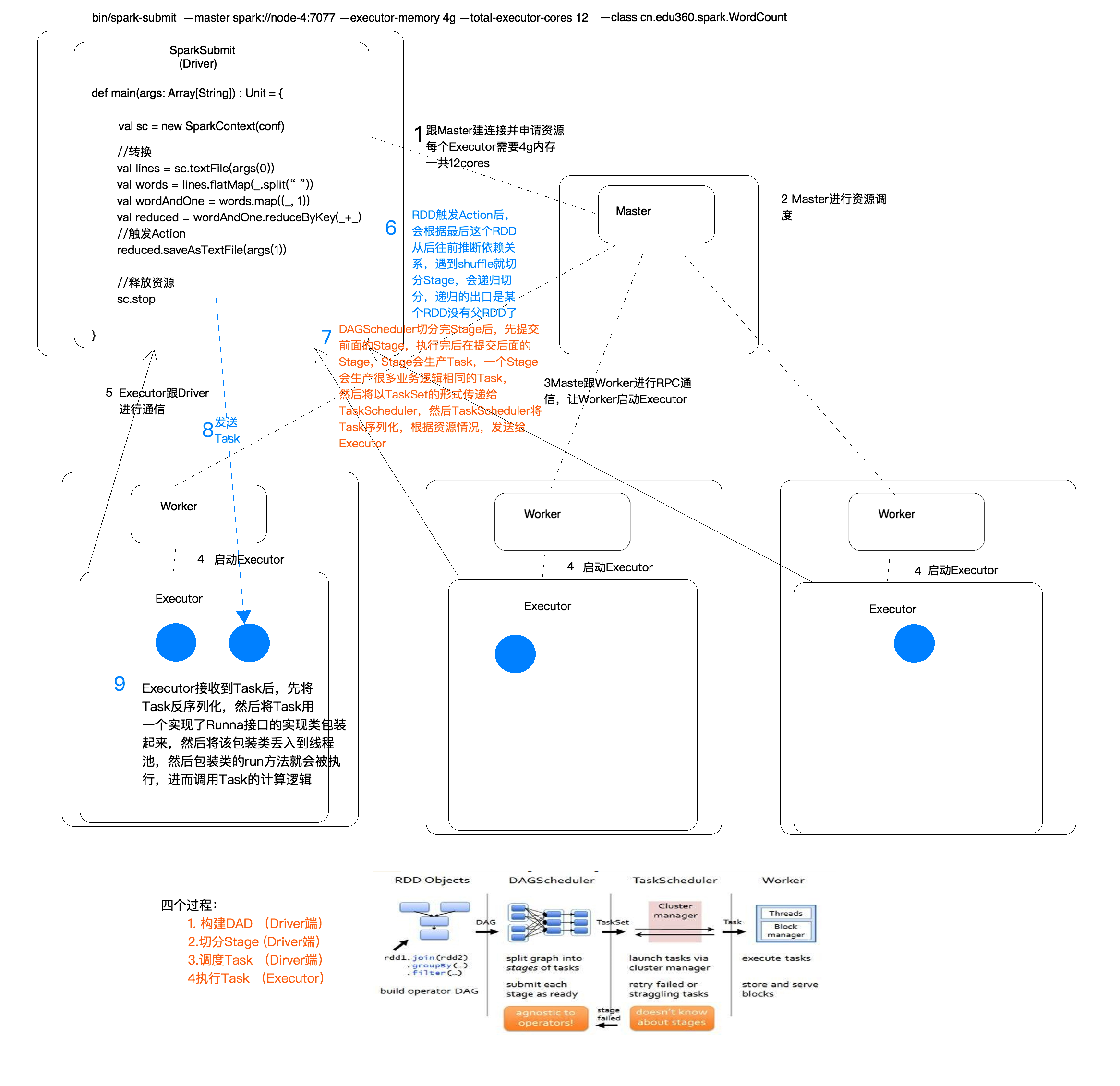
Spark 任务执行的流程
Spark 任务执行的流程
四个步骤
1.构建DAG(调用RDD上的方法)
2.DAGScheduler将DAG切分Stage(切分的依据是Shuffle),将Stage中生成的Task以TaskSet的形式给TaskScheduler
3.TaskScheduler调度Task(根据资源情况将Task调度到相应的Executor中)
4.Executor接收Task,然后将Task丢入到线程池中执行
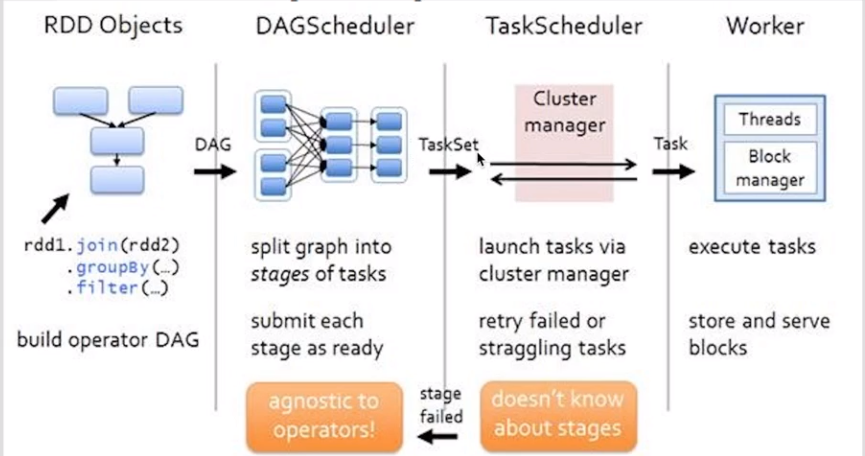
DAG 有向无环图(数据执行过程,有方法,无闭环)
DAG描述多个RDD的转换过程,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程)
DAG是有边界的:开始(通过SparkContext创建的RDD),结束(触发Action,调用run Job就是一个完整的DAG就形成了,一旦触发Action就形成了一个完整的DAG)
一个RDD只是描述了数据计算过程中的一个环节,而DGA由一到多个RDD组成,描述了数据计算过程中的所有环节(过程)
一个Spark Application中是有多少个DAG:一到多个(取决于触发了多少次Action)
--------------------------------------------
一个DAG中可能有产生多种不同类型和功能的Task,会有不同的阶段
DAGScheduler:将一个DAG切分成一到多个Stage,DAGScheduler切分的依据是Shuffle(宽依赖)
为什么要切分Stage?
一个复杂的业务逻辑(将多台机器上具有相同属性的数据聚合到一台机器上:shuffle)
如果有shuffle,那么就意味着前面阶段产生的结果后,才能执行下一个阶段,下一个阶段的计算要依赖上一个阶段的数据。
在同一个Stage中,会有多个算子,可以合并在一起,我们称其为pipeline(流水线:严格按照流程、顺序执行)
--------------------------------------------
宽依赖和窄依赖 一般来说普通的join都是宽依赖
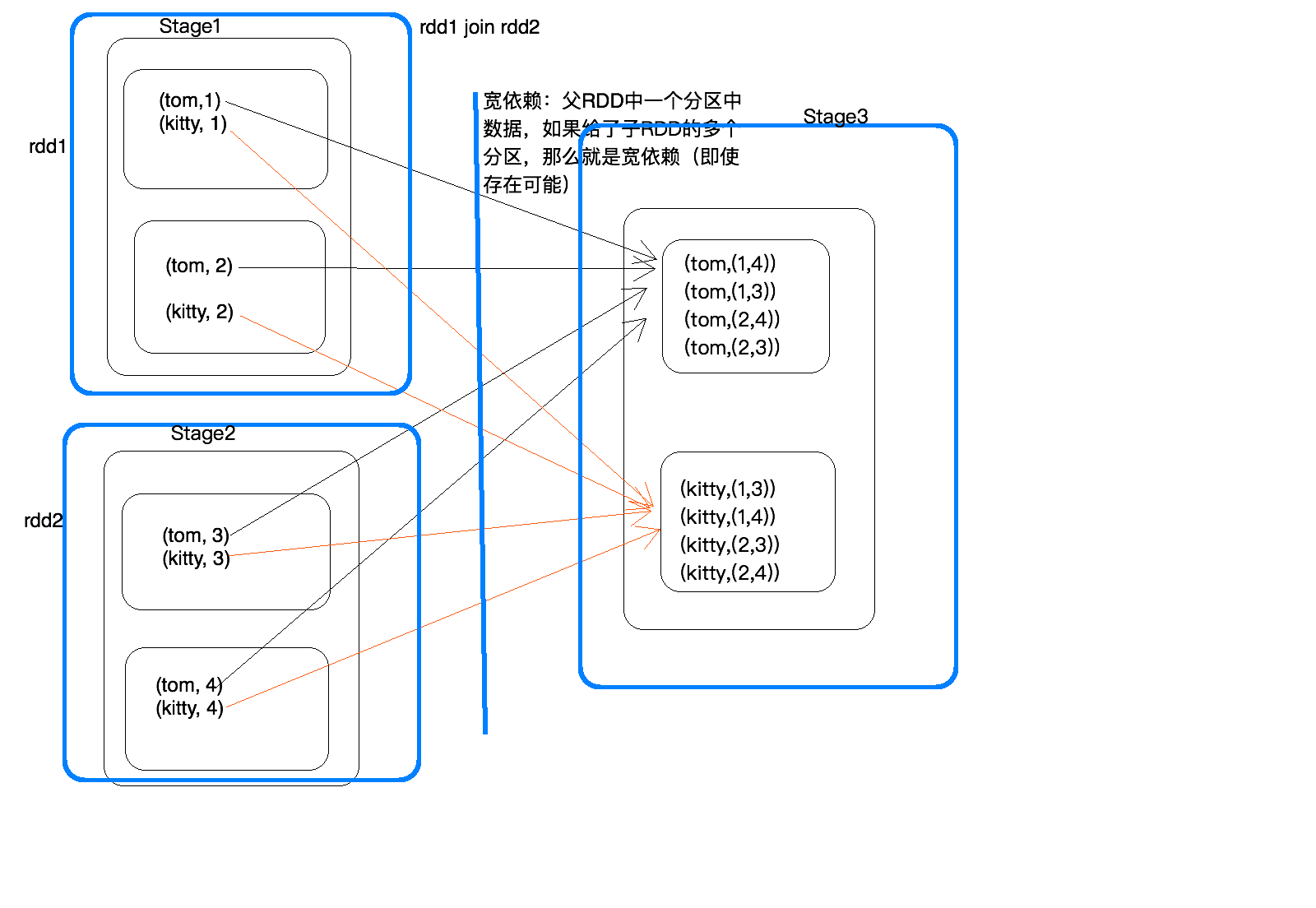
rdd的特殊jion 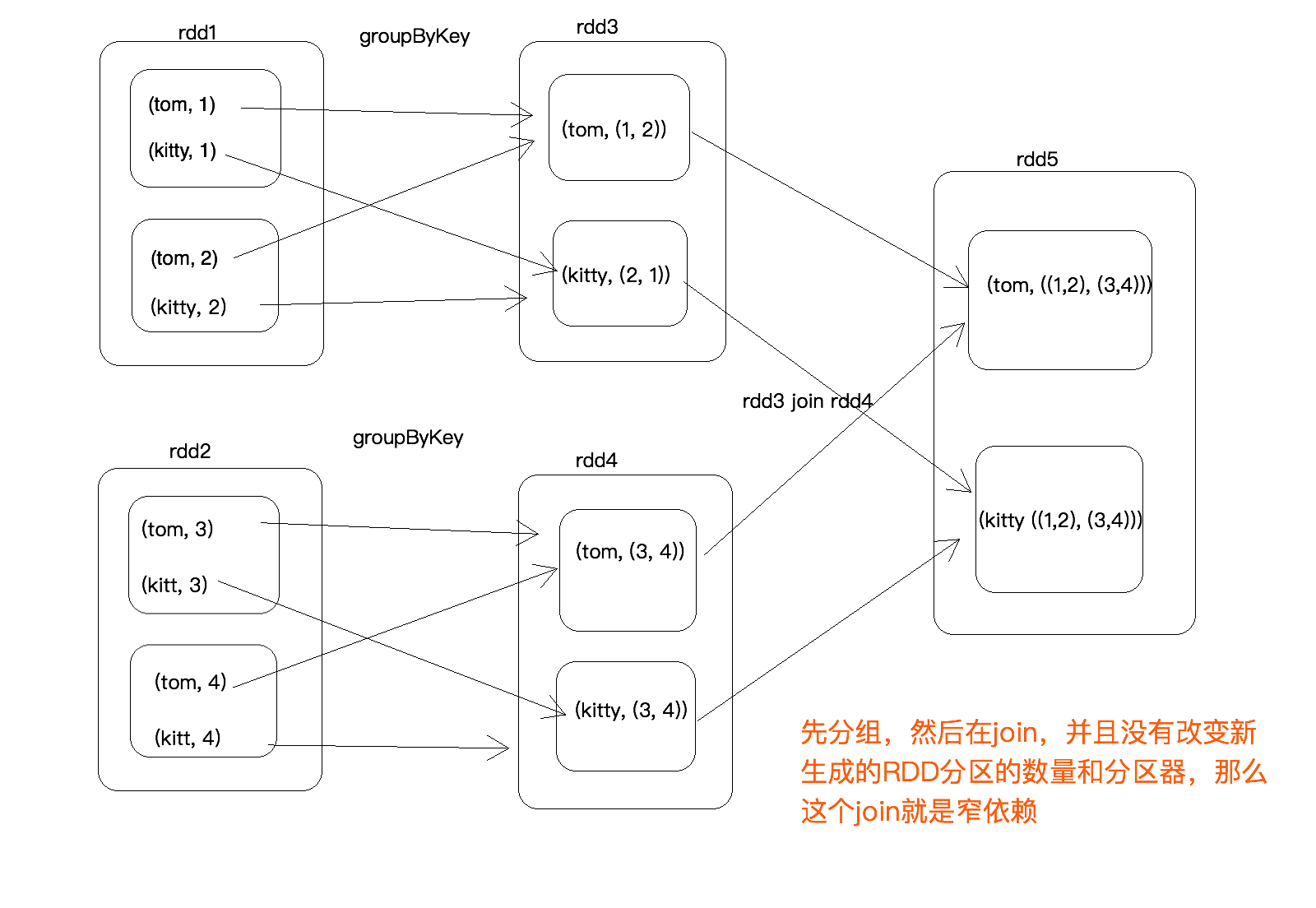
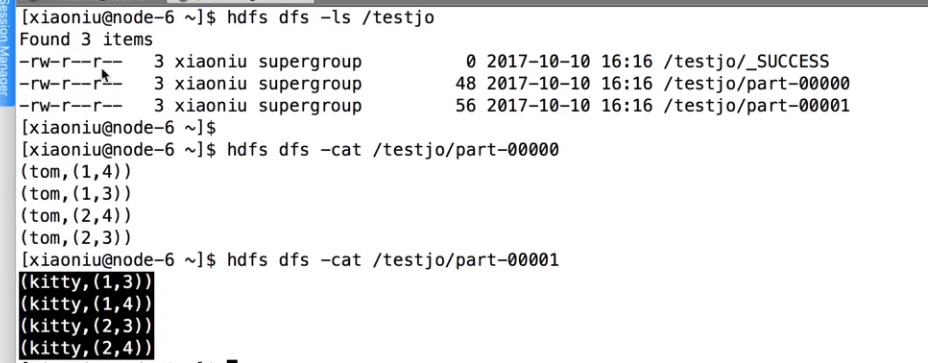
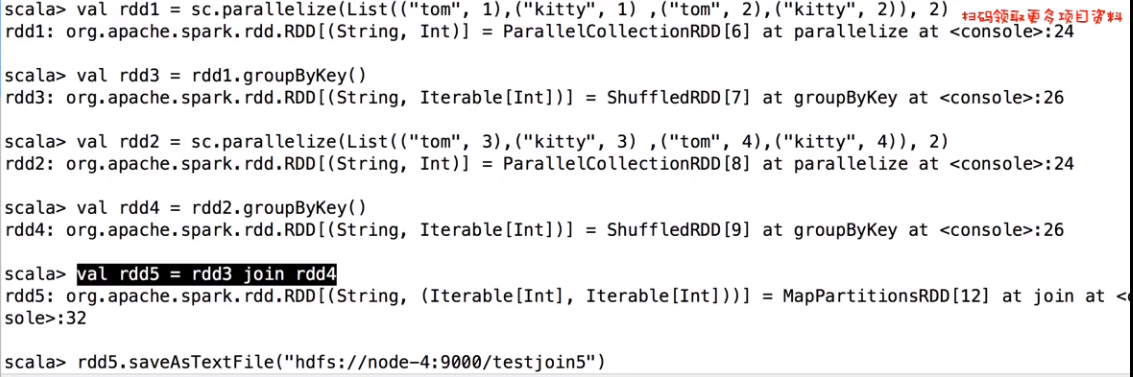
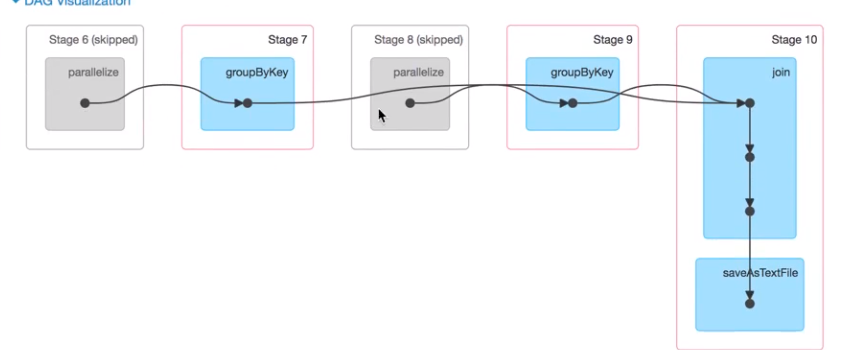
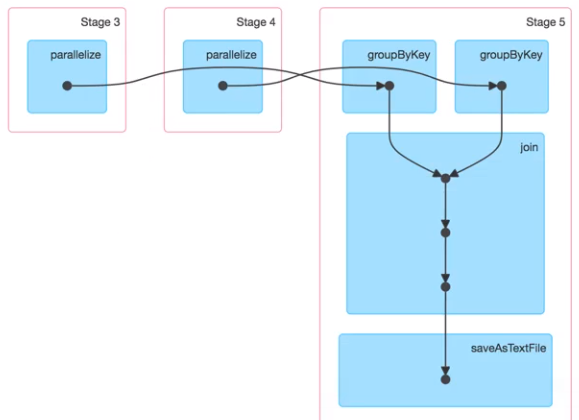
stage过程,3个stage 6 个Task 一个stage有两个分区就有两个Task,一个Application有很多job,job划分依据run