flink学习笔记-各种Time
说明:本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
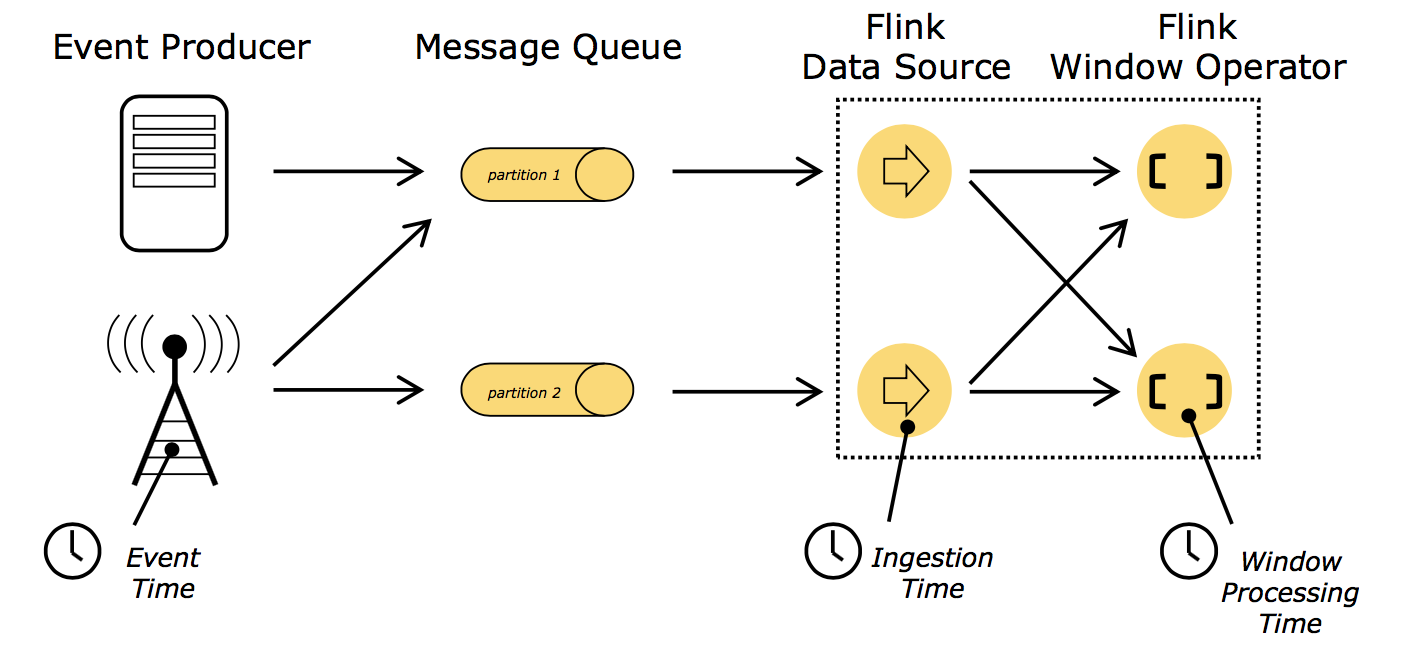
从上图可以看出Flink 中的Time大致分为以下三类:
1.Event Time:Event 真正产生的时间,我们称之为Event Time。
2.Ingestion Time:Event 事件被Source拿到,进入Flink处理引擎的时间,我们称之为Ingestion Time。
3.Window Processing Time:Event事件被Flink 处理(比如做windows操作)时的时间,我们称之为Window Processing Time。
4. Stateful Operations
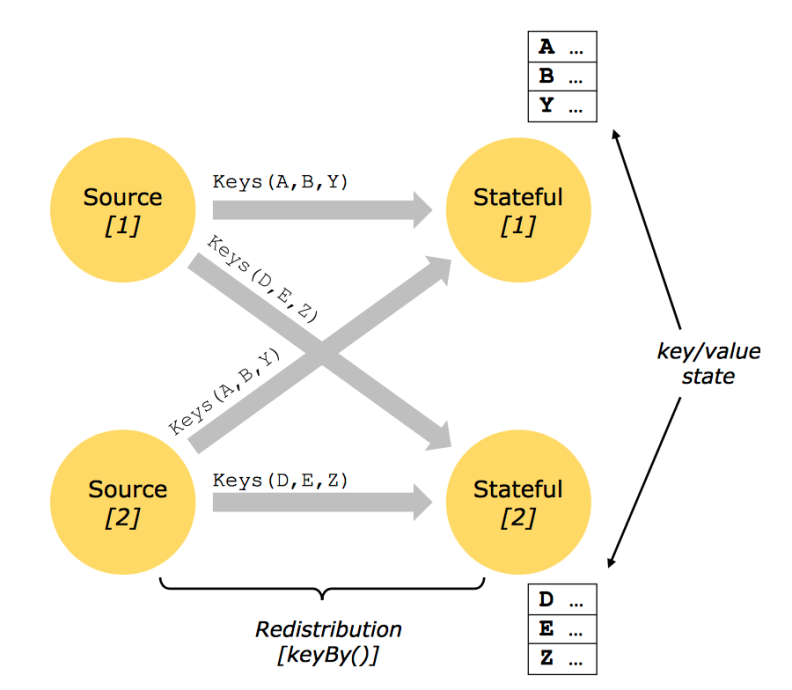
什么是状态?
