
SQL 中 left join 的底层原理
转载自:https://www.cnblogs.com/jmcui/archive/2020/12/10/14117113.html#_label1
好好学习数据结构吧,毕业也几年了,很多东西都稀里糊涂,不能再这样下去了。
突然想起来了高中物理老师的一句话,做了十道题,不如弄懂一道题。
01. 前言
写过或者学过 SQL 的人应该都知道 left join,知道 left join 的实现的效果,就是保留左表的全部信息,然后把右表往左表上拼接,如果拼不上就是 null。除了 left join 以外,还有 inner join、outer join、right join,这些不同的 join 能达到的什么样的效果,大家应该都了解了,如果不了解的可以看看网上的帖子或者随便一本 SQL 书都有讲的。今天我们不讲这些 join 能达到什么效果,我们主要讲这些 join 的底层原理是怎么实现的,也就是具体的效果是怎么呈现出来的。
join 主要有 Nested Loop、Hash Join、Merge Join 这三种方式,我们这里只讲最普遍的,也是最好的理解的 Nested Loop,Nested Loop 翻译过来就是嵌套循环的意思,那什么又是嵌套循环呢?嵌套大家应该都能理解,就是一层套一层;那循环呢,你可以理解成是 for 循环。
Nested Loop 里面又有三种细分的连接方式,分别是 Simple Nested-Loop Join、Index Nested-Loop Join、Block Nested-Loop Join,接下来我们就分别去看一下这三种细分的连接方式。
在正式开始之前,先介绍两个概念:驱动表(也叫外表)和被驱动表(也叫非驱动表,还可以叫匹配表,亦可叫内表),简单来说,驱动表就是主表,left join 中的左表就是驱动表,right join 中的右表是驱动表。一个是驱动表,那另一个就只能是非驱动表了,在 join 的过程中,其实就是从驱动表里面依次(注意理解这里面的依次)取出每一个值,然后去非驱动表里面进行匹配,那具体是怎么匹配的呢?这就是我们接下来讲的这三种连接方式。
02.Simple Nested-Loop Join
Simple Nested-Loop Join 是这三种方法里面最简单,最好理解,也是最符合大家认知的一种连接方式,现在有两张表 table A 和 table B,我们让 table A left join table B,如果是用第一种连接方式去实现的话,会是怎么去匹配的呢?直接上图:
上面的 left join 会从驱动表 table A 中依次取出每一个值,然后去非驱动表 table B 中从上往下依次匹配,然后把匹配到的值进行返回,最后把所有返回值进行合并,这样我们就查找到了 table A left join table B 的结果。是不是和你的认知是一样的呢?利用这种方法,如果 table A 有10行,table B 有10行,总共需要执行 10 x 10 = 100 次查询。
这种暴力匹配的方式在数据库中一般不使用。
03.Index Nested-Loop Join
Index Nested-Loop Join 这种方法中,我们看到了 Index,大家应该都知道这个就是索引的意思,这个 Index 是要求非驱动表上要有索引,有了索引以后可以减少匹配次数,匹配次数减少了就可以提高查询的效率了。
为什么会有了索引以后可以减少查询的次数呢?这个其实就涉及到数据结构里面的一些知识了,给大家举个例子就清楚了。
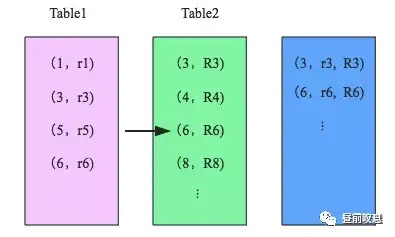
上图中左边就是普通列的存储方式,右边是树结构索引,什么是树结构呢?就是数据分布的像树这样一层一层的,树结构有一个特点就是左边的数据小于顶点的数,右边的数大于顶点的数,你看右图中,左边的数3是不是小于顶点6,右边的数7是不是大于顶点6;左边的数1是不是小于顶点3,右边的数4是不是大于顶点3。
假如我们现在要匹配数值9,如果是左边这种数据存储方式的话,我们需要从第一行依次匹配到最后一行才能找到数值9,总共需要匹配7次;但是如果我们是用右边这种树结构索引的话,我们先拿9和最上层顶点6去匹配,发现9比6大,我们就去顶点的右边去找,再去和7匹配,发现9仍然比7大,再去7的右边找,就找到了9,这样我们只匹配了3次就把我们想要的9找到了。是不是相比匹配7次节省了很多时间。
数据库中的索引一般用 B+ 树,为了让大家更好的理解,我上面画的图只是最简单的一种树结构,而非真实的 B+ 树,但是原理是一样的。
如果索引是主键的话,效率会更高,因为主键必须是唯一的,所以如果被驱动表是用主键去连接,只会出现多对一或者一对一的情况,而不会出现多对多和一对多的情况。
04.Block Nested-Loop Join
理想情况下,用索引匹配是最高效的一种方式,但是在现实工作中,并不是所有的列都是索引列,这个时候就需要用到 Block Nested-Loop Join 方法了,这种方法与第一种方法比较类似,唯一的区别就是会把驱动表中 left join 涉及到的所有列(不止是用来on的列,还有select部分的列)先取出来放到一个缓存区域,然后再去和非驱动表进行匹配,这种方法和第一种方法相比所需要的匹配次数是一样的,差别就在于驱动表的列数不同,也就是数据量的多少不同。所以虽然匹配次数没有减少,但是总体的查询性能还是有提升的。
spark的三种jion
转载自:https://zhuanlan.zhihu.com/p/91510137
引言Join是SQL语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余、更新容错等。而建立表和表之间关系的最佳方式就是Join操作。
对于Spark来说有3中Join的实现,每种Join对应着不同的应用场景:
Broadcast Hash Join :适合一张较小的表和一张大表进行join
Shuffle Hash Join : 适合一张小表和一张大表进行join,或者是两张小表之间的join
Sort Merge Join :适合两张较大的表之间进行join
前两者都基于的是Hash Join,只不过在hash join之前需要先shuffle还是先broadcast。下面将详细的解释一下这三种不同的join的具体原理。
Hash Join先来看看这样一条SQL语句:
select * from order,item where item.id = order.i_id
- 确定Build Table以及Probe Table:这个概念比较重要,Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起。通常情况下,小表会作为Build Table,大表作为Probe Table。此事例中item为Build Table,order为Probe Table;很简单一个Join节点,参与join的两张表是item和order,join key分别是item.id以及order.i_id。现在假设这个Join采用的是hash join算法,整个过程会经历三步:
- 构建Hash Table:依次读取Build Table(item)的数据,对于每一行数据根据join key(item.id)进行hash,hash到对应的Bucket,生成hash table中的一条记录。数据缓存在内存中,如果内存放不下需要dump到外存;
- 探测:再依次扫描Probe Table(order)的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件(item.id = order.i_id),如果匹配成功就可以将两者join在一起。

