Logstash介绍及Input插件介绍
一、Logstash简介
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
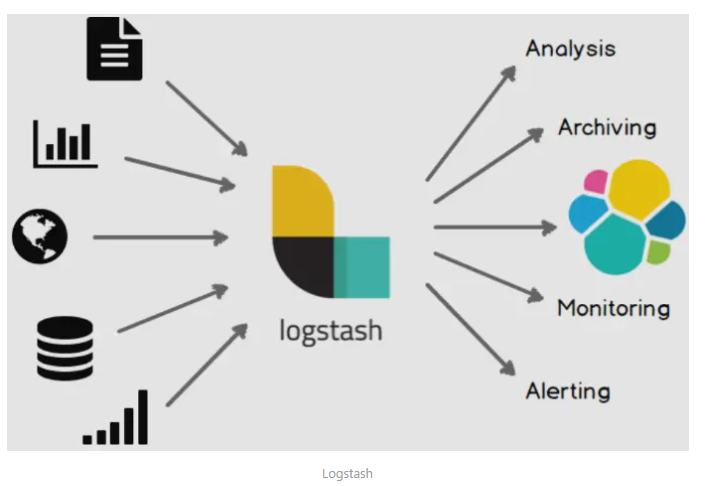
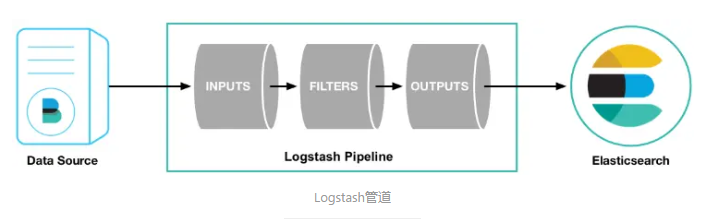
Logstash管道有两个必需的元素,输入和输出,以及一个可选元素过滤器。输入插件从数据源那里消费数据,过滤器插件根据你的期望修改数据,输出插件将数据写入目的地。
输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
利用 Grok 从非结构化数据中派生出结构
从 IP 地址破译出地理坐标
将 PII(个人验证信息) 数据匿名化,完全排除敏感字段
整体处理不受数据源、格式或架构的影响
输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
logstash是做数据采集的,类似于flume。
Logstash架构:
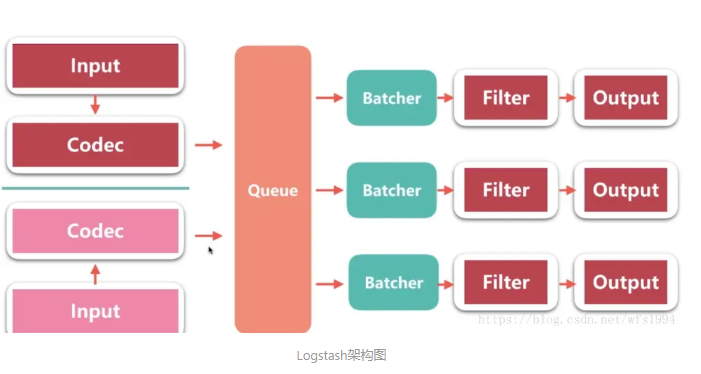
Batcher负责批量的从queue中取数据;
Queue分类:
In Memory : 无法处理进程Crash、机器宕机等情况,会导致数据丢失
Persistent Queue In Disk:可处理进程Crash等情况,保证数据不丢失,保证数据至少消费一次,充当缓冲区,可以替代kafka等消息队列的作用。
二、Input插件
|
Plugin |
Description |
Github repository |
|
Receives events from Azure Event Hubs |
||
|
Receives events from the Elastic Beats framework |
||
|
Pulls events from the Amazon Web Services CloudWatch API |
||
|
Streams events from CouchDB’s |
||
|
read events from Logstash’s dead letter queue |
||
|
Reads query results from an Elasticsearch cluster |
||
|
Captures the output of a shell command as an event |
||
|
Streams events from files |
||
|
Reads Ganglia packets over UDP |
||
|
Reads GELF-format messages from Graylog2 as events |
||
|
Generates random log events for test purposes |
||
|
Reads events from a GitHub webhook |
||
|
Extract events from files in a Google Cloud Storage bucket |
||
|
Consume events from a Google Cloud PubSub service |
||
|
Reads metrics from the |
||
|
Generates heartbeat events for testing |
||
|
Receives events over HTTP or HTTPS |
||
|
Decodes the output of an HTTP API into events |
||
|
Reads mail from an IMAP server |
||
|
Reads events from an IRC server |
||
|
Generates synthetic log events |
||
|
Reads events from standard input |
||
|
Creates events from JDBC data |
||
|
Reads events from a Jms Broker |
||
|
Retrieves metrics from remote Java applications over JMX |
||
|
Reads events from a Kafka topic |
||
|
Receives events through an AWS Kinesis stream |
||
|
Reads events over a TCP socket from a Log4j |
||
|
Receives events using the Lumberjack protocl |
||
|
Captures the output of command line tools as an event |
||
|
Streams events from a long-running command pipe |
||
|
Receives facts from a Puppet server |
||
|
Pulls events from a RabbitMQ exchange |
||
|
Reads events from a Redis instance |
||
|
Receives RELP events over a TCP socket |
||
|
Captures the output of command line tools as an event |
||
|
Streams events from files in a S3 bucket |
||
|
Creates events based on a Salesforce SOQL query |
||
|
Polls network devices using Simple Network Management Protocol (SNMP) |
||
|
Creates events based on SNMP trap messages |
||
|
Creates events based on rows in an SQLite database |
||
|
Pulls events from an Amazon Web Services Simple Queue Service queue |
||
|
Reads events from standard input |
||
|
Creates events received with the STOMP protocol |
||
|
Reads syslog messages as events |
||
|
Reads events from a TCP socket |
||
|
Reads events from the Twitter Streaming API |
||
|
Reads events over UDP |
||
|
Reads events over a UNIX socket |
||
|
Reads from the |
||
|
Reads events from a websocket |
||
|
Creates events based on the results of a WMI query |
||
|
Receives events over the XMPP/Jabber protocol |
举例几个常用的input来源:
注:以下为谷歌翻译,可能会出现部分偏差。
Beats输入插件
该输入插件使Logstash可以从Elastic Beats框架接收事件 。
以下示例显示如何配置Logstash以在端口5044上侦听传入的Beats连接并索引到Elasticsearch。
input { beats { port => 5044 } } output { elasticsearch { hosts => ["http://localhost:9200"] index => "%{[@metadata][beat]}-%{[@metadata][version]}" } }
使用此处显示的Logstash配置索引到Elasticsearch中的事件将类似于Beats直接索引到Elasticsearch中的事件。
如果未使用ILM,则将其设置index为, %{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}以便Logstash每天根据@timestampBeats事件的值创建一个索引。
如果要传送跨越多行的事件,则需要使用Filebeat中可用的配置选项来处理多行事件,然后再将事件数据发送到Logstash。您不能使用 多行编解码器插件来处理多行事件。这样做将导致无法启动Logstash。
