: 伴随数据快速性的特征,数据流还呈现一种波动的特征。不稳定的数据流会随着日,季节,特定事件的触发出现周期性峰值
- 准确性: 又称为数据保证(data assurance)。不同方式,渠道收集到的数据在质量上会有很大差异。数据分析和输出结果的错误程度和可信度在很大程度上取决于收集到的数据质量的高低
- 复杂性: 体现在数据的管理和操作上。如何抽取,转换,加载,连接,关联以把握数据内蕴的有用信息已经变得越来越有挑战性
关键技术
-
数据分布在多台机器
可靠性:每个数据块都复制到多个节点
性能:多个节点同时处理数据
-
计算随数据走
网络IO速度 << 本地磁盘IO速度,大数据系统会尽量地将任务分配到离数据最近的机器上运行(程序运行时,将程序及其依赖包都复制到数据所在的机器运行)
代码向数据迁移,避免大规模数据时,造成大量数据迁移的情况,尽量让一段数据的计算发生在同一台机器上
-
串行IO取代随机IO
传输时间 << 寻道时间,一般数据写入后不再修改
Hadoop发现版本
1)Lucene--Doug Cutting开创的开源软件,用java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
2)2001年年底成为apache基金会的一个子项目
3)对于大数量的场景,Lucene面对与Google同样的困难
4)学习和模仿Google解决这些问题的办法 :微型版Nutch
5)可以说Google是hadoop的思想之源(Google在大数据方面的三篇论文)
GFS --->HDFS
Map-Reduce --->MR
BigTable --->Hbase
6)2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,使Nutch性能飙升
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
8)名字来源于Doug Cutting儿子的玩具大象

9)Hadoop就此诞生并迅速发展,标志这云计算时代来临
2.4 Hadoop的优势
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:能够自动将失败的任务重新分配。
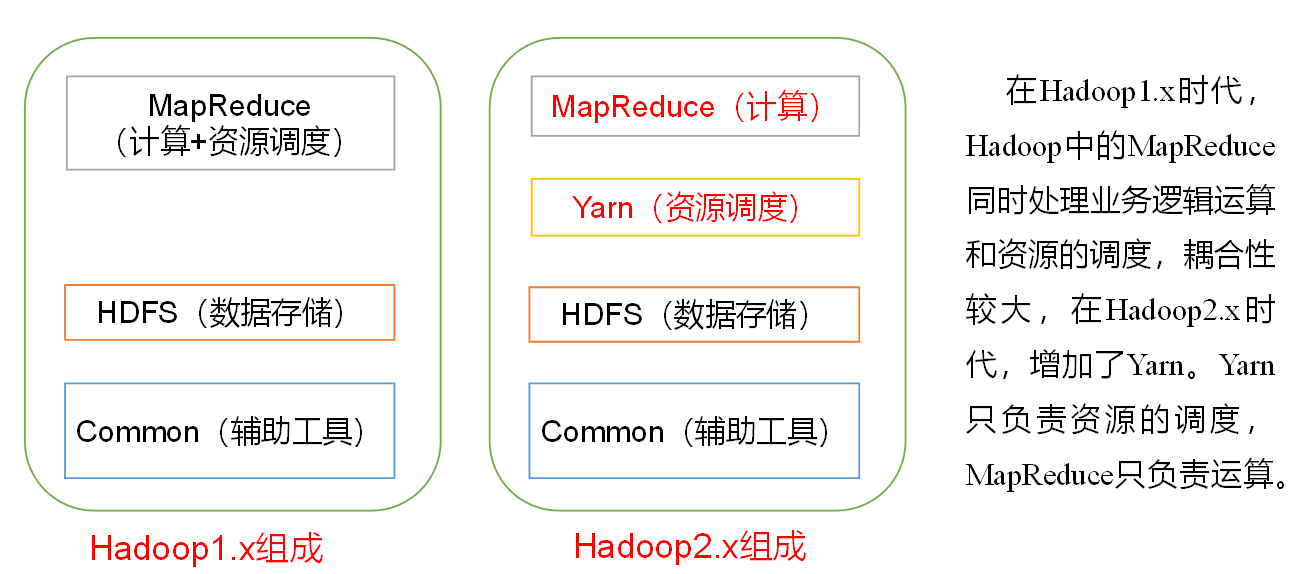
Hadoop组成
HDFS架构概述
HDFS架构概述
HDFS(Hadoop Distributed File System)的架构概述,如图所示

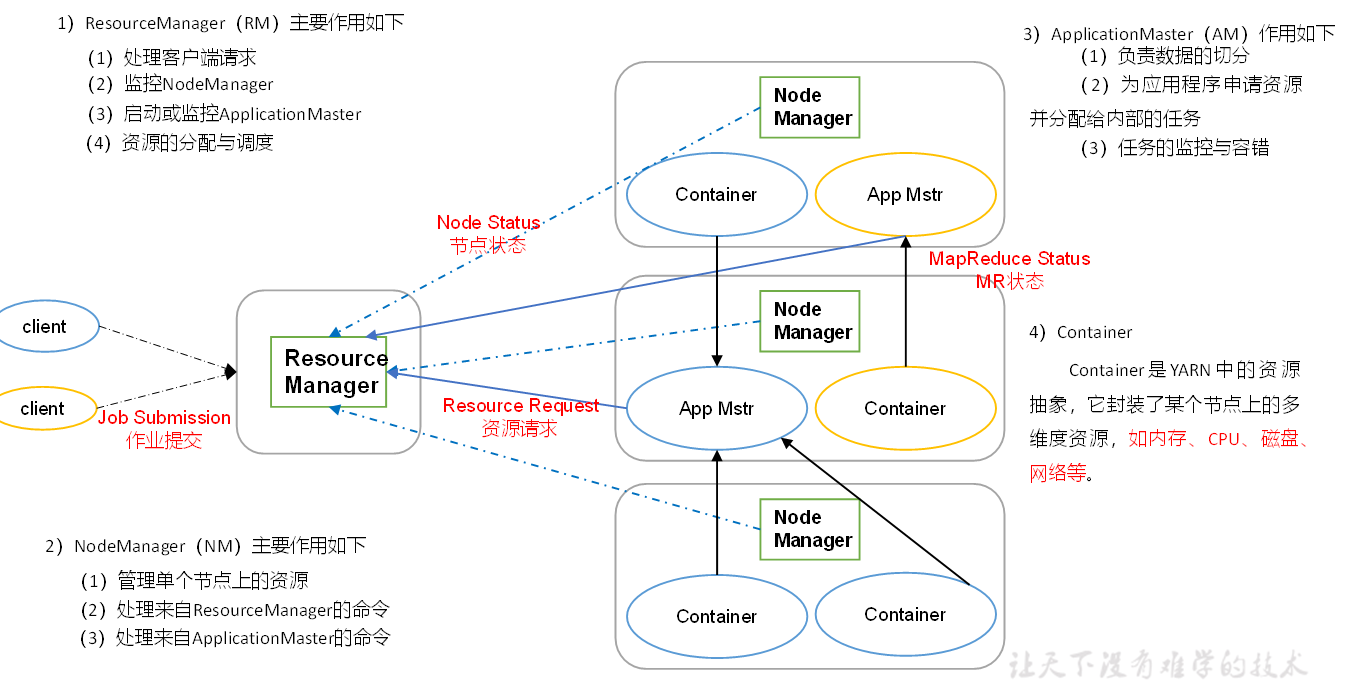
YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
Hadoop运行环境搭建
有多台阿里云,直接在阿里云上操作的
[root@iZbp1efx14jd8471u20gpaZ ~]# hostnamectl set-hostname hadoop001 [root@iZbp1efx14jd8471u20gpaZ ~]# cd /opt [root@iZbp1efx14jd8471u20gpaZ opt]# mkdir module [root@iZbp1efx14jd8471u20gpaZ opt]# mkdir software [root@iZbp1efx14jd8471u20gpaZ opt]# rpm -qa | grep java [root@iZbp1efx14jd8471u20gpaZ opt]# cd software/ [root@iZbp1efx14jd8471u20gpaZ software]# ll total 257012 -rw-r--r-- 1 root root 77660160 Jan 13 20:26 hadoop-2.7.2.tar.gz -rw-r--r-- 1 root root 185515842 Jan 13 20:24 jdk-8u144-linux-x64.tar.gz [root@iZbp1efx14jd8471u20gpaZ software]# tar -zvxf jdk-8u144-linux-x64.tar.gz /opt/module/ -C tar: option requires an argument -- 'C' Try `tar --help' or `tar --usage' for more information. [root@iZbp1efx14jd8471u20gpaZ software]# tar -zvxf jdk-8u144-linux-x64.tar.gz -C /opt/module/ jdk1.8.0_144/ jdk1.8.0_144/THIRDPARTYLICENSEREADME-JAVAFX.txt jdk1.8.0_144/THIRDPARTYLICENSEREADME.txt
[root@iZbp1efx14jd8471u20gpaZ module]# cd jdk1.8.0_144/ [root@iZbp1efx14jd8471u20gpaZ jdk1.8.0_144]# vi /etc/profile [root@iZbp1efx14jd8471u20gpaZ jdk1.8.0_144]# vi /etc/profile [root@iZbp1efx14jd8471u20gpaZ jdk1.8.0_144]# source /etc/profile [root@iZbp1efx14jd8471u20gpaZ jdk1.8.0_144]# java -version java version "1.8.0_144" Java(TM) SE Runtime Environment (build 1.8.0_144-b01) Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode) [root@iZbp1efx14jd8471u20gpaZ jdk1.8.0_144]# cd ../../software/ [root@iZbp1efx14jd8471u20gpaZ software]# ll total 374200 -rw-r--r-- 1 root root 197657687 Jan 13 20:30 hadoop-2.7.2.tar.gz -rw-r--r-- 1 root root 185515842 Jan 13 20:24 jdk-8u144-linux-x64.tar.gz [root@iZbp1efx14jd8471u20gpaZ software]# tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/ hadoop-2.7.2/ hadoop-2.7.2/NOTICE.txt hadoop-2.7.2/etc/ hadoop-2.7.2/etc/hadoop/ hadoop-2.7.2/etc/hadoop/kms-log4j.properties