state一般指一个具体的task/operator的状态,比如当前处理那些数据,数据处理的进度等等。
Flink state操作状态分为两类:
1.Operator State
Operator State跟一个特定operator的一个并发实例绑定,整个operator只对应一个state。
2.Keyed State
基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,可能都对应一个state。
Flink 每个操作状态又分为两类:
Keyed State和Operator State可以以两种形式存在:原始状态和托管状态( Flink框架管理的状态)。
1.原始状态:比如一个字符串或者数组,它需要序列化,保存到内存或磁盘,或者外部存储中,这就是它的原始状态。
2.托管状态:比如数据放在Hash表中,或者放在HDFS中,或者放在rocksdb中,这种就是托管状态。当需要处理数据的时候,从托管状态中读取出来,还原成原始状态,甚至变量和集合,然后再进行处理。
5.Checkpoints(备份)
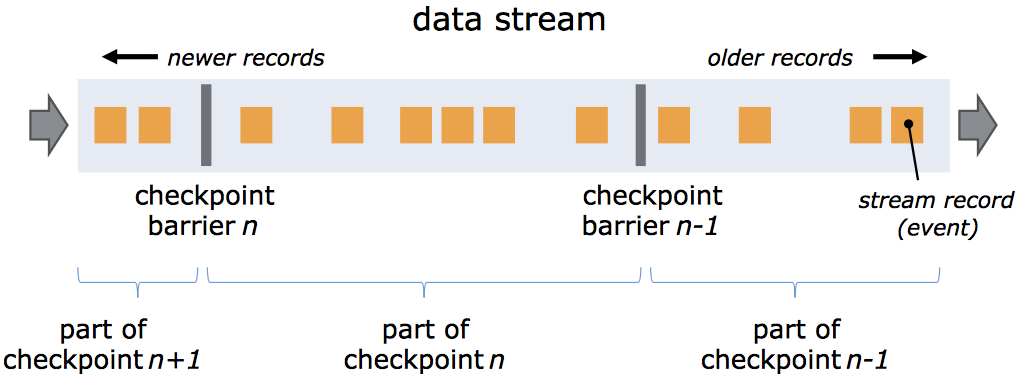
什么是checkpoint?
所谓checkpoint,就是在某一时刻,将所有task的状态做一个快照(snapshot),然后存储到State Backend(比如hdfs)。checkpoint拥有轻量级容错机制,可以保证exactly-once 语义,用于内部失败的恢复(比如当应用挂了,它可以自动恢复从上次的进度接着执行)。
checkpoint基本原理:通过往source 注入barrier(可以理解为特殊的Event),barrier作为checkpoint的标志,它会自动做checkpoint无需人工干预。
6.Savepoint
savepoint是流处理过程中的状态历史版本,它具有可以replay的功能。用于外部恢复,当Flink应用重启和升级,它会做一个先做一个savepoint,下次应用启动可以接着上次进度执行。