Versioned Beats Indices
为了最大程度地减少未来架构更改对Elasticsearch中现有索引和映射的影响,请配置Elasticsearch输出以写入版本索引。您为index设置指定的模式控制索引名称:
index = > “%{[@@ metadata] [beat]}-%{[@@ metadata] [version]}-%{+ YYYY.MM.dd}”
%{[@metadata][beat]}- 将索引名称的第一部分设置为
beat元数据字段的值,例如filebeat。 %{[@metadata][version]}- 将名称的第二部分设置为Beat版本,例如
7.4.2。 %{+YYYY.MM.dd}- 根据Logstash
@timestamp字段将名称的第三部分设置为日期。
此配置产生每日索引名称,例如 filebeat-7.4.2-2019-11-27。
该插件支持以下配置选项以及稍后介绍的“ 通用选项”。
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
布尔值 |
没有 |
|
没有 |
||
|
没有 |
||
|
没有 |
||
|
没有 |
||
|
是 |
||
|
没有 |
||
|
有效的文件系统路径 |
没有 |
|
|
没有 |
||
|
没有 |
||
|
有效的文件系统路径 |
没有 |
|
|
没有 |
||
|
字符串,其中之一 |
没有 |
|
|
没有 |
||
|
没有 |
||
|
没有 |
- 值类型为数组
- 默认值为
java.lang.String[TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384, TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384, TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256, TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256, TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384, TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384, TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256, TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256]@459cfcca
要使用的密码套件列表,按优先级列出。
client_inactivity_timeout
- 值类型是数字
- 默认值为
60
X秒钟不活动后,关闭空闲客户端。
host
- 值类型为字符串
- 默认值为
"0.0.0.0"
要监听的IP地址。
include_codec_tag
- 值类型为布尔值
- 默认值为
true
port
- 这是必需的设置。
- 值类型是数字
- 此设置没有默认值。
要监听的端口。
ssl
- 值类型为布尔值
- 默认值为
false
默认情况下,事件以纯文本发送。您可以通过设置ssl为true并配置ssl_certificate和ssl_key选项来启用加密。
ssl_certificate
- 值类型是路径
- 此设置没有默认值。
要使用的SSL证书。
ssl_certificate_authorities
- 值类型为数组
- 默认值为
[]
根据这些权限验证客户证书。您可以定义多个文件或路径。所有证书将被读取并添加到信任存储中。您需要配置ssl_verify_mode 到peer或force_peer启用验证。
ssl_handshake_timeout
- 值类型是数字
- 默认值为
10000
ssl握手不完整超时的时间(以毫秒为单位)
ssl_key
- 值类型是路径
- 此设置没有默认值。
要使用的SSL密钥。注意:该密钥必须为PKCS8格式,您可以使用OpenSSL对其 进行转换以获取更多信息。
ssl_key_passphrase
- 值类型为密码
- 此设置没有默认值。
要使用的SSL密钥密码。
ssl_verify_mode
- 值可以是任何的:
none,peer,force_peer - 默认值为
"none"
默认情况下,服务器不执行任何客户端验证。
peer将使服务器要求客户端提供证书。如果客户端提供证书,则将对其进行验证。
force_peer将使服务器要求客户端提供证书。如果客户端不提供证书,则连接将关闭。
此选项需要与ssl_certificate_authoritiesCA 一起使用,并已定义了CA列表。
ssl_peer_metadata
- 值类型为布尔值
- 默认值为
false
允许在事件的元数据中存储客户端证书信息。
仅当ssl_verify_mode设置为peer或时,此选项才有效force_peer。
tls_max_version
- 值类型是数字
- 默认值为
1.2
加密连接允许的最大TLS版本。该值必须是以下之一:TLS 1.0的1.0,TLS 1.1的1.1,TLS 1.2的1.2
tls_min_version
- 值类型是数字
- 默认值为
1
加密连接允许的最低TLS版本。该值必须是以下之一:TLS 1.0的1.0,TLS 1.1的1.1,TLS 1.2的1.2
常用选项
所有输入插件均支持以下配置选项:
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
杂凑 |
没有 |
|
|
编解码器 |
没有 |
|
|
布尔值 |
没有 |
|
|
串 |
没有 |
|
|
数组 |
没有 |
|
|
串 |
没有 |
add_field
- 值类型为哈希
- 默认值为
{}
向事件添加字段
codec
- 值类型为编解码器
- 默认值为
"plain"
用于输入数据的编解码器。输入编解码器是一种在数据输入之前解码数据的便捷方法,而无需在Logstash管道中使用单独的过滤器。
enable_metric
- 值类型为布尔值
- 默认值为
true
默认情况下,为此特定插件实例禁用或启用度量标准日志记录,我们会记录所有可以度量的数据,但是您可以禁用特定插件的度量标准收集。
id
- 值类型为字符串
- 此设置没有默认值。
ID向插件配置添加唯一。如果未指定ID,Logstash将生成一个。强烈建议在您的配置中设置此ID。当您有两个或多个相同类型的插件时(例如,如果您有2个拍子输入),这特别有用。在这种情况下,添加命名ID将有助于在使用监视API时监视Logstash。
input {
beats {
id => "my_plugin_id"
}
}
tags
- 值类型为数组
- 此设置没有默认值。
将任意数量的任意标签添加到您的事件中。
这可以帮助以后进行处理。
type
- 值类型为字符串
- 此设置没有默认值。
type向此输入处理的所有事件添加一个字段。
新发现并从头开始读取。因此,复制的文件路径不应位于要监视的文件名模式中(该path选项)。将检测到截断,并将“最后读取”位置更新为零。
File输入配置选项
该插件支持以下配置选项以及稍后介绍的“ 通用选项”。
持续时间设置可以以文本形式指定,例如“ 250 ms”,该字符串将转换为十进制秒。有很多受支持的自然和缩写持续时间,有关详细信息,请参见string_duration。
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
数字或string_duration |
没有 |
|
|
串 |
没有 |
|
|
数 |
没有 |
|
|
数组 |
没有 |
|
|
数 |
没有 |
|
|
数 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
串 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
数字或string_duration |
没有 |
|
|
数 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
数组 |
是 |
|
|
数字或string_duration |
没有 |
|
|
串 |
没有 |
|
|
数字或string_duration |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
数字或string_duration |
没有 |
ose_older
- 值类型是数字或string_duration
- 默认值为
"1 hour"
文件输入将关闭最后一次读取指定持续时间(如果指定了数字,则为秒)的所有文件。根据文件是尾部还是读取,这具有不同的含义。如果拖尾,并且传入数据有很大的时间间隔,则可以关闭文件(允许打开其他文件),但是当检测到新数据时,将排队等待重新打开文件。如果正在读取,则从读取最后一个字节起,在closed_older秒后将关闭文件。如果将插件升级到4.1.0+,则此设置将保留,以实现向后兼容,并且读取不会拖尾并且不切换为使用读取模式。
delimiter
- 值类型为字符串
- 默认值为
"\n"
设置新行分隔符,默认为“ \ n”。请注意,在读取压缩文件时,不会使用此设置,而是使用标准Windows或Unix行结尾。
discover_interval
- 值类型是数字
- 默认值为
15
我们多长时间扩展一次path选项中的文件名模式,以发现要观看的新文件。该值是的倍数stat_interval,例如,如果stat_interval是“ 500 ms”,则可以每15 X 500毫秒-7.5秒发现新文件文件。实际上,这是最好的情况,因为需要考虑读取新内容所花费的时间。
exclude
- 值类型为数组
- 此设置没有默认值。
排除项(与文件名匹配,不是完整路径)。文件名模式在这里也是有效的。例如,如果您有
路径=> “ / var / log / *”
在尾模式下,您可能要排除压缩文件:
排除=> “ * .gz”
file_chunk_count
- 值类型是数字
- 默认值为
4611686018427387903
与结合使用时file_chunk_size,此选项设置在移至下一个活动文件之前从每个文件读取多少块(带或条纹)。例如,file_chunk_count32和file_chunk_size32KB的a 将处理每个活动文件中的下一个1MB。由于默认值非常大,因此在移至下一个活动文件之前,该文件已有效读取到EOF。
file_chunk_size
- 值类型是数字
- 默认值为
32768(32KB)
从磁盘上以块或块的形式读取文件内容,并从块中提取行。请参阅file_chunk_count以了解为什么和何时从默认设置更改此设置。
file_completed_action
- 值可以是任何的:
delete,log,log_and_delete - 默认值为
delete。
在read模式下,完成文件后应执行什么动作。如果指定了删除,则文件将被删除。如果指定了日志,则文件的完整路径将记录到file_completed_log_path设置中指定的文件中 。如果log_and_delete指定,则以上两个动作都会发生。
file_completed_log_path
- 值类型为字符串
- 此设置没有默认值。
完全读取的文件路径应附加到哪个文件。只有当指定文件这条道路file_completed_action是日志或log_and_delete。重要说明:此文件仅附加到-可能会变得很大。您负责文件轮换。
file_sort_by
- 值可以是任何的:
last_modified,path - 默认值为
last_modified。
应该使用“监视”文件的哪个属性对其进行排序。文件可以按修改日期或全路径字母排序。以前,发现并因此“监视”的文件的处理顺序取决于操作系统。
file_sort_direction
- 值可以是任何的:
asc,desc - 默认值为
asc。
排序“监视”的文件时,在升序和降序之间进行选择。如果最旧的数据优先,那么last_modified+ 的默认值asc很好。如果首先获取最新数据更为重要,则选择last_modified+ desc。如果对文件的完整路径使用特殊的命名约定,则path+ 可能 asc会帮助控制文件处理的顺序。
ignore_older
- 值类型是数字或string_duration
- 此设置没有默认值。
当文件输入发现在指定持续时间(如果指定了数字,则为秒)之前最后修改的文件时,将忽略该文件。发现后,如果修改了忽略的文件,则不再忽略它,并且读取任何新数据。默认情况下,此选项是禁用的。请注意,该单位以秒为单位。
max_open_files
- 值类型是数字
- 此设置没有默认值。
此输入一次一次消耗的file_handles的最大数量是多少。如果您需要处理的文件数量超过此数目,请使用close_older关闭一些文件。不应将其设置为OS可以执行的最大操作,因为其他LS插件和OS进程需要文件句柄。内部默认设置为4095。
mode
- 值可以是
tail或read。 - 默认值为
tail。
您希望文件输入以哪种模式操作。尾部几个文件或读取许多内容完整的文件。读取模式现在支持gzip文件处理。如果指定了“读取”,则将忽略以下其他设置:
start_position(始终从头开始读取文件)close_older(到达EOF时文件自动关闭)
如果指定为“ read”,则注意以下设置:
ignore_older(旧文件未处理)file_completed_action(处理文件时应采取什么措施)file_completed_log_path(完整的文件路径应记录到哪个文件)
path
- 这是必需的设置。
- 值类型为数组
- 此设置没有默认值。
用作输入的文件的路径。您可以在此处使用文件名模式,例如/var/log/*.log。如果您使用的模式/var/log/**/*.log,/var/log则将对所有*.log文件进行递归搜索。路径必须是绝对路径,不能是相对路径。
您也可以配置多个路径。请参阅Logstash配置页面上的示例。
sincedb_clean_after
- 值类型是数字或string_duration
- 此设置的默认值为“ 2周”。
- 如果指定了一个数字,则将其解释为天,可以是十进制,例如0.5是12小时。
现在,sincedb记录具有与其关联的最后一个活动时间戳记。如果在过去N天内未在跟踪文件中检测到任何更改,则它的sincedb跟踪记录将过期,并且不会保留。此选项有助于防止索引节点回收问题。Filebeat有一个有关inode回收的常见问题解答。
sincedb_path
- 值类型为字符串
- 此设置没有默认值。
sincedb数据库文件的路径(保留跟踪的日志文件的当前位置的路径),该路径将被写入磁盘。默认情况下会将sincedb文件写入到<path.data>/plugins/inputs/file NOTE:它必须是文件路径,而不是目录路径
sincedb_write_interval
- 值类型是数字或string_duration
- 默认值为
"15 seconds"
自监视的日志文件的当前位置起写入数据库的频率(以秒为单位)。
start_position
- 值可以是任何的:
beginning,end - 默认值为
"end"
选择Logstash最初从哪个位置开始读取文件:在开头还是结尾。默认行为将文件视为实时流,因此从结尾开始。如果您要导入的旧数据,请将其设置为Beginning。
此选项仅修改文件为新文件且之前未曾查看过的“首次联系”情况,即Logstash读取的sincedb文件中未记录当前位置的文件。如果以前已经看过文件,则此选项无效,并且将使用sincedb文件中记录的位置。
stat_interval
- 值类型是数字或string_duration
- 默认值为
"1 second"
我们统计文件的频率(以秒为单位),以查看它们是否已被修改。增加此间隔将减少我们进行的系统调用的数量,但会增加检测新日志行的时间。
发现新文件并检查它们是否已增长/收缩。该循环将休眠stat_interval数秒,然后再次循环。但是,如果文件已增长,则将读取新内容并排队。跨所有增长的文件进行读取和排队可能会花费一些时间,尤其是在管道拥塞的情况下。因此,整个循环时间是stat_interval和文件读取时间的组合 。
常用选项
所有输入插件均支持以下配置选项:
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
杂凑 |
没有 |
|
|
编解码器 |
没有 |
|
|
布尔值 |
没有 |
|
|
串 |
没有 |
|
|
数组 |
没有 |
|
|
串 |
没有 |
add_field
- 值类型为哈希
- 默认值为
{}
向事件添加字段
codec
- 值类型为编解码器
- 默认值为
"plain"
用于输入数据的编解码器。输入编解码器是一种在数据输入之前解码数据的便捷方法,而无需在Logstash管道中使用单独的过滤器。
enable_metric
- 值类型为布尔值
- 默认值为
true
默认情况下,为此特定插件实例禁用或启用度量标准日志记录,我们会记录所有可以度量的数据,但是您可以禁用特定插件的度量标准收集。
id
- 值类型为字符串
- 此设置没有默认值。
ID向插件配置添加唯一。如果未指定ID,Logstash将生成一个。强烈建议在您的配置中设置此ID。当您有两个或多个相同类型的插件时(例如,如果您有2个文件输入),这特别有用。在这种情况下,添加命名ID将有助于在使用监视API时监视Logstash。
