



hive笔记梳理
1/ HIVE是什么?
HIVE是一个可以将sql翻译为MR程序的工具
HIVE支持用户将HDFS上的文件映射为表结构,然后用户就可以输入SQL对这些表(HDFS上的文件)进行查询分析
HIVE将用户定义的库、表结构等信息存储hive的元数据库(可以是本地derby,也可以是远程mysql)中
2/ HIVE的用途?
解放大数据分析程序员,不用自己写大量的mr程序来分析数据,只需要写sql脚本即可
HIVE可用于构建大数据体系下的数据仓库
3/ HIVE的使用方式?
方式1:可以交互式查询:
** bin/hive -----> hive>select * from t_test;
** 将hive启动为一个服务: bin/hiveserver ,然后可以在任意一台机器上使用beeline客户端连接hive服务,进行交互式查询
方式2:可以将hive作为命令一次性运行:
** bin/hive -e "sql1;sql2;sql3;sql4"
** 事先将sql语句写入一个文件比如 q.hql ,然后用hive命令执行: bin/hive -f q.hql
方式3:可以将方式2写入一个xxx.sh脚本中
4/ HIVE的DDL语法
建库: create database db1; ---> hive就会在/user/hive/warehouse/下建一个文件夹: db1.db
建内部表: use db1;
create table t_test1(id int,name string,age int,create_time bigint)
row format delimited
fields terminated by '\001';
建表后,hive会在仓库目录中建一个表目录: /user/hive/warehouse/db1.db/t_test1
建外部表:
create external table t_test1(id int,name string,age int,create_time bigint)
row format delimited
fields terminated by '\001'
location '/external/t_test';
导入数据:
本质上就是把数据文件放入表目录;
可以用hive命令来做:
hive> load data [local] inpath '/data/path' [overwrite] into table t_test;
**建分区表:
分区的意义在于可以将数据分子目录存储,以便于查询时让数据读取范围更精准;
create table t_test1(id int,name string,age int,create_time bigint)
partitioned by (day string,country string)
row format delimited
fields terminated by '\001';
插入数据到指定分区:
hive> load data [local] inpath '/data/path1' [overwrite] into table t_test partition(day='2017-06-04',country='China');
hive> load data [local] inpath '/data/path2' [overwrite] into table t_test partition(day='2017-06-05',country='China');
hive> load data [local] inpath '/data/path3' [overwrite] into table t_test partition(day='2017-06-04',country='England');
导入完成后,形成的目录结构如下:
/user/hive/warehouse/db1.db/t_test1/day=2017-06-04/country=China/...
/user/hive/warehouse/db1.db/t_test1/day=2017-06-04/country=England/...
/user/hive/warehouse/db1.db/t_test1/day=2017-06-05/country=China/...
表定义的修改:改表名、增加列,删除列,修改列定义.......
5/ HIVE的DML
基本查询语法跟标准sql基本一致
SELECT FIELDS,FUNCTION(FIELDS)
FROM T1
JOIN T2
WHERE CONDITION
GROUP BY FILEDS
HAVING CONDTION
ORDER BY FIELDS DESC|ASC
各类JOIN语法跟SQL也基本一致,不过HIVE有一个自己的特别的JOIN: LEFT SEMI JOIN
hive在1.2.0之前不支持“不等值”join,但在1.2.0后支持不等值join,只是语法必须按如下形式写:
SELECT A.*,B.* from A,B WHERE A.ID>B.ID;
各类流程控制语句根SQL也基本一致:
case when l.userid is null
then concat('hive',rand())
when l.userid > 20
then concat('hive',rand())
else l.userid
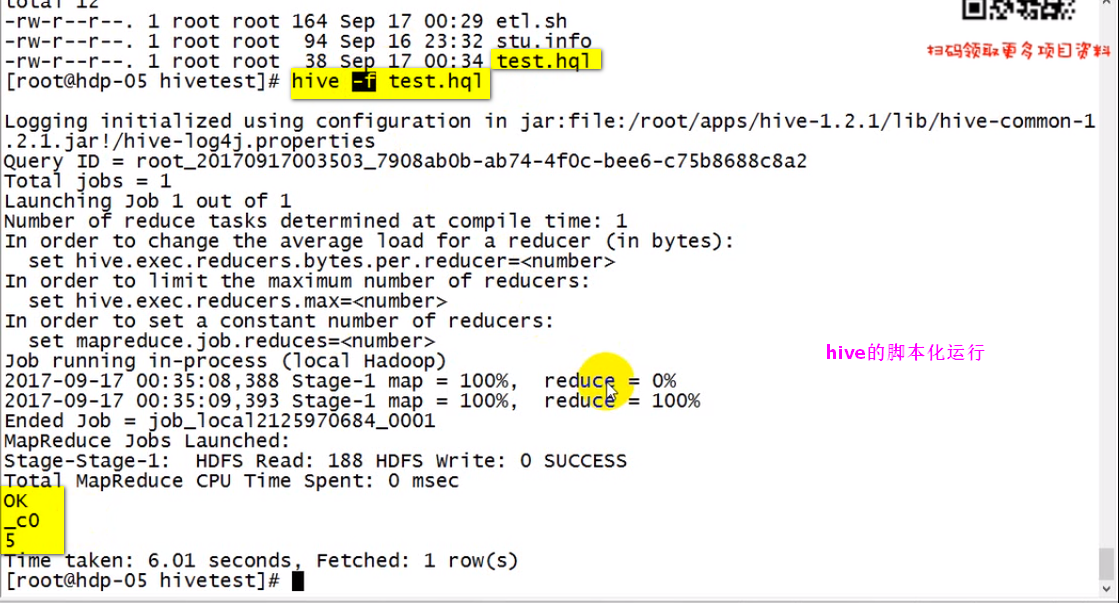
hive的脚本化运行
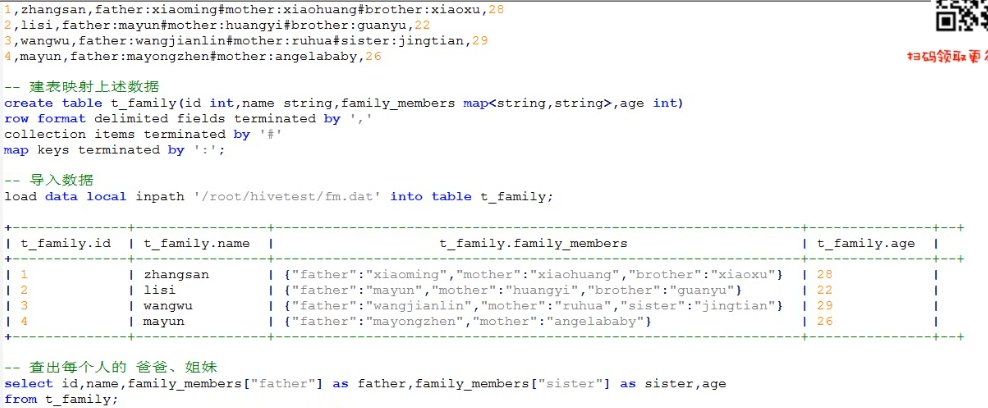
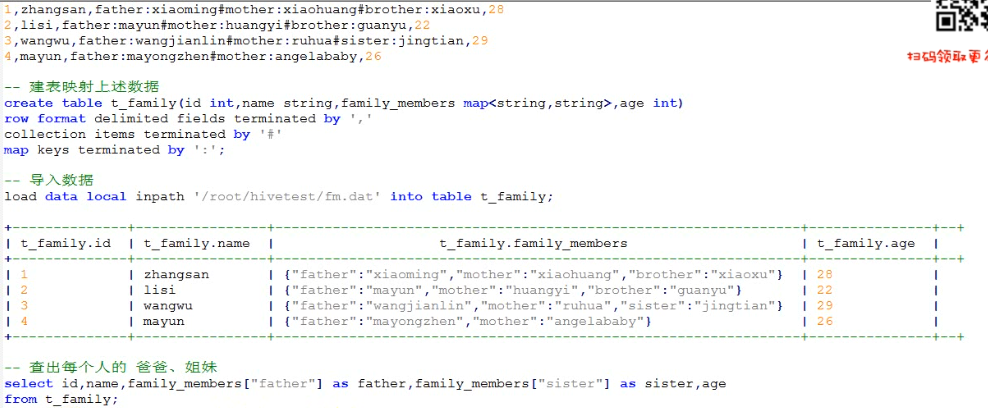
hive的map类型案例
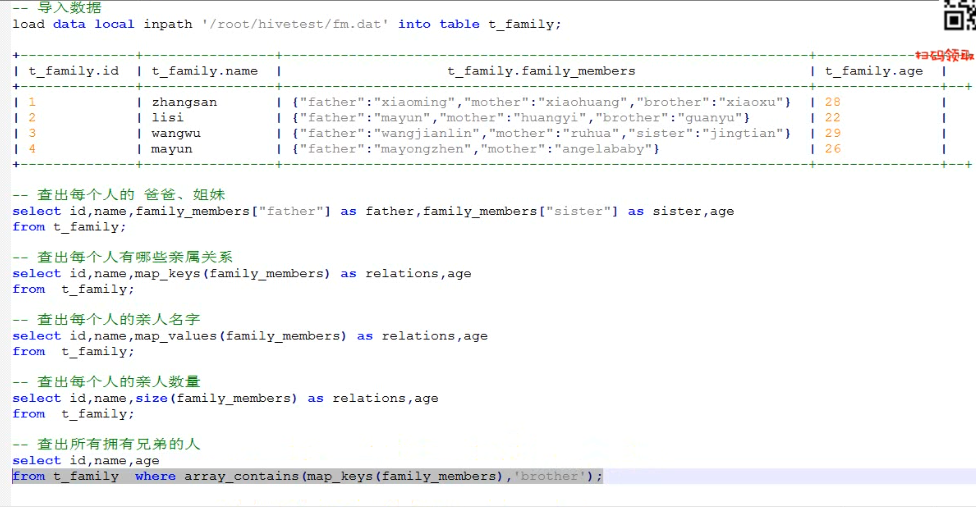

Struct结构体 类型.属性名 类似c语言的结构体
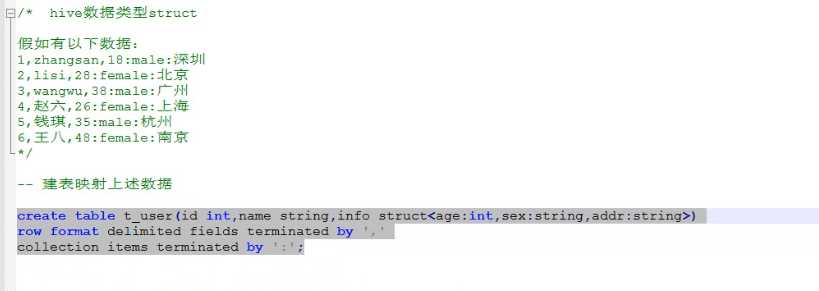

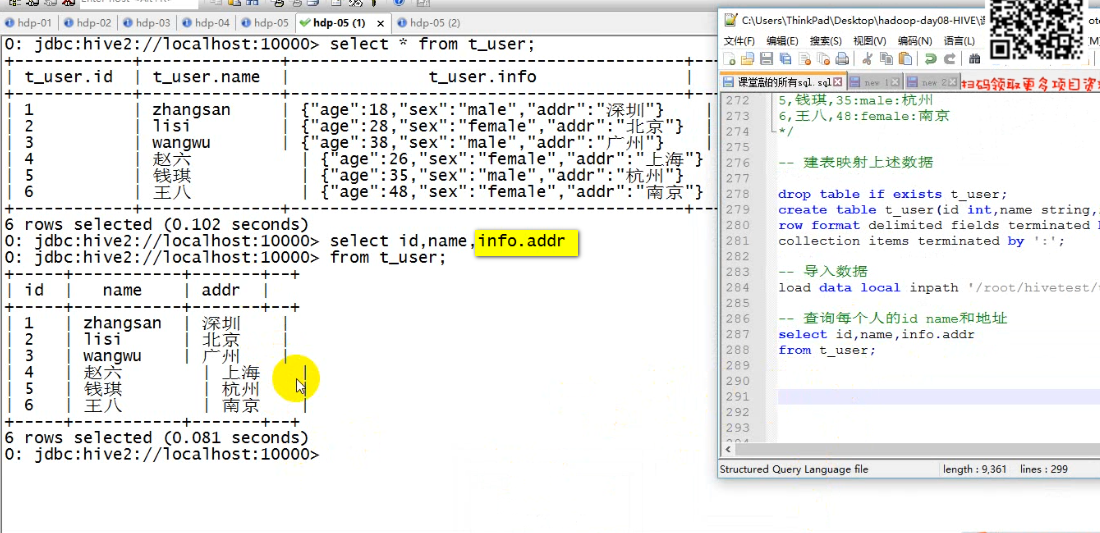
6/ HIVE的内置函数
时间处理函数:
from_unixtime(21938792183,'yyyy-MM-dd HH:mm:ss') --> '2017-06-03 17:50:30'
类型转换函数:
from_unixtime(cast('21938792183' as bigint),'yyyy-MM-dd HH:mm:ss')
字符串截取和拼接
substr("abcd",1,3) --> 'abc'
concat('abc','def') --> 'abcdef'
Json数据解析函数
get_json_object('{\"key1\":3333,\"key2\":4444}' , '$.key1') --> 3333
json_tuple('{\"key1\":3333,\"key2\":4444}','key1','key2') as(key1,key2) --> 3333, 4444
url解析函数
parse_url_tuple('http://www.edu360.cn/bigdata/baoming?userid=8888','HOST','PATH','QUERY','QUERY:userid')
---> www.edu360.cn /bigdata/baoming userid=8888 8888
******* 函数:explode 和 lateral view
可以将一个数组变成列
加入有一个表,其中的字段为array类型
表数据:
1,zhangsan,数学:语文:英语:生物
2,lisi,数学:语文
3,wangwu,化学:计算机:java编程
建表:
create table t_xuanxiu(uid string,name string,kc array<string>)
row format delimited
fields terminated by ','
collection items terminated by ':';
** explode效果示例:
select explode(kc) from t_xuanxiu where uid=1;
数学
语文
英语
生物
** lateral view 表生成函数
hive> select uid,name,tmp.* from t_xuanxiu
> lateral view explode(kc) tmp as course;
OK
1 zhangsan 数学
1 zhangsan 语文
1 zhangsan 英语
1 zhangsan 生物
2 lisi 数学
2 lisi 语文
3 wangwu 化学
3 wangwu 计算机
3 wangwu java编程
==== 利用explode和lateral view 实现hive版的wordcount
有以下数据:
a b c d e f g
a b c
e f g a
b c d b
对数据建表:
create table t_juzi(line string) row format delimited;
导入数据:
load data local inpath '/root/words.txt' into table t_juzi;
** ***** ******** ***** ******** ***** ******** wordcount查询语句:***** ******** ***** ******** ***** ********
select a.word,count(1) cnt
from
(select tmp.* from t_juzi lateral view explode(split(line,' ')) tmp as word) a
group by a.word
order by cnt desc;
***************** ******** ***** ******** row_number() over() 函数***** ******** ***** ******** ***** ******** ***** ******** ***** *******
常用于求分组TOPN
有如下数据:
zhangsan,kc1,90
zhangsan,kc2,95
zhangsan,kc3,68
lisi,kc1,88
lisi,kc2,95
lisi,kc3,98
建表:
create table t_rowtest(name string,kcId string,score int)
row format delimited
fields terminated by ',';
导入数据:
利用row_number() over() 函数看下效果:
select *,row_number() over(partition by name order by score desc) as rank from t_rowtest;
+-----------------+-----------------+------------------+----------------------+--+
| t_rowtest.name | t_rowtest.kcid | t_rowtest.score | rank |
+-----------------+-----------------+------------------+----------------------+--+
| lisi | kc3 | 98 | 1 |
| lisi | kc2 | 95 | 2 |
| lisi | kc1 | 88 | 3 |
| zhangsan | kc2 | 95 | 1 |
| zhangsan | kc1 | 90 | 2 |
| zhangsan | kc3 | 68 | 3 |
+-----------------+-----------------+------------------+----------------------+--+
从而,求分组topn就变得很简单了:
select name,kcid,score
from
(select *,row_number() over(partition by name order by score desc) as rank from t_rowtest) tmp
where rank<3;
+-----------+-------+--------+--+
| name | kcid | score |
+-----------+-------+--------+--+
| lisi | kc3 | 98 |
| lisi | kc2 | 95 |
| zhangsan | kc2 | 95 |
| zhangsan | kc1 | 90 |
+-----------+-------+--------+--+
create table t_rate_topn_uid
as
select uid,movie,rate,ts
from
(select *,row_number() over(partition by uid order by rate desc) as rank from t_rate) tmp
where rank<11;
7/ 自定义函数 ***** ******** ***** ******** ***** ******** ***** ********
有如下数据:
1,zhangsan:18-1999063117:30:00-beijing
2,lisi:28-1989063117:30:00-shanghai
3,wangwu:20-1997063117:30:00-tieling
建表:
create table t_user_info(info string)
row format delimited;
导入数据:
load data local inpath '/root/udftest.data' into table t_user_info;
需求:利用上表生成如下新表t_user:
uid,uname,age,birthday,address
思路:可以自定义一个函数parse_user_info(),能传入一行上述数据,返回切分好的字段
然后可以通过如下sql完成需求:
create t_user
as
select
parse_user_info(info,0) as uid,
parse_user_info(info,1) as uname,
parse_user_info(info,2) as age,
parse_user_info(info,3) as birthday_date,
parse_user_info(info,4) as birthday_time,
parse_user_info(info,5) as address
from t_user_info;
实现关键: 自定义parse_user_info() 函数
实现步骤:
1、写一个java类实现函数所需要的功能
public class UserInfoParser extends UDF{
// 1,zhangsan:18-1999063117:30:00-beijing
public String evaluate(String line,int index) {
String newLine = line.replaceAll(",", "\001").replaceAll(":", "\001").replaceAll("-", "\001");
StringBuilder sb = new StringBuilder();
String[] split = newLine.split("\001");
StringBuilder append = sb.append(split[0])
.append("\t")
.append(split[1])
.append("\t")
.append(split[2])
.append("\t")
.append(split[3].substring(0, 8))
.append("\t")
.append(split[3].substring(8, 10)).append(split[4]).append(split[5])
.append("\t")
.append(split[6]);
String res = append.toString();
return res.split("\t")[index];
}
}
2、将java类打成jar包: d:/up.jar
3、上传jar包到hive所在的机器上 /root/up.jar
4、在hive的提示符中添加jar包
hive> add jar /root/up.jar;
5、创建一个hive的自定义函数名 跟 写好的jar包中的java类对应
hive> create temporary function parse_user_info as 'com.doit.hive.udf.UserInfoParser';