[root@iZbp1efx14jd8471u20gpaZ hadoop-2.7.2]# vi /etc/profile [root@iZbp1efx14jd8471u20gpaZ hadoop-2.7.2]# source /etc/profile [root@iZbp1efx14jd8471u20gpaZ hadoop-2.7.2]# hadoop -version Error: No command named `-version' was found. Perhaps you meant `hadoop version' [root@iZbp1efx14jd8471u20gpaZ hadoop-2.7.2]# hadoop version Hadoop 2.7.2 Subversion Unknown -r Unknown Compiled by root on 2017-05-22T10:49Z Compiled with protoc 2.5.0 From source with checksum d0fda26633fa762bff87ec759ebe689c This command was run using /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar [root@iZbp1efx14jd8471u20gpaZ hadoop-2.7.2]# hadoop Usage: hadoop [--config confdir] [COMMAND | CLASSNAME] CLASSNAME run the class named CLASSNAME or where COMMAND is one of: fs run a generic filesystem user client version print the version jar <jar> run a jar file note: please use "yarn jar" to launch YARN applications, not this command. checknative [-a|-h] check native hadoop and compression libraries availability distcp <srcurl> <desturl> copy file or directories recursively archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive classpath prints the class path needed to get the credential interact with credential providers Hadoop jar and the required libraries daemonlog get/set the log level for each daemon trace view and modify Hadoop tracing settings Most commands print help when invoked w/o parameters. [root@iZbp1efx14jd8471u20gpaZ hadoop-2.7.2]#
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号