输入{
文件{
id => “ my_plugin_id” } }
tags
- 值类型为数组
- 此设置没有默认值。
将任意数量的任意标签添加到您的事件中。
这可以帮助以后进行处理。
type
- 值类型为字符串
- 此设置没有默认值。
type向此输入处理的所有事件添加一个字段。
JDBC配置选项
计划
可以将来自此插件的输入安排为根据特定计划定期运行。此调度语法由rufus-scheduler支持。该语法类似于cron,具有一些特定于Rufus的扩展(例如时区支持)。
例子:
|
|
从一月到三月的每天凌晨5点每分钟执行一次。 |
|
|
将在每天每小时的第0分钟执行。 |
|
|
每天早上6:00(UTC / GMT -5)执行。 |
可以在此处找到描述此语法的更多文档。
状态
插件将以sql_last_value元数据文件的形式保存配置文件中的参数last_run_metadata_path。执行查询后,该文件将更新为的当前值sql_last_value。下次管道启动时,将通过从文件中读取来更新此值。如果 clean_run设置为true,则将忽略此值并将其sql_last_value设置为1970年1月1日;如果use_column_value为true,则将其设置为0 ,就好像从未执行过任何查询一样。
处理大型结果集
许多JDBC驱动程序使用该fetch_size参数来限制一次从游标到客户端缓存中一次预取多少结果,然后再从结果集中检索更多结果。这是使用jdbc_fetch_size配置选项在此插件中配置的。默认情况下,此插件未设置提取大小,因此将使用特定驱动程序的默认大小。
用法:
这是设置插件以从MySQL数据库获取数据的示例。首先,我们在当前路径中放置适当的JDBC驱动程序库(可以将其放置在文件系统上的任何位置)。在此示例中,我们使用用户mysql连接到mydb数据库,并希望在songs 表中输入与特定艺术家匹配的所有行。以下示例演示了为此可能的Logstash配置。此示例中的选项将指示插件每分钟在每分钟执行一次此输入语句。schedule
input { jdbc { jdbc_driver_library => "mysql-connector-java-5.1.36-bin.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb" jdbc_user => "mysql" parameters => { "favorite_artist" => "Beethoven" } schedule => "* * * * *" statement => "SELECT * from songs where artist = :favorite_artist" } }
配置SQL语句
此输入需要sql语句。这可以通过字符串形式的语句选项传入,也可以从文件(statement_filepath)中读取。当配置中提供的SQL语句很大或很麻烦时,通常使用File选项。file选项仅支持一个SQL语句。该插件仅接受以下选项之一。它无法从文件以及statement配置参数中读取语句。
配置多个SQL语句
当需要从不同的数据库表或视图中查询和提取数据时,配置多个SQL语句很有用。可以为每个语句定义单独的Logstash配置文件,或者在一个配置文件中定义多个语句。在单个Logstash配置文件中使用多个语句时,必须将每个语句定义为单独的jdbc输入(包括jdbc驱动程序,连接字符串和其他必需的参数)。
请注意,如果任何语句使用sql_last_value参数(例如,仅提取自上次运行以来更改的数据),则每个输入都应定义自己的 last_run_metadata_path参数。否则,将导致不良行为,因为所有输入都会将其状态存储到同一(默认)元数据文件中,从而有效覆盖彼此的sql_last_value。
预定义的参数
一些参数是内置的,可以在查询中使用。这是清单:
|
sql_last_value |
用于计算要查询的行的值。在运行任何查询之前,将其设置为1970年1月1日(星期四),如果设置 |
例:
input { jdbc { statement => "SELECT id, mycolumn1, mycolumn2 FROM my_table WHERE id > :sql_last_value" use_column_value => true tracking_column => "id" # ... other configuration bits } }
预处理语句
使用服务器端准备好的语句可以加快执行速度,因为服务器可以优化查询计划和执行。
并非所有的JDBC可访问技术都将支持准备好的语句。
随着Prepared Statement支持的引入,带来了不同的代码执行路径和一些新设置。现有的大多数设置仍然有用,但是有一些新的设置可供预读语句读取。使用布尔值设置use_prepared_statements启用此执行模式。使用该prepared_statement_name设置为“ Prepared Statement”指定名称,这将在本地和远程标识“ Prepared Statement”,并且它在配置和数据库中应该是唯一的。使用prepared_statement_bind_values数组设置来指定绑定值,:sql_last_value为前面提到的预定义参数使用精确的字符串(必要时多次)。该statement(或statement_path)设置仍保存SQL语句,但使用必须使用绑定变量?字符,按在prepared_statement_bind_values数组中找到的确切顺序作为占位符。
目前不支持围绕预备语句构建计数查询,并且由于jdbc分页在后台使用计数查询,因此此时预备语句也不支持jdbc分页。因此,使用准备好的语句时jdbc_paging_enabled,jdbc_page_size设置将被忽略。
例:
input { jdbc { statement => "SELECT * FROM mgd.seq_sequence WHERE _sequence_key > ? AND _sequence_key < ? + ? ORDER BY _sequence_key ASC" prepared_statement_bind_values => [":sql_last_value", ":sql_last_value", 4] prepared_statement_name => "foobar" use_prepared_statements => true use_column_value => true tracking_column_type => "numeric" tracking_column => "_sequence_key" last_run_metadata_path => "/elastic/tmp/testing/confs/test-jdbc-int-sql_last_value.yml" # ... other configuration bits } }
Jdbc输入配置选项编辑
该插件支持以下配置选项以及稍后介绍的“ 通用选项”。
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
布尔值 |
没有 |
|
|
Hash |
没有 |
|
|
数 |
没有 |
|
|
数 |
没有 |
|
|
串 |
是 |
|
|
串 |
没有 |
|
|
串 |
是 |
|
|
串 |
没有 |
|
|
数 |
没有 |
|
|
数 |
没有 |
|
|
布尔值 |
没有 |
|
|
密码 |
没有 |
|
|
有效的文件系统路径 |
没有 |
|
|
数 |
没有 |
|
|
串 |
是 |
|
|
布尔值 |
没有 |
|
|
数 |
没有 |
|
|
串 |
没有 |
|
|
布尔值 |
没有 |
|
|
杂凑 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
数组 |
没有 |
|
|
串 |
没有 |
|
|
布尔值 |
没有 |
|
|
串 |
没有 |
|
|
杂凑 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
串 |
没有 |
|
|
有效的文件系统路径 |
没有 |
|
|
串 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
布尔值 |
没有 |
|
|
布尔值 |
没有 |
clean_run
- 值类型为布尔值
- 默认值为
false
是否应保留先前的运行状态
columns_charset
- 值类型为哈希
- 默认值为
{}
特定列的字符编码。此选项将覆盖:charset指定列的选项。
例:
input {
jdbc {
...
columns_charset => { "column0" => "ISO-8859-1" }
...
