
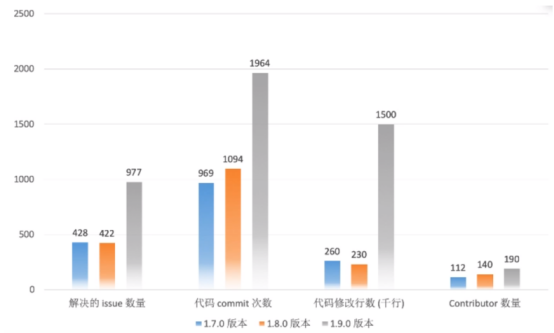
Flink1.9重大改进和新功能
注:由于文章篇幅有限,获取资料可直接扫二维码 ,更有深受好评的Flink大数据项目实战精品课等你。
,更有深受好评的Flink大数据项目实战精品课等你。
大数据技术交流QQ群:207540827

一、Flink1.9.0的里程碑意义

二、重构 Flink WebUI
Flink社区讨论了现代化 Flink WebUI 的提案,决定采用 Angular 的最新稳定版来重构这个组件。从Angular 1.x 跃升到了 7.x 。重新设计的 UI 是 1.9.0 的默认UI,不过有一个按钮可以切换到旧版的WebUI。
点击上图所示按钮可切换至旧版Web UI:

新版更加漂亮,性能方面也表现更好。
注意:未来,新版UI不保证跟旧版 WebUI 的功能是对齐的,且待新版本稳定后将会完全移除旧版WebUI。
三、架构改动
Flink老架构及存在的问题
Flink设计理念与当前架构
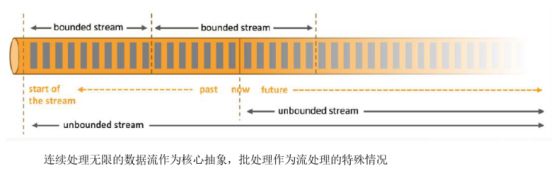
Flink的设计理念如下图:
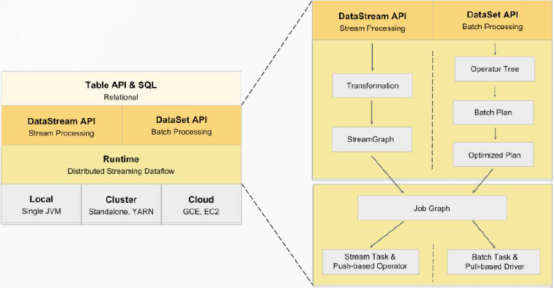
存在的问题
(1)从Flink用户角度
1)开发的时候需要在两个底层API中进行选择
2)不同的语义、不同的connector支持、不同的错误恢复策略…
3)Table API也会受不同的底层API、不同的connector等问题的影响
(2)从Flink开发者角度
1)不同的翻译流程,不同的算子实现、不同的Task执行…
2)代码难以复用
3)两条独立的技术栈需要更多人力功能开发变慢、性能提升变难,bug变多
Flink新架构
既然批是流的一个特例,是否可以。。。?一个大胆的想法(流批统一):

Blink本身就在做去DataSet的工作,在 Blink 捐赠给 Apache Flink 之后,社区就致力于为 Table API 和SQL 集成 Blink 的查询优化器和 runtime。第一步,我们将 flink-table 单模块重构成了多个小模块(FLIP-32)。这对于 Java 和 Scala API 模块、优化器、以及 runtime 模块来说,有了一个更清晰的分层和定义明确的接口。
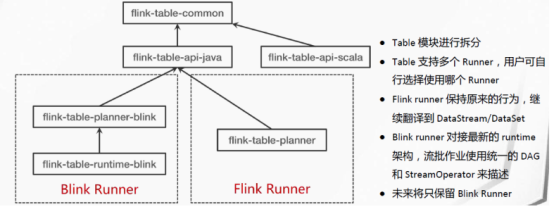
紧接着,社区扩展了 Blink 的 planner 以实现新的优化器接口,所以现在有两个插件化的查询处理器来执行 Table API 和 SQL:1.9 以前的 Flink 处理器和新的基于 Blink 的处理器。基于 Blink 的查询处理器提供了更好地 SQL 覆盖率(1.9 完整支持 TPC-H,TPC-DS 的支持在下一个版本的计划中)并通过更广泛的查询优化(基于成本的执行计划选择和更多的优化规则)、改进的代码生成机制、和调优过的算子实现来提升批处理查询的性能。除此之外,基于 Blink 的查询处理器还提供了更强大的流处理能力,包括一些社区期待已久的新功能(如维表 Join,TopN,去重)和聚合场景缓解数据倾斜的优化,以及内置更多常用的函数。
因此,Flink1.9架构长成了这个样子:
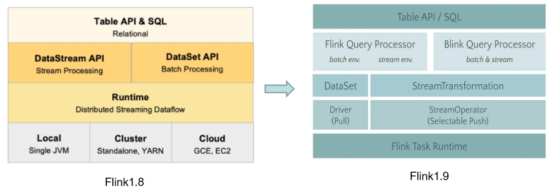
不过, Blink 的查询处理器的集成还没有完全完成,暂时先不忙上生产。