savepoint两种触发方式:
1.Cancel with savepoint
2.手动主动触发
savepoint可以理解为是一种特殊的checkpoint,savepoint就是指向checkpoint的一个指针,需要手动触发,而且不会过期,不会被覆盖,除非手动删除。正常情况下的线上环境是不需要设置savepoint的。除非对job或集群做出重大改动的时候,需要进行测试运行。
(4)Flink Runtime
1. Flink运行时架构
1.1Flink架构
Flink 运行时架构主要包含几个部分:Client、JobManager(master节点)和TaskManger(slave节点)。
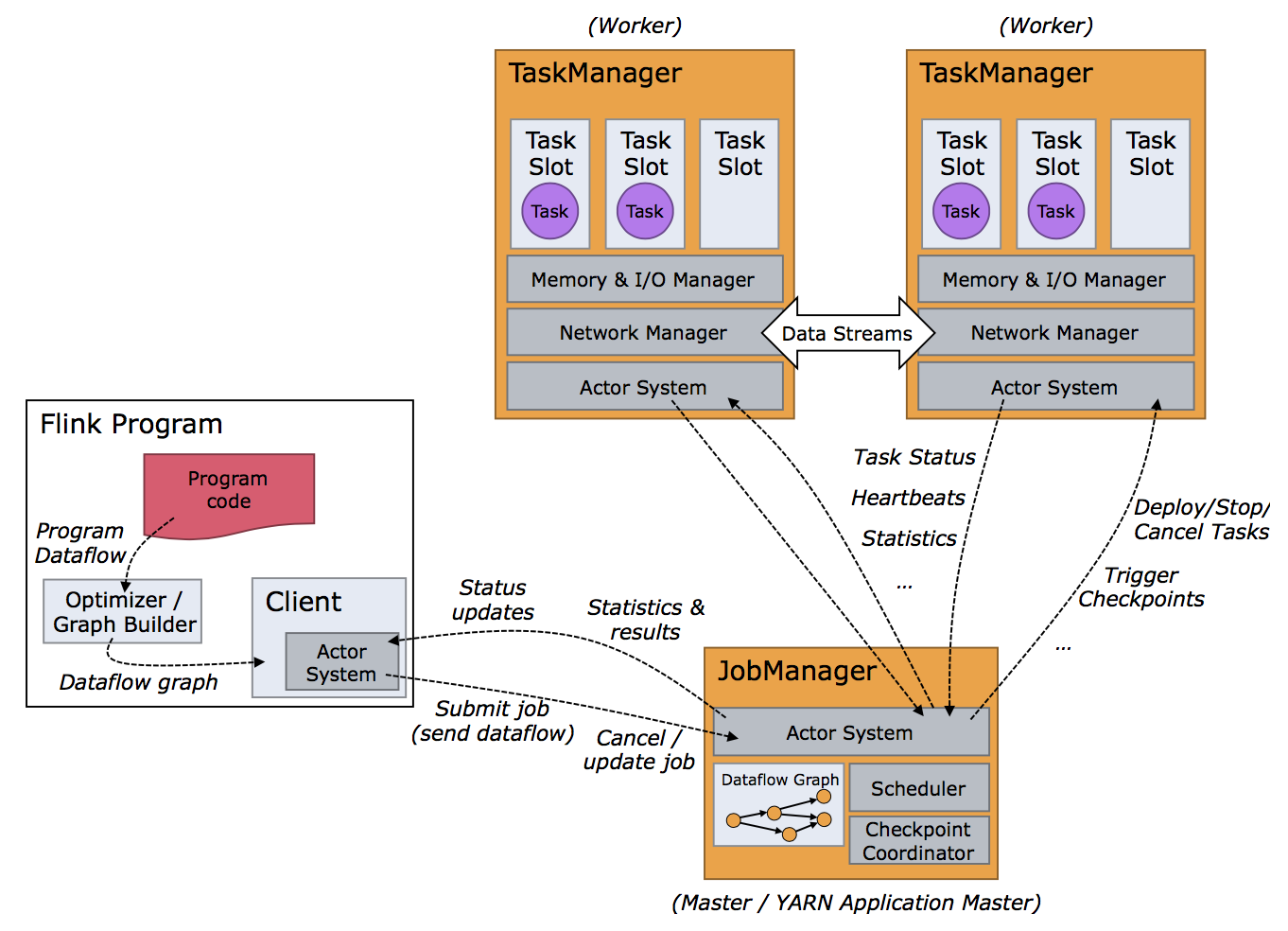
Client:Flink 作业在哪台机器上面提交,那么当前机器称之为Client。用户开发的Program 代码,它会构建出DataFlow graph,然后通过Client提交给JobManager。
JobManager:是主(master)节点,相当于YARN里面的REsourceManager,生成环境中一般可以做HA 高可用。JobManager会将任务进行拆分,调度到TaskManager上面执行。
TaskManager:是从节点(slave),TaskManager才是真正实现task的部分。
Client提交作业到JobManager,就需要跟JobManager进行通信,它使用Akka框架或者库进行通信,另外Client与JobManager进行数据交互,使用的是Netty框架。Akka通信基于Actor System,Client可以向JobManager发送指令,比如Submit job或者Cancel /update job。JobManager也可以反馈信息给Client,比如status updates,Statistics和results。
