大数据技术Spark之RDD基础编程
一、RDD编程相关的就是Spark Core内容,spark的数据抽象就是RDD
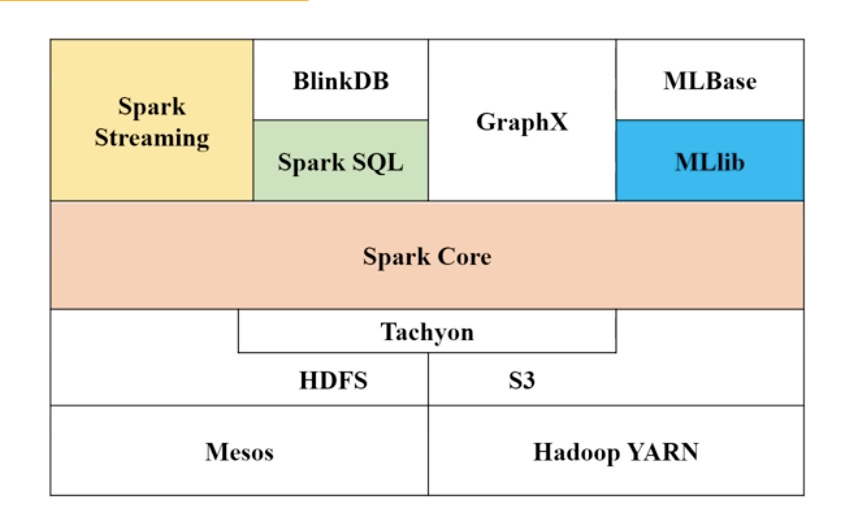
二、创建RDD(两种方法)
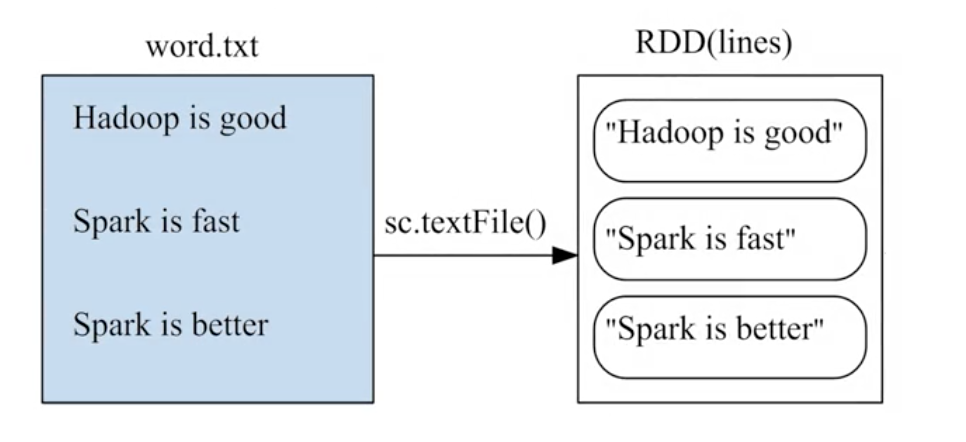
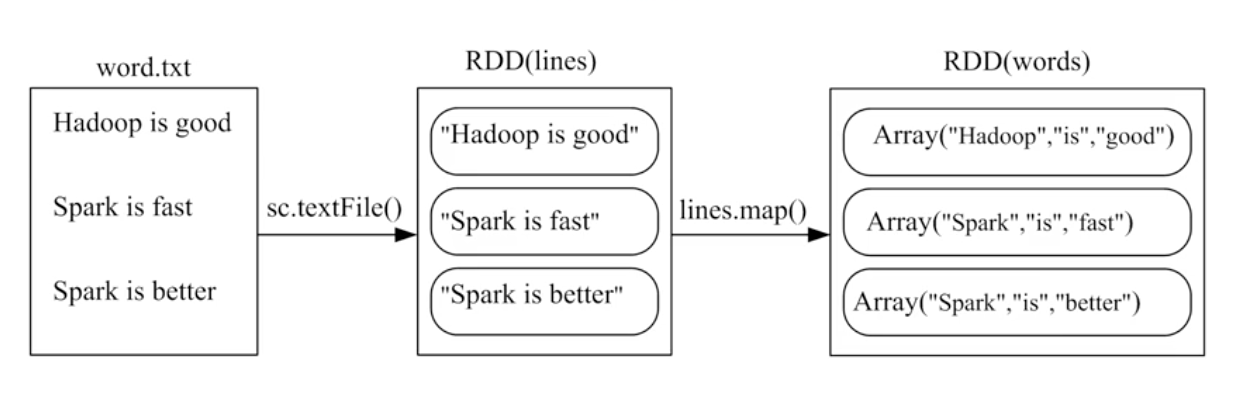
1、从文件系统中加载数据
SparkContext通过textfile()读取数据生成,数据源可以是本地,hdfs,云端
a、从本地数据集

