
Atlas(元数据管理)从扫盲到和Hive、HBase、Kafka、Flink等集成开发
注:由于文章篇幅有限,获取资料可直接扫二维码!

大数据技术交流QQ群:207540827
速点链接加入高手战队:http://www.dajiangtai.com/course/112.do

先对数据分个类
企业数据管理的内容及范畴通常包括交易数据、主数据以及元数据。
(1)交易数据:用于纪录业务事件,如客户的订单,投诉记录,客服申请等,它往往用于描述在某一个时间点上业务系统发生的行为。
(2)主数据:主数据则定义企业核心业务对象,如客户、产品、地址等,与交易流水信息不同,主数据一旦被记录到数据库中,需要经常对其进行维护,从而确保其时效性和准确性;主数据还包括关系数据,用以描述主数据之间的关系,如客户与产品的关系、产品与地域的关系、客户与客户的关系、产品与产品的关系等。
(3)元数据:即关于数据的数据,用以描述数据及其环境的结构化信息,便于查找、理解、使用和管理数据。
什么是元数据管理
我们前面讲解的技术和平台都在解决主数据和交易数据的采集、加工、存储、计算等问题。但面对海量且持续增加的各式各样的数据时,你一定想知道数据从哪里来以及它如何随时间而变化?采用Hadoop必须考虑数据管理的实际情况,元数据与数据治理成为企业级数据湖的重要部分。
所谓元数据管理其实通俗来讲就两点:
(1)把各个组件(一般是存储)的元数据收集起来统一管控
(2)利用这些收集的元数据去实现各种上层应用以满足各种数据治理场景(数组资产目录、数据分类、搜索与血缘等等)
Atlas是什么
Apache Atlas是Hadoop社区为解决Hadoop生态系统的元数据治理问题而产生的开源项目,它为Hadoop集群提供了包括 数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。可以帮助企业构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队,提供围绕这些数据资产的协作功能。
Atlas不尽致力于管理共享元数据、数据分级、审计、安全性以及数据保护等方面,同时努力与Apache Ranger整合,用于数据权限控制策略。
Apache Atlas是hadoop的数据治理和元数据框架,它提供了一个可伸缩和可扩展的核心基础数据治理服务集,使得 企业可以有效的和高效的满足Hadoop中的合规性要求,并允许与整个企业的数据生态系统集成。

Atlas架构与原理
Atlas 是一个可伸缩且功能丰富的数据管理系统,深度集成了 Hadoop 大数据组件。简单理解就是一个跟 Hadoop 关系紧密的,可以用来做元数据管理的一个系统,整个结构 图如下所示:
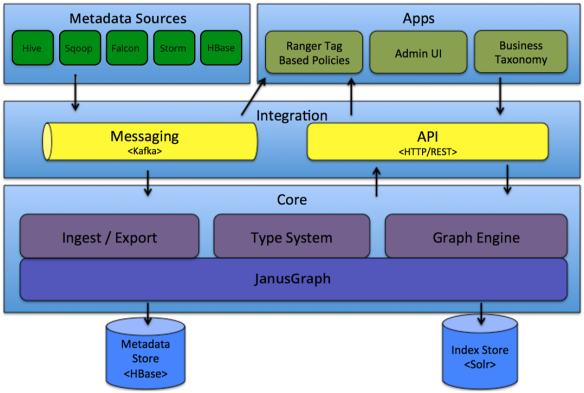
Atlas核心功能分层及说明

集成Hive
集成原理

验证Hive元数据采集效果
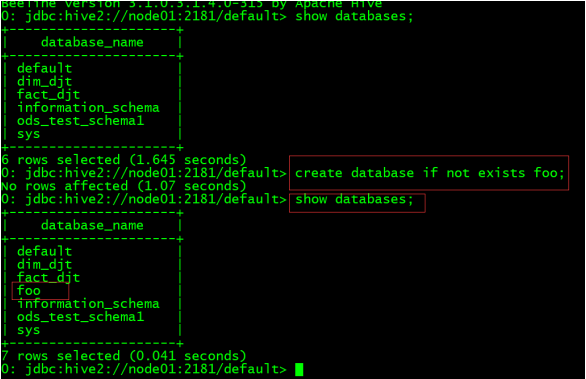
(1)先查看Atlas里是否有Hive元数据

(2)进入Hive创建一个库表
create database if not exists foo;
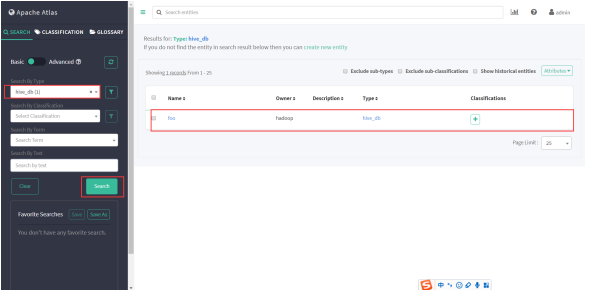
(3)再次进入Atlas查看元数据
历史元数据处理
在上线Atlas之前Hive可能运行很久了,所以历史上的元数据无法触发hook,因此需要一个工具来做初始化导入。
Apache Atlas提供了一个命令行脚本 import-hive.sh ,用于将Apache Hive数据库和表的元数据导入Apache Atlas。该脚本可用于使用Apache Hive中的数据库/表初始化Apache Atlas。此脚本支持导入特定表的元数据,特定数据库中的表或所有数据库和表。
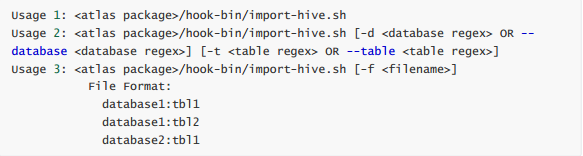
导入工具调用的是对应的Bridge:org.apache.atlas.hive.bridge.HiveMetaStoreBridge执行导入脚本任意找一台安装过Atlas client的节点,执行如下命令:
注意:一定要进入atlas用户,因为Atlas的Linux管理账户是atlas,其他账户下可能会报没有权限的错误。
脚本执行过程中会要求输入Atlas的管理员账号/密码(admin/admin%123),看到如下信息就成功了:

查看元数据
注:由于文章篇幅有限,更多基础核心内容、生产环境安装部署、集成HBase、集成Kafka、源码编译等完整文档可扫下面二维码。