Client提交给JobManager的是一个Job,然后JobManager将Job拆分成task,提交给TaskManager(worker)。JobManager与TaskManager也是基于Akka进行通信,JobManager发送指令,比如Deploy/Stop/Cancel Tasks或者触发Checkpoint,反过来TaskManager也会跟JobManager通信返回Task Status,Heartbeat(心跳),Statistics等。另外TaskManager之间的数据通过网络进行传输,比如Data Stream做一些算子的操作,数据往往需要在TaskManager之间做数据传输。
1.2. TaskManger Slot
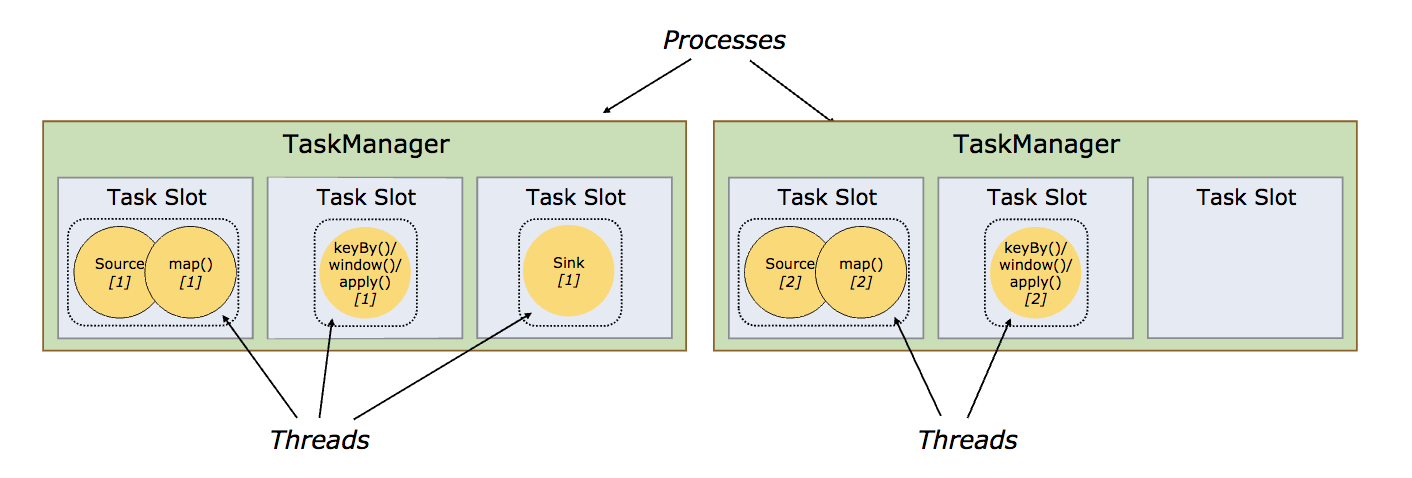
TaskManager是进程,他下面运行的task(整个Flink应用是Job,Job可以拆分成很多个task)是线程,每个task/subtask(线程)下可运行一个或者多个operator,即OperatorChain。Task是class,抽象的,subtask是Object(类比学习),具体的。
一个TaskManager通过Slot(任务槽)来控制它上面可以接受多少个task,比如一个TaskManager划分了3个Task Slot(仅限内存托管,目前CPU未做隔离),它只能接受3个task。Slot均分TaskManager所托管的内存,比如一个TaskManager有6G内存,那么每个Slot分配2G。
同一个TaskManager中的task共享TCP连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销。一个TaskManager有N个槽位只能接受N个Task吗?不是,后面会讲共享槽位。
1.3. OperatorChain && Task
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。以wordcount为例,解析不同视图下的数据流,如下图所示。
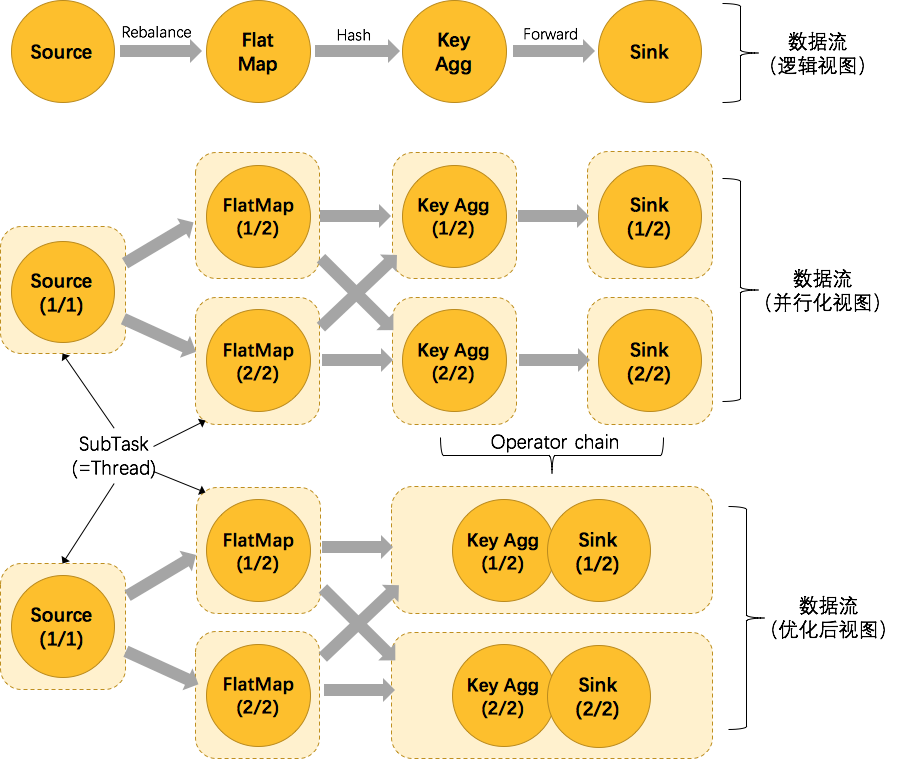
数据流(逻辑视图)