}
}
connection_retry_attempts
- 值类型是数字
- 默认值为
1
尝试连接数据库的最大次数
connection_retry_attempts_wait_time
- 值类型是数字
- 默认值为
0.5
两次尝试之间休眠的秒数
jdbc_connection_string
- 这是必需的设置。
- 值类型为字符串
- 此设置没有默认值。
JDBC连接字符串
jdbc_default_timezone
- 值类型为字符串
- 此设置没有默认值。
时区转换。Logstash(和Elasticsearch)期望时间戳以UTC术语表示。如果您的数据库记录了相对于另一个时区的时间戳,则将记录该数据库的时区,然后将此设置设置为数据库使用的时区。但是,由于SQL不允许在时间戳字段中提供时区数据,因此我们无法逐条记录地进行计算。此插件将以ISO8601格式的相对UTC时间自动将您的SQL时间戳字段转换为Logstash时间戳。
使用此设置将手动分配指定的时区偏移,而不是使用本地计算机的时区设置。例如,您必须使用标准时区,例如America / Denver。
plugin_timezone
- 值可以是任何的:
utc,local - 默认值为
"utc"
如果您希望此插件将时间戳偏移到UTC以外的时区,则可以将此设置设置为local,插件将使用OS时区进行偏移调整。
注意:当指定plugin_timezone和/或时jdbc_default_timezone,偏移量调整在两个地方进行,如果sql_last_value是时间戳,并且在语句中用作参数,则偏移量调整将从插件时区到数据时区,并且在处理记录时,时间戳从数据库时区偏移到插件时区。如果您的数据库时区为UTC,则无需设置这些设置中的任何一个。
jdbc_driver_class
- 这是必需的设置。
- 值类型为字符串
- 此设置没有默认值。
如果要使用Oracle JDBC ,则按https://github.com/logstash-plugins/logstash-input-jdbc/issues/43加载的JDBC驱动程序类,例如“ org.apache.derby.jdbc.ClientDriver” NB。驱动程序(ojdbc6.jar)正确jdbc_driver_class是"Java::oracle.jdbc.driver.OracleDriver"
jdbc_driver_library
- 值类型为字符串
- 此设置没有默认值。
尝试将JDBC逻辑抽象为mixin,以便在其他插件(输入/输出)中潜在地重用。当某人包含此模块时,将调用此方法。将这些方法添加到给定的基础中。第三方驱动程序库的JDBC驱动程序库路径。如果需要多个库,可以通过逗号分隔它们。
如果未提供,则插件将在Logstash Java类路径中查找驱动程序类。
jdbc_fetch_size
- 值类型是数字
- 此设置没有默认值。
JDBC提取大小。如果未提供,将使用各自的驱动程序默认值
jdbc_page_size
- 值类型是数字
- 默认值为
100000
JDBC页面大小
jdbc_paging_enabled
- 值类型为布尔值
- 默认值为
false
JDBC启用分页
这将导致sql语句分解为多个查询。每个查询将使用限制和偏移量来集体检索完整的结果集。限制大小通过设置jdbc_page_size。
请注意,不能保证查询之间的顺序。
jdbc_password
- 值类型为密码
- 此设置没有默认值。
JDBC密码
jdbc_password_filepath
- 值类型是路径
- 此设置没有默认值。
JDBC密码文件名
jdbc_pool_timeout
- 值类型是数字
- 默认值为
5
连接池配置。引发PoolTimeoutError之前等待获取连接的秒数(默认为5)
jdbc_user
- 这是必需的设置。
- 值类型为字符串
- 此设置没有默认值。
JDBC用户
jdbc_validate_connection
- 值类型为布尔值
- 默认值为
false
连接池配置。使用前验证连接。
jdbc_validation_timeout
- 值类型是数字
- 默认值为
3600
连接池配置。验证连接的频率(以秒为单位)
last_run_metadata_path
- 值类型为字符串
- 默认值为
"$HOME/.logstash_jdbc_last_run"
上次运行时间的文件路径
lowercase_column_names
- 值类型为布尔值
- 默认值为
true
是否强制使用标识符字段的小写
parameters
- 值类型为哈希
- 默认值为
{}
查询参数的散列,例如 { "target_id" => "321" }
prepared_statement_bind_values
- 值类型为数组
- 默认值为
[]
准备好的语句的绑定值数组。:sql_last_value是保留的预定义字符串
prepared_statement_name
- 值类型为字符串
- 默认值为
""
准备好的语句的名称。它在您的配置和数据库中必须是唯一的
record_last_run
- 值类型为布尔值
- 默认值为
true
是否保存状态 last_run_metadata_path
schedule
- 值类型为字符串
- 此设置没有默认值。
定期运行语句的时间表,例如Cron格式:“ * * * * *”(每分钟,每分钟执行一次查询)
默认情况下没有时间表。如果没有给出时间表,则该语句仅运行一次。
sequel_opts
- 值类型为哈希
- 默认值为
{}
常规/特定于供应商的续集配置选项。
可选连接池配置的示例max_connections-连接池的最大连接数
可以在此文档页面中找到特定于供应商的选项的示例:https : //github.com/jeremyevans/sequel/blob/master/doc/opening_databases.rdoc
sql_log_level
- 值可以是任何的:
fatal,error,warn,info,debug - 默认值为
"info"
记录SQL查询的日志级别,可接受的值是常见的致命,错误,警告,信息和调试值。默认值为info。
statement
- 值类型为字符串
- 此设置没有默认值。
如果未定义,则即使未使用编解码器,Logstash也会进行投诉。执行语句
要使用参数,请使用命名参数语法。例如:
“选择*从MYTABLE WHERE id =:target_id”
在这里,“:target_id”是一个命名参数。您可以使用该parameters设置配置命名参数。
statement_filepath
- 值类型是路径
- 此设置没有默认值。
包含要执行的语句的文件的路径
tracking_column
- 值类型为字符串
- 此设置没有默认值。
值将被跟踪的列use_column_value设置为true
tracking_column_type
- 值可以是任何的:
numeric,timestamp - 默认值为
"numeric"
跟踪列的类型。目前仅“数字”和“时间戳”
use_column_value
- 值类型为布尔值
- 默认值为
false
设置为时true,将定义的 tracking_column值用作:sql_last_value。设置为时false,:sql_last_value反映上一次执行查询的时间。
use_prepared_statements
- 值类型为布尔值
- 默认值为
false
设置为时true,启用prepare语句用法
常用选项
所有输入插件均支持以下配置选项:
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
杂凑 |
没有 |
|
|
编解码器 |
没有 |
|
|
布尔值 |
没有 |
|
|
串 |
没有 |
|
|
数组 |
没有 |
|
|
串 |
没有 |
add_field
- 值类型为哈希
- 默认值为
{}
向事件添加字段
codec
- 值类型为编解码器
- 默认值为
"plain"
用于输入数据的编解码器。输入编解码器是一种在数据输入之前解码数据的便捷方法,而无需在Logstash管道中使用单独的过滤器。