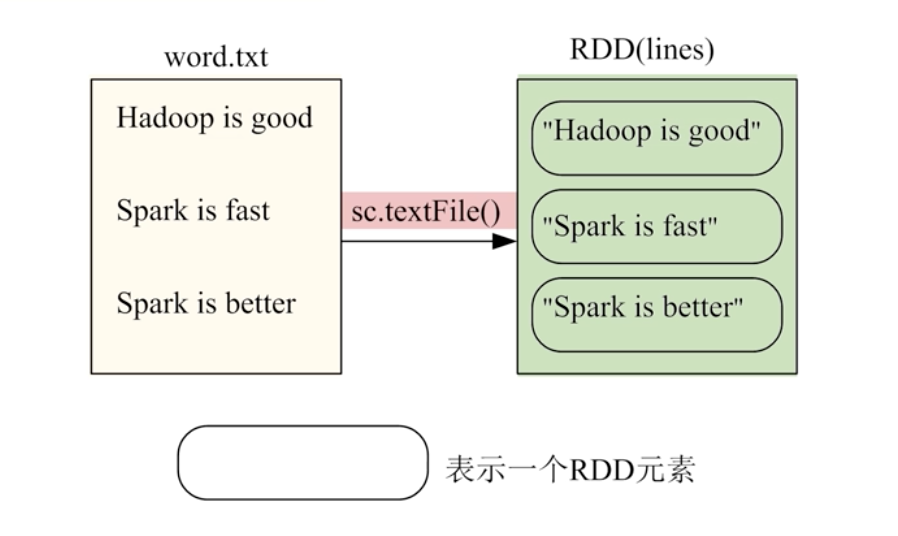
b、从hdfs生成

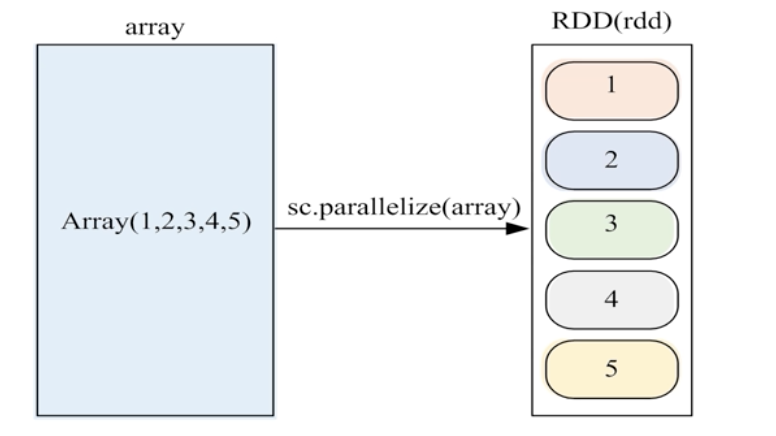
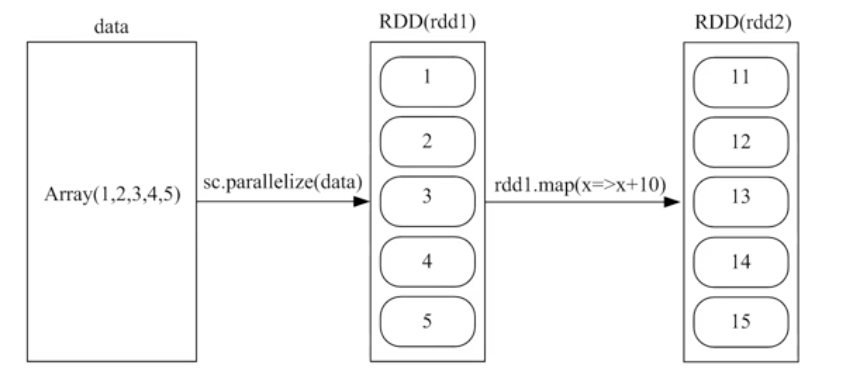
2、通过并行集合(数组)
调用SparkContext对象的Parallelize方法