创建Source(并行度设置为1)读取数据源,数据经过FlatMap(并行度设置为2)做转换操作,然后数据经过Key Agg(并行度设置为2)做聚合操作,最后数据经过Sink(并行度设置为2)将数据输出。
数据流(并行化视图)
并行度为1的Source读取数据源,然后FlatMap并行度为2读取数据源进行转化操作,然后数据经过Shuffle交给并行度为2的Key Agg进行聚合操作,然后并行度为2的Sink将数据输出,未优化前的task总和为7。
数据流(优化后视图)
并行度为1的Source读取数据源,然后FlatMap并行度为2读取数据源进行转化操作,然后数据经过Shuffle交给Key Agg进行聚合操作,此时Key Agg和Sink操作合并为一个task(注意:将KeyAgg和Sink两个operator进行了合并,因为这两个合并后并不会改变整体的拓扑结构),它们一起的并行度为2,数据经过Key Agg和Sink之后将数据输出,优化后的task总和为5.
1.4. OperatorChain的优点和组成条件
OperatorChain的优点
1.减少线程切换
2.减少序列化与反序列化
3.减少数据在缓冲区的交换
4.减少延迟并且提高吞吐能力
OperatorChain 组成条件
1.没有禁用Chain
2.上下游算子并行度一致 。
3.下游算子的入度为1(也就是说下游节点没有来自其他节点的输入)。
4.上下游算子在同一个slot group(后面紧跟着就会讲如何通过slot group先分配到同一个solt,然后才能chain) 。
5.下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)。
6.上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)。
7.上下游算子之间没有数据shuffle (数据分区方式是 forward)。
1.5. 编程改变OperatorChain行为