基本流程可以参考上图,这里有两个小问题需要关注:
- hash join性能如何?很显然,hash join基本都只扫描两表一次,可以认为o(a+b),较之最极端的笛卡尔集运算a*b,不知甩了多少条街;
- 为什么Build Table选择小表?道理很简单,因为构建的Hash Table最好能全部加载在内存,效率最高;这也决定了hash join算法只适合至少一个小表的join场景,对于两个大表的join场景并不适用。
上文说过,hash join是传统数据库中的单机join算法,在分布式环境下需要经过一定的分布式改造,说到底就是尽可能利用分布式计算资源进行并行化计算,提高总体效率。hash join分布式改造一般有两种经典方案:
- broadcast hash join:将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行hash join。broadcast适用于小表很小,可以直接广播的场景;
- shuffler hash join:一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据join key相同必然分区相同的原理,将两张表分别按照join key进行重新组织分区,这样就可以将join分而治之,划分为很多小join,充分利用集群资源并行化。
Broadcast Hash Join大家知道,在数据库的常见模型中(比如星型模型或者雪花模型),表一般分为两种:事实表和维度表。维度表一般指固定的、变动较少的表,例如联系人、物品种类等,一般数据有限。而事实表一般记录流水,比如销售清单等,通常随着时间的增长不断膨胀。
因为Join操作是对两个表中key值相同的记录进行连接,在SparkSQL中,对两个表做Join最直接的方式是先根据key分区,再在每个分区中把key值相同的记录拿出来做连接操作。但这样就不可避免地涉及到shuffle,而shuffle在Spark中是比较耗时的操作,我们应该尽可能的设计Spark应用使其避免大量的shuffle。
当维度表和事实表进行Join操作时,为了避免shuffle,我们可以将大小有限的维度表的全部数据分发到每个节点上,供事实表使用。executor存储维度表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时,这在SparkSQL中称作Broadcast Join,如下图所示:

Table B是较小的表,黑色表示将其广播到每个executor节点上,Table A的每个partition会通过block manager取到Table A的数据。根据每条记录的Join Key取到Table B中相对应的记录,根据Join Type进行操作。这个过程比较简单,不做赘述。
Broadcast Join的条件有以下几个:
- 被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M (或者加了broadcast join的hint)
- 基表不能被广播,比如left outer join时,只能广播右表
看起来广播是一个比较理想的方案,但它有没有缺点呢?也很明显。这个方案只能用于广播较小的表,否则数据的冗余传输就远大于shuffle的开销;另外,广播时需要将被广播的表现collect到driver端,当频繁有广播出现时,对driver的内存也是一个考验。
如下图所示,broadcast hash join可以分为两步:
- broadcast阶段:将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给driver,driver再统一分发给所有executor;要不就是基于bittorrete的p2p思路;
- hash join阶段:在每个executor上执行单机版hash join,小表映射,大表试探;

SparkSQL规定broadcast hash join执行的基本条件为被广播小表必须小于参数spark.sql.autoBroadcastJoinThreshold,默认为10M。
Shuffle Hash Join当一侧的表比较小时,我们选择将其广播出去以避免shuffle,提高性能。但因为被广播的表首先被collect到driver段,然后被冗余分发到每个executor上,所以当表比较大时,采用broadcast join会对driver端和executor端造成较大的压力。
但由于Spark是一个分布式的计算引擎,可以通过分区的形式将大批量的数据划分成n份较小的数据集进行并行计算。这种思想应用到Join上便是Shuffle Hash Join了。利用key相同必然分区相同的这个原理,两个表中,key相同的行都会被shuffle到同一个分区中,SparkSQL将较大表的join分而治之,先将表划分成n个分区,再对两个表中相对应分区的数据分别进行Hash Join,这样即在一定程度上减少了driver广播一侧表的压力,也减少了executor端取整张被广播表的内存消耗。其原理如下图:
Shuffle Hash Join分为两步:
- 对两张表分别按照join keys进行重分区,即shuffle,目的是为了让有相同join keys值的记录分到对应的分区中
- 对对应分区中的数据进行join,此处先将小表分区构造为一张hash表,然后根据大表分区中记录的join keys值拿出来进行匹配
Shuffle Hash Join的条件有以下几个:
- 分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M
- 基表不能被广播,比如left outer join时,只能广播右表
- 一侧的表要明显小于另外一侧,小的一侧将被广播(明显小于的定义为3倍小,此处为经验值)
我们可以看到,在一定大小的表中,SparkSQL从时空结合的角度来看,将两个表进行重新分区,并且对小表中的分区进行hash化,从而完成join。在保持一定复杂度的基础上,尽量减少driver和executor的内存压力,提升了计算时的稳定性。
在大数据条件下如果一张表很小,执行join操作最优的选择无疑是broadcast hash join,效率最高。但是一旦小表数据量增大,广播所需内存、带宽等资源必然就会太大,broadcast hash join就不再是最优方案。此时可以按照join key进行分区,根据key相同必然分区相同的原理,就可以将大表join分而治之,划分为很多小表的join,充分利用集群资源并行化。如下图所示,shuffle hash join也可以分为两步:
- shuffle阶段:分别将两个表按照join key进行分区,将相同join key的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为shuffle
- hash join阶段:每个分区节点上的数据单独执行单机hash join算法。

看到这里,可以初步总结出来如果两张小表join可以直接使用单机版hash join;如果一张大表join一张极小表,可以选择broadcast hash join算法;而如果是一张大表join一张小表,则可以选择shuffle hash join算法;那如果是两张大表进行join呢?
Sort Merge Join上面介绍的两种实现对于一定大小的表比较适用,但当两个表都非常大时,显然无论适用哪种都会对计算内存造成很大压力。这是因为join时两者采取的都是hash join,是将一侧的数据完全加载到内存中,使用hash code取join keys值相等的记录进行连接。
当两个表都非常大时,SparkSQL采用了一种全新的方案来对表进行Join,即Sort Merge Join。这种实现方式不用将一侧数据全部加载后再进星hash join,但需要在join前将数据排序,如下图所示:

可以看到,首先将两张表按照join keys进行了重新shuffle,保证join keys值相同的记录会被分在相应的分区。分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接,如下图示:

看着很眼熟吧?也很简单,因为两个序列都是有序的,从头遍历,碰到key相同的就输出;如果不同,左边小就继续取左边,反之取右边。
可以看出,无论分区有多大,Sort Merge Join都不用把某一侧的数据全部加载到内存中,而是即用即取即丢,从而大大提升了大数据量下sql join的稳定性。
SparkSQL对两张大表join采用了全新的算法-sort-merge join,如下图所示,整个过程分为三个步骤:

- shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理;
- sort阶段:对单个分区节点的两表数据,分别进行排序;
- merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边,见下图示意:
经过上文的分析,可以明确每种Join算法都有自己的适用场景,数据仓库设计时最好避免大表与大表的join查询,SparkSQL也可以根据内存资源、带宽资源适量将参数spark.sql.autoBroadcastJoinThreshold调大,让更多join实际执行为broadcast hash join。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号