2018软件工程第二次作业——个人项目
1.WordCount项目:031602510/scr
2.psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 80 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 80 | 60 |
| Development | 开发 | 2000 | 2700 |
| · Analysis | · 需求分析 (包括学习新技术) | 400 | 450 |
| · Design Spec | · 生成设计文档 | 30 | 50 |
| · Design Review | · 设计复审 | 30 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| · Design | · 具体设计 | 150 | 180 |
| · Coding | · 具体编码 | 1000 | 1300 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 280 | 370 |
| Reporting | 报告 | 90 | 120 |
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 实际用的时间会比起估计时间长上许多 | 所以应该安排好时间提前几天完成任务,不然会造成最后几天疯狂赶代码的情况 |
| 3.解题思路描述。即刚开始拿到题目后,如何思考,如何找资料的过程。 |
解题思路:仔细阅读作业题目之后,发现程序要完成四件任务:
- <1>统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
估摸着应该是可以用函数fopen()来打开文件,然后用 fgetc()来逐个获取文件中的字符,这个应该不难实现,不过写出来的代码才发现提示fopen()是unsafe的,查了资料才知道现在都建议用函数fopen_s(),二者在接受参数和返回值上都有区别。
-
<2>统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
一开始没有看清楚后面的单词实例,一开始感觉要求有歧义,走了很多弯路。对于单词总数的统计,我的思路是先将输入的input.txt文件存入一个字符串变量之中,然后对字符串进行预处理———大写转化为小写,除英文字母,数字以外的字符统一用空格符号代替,然后将字符串按空格隔开放进unordered_map<string, int> strMap;中,最后用容器vector和定义的sort();生成字典排序,然后遍历将符合条件的单词个数累加。
- <3>统计文件的有效行数:任何包含非空白字符的行,都需要统计。
行数的统计虽然会稍微简单点,不过也有一些坑点,比如空白行可能存在着空格不只有"\n",我写的程序一开始嗨啊忽略了第一行是空白的情况,多次测试之后才发现问题;
-
<4>统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
一开始把result.txt文件忘了,后来经过舍友提醒才知道的,关于单词频率的统计思路和之前写的单词数统计的主要思想差不多,不过统计的是字典序的单词,不过今天思考了一下比起用sort()函数,用堆排序单词会更快,还有听说有的同学遍历了十次容器每次取出最小的字典序单词,只需要O(10N),可以说是很黑科技了。
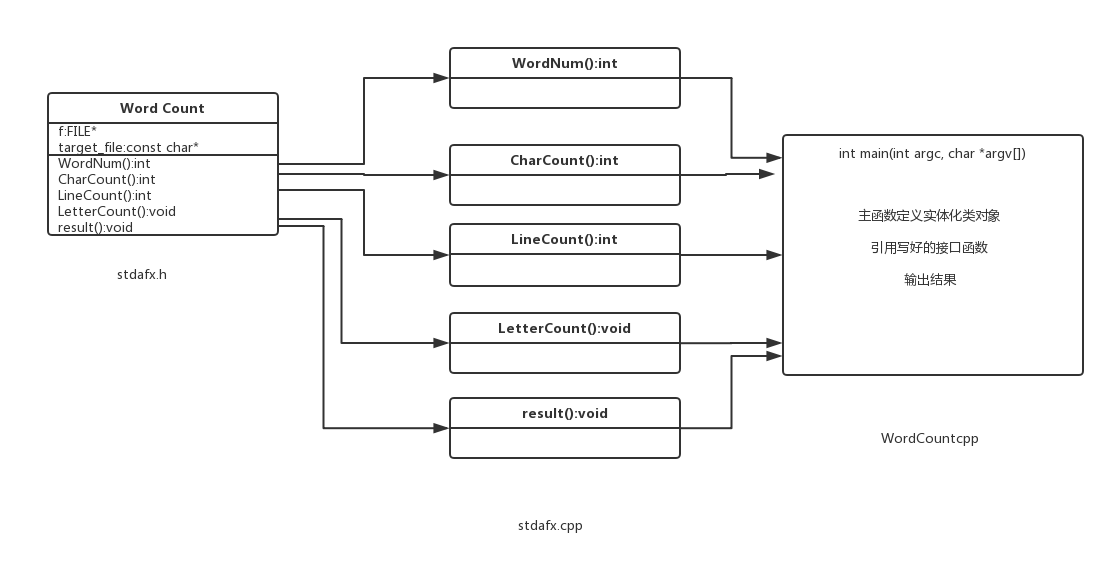
4.设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
设计的实现过程:
类图
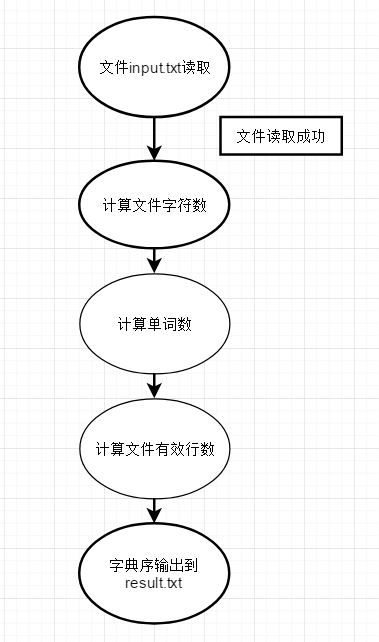
流程图
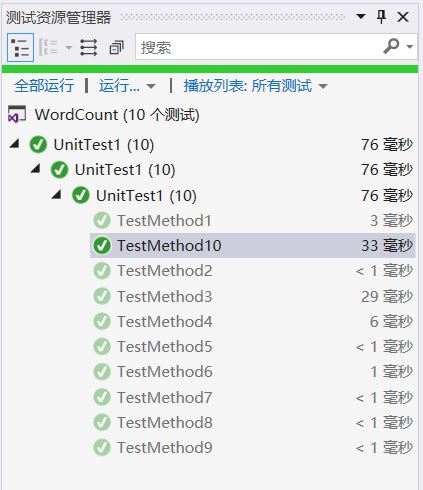
单元测试的设计,
其实总共有十个测试的,就不一一列出来了
text.cpp
#include "stdafx.h"
#include "CppUnitTest.h"
#include "../WordCount/stdafx.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace UnitTest1
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
int Charnum = 198;//期望的测试结果
int WordNum = 7;
int lineNum = 3;
char* filename = "F:\\WordCount\\UnitTest1\\test.txt";//文件存放位置绝对路径
FILE *fp;
fopen_s(&fp, filename, "r");
WordCount A(fp, filename);
Assert::AreEqual(lineNum, A.LineCount());//用的函数接口作为参数做测试
Assert::AreEqual(Charnum, A.CharCount());
Assert::AreEqual(WordNum , A.WordNum());
}
};
}
测试结果查看
5.记录在改进程序性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS2017的性能分析工具自动生成),并展示你程序中消耗最大的函数。
cpu占用图
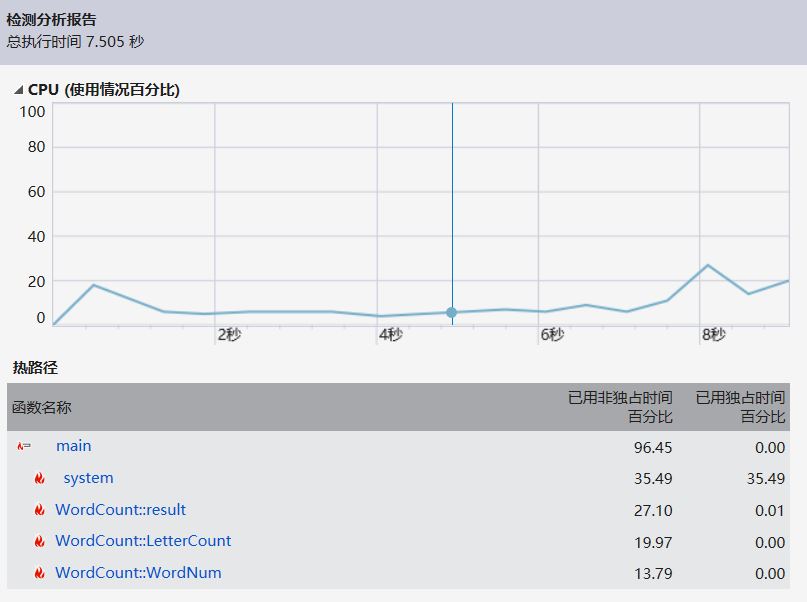
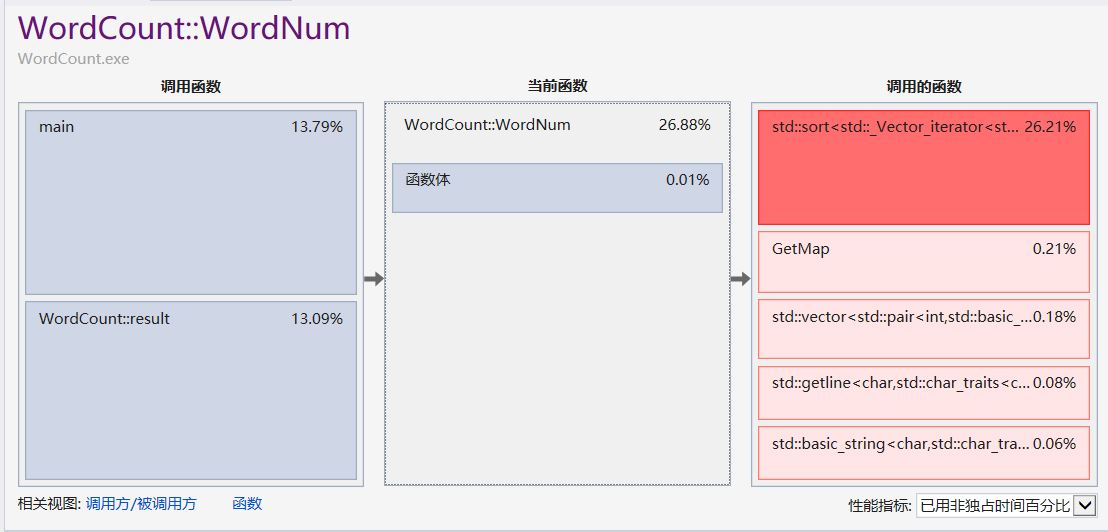
main函数占用

占用最大的操作原来和vector有关
代码覆盖率
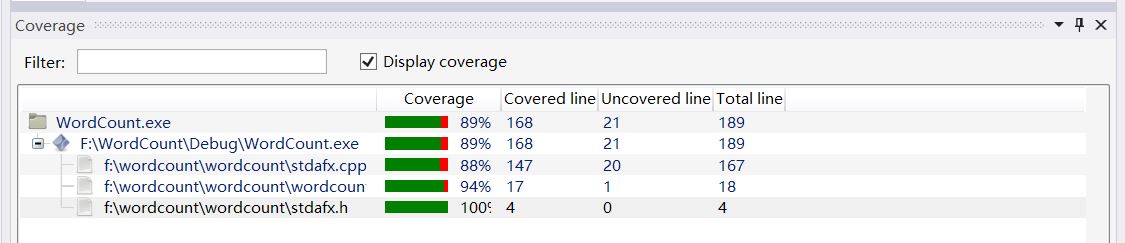
改进思路,对于容器vector和排序sort()是可以找到更好的替代,用堆排序或者遍历10次Map应该会减少算法复杂度。
6.代码说明。展示出项目关键代码,并解释思路与注释说明。
下面就是自己觉得花了比较多时间的核心代码:主要是单词以及频率输出部分,其他就不做赘述。
unordered_map<string, int> strMap;
bool mysort(pair < int, string > a, pair < int, string > b)//定义sort规则
{
if (a.first != b.first)
return a.first > b.first;
else
return a.second < b.second;
}
void GetMap(stringstream &ss)//生成string中单词的键值对
{
string strTmp;
while (ss >> strTmp)
{
unordered_map<string, int>::iterator it = strMap.find(strTmp);
if (it == strMap.end())
{
strMap.insert(unordered_map<string, int>::value_type(strTmp, 1));
}
else
strMap[strTmp]++;
}
}
void WordCount::LetterCount() //字符统计函数
{
string strFile, tmp;
int i = 0;
ifstream file(target_file); //读取当前文件夹下input.txt文件
while (getline(file, tmp))//直到文件结尾,依次逐行读入文本
{
strFile.append(tmp); //每次读入一行附加到strFile结尾
strFile.append(" ");//行尾补充空格
tmp.clear(); //记得清除,否则上一次读入比这次文本长,不会完全覆盖而出错
}
for (unsigned int i = 1; i <= strFile.size(); i++)//将字符串中英文字母大写转小写
{
if (strFile[i] >= 'A'&&strFile[i] <= 'Z')
strFile[i] += 32;
}
for (unsigned int i = 0; i < strFile.length(); i++)//分隔符号替换成为空格
{
if (ispunct(strFile[i]))
strFile[i] = ' ';
}
stringstream ss(strFile);
if (strMap.empty()) GetMap(ss);
vector < pair < int, string > > m;//容器
for (unordered_map<string, int>::iterator it = strMap.begin(); it != strMap.end(); ++it)
m.push_back(make_pair(it->second, it->first));
sort(m.begin(), m.end(), mysort);//排序
for (unsigned int k = 0; k < m.size(); ++k)//输出单词以及频率
{
string a = m[k].second.c_str();
if (
((a[0] >= 'a'&&a[0] <= 'z') || (a[0] >= 'A'&&a[0] <= 'Z')) &&
((a[1] >= 'a'&&a[1] <= 'z') || (a[1] >= 'A'&&a[1] <= 'Z')) &&
((a[2] >= 'a'&&a[2] <= 'z') || (a[2] >= 'A'&&a[2] <= 'Z')) &&
((a[3] >= 'a'&&a[3] <= 'z') || (a[3] >= 'A'&&a[3] <= 'Z')))
{
cout << '<' << a << '>' << ":" << m[k].first << endl;//打印结果
i++;
if (i >= 10)//输出频率前十
break;
}
}
}
7.结合在构建之法中学习到的相关内容与个人项目的实践经历,撰写解决项目的心路历程与收获。
一开始并没有感觉第二次作业会很难,git的操作之前有过,都蛮顺利的,写代码也没有花费很多时间。看到题目之后捋了一下思路,其实题目就是在之前c/c++课程的基础上,把一个个简单的功能糅合成一个程序,往里面掺杂一些文件的读写,排序,字符串处理等一些“简单”操作,应该不难。
但是当调试的时候,和同学一对比运行结果,就发现不少问题,代码有很多bug导致结果出错,主要还是没有考虑周全,有的地方代码不得不重新写过,用到Map和容器的时候,由于不熟悉,甚至结果完全出错,在电脑面前找了一个多小时,最后发现是自己写的Get Map()(往Map里面传数据的函数)多次传入,导致单词频率的统计结果翻了几倍。
接下来就是单元测试?什么是单元测试??怎么测试???这是第一次听的时候的心理活动,不过万能的百度和善良的同学给了我不少帮助,最后也学会了编写测试代码,看测试结果是否正确。期间还有一个小插曲,写好测试程序之后不管怎么测试,都会有部分通过不了,但是运行结果是没错的?!自己折腾了一两个小时,查Assert::AreEqual()的很多资料,感觉测试结果不应该不对啊,然后舍友说,你再运行一下未通过的测试,然后居然能通过了。
最后对于封装,也是一知半解,感觉封装的也不是很完善,第一次认真正式地封装。
现在对于这次的作业,感觉就是各种触及我的知识盲区,不过有所得。说实话,和周围同学比起来,作业对于我来说是挺吃力的,甚至于过程是艰难的,不过能听听同学聊聊程序的改进,向他们学习,上网络上查资料,自己也把查资料过程中的好博客和内容摘抄下来,积累起来,也有欣慰。