Operator chain的行为可以通过编程API中进行指定,可以通过在DataStream的operator后面(如someStream.map(..))调用startNewChain()来指示从该operator开始一个新的chain(与前面截断,不会被chain到前面)。可以调用disableChaining()来指示该operator不参与chaining(不会与前后的operator chain一起)。可以通过调用StreamExecutionEnvironment.disableOperatorChaining()来全局禁用chaining。可以设置Slot group,例如someStream.filter(...).slotSharingGroup(“name”)。可以通过调整并行度,来调整Operator chain。
2. Slot分配与共享
2.1共享Slot
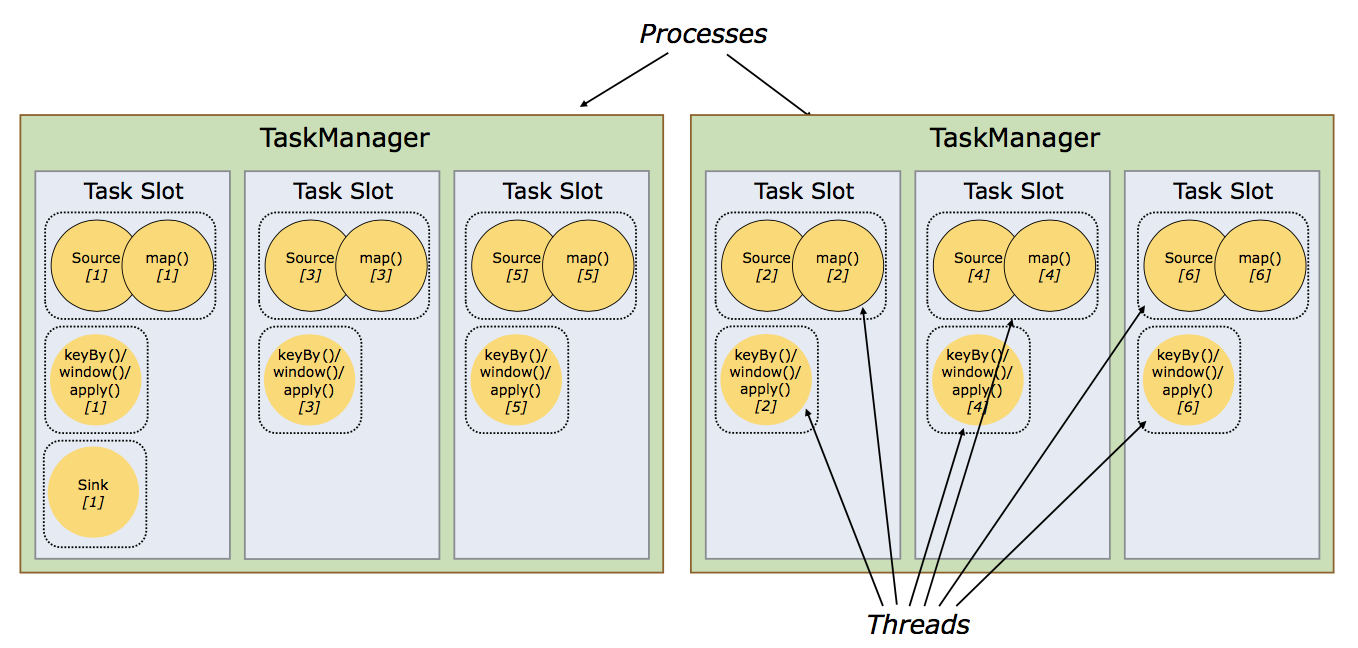
默认情况下,Flink 允许subtasks共享slot,条件是它们都来自同一个Job的不同task的subtask。结果可能一个slot持有该job的整个pipeline。
允许slot共享有以下两点好处:
1.Flink集群需要的任务槽与作业中使用的最高并行度正好相同(前提,保持默认SlotSharingGroup)。也就是说我们不需要再去计算一个程序总共会起多少个task了。
2.更容易获得更充分的资源利用。如果没有slot共享,那么非密集型操作source/flatmap就会占用同密集型操作 keyAggregation/sink 一样多的资源。如果有slot共享,将task的2个并行度增加到6个,能充分利用slot资源,同时保证每个TaskManager能平均分配到重的subtasks。
2.2共享Slot实例
将 WordCount 的并行度从之前的2个增加到6个(Source并行度仍为1),并开启slot共享(所有operator都在default共享组),将得到如上图所示的slot分布图。
首先,我们不用去计算这个job会其多少个task,总之该任务最终会占用6个slots(最高并行度为6)。其次,我们可以看到密集型操作 keyAggregation/sink 被平均地分配到各个 TaskManager。
2.3 SlotSharingGroup(soft)
SlotSharingGroup是Flink中用来实现slot共享的类,它尽可能地让subtasks共享一个slot。
保证同一个group的并行度相同的sub-tasks 共享同一个slots。算子的默认group为default(即默认一个job下的subtask都可以共享一个slot)
为了防止不合理的共享,用户也能通过API来强制指定operator的共享组,比如:someStream.filter(...).slotSharingGroup("group1");就强制指定了filter的slot共享组为group1。怎么确定一个未做SlotSharingGroup设置算子的SlotSharingGroup什么呢(根据上游算子的group 和自身是否设置group共同确定)。适当设置可以减少每个slot运行的线程数,从而整体上减少机器的负载。
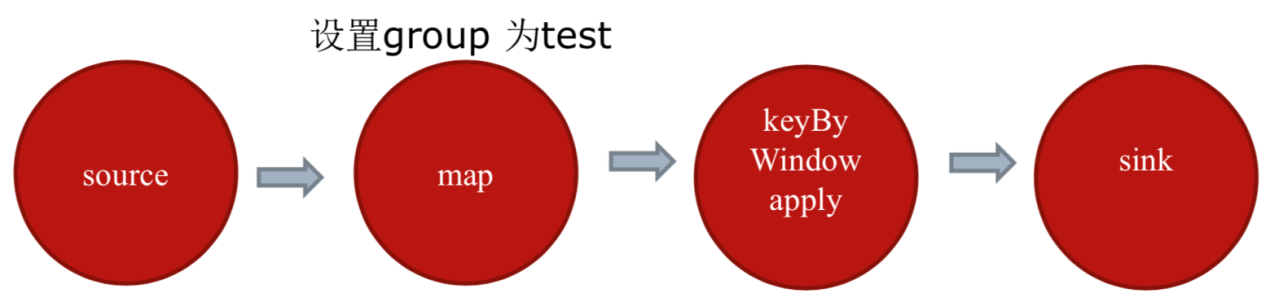
2.4 CoLocationGroup(强制)
CoLocationGroup可以保证所有的并行度相同的sub-tasks运行在同一个slot,主要用于迭代流(训练机器学习模型)。
3. Slot & parallelism的关系
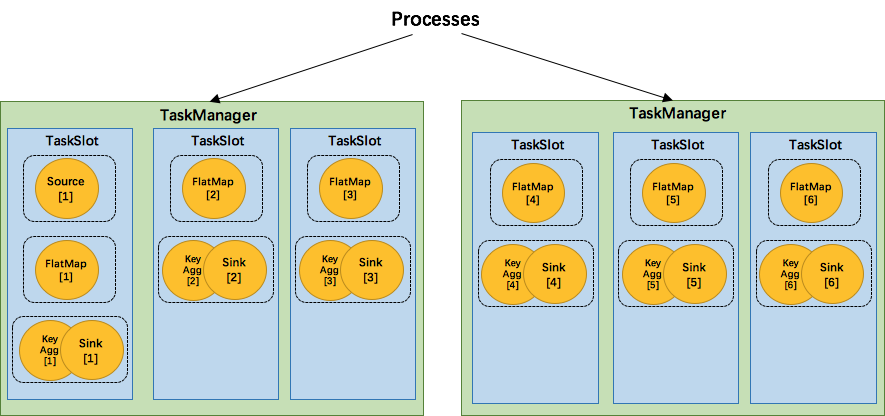
3.1 Slots && parallelism
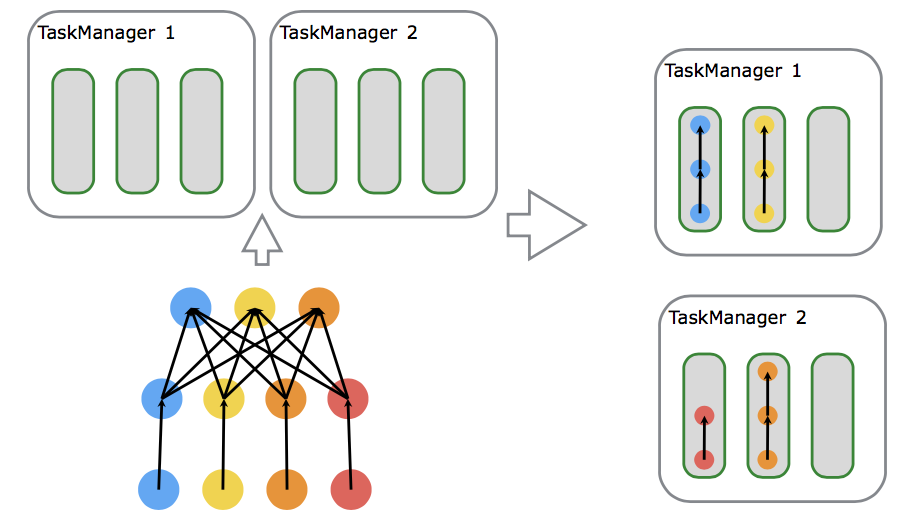
如上图所示,有两个TaskManager,每个TaskManager有3个槽位。假设source操作并行度为3,map操作的并行度为4,sink的并行度为4,所需的task slots数与job中task的最高并行度一致,最高并行度为4,那么使用的Slot也为4。
3.2如何计算Slot
如何计算一个应用需要多少slot?
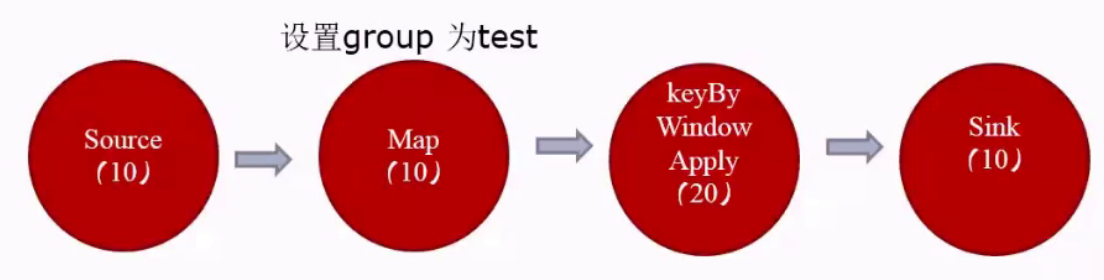
如果不设置SlotSharingGroup,那么需要的Slot数为应用的最大并行度数。如果设置了SlotSharingGroup,那么需要的Slot数为所有SlotSharingGroup中的最大并行度之和。比如已经强制指定了map的slot共享组为test,那么map和map下游的组为test,map的上游source的组为默认的default,此时default组中最大并行度为10,test组中最大并行度为20,那么需要的Slot=10+20=30。
4.Flink部署模式
4.1 Local 本地部署
Flink 可以运行在 Linux、Mac OS X 和 Windows 上。本地模式的安装唯一需要的只是 Java 1.7.x或更高版本,本地运行会启动Single JVM,主要用于测试调试代码。
4.2 Standalone Cluster集群部署
软件需求
1.安装Java1.8或者更高版本
2.集群各个节点需要ssh免密登录
Flink Standalone 运行流程前面已经讲过,这里就不在赘叙。
4.3Flink ON YARN
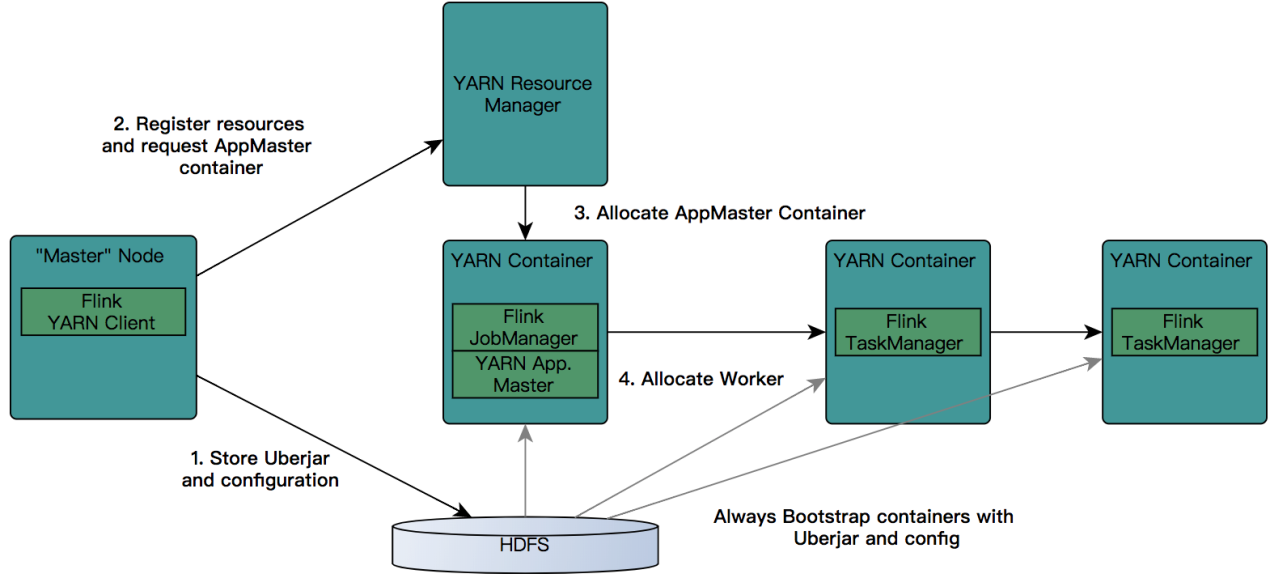
Flink ON YARN工作流程如下所示:
首先提交job给YARN,就需要有一个Flink YARN Client。
第一步:Client将Flink 应用jar包和配置文件上传到HDFS。
第二步:Client向REsourceManager注册resources和请求APPMaster Container
第三步:REsourceManager就会给某一个Worker节点分配一个Container来启动APPMaster,JobManager会在APPMaster中启动。
第四步:APPMaster为Flink的TaskManagers分配容器并启动TaskManager,TaskManager内部会划分很多个Slot,它会自动从HