
数据库第二章总结
说明一下:下面会有大量的截图,因为我打不出符号
复习:笛卡尔积
A = {1,2,3}; B = {a,b,c} A * B = { (a,1)(a,2)(a,3), (b,1)(b,2)(b.3), (c,1)(c,2)(c,3) } num = Na * Nb
可以推广到一般形式
存在 集合 A,B,C,D …… n, 则其笛卡尔积:
A * B * C * D * …… * n = { (A1,B1,C1,D1,……,n1),(A1,B1,C1,D1,...,n2), ... } NUM = Na*Nb*Nc*Nd*...*Nn (所有的n不一定相等)
ps:笛卡尔积会产生
关系:P33
属性:
- 都有一个名称
- 允许存在一个属性集合
- 属性必须时原子的,即不可分割(1NF,第一范式)
-
- 多值属性值不是原子的
- 符合属性值不是原子的
4. 特殊值null是每一个域的成员
ps:空值会给数据库访问带来困难,需要避免使用
概念:
1、关系模式:描述关系的结构
2、关系实例:表示关系的一个特定实例,也就是所包含是一组特定行
变量 --> 关系
变量类型 --> 关系模式
变量值 --> 关系实例
码、键:
1、某个值能够在一个关系中唯一的标志一个元组,则K是R的 超码
例如:身份证号码、学号或者身份证号加学号加银行卡号
2、候选码:
超码的一个子集,当超码集合不唯一,超码的集合中的子集称为候选码
3、候选码:k是一个候选码,K是一个主键,则需要用户明确定义。(下划线表示)
就像上面的例子,从身份证,银行卡,学号……里选出一个(黑体)
4、外键:(保证参照完整性)
假设存在关系 r 和 s:r(A, B, C),s(B, D),则在关系r上的属性B称作参照s的外码
r也称为依赖的 参照关系
例如:
学生(ID, name, PID, age)—— 参照关系
专业(PID, Pname)—————————— 被参照关系(target relation)
其中属性专业号称为学生的外码
instructor(ID, name, dep_name, salary) - 参照关系被参照关系
departerment(dept_name, building, budget) - 被参照关系
ps:参照关系中外码值必须在被参照关系中实际存在或为NULL
关系代数和关系运算:
关系代数是SQL的基础
基本操作:{考虑集合性质}
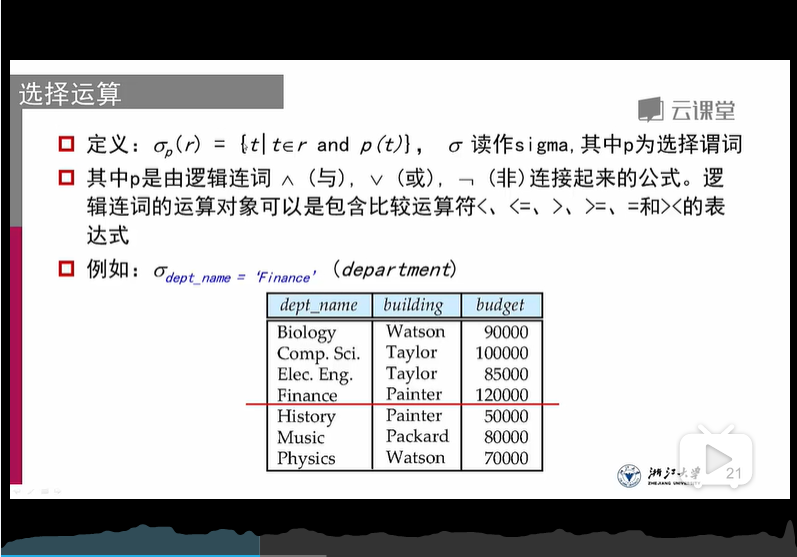
1、选择操作
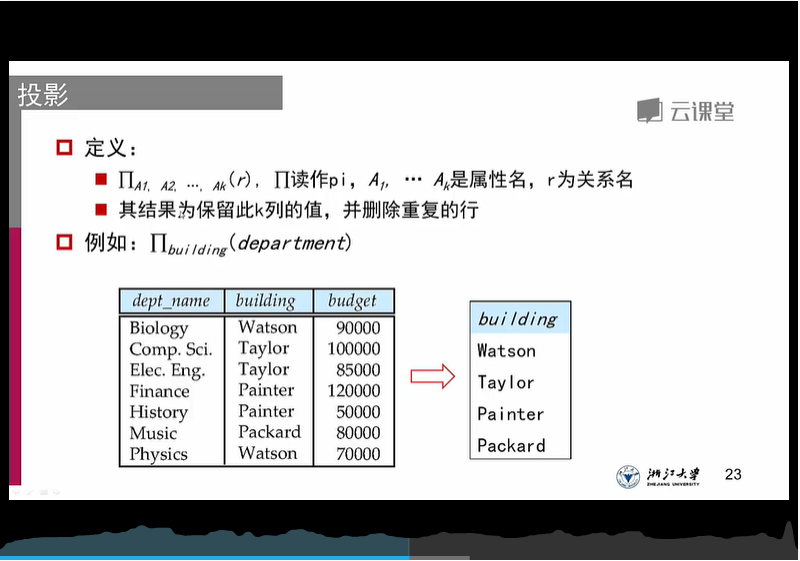
2、投影操作:取单个元素,采用投影
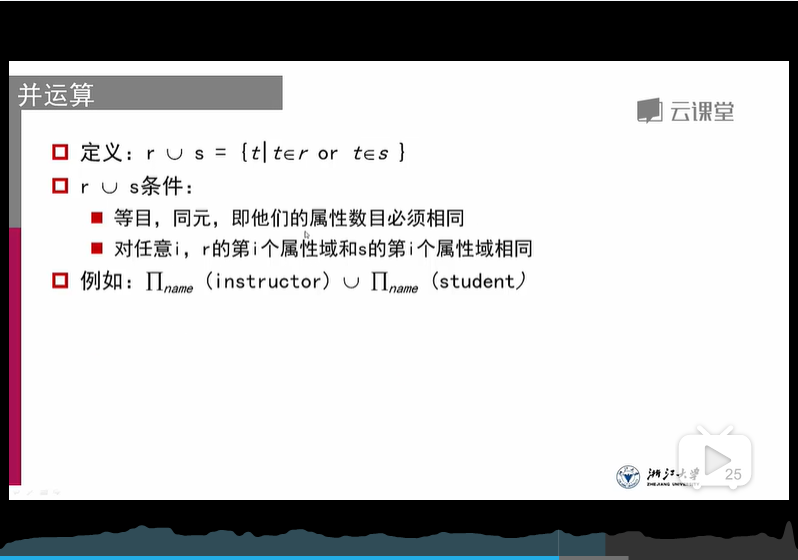
3、并操作 {和集合的并集差不多}
限制:等目,同元(属性的数目必须相同)
对任意i,r的第i个属性域和s的第i个属性域相同
(其外模式层采用同一个结构)存疑
4、差运算:
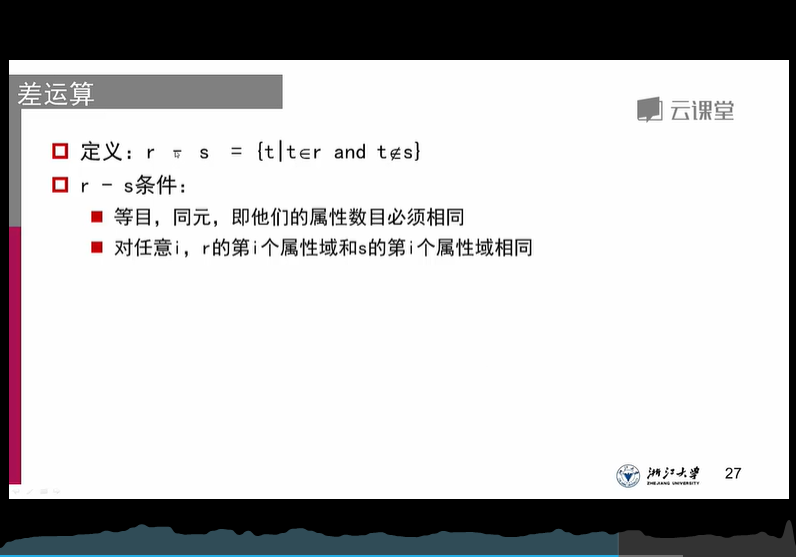
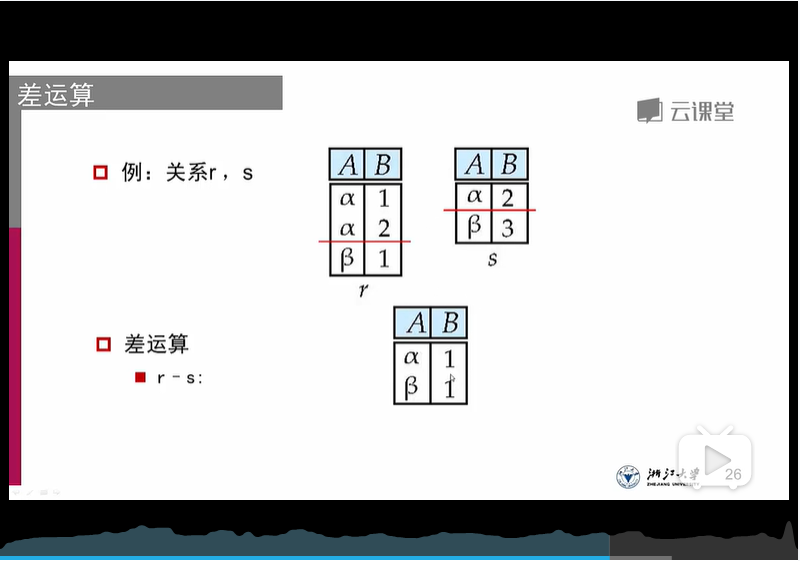
限制与3相同
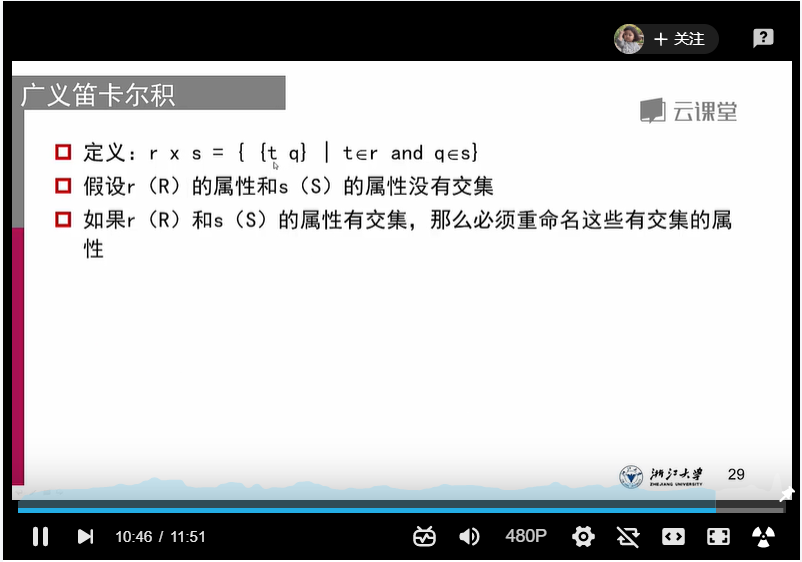
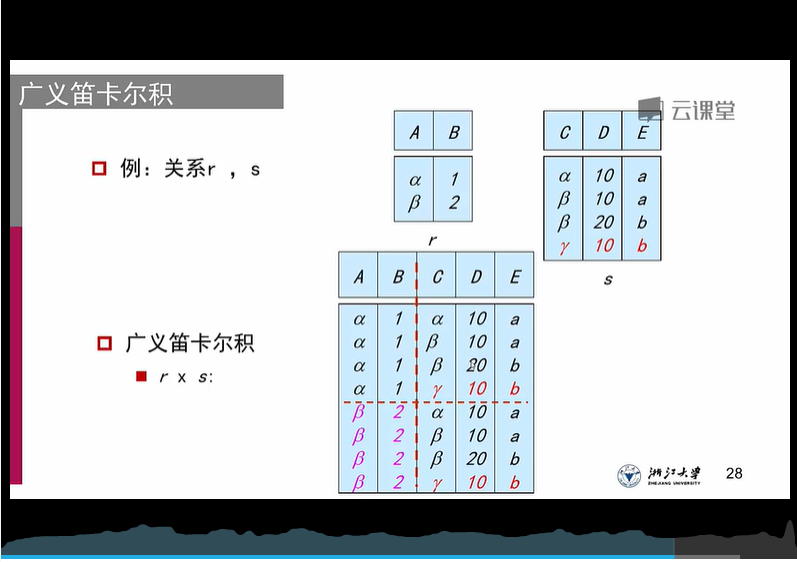
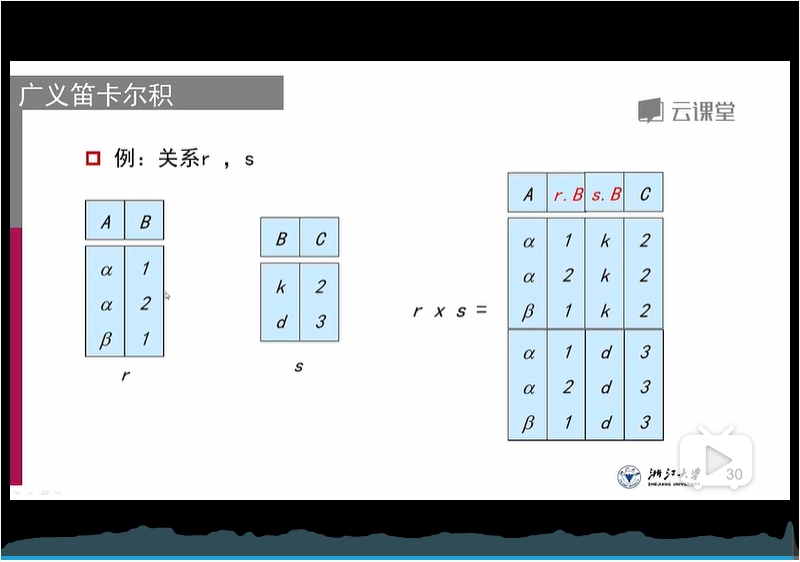
5、笛卡尔积:{当一个选择涉及到多个relation,辣么就需要笛卡尔积}
出现同名属性,当作不同名处理
复合运算:基本操作的复合
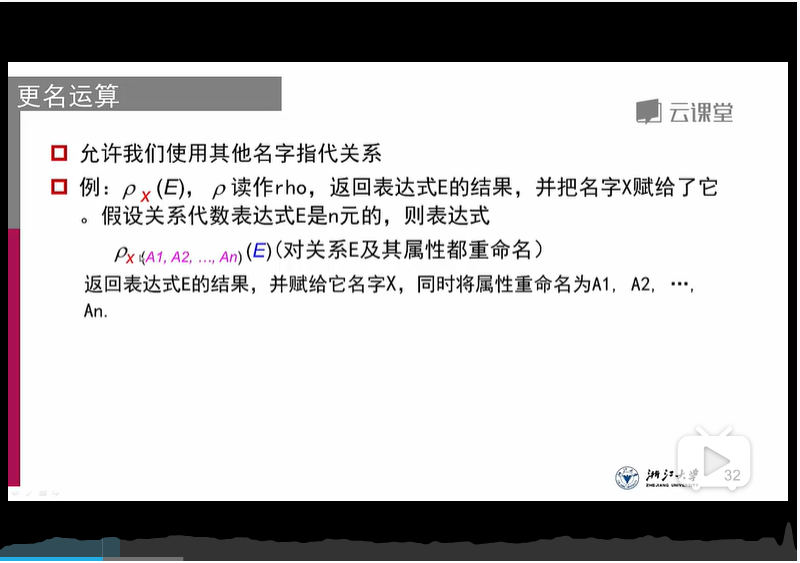
6、更名运算:允许使用其他名字对输出的关系进行重命名
附加运算:{莫得增加新功能,只是简化表达式,都可以被基本表达式所表示}
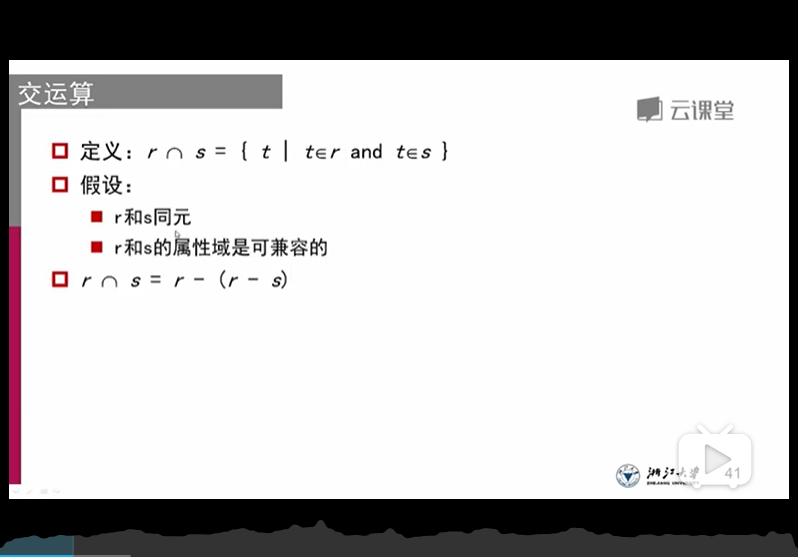
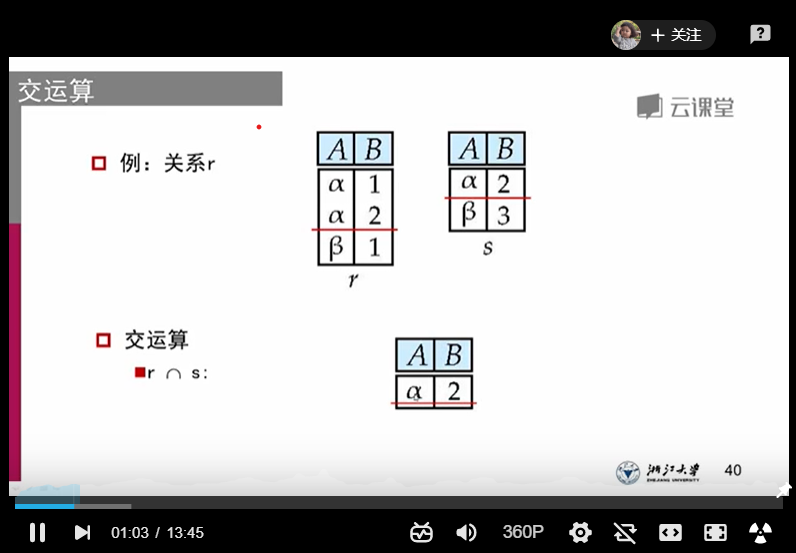
1、交运算:
r和s同元
r和s的属性域是可兼容的
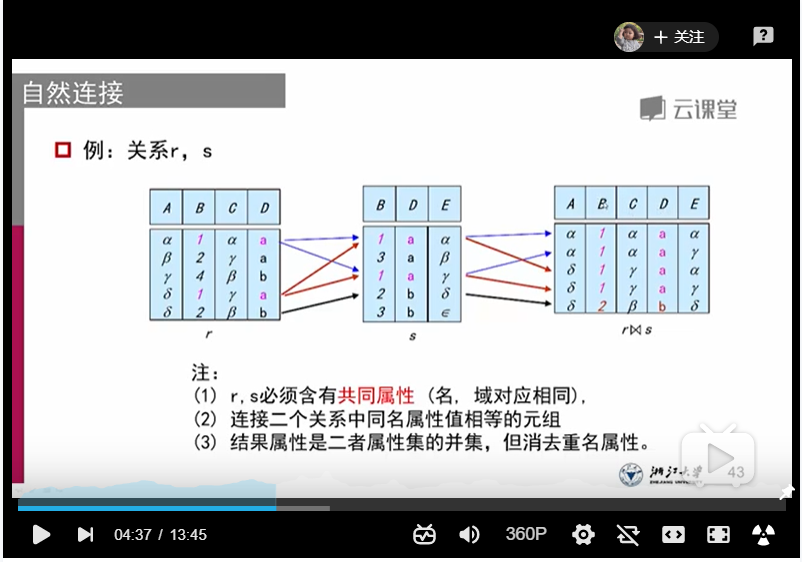
2、自然连接:(个人觉得这就是个查找相同元素并保留其所有属性的运算)
同名属性只出现一次(名,域对应相同)
1、r,s必须含有同名属性
2、连接两个关系中同名属性值相等的元组
3、结果属性是二者属性的集合

3、theta连接:连接条件可以由用户来指定
4、除运算:比较复杂,看图吧(凡是查询条件里涉及到“全部,所有”优先考虑除法)
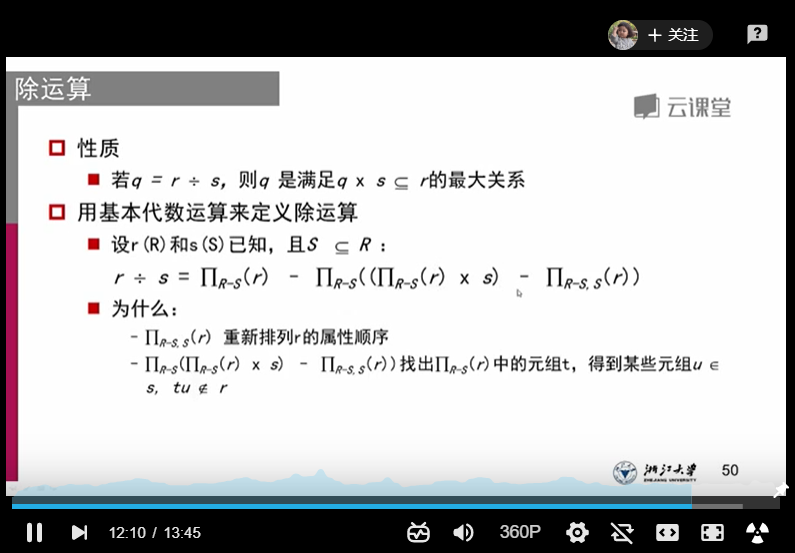
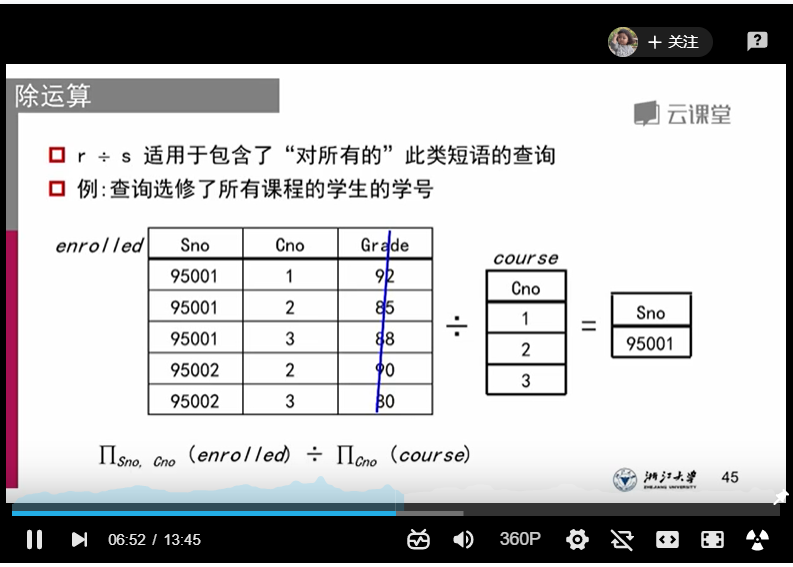
5、赋值操作:
可以将查询表达为一个顺序程序,该程序包括:
——一系列赋值
——一个值被作为查询结果显示的表达式
赋值必须赋给一个临时的关系变量

广义投影:
允许在投影列表中是由算数来对投影进行拓展
聚集操作:
平均值:
最小值:
最大值:
值的综合:
值的数量:
直接看图吧,符号太难找了
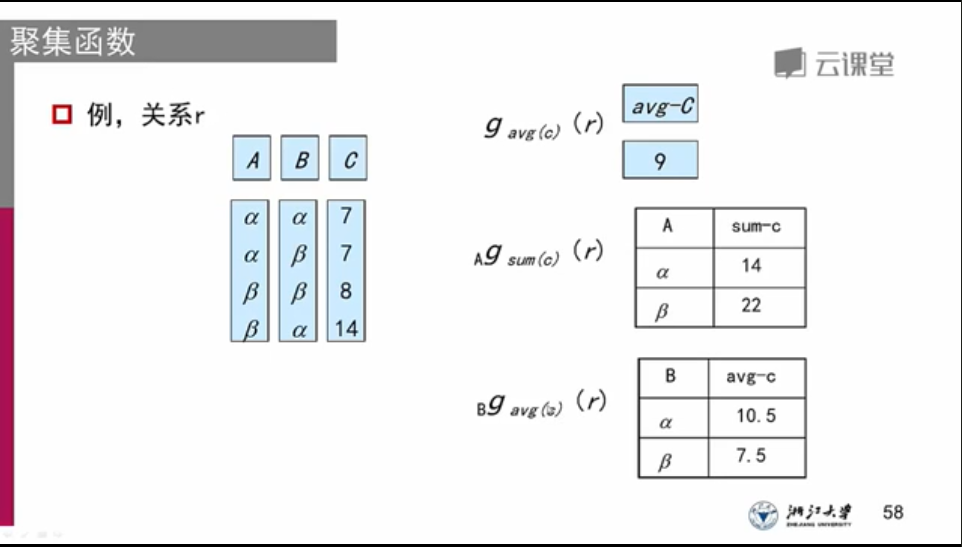

ps:聚集操作的运算结果没有名称,需要与更名运算连用
外连接:
外连接运算时连接运算的扩展,处理缺失信息,
自然连接有一部分找不到的对应元组,外连接将这个找不到的元组加入
自然连接的结构
存在关系 A 和 关系 B
- 左外连接,将 B 在 A 中不匹配的元组添加到 自然连接 中,不知道或者不存在的值置为NULL
- 右外连接,将 A 在 B 中不匹配的元组添加到 自然连接 中,不知道或者不存在的值置为NULL
- 在连接中,将 A 与 B 不匹配的所有元组添加到 自然连接 中,不知道或者不存在的值置为NULL
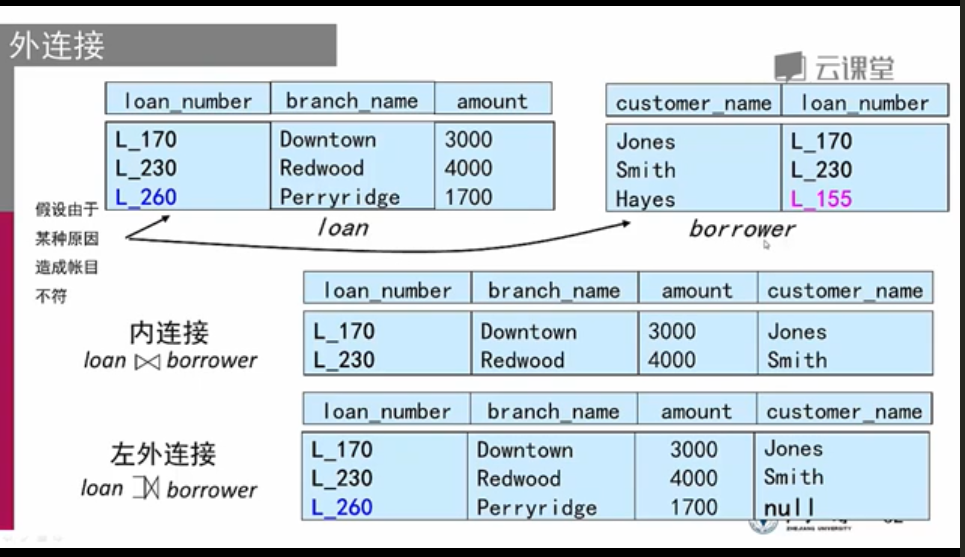

空值:{特殊值null是每一个域的成员}
- 元组的某些值可以为空值
- 空值表示不知道 和 不存在
- 聚集函数会忽略空值
空值可以作为返回结果
遵循SQL对空值的操作
4.为了消除重复和分组,空值和其他值同等对待
-
- 一种方式是两个空值被认为是相同的
- 另一个方法两个空值被认为是不同的
PS: 两种都可行,最好遵循SQL对空值的处理语义
逻辑比较问题:
考虑:
not(A < 5) 与 (A>=5)
若前式为真,那与后式矛盾;
若后式为真,那与前式矛盾;
所以:
空值的的任何比较结果都为:unknown
5.使用特殊值的三值逻辑:
OR:(unknown or false) = true
AND:(unknown AND false) = false
NOT:(not unknown) = unknown
其他都为unknown

在SQL中,谓词P的值为unknown ,那么 "P is unknown"的值为true
数据库的修改:
删除:{通过覆盖实现(赋值操作和差运算)}
r <- r - E
其中,r是关系,E是关系代数查询
插入:{赋值操作+并操作}
r <- r U E
其中,r是关系,E是关系代数查询
更新:{赋值+广义投影}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号