enable_metric
- 值类型为布尔值
- 默认值为
true
默认情况下,为此特定插件实例禁用或启用度量标准日志记录,我们会记录所有可以度量的数据,但是您可以禁用特定插件的度量标准收集。
id
- 值类型为字符串
- 此设置没有默认值。
ID向插件配置添加唯一。如果未指定ID,Logstash将生成一个。强烈建议在您的配置中设置此ID。当您有两个或多个相同类型的插件时,例如在您有2个jdbc输入时,这特别有用。在这种情况下,添加命名ID将有助于在使用监视API时监视Logstash。
输入{
jdbc {
id => “ my_plugin_id” } }
tags
- 值类型为数组
- 此设置没有默认值。
将任意数量的任意标签添加到您的事件中。
这可以帮助以后进行处理。
type
- 值类型为字符串
- 此设置没有默认值。
type向此输入处理的所有事件添加一个字段。
Kafka输入配置选项
其中一些选项映射到Kafka选项。有关更多详细信息,请参见https://kafka.apache.org/documentation。
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
数 |
没有 |
|
|
布尔值 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
有效的文件系统路径 |
没有 |
|
|
有效的文件系统路径 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
数 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
密码 |
没有 |
|
|
有效的文件系统路径 |
没有 |
|
|
密码 |
没有 |
|
|
串 |
没有 |
|
|
有效的文件系统路径 |
没有 |
|
|
密码 |
没有 |
|
|
串 |
没有 |
|
|
数组 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
auto_commit_interval_ms
- 值类型为字符串
- 默认值为
"5000"
消费者抵消被提交给Kafka的频率(以毫秒为单位)。
auto_offset_reset
- 值类型为字符串
- 此设置没有默认值。
Kafka中没有初始偏移量或偏移量超出范围时该怎么办:
- 最早:将偏移量自动重置为最早的偏移量
- 最新:自动将偏移量重置为最新偏移量
- none:如果未找到消费者组的先前偏移量,则向消费者抛出异常
- 其他:向消费者抛出异常。
bootstrap_servers
- 值类型为字符串
- 默认值为
"localhost:9092"
Kafka实例的URL列表,用于建立与集群的初始连接。host1:port1,host2:port2这些网址的形式应为这些url 。这些网址仅用于初始连接,以发现完整的集群成员身份(可能会动态更改),因此该列表不需要包含完整的服务器集(不过,您可能需要多个服务器,以防服务器宕机)。
check_crcs
- 值类型为字符串
- 此设置没有默认值。
自动检查消耗的记录的CRC32。这样可以确保不会发生在线或磁盘损坏消息的情况。此检查会增加一些开销,因此在寻求极端性能的情况下可能会禁用该检查。
client_id
- 值类型为字符串
- 默认值为
"logstash"
发出请求时传递给服务器的ID字符串。其目的是通过允许包含逻辑应用程序名称来跟踪IP /端口以外的请求源。
connections_max_idle_ms
- 值类型为字符串
- 此设置没有默认值。
在此配置指定的毫秒数后关闭空闲连接。
consumer_threads
- 值类型是数字
- 默认值为
1
理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡-线程多于分区意味着某些线程将处于空闲状态
decorate_events
- 值类型为布尔值
- 默认值为
false
向事件添加Kafka元数据(如主题,消息大小)的选项。这将添加一个名为kafkalogstash事件的字段,其中包含以下属性:
topic:此消息与之相关的主题consumer_group:此事件中曾经阅读的消费者组partition:此消息与之关联的分区offset:与该消息关联的分区的偏移量key:包含消息密钥的ByteBuffer
enable_auto_commit
- 值类型为字符串
- 默认值为
"true"
如果为true,则定期将使用方已经返回的消息的偏移量提交给Kafka。当处理失败时,将使用此已提交的偏移量作为开始消耗的位置。
exclude_internal_topics
- 值类型为字符串
- 此设置没有默认值。
内部主题的记录(例如偏移量)是否应向消费者公开。如果设置为true,则从内部主题接收记录的唯一方法是订阅该主题。
fetch_max_bytes
- 值类型为字符串
- 此设置没有默认值。
服务器为获取请求应返回的最大数据量。这不是绝对最大值,如果提取的第一个非空分区中的第一条消息大于此值,则仍将返回该消息以确保使用者可以取得进展。
fetch_max_wait_ms
- 值类型为字符串
- 此设置没有默认值。
如果没有足够的数据立即满足,服务器在响应提取请求之前将阻塞的最长时间fetch_min_bytes。此时间应小于或等于在poll_timeout_ms
fetch_min_bytes
- 值类型为字符串
- 此设置没有默认值。
服务器为获取请求应返回的最小数据量。如果没有足够的数据,则请求将等待该数据积累,然后再回答请求。
group_id
- 值类型为字符串
- 默认值为
"logstash"
该消费者所属的组的标识符。使用者组是一个逻辑订户,恰好由多个处理器组成。主题中的消息将以相同的方式分发到所有Logstash实例group_id
heartbeat_interval_ms
- 值类型为字符串
- 此设置没有默认值。
消费者协调员之间心跳的预期时间。心跳用于确保消费者的会话保持活动状态,并在新消费者加入或离开小组时促进重新平衡。该值必须设置为小于 session.timeout.ms,但通常应设置为不大于该值的1/3。可以将其调整得更低,以控制正常重新平衡的预期时间。
jaas_path
- 值类型是路径
- 此设置没有默认值。
Java身份验证和授权服务(JAAS)API为Kafka提供用户身份验证和授权服务。此设置提供JAAS文件的路径。Kafka客户端的样本JAAS文件:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useTicketCache=true
renewTicket=true
serviceName="kafka";
};
请注意,在配置文件中指定jaas_path和kerberos_config将把它们添加到全局JVM系统属性中。这意味着,如果您有多个Kafka输入,则所有这些都将共享 jaas_path和kerberos_config。如果不希望这样做,则必须在不同的JVM实例上运行Logstash的单独实例。
kerberos_config
- 值类型是路径
- 此设置没有默认值。
kerberos配置文件的可选路径。这是krb5.conf样式,如https://web.mit.edu/kerberos/krb5-1.12/doc/admin/conf_files/krb5_conf.html中所述
key_deserializer_class
- 值类型为字符串
- 默认值为
"org.apache.kafka.common.serialization.StringDeserializer"
用于反序列化记录键的Java类
max_partition_fetch_bytes
- 值类型为字符串
- 此设置没有默认值。
服务器将返回的每个分区的最大数据量。用于请求的最大总内存为#partitions * max.partition.fetch.bytes。此大小必须至少与服务器允许的最大消息大小一样大,否则,生产者有可能发送大于消费者可以获取的消息。如果发生这种情况,使用者可能会在尝试在某个分区上获取大消息时陷入困境。
max_poll_interval_ms
- 值类型为字符串
- 此设置没有默认值。
使用使用者组管理时,调用poll()之间的最大延迟。这为使用者在获取更多记录之前可以处于空闲状态的时间设置了上限。如果在此超时到期前未调用poll(),则认为使用方失败,该组将重新平衡以将分区重新分配给另一个成员。配置的值request_timeout_ms必须始终大于max_poll_interval_ms
max_poll_records
- 值类型为字符串
- 此设置没有默认值。
一次调用poll()返回的最大记录数。
metadata_max_age_ms
- 值类型为字符串
- 此设置没有默认值。
以毫秒为单位的时间段,在此之后,即使我们没有看到任何分区领导更改也可以强制刷新元数据以主动发现任何新的代理或分区
partition_assignment_strategy
- 值类型为字符串
- 此设置没有默认值。
客户端用于在使用者实例之间分配分区所有权的分区分配策略的类名称。映射到Kafka partition.assignment.strategy设置,默认设置为org.apache.kafka.clients.consumer.RangeAssignor。
poll_timeout_ms
- 值类型是数字
- 默认值为
100
时间卡夫卡消费者将等待接收来自主题的新消息
receive_buffer_bytes
- 值类型为字符串
- 此设置没有默认值。
读取数据时要使用的TCP接收缓冲区(SO_RCVBUF)的大小。
reconnect_backoff_ms
- 值类型为字符串
- 此设置没有默认值。
尝试重新连接到给定主机之前要等待的时间。这样可以避免以紧密的循环重复连接到主机。此退回适用于消费者发送给代理的所有请求。
request_timeout_ms
- 值类型为字符串
- 此设置没有默认值。
该配置控制客户端等待请求响应的最长时间。如果超时之前仍未收到响应,则客户端将在必要时重新发送请求,如果重试已用尽,则会使请求失败。
retry_backoff_ms
- 值类型为字符串
- 此设置没有默认值。
尝试对给定主题分区重试失败的获取请求之前等待的时间。这避免了在紧密的循环中反复进行获取和失败。
sasl_jaas_config
- 值类型为字符串
- 此设置没有默认值。
此插件实例本地的JAAS配置设置,与使用通过进行配置的配置文件(jaas_path通过JVM共享)相反。这允许每个插件实例都有其自己的配置。
如果同时设置sasl_jaas_config和jaas_path配置,则此处的设置优先。
示例(为Azure Event Hub设置):
input {
kafka {
sasl_jaas_config => "org.apache.kafka.common.security.plain.PlainLoginModule required username='auser' password='apassword';"
}
}
sasl_kerberos_service_name
- 值类型为字符串
- 此设置没有默认值。
Kafka代理运行时使用的Kerberos主体名称。这可以在Kafka的JAAS配置中定义,也可以在Kafka的配置中定义。
sasl_mechanism
- 值类型为字符串
- 默认值为
"GSSAPI"
用于客户端连接的SASL机制。这可以是安全提供程序可用的任何机制。GSSAPI是默认机制。
security_protocol
- 值可以是任何的:
PLAINTEXT,SSL,SASL_PLAINTEXT,SASL_SSL - 默认值为
"PLAINTEXT"
要使用的安全协议,可以是PLAINTEXT,SSL,SASL_PLAINTEXT,SASL_SSL之一
send_buffer_bytes
- 值类型为字符串
- 此设置没有默认值。
发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小
session_timeout_ms
- 值类型为字符串
- 此设置没有默认值。
超时后,如果poll_timeout_ms未调用,则将使用者标记为已死,并为由标识的组触发重新平衡操作group_id
ssl_endpoint_identification_algorithm
- 值类型为字符串
- 默认值为
"https"
端点识别算法,默认为"https"。设置为空字符串""以禁用端点验证
ssl_key_password
- 值类型为密码
- 此设置没有默认值。
密钥存储文件中私钥的密码。
ssl_keystore_location
- 值类型是路径
- 此设置没有默认值。
如果需要客户端身份验证,则此设置存储密钥库路径。
ssl_keystore_password
- 值类型为密码
- 此设置没有默认值。
如果需要客户端身份验证,则此设置存储密钥库密码
ssl_keystore_type
- 值类型为字符串
- 此设置没有默认值。
密钥库类型。
ssl_truststore_location
- 值类型是路径
- 此设置没有默认值。
用于验证Kafka经纪人证书的JKS信任库路径。
ssl_truststore_password
- 值类型为密码
- 此设置没有默认值。
信任库密码
ssl_truststore_type
- 值类型为字符串
- 此设置没有默认值。
信任库类型。
topics
- 值类型为数组
- 默认值为
["logstash"]
要订阅的主题列表,默认为[“ logstash”]。
topics_pattern
- 值类型为字符串
- 此设置没有默认值。
要订阅的主题正则表达式模式。使用此配置时,主题配置将被忽略。
value_deserializer_class
- 值类型为字符串
- 默认值为
"org.apache.kafka.common.serialization.StringDeserializer"
用于反序列化记录值的Java类
常用选项
所有输入插件均支持以下配置选项:
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
杂凑 |
没有 |
|
|
编解码器 |
没有 |
|
|
布尔值 |
没有 |
|
|
串 |
没有 |
|
|
数组 |
没有 |
|
|
串 |
没有 |
add_field
- 值类型为哈希
- 默认值为
{}
向事件添加字段
codec
- 值类型为编解码器
- 默认值为
"plain"
用于输入数据的编解码器。输入编解码器是一种在数据输入之前解码数据的便捷方法,而无需在Logstash管道中使用单独的过滤器。
enable_metric
- 值类型为布尔值
- 默认值为
true
默认情况下,为此特定插件实例禁用或启用度量标准日志记录,我们会记录所有可以度量的数据,但是您可以禁用特定插件的度量标准收集。
id
- 值类型为字符串
- 此设置没有默认值。
ID向插件配置添加唯一。如果未指定ID,Logstash将生成一个。强烈建议在您的配置中设置此ID。当您有两个或多个相同类型的插件时,例如在您有2个kafka输入时,这特别有用。在这种情况下,添加命名ID将有助于在使用监视API时监视Logstash。
input {
kafka {
id => "my_plugin_id"
}
}
tags
- 值类型为数组
- 此设置没有默认值。
将任意数量的任意标签添加到您的事件中。
这可以帮助以后进行处理。
type
- 值类型为字符串
- 此设置没有默认值。
type向此输入处理的所有事件添加一个字段。
均不支持批处理所使用的操作。
Redis输入配置选项
该插件支持以下配置选项以及稍后介绍的“ 通用选项”。
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
数 |
没有 |
|
|
字符串,其中之一 |
是 |
|
|
数 |
没有 |
|
|
串 |
没有 |
|
|
串 |
没有 |
|
|
串 |
是 |
|
|
密码 |
没有 |
|
|
数 |
没有 |
|
|
布尔值 |
没有 |
|
|
数 |
没有 |
|
|
数 |
没有 |
|
|
hash |
没有 |
另请参阅通用选项,以获取所有输入插件支持的选项列表。
batch_count
- 值类型是数字
- 默认值为
125
使用EVAL从Redis返回的事件数。
data_type
- 这是必需的设置。
- 值可以是任何的:
list,channel,pattern_channel - 此设置没有默认值。
指定列表或频道。如果data_type为list,则我们将对密钥进行BLPOP锁定。如果data_type为channel,那么我们将订阅该密钥。如果data_type为pattern_channel,则我们将订阅该密钥。
db
- 值类型是数字
- 默认值为
0
Redis数据库号。
host
- 值类型为字符串
- 默认值为
"127.0.0.1"
Redis服务器的主机名。
path
- 值类型为字符串
- 此设置没有默认值。
- 如果两者都指定,路径将覆盖主机配置。
Redis服务器的unix套接字路径。
key
- 这是必需的设置。
- 值类型为字符串
- 此设置没有默认值。
Redis列表或通道的名称。
password
- 值类型为密码
- 此设置没有默认值。
用于验证的密码。默认情况下没有身份验证。
port
- 值类型是数字
- 默认值为
6379
要连接的端口。
ssl
- 值类型为布尔值
- 默认值为
false
启用SSL支持。
threads
- 值类型是数字
- 默认值为
1
timeout
- 值类型是数字
- 默认值为
5
初始连接超时(以秒为单位)。
command_map
- 值类型为哈希
- 此设置没有默认值。
- key是默认命令名称,value是重命名的命令。
以“旧名称”⇒“新名称”的形式配置重命名的redis命令。Redis允许在其协议中重命名或禁用命令,请参见:https : //redis.io/topics/security
常用选项
所有输入插件均支持以下配置选项:
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
hash |
没有 |
|
|
编解码器 |
没有 |
|
|
布尔值 |
没有 |
|
|
串 |
没有 |
|
|
数组 |
没有 |
|
|
串 |
没有 |
详细信息
add_field
- 值类型为哈希
- 默认值为
{}
向事件添加字段
codec
- 值类型为编解码器
- 默认值为
"json"
用于输入数据的编解码器。输入编解码器是一种在数据输入之前解码数据的便捷方法,而无需在Logstash管道中使用单独的过滤器。
enable_metric
- 值类型为布尔值
- 默认值为
true
默认情况下,为此特定插件实例禁用或启用度量标准日志记录,我们会记录所有可以度量的数据,但是您可以禁用特定插件的度量标准收集。
id
- 值类型为字符串
- 此设置没有默认值。
ID向插件配置添加唯一。如果未指定ID,Logstash将生成一个。强烈建议在您的配置中设置此ID。当您有两个或两个以上相同类型的插件时,例如在您有2个redis输入时,此功能特别有用。在这种情况下,添加命名ID将有助于在使用监视API时监视Logstash。
input {
redis {
id => "my_plugin_id"
}
}
tags
- 值类型为数组
- 此设置没有默认值。
将任意数量的任意标签添加到您的事件中。
这可以帮助以后进行处理。
type
- 值类型为字符串
- 此设置没有默认值。
type向此输入处理的所有事件添加一个字段。
TCP输入插件
Tcp输入配置选项
该插件支持以下配置选项以及稍后介绍的“ 通用选项”。
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
串 |
没有 |
|
|
字符串,其中之一 |
没有 |
|
|
数 |
是 |
|
|
布尔值 |
没有 |
|
|
有效的文件系统路径 |
没有 |
|
|
数组 |
没有 |
|
|
布尔值 |
没有 |
|
|
数组 |
没有 |
|
|
有效的文件系统路径 |
没有 |
|
|
密码 |
没有 |
|
|
布尔值 |
没有 |
|
|
布尔值 |
没有 |
|
|
布尔值 |
没有 |
host
- 值类型为字符串
- 默认值为
"0.0.0.0"
当mode为时server,要监听的地址。当mode为时client,要连接的地址。
mode
- 值可以是任何的:
server,client - 默认值为
"server"
运行模式。server侦听客户端连接, client连接到服务器。
port
- 这是必需的设置。
- 值类型是数字
- 此设置没有默认值。
当mode为时server,要监听的端口。当mode为时client,要连接的端口。
proxy_protocol
- 值类型为布尔值
- 默认值为
false
代理协议支持,目前仅支持v1 http://www.haproxy.org/download/1.5/doc/proxy-protocol.txt
ssl_cert
- 值类型是路径
- 此设置没有默认值。
PEM格式的证书路径。该证书将显示给连接的客户端。
ssl_certificate_authorities
- 值类型为数组
- 默认值为
[]
根据这些权限验证客户证书或证书链。您可以定义多个文件或路径。所有证书将被读取并添加到信任存储中。
ssl_enable
- 值类型为布尔值
- 默认值为
false
启用SSL(必须设置其他ssl_选项才能生效)。
ssl_extra_chain_certs
- 值类型为数组
- 默认值为
[]
额外的X509证书的路径数组。这些证书与证书一起使用以构造提供给客户端的证书链。
ssl_key
- 值类型是路径
- 此设置没有默认值。
对应于指定证书(PEM格式)的私钥的路径。
ssl_key_passphrase
- 值类型为密码
- 默认值为
nil
私钥的SSL密钥密码。
ssl_verify
- 值类型为布尔值
- 默认值为
true
根据CA验证SSL连接另一端的身份。对于输入,将字段设置sslsubject为客户端证书的字段。
tcp_keep_alive
- 值类型为布尔值
- 默认值为
false
指示套接字使用TCP保持活动。使用操作系统默认设置保持活动设置。
dns_reverse_lookup_enabled
- 值类型为布尔值
- 默认值为
true
通过禁用此设置可以避免DNS反向查找。如果禁用,添加到事件的地址元数据将包含在TCP层指定的源地址,并且IP不会解析为主机名。
常用选项
所有输入插件均支持以下配置选项:
| 设置 | 输入类型 | 需要 |
|---|---|---|
|
|
杂凑 |
没有 |
|
|
编解码器 |
没有 |
|
|
布尔值 |
没有 |
|
|
串 |
没有 |
|
|
数组 |
没有 |
|
|
串 |
没有 |
详细信息编辑
add_field
- 值类型为哈希
- 默认值为
{}
向事件添加字段
codec
- 值类型为编解码器
- 默认值为
"line"
用于输入数据的编解码器。输入编解码器是一种在数据输入之前解码数据的便捷方法,而无需在Logstash管道中使用单独的过滤器。
enable_metric
- 值类型为布尔值
- 默认值为
true
默认情况下,为此特定插件实例禁用或启用度量标准日志记录,我们会记录所有可以度量的数据,但是您可以禁用特定插件的度量标准收集。
id
- 值类型为字符串
- 此设置没有默认值。
ID向插件配置添加唯一。如果未指定ID,Logstash将生成一个。强烈建议在您的配置中设置此ID。当您有两个或多个相同类型的插件时(例如,如果您有2个tcp输入),这特别有用。在这种情况下,添加命名ID将有助于在使用监视API时监视Logstash。
input {
tcp {
id => "my_plugin_id"
}
}
tags
- 值类型为数组
- 此设置没有默认值。
将任意数量的任意标签添加到您的事件中。
这可以帮助以后进行处理。
type
- 值类型为字符串
- 此设置没有默认值。
type向此输入处理的所有事件添加一个字段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号