三、RDD操作包括两种:转换操作,行动操作
转换操作不会对RDD进行计算,只是记录下来,等到行动操作才会进行计算。
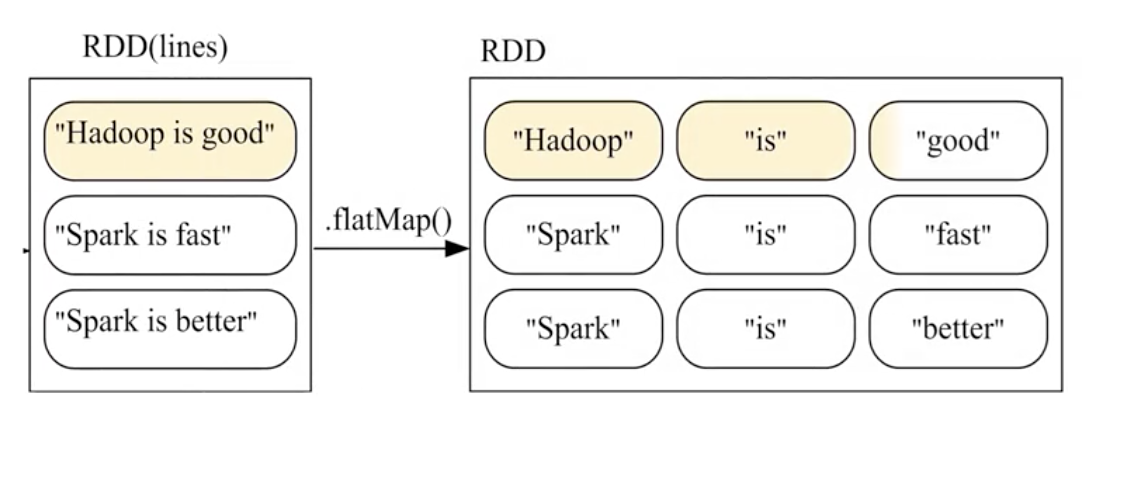
