
满满干货,Kylin从入门到精通,含Kylin3.0生产环境实战总结
注:由于文章篇幅有限,获取资料可直接扫二维码,更有深受好评的大数据实战精英+架构师好课等着你。
大数据技术交流QQ群:207540827

速点链接加入高手战队:http://www.dajiangtai.com/course/112.do

唯一由中国人主导的Apache顶级项目Kylin到底是什么
Apache Kylin(Extreme OLAP Engine for Big Data)是一个开源的分布式分析引擎,为Hadoop等大型分布式数据平台之上的超大规模数据集提供标准SQL查询及多维分析(OLAP)能力,并提供亚秒级的交互式分析功能。
它最初由eBay开发并贡献给开源社区。核心特性有
(1)为Hadoop提供标准SQL支持(大部分)
(2)支持超大数据集(预计算)
(3)亚秒级交互式查询(预计算)
(4)可伸缩高吞吐(MR、Spark、HBase)
(5)BI工具无缝集成
Apache Kylin是目前唯一由中国人主导的Apache顶级项目,核心开发者及贡献者都是中国人。

哪些公司在用Kylin?说不定就有你一直想进的哦!


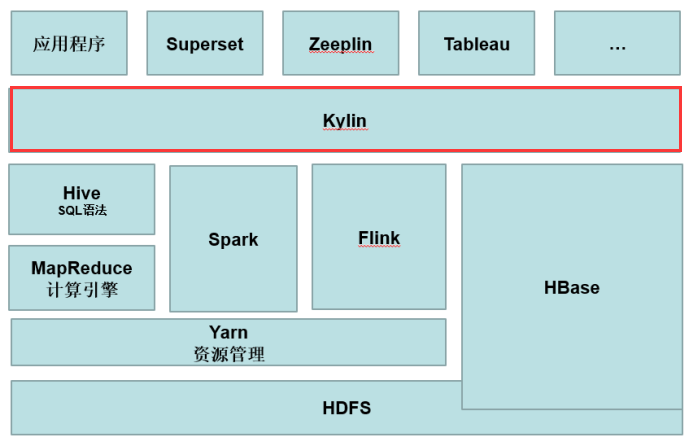
看Kylin与其他组件的关系,凸显Kylin重要地位
更多
第二章:Kylin架构原理
第三章:Kylin集群部署
第四章:Kylin开发流程
第五章:Cube增量构建
第六章:Cube实时构建
第七章:Kylin性能调优
第八章:Kylin3.x部署和使用
第九章:Kylin运维
第十章:BI工具这个
第十一章:Spark、Flink构建引擎整合
第十二章:Kylin源码编译