job行动算子,调用了几次就有几个job ,stage划分是依据suffle来的,相同的过程划分到同一个stage,产生shuffle的阶段一份为二。
Jion底层源码 
Rdd的依赖关系 ,记录当前rdd的父亲rdd从哪来,本来一个rdd有两个分区,map循环遍历,比较每个分区的partitioner如果类型一致又相同,其实分区个数一样就默认认为窄依赖,如果不等就是宽依赖,Some(part)是自己传入的分区个数。

HashPartitioner源码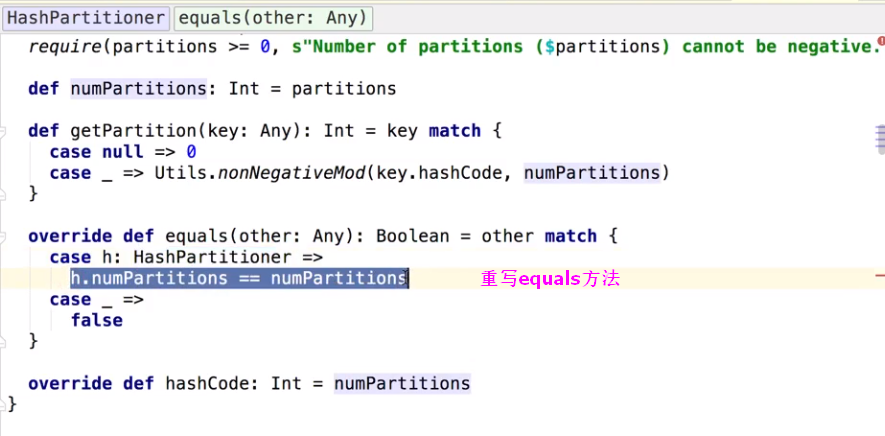
根据源码发现,如果改变了分区数,就会产生suffle了 如
任务将划分5个Stage