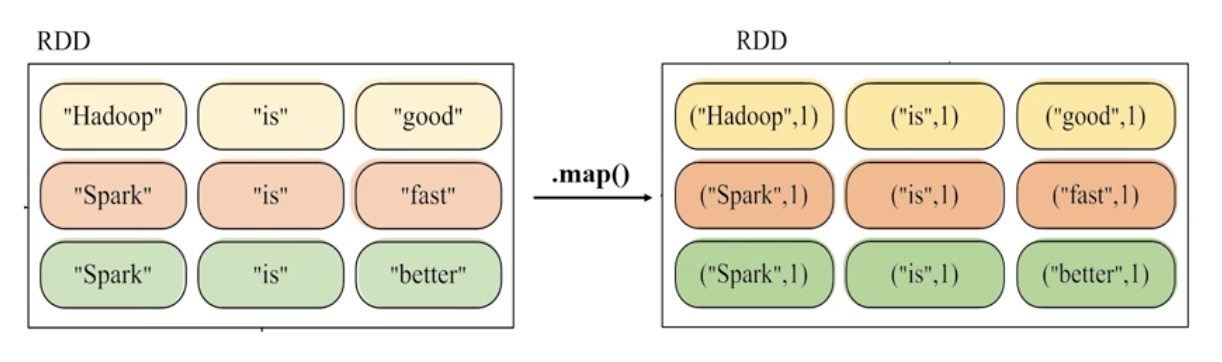
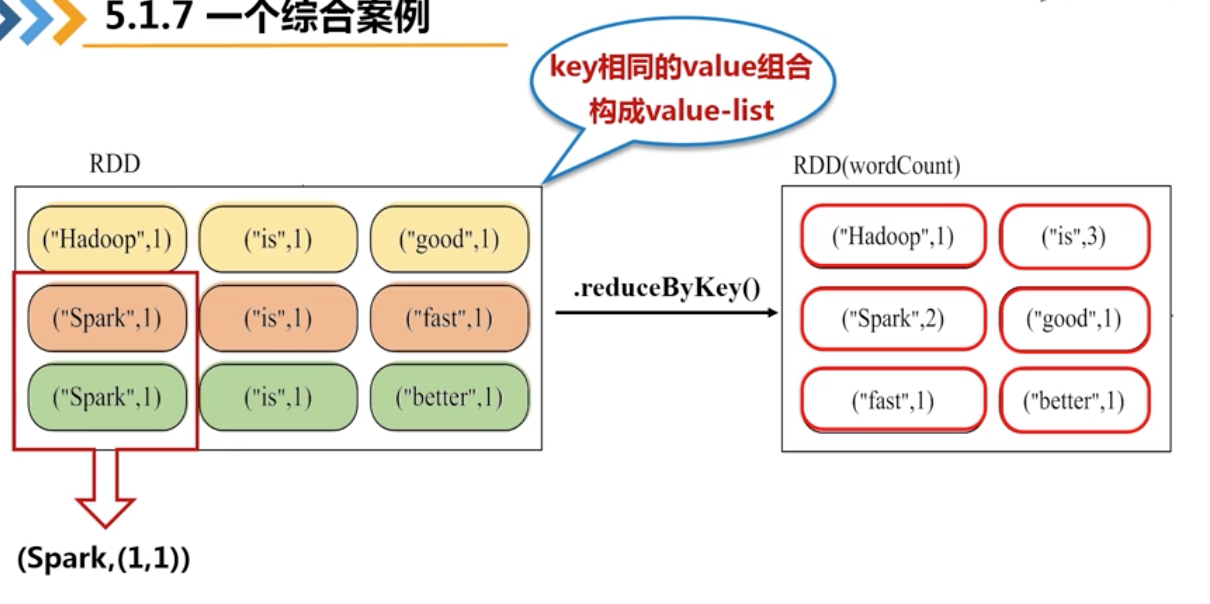
常用的转换操作包括:filter,map,flatmap,groupByKey,reduceByKey

1、filter


2、map


3、flatmap


4、groupkey

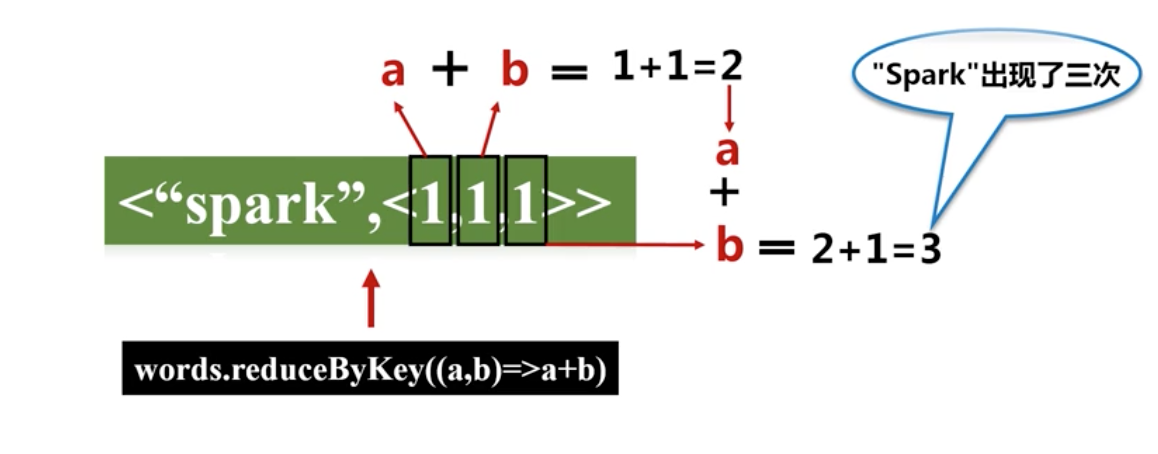
5、reduceByKey

行动操作
只有遇到动作才会去加载


四、持久化
允许用户手动操作把一些反复使用的数据集保存在内存之中,避免一直取

改进:

在调用cache()/persist()的时候不会把rdd放到缓存之中,当涉及到动作操作才会触发执行,把rdd放到缓存之中。
rdd.cache()等价于rdd.persist(MEMORY_ONLY)(只把东西缓存在内存之中,如果超过了限制,新的会覆盖掉之前的)
rdd.persist(MEMORY_AND_DISK)如果存不下了会把多余的放在硬盘上。

五、分区
作用:1、增加并行度
2、减少通信开销
分区的个数尽量等于cpu的核数
spark中有spark.default.parallelism
本地模式默认是cpu数量,如果设置了local[n]则为N个,Apache Mesos模式默认是8个。
Yarn模式会把“集群中所有CPU核心数目总和”和“2”之间取大的。
1、设置分区个数:


2、重新分区
利用reparitition

3、自定义分区(默认可以是哈希分区)
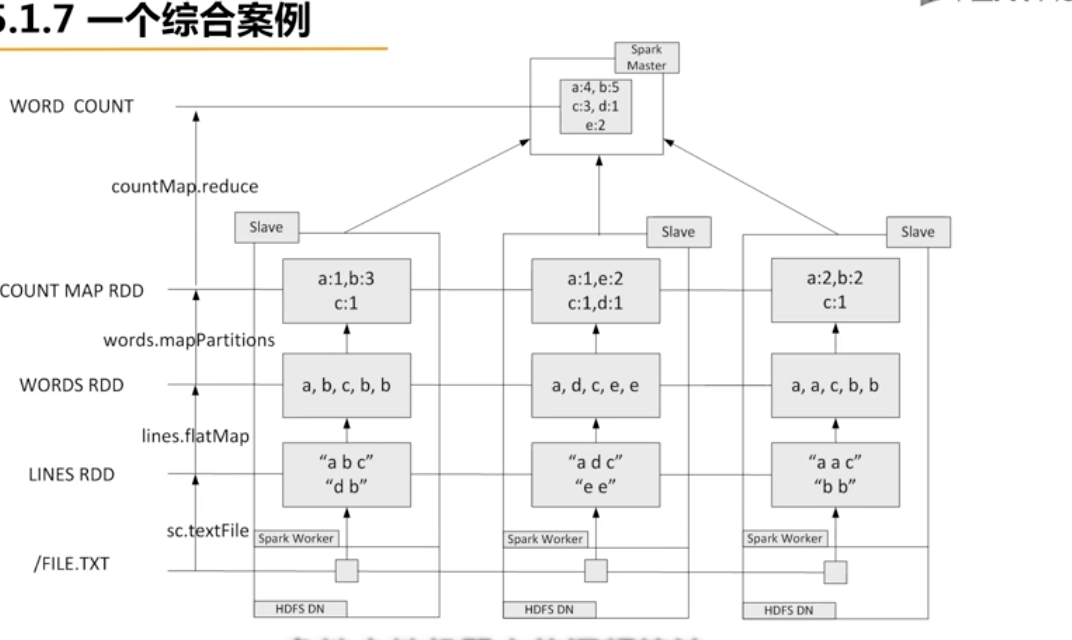
6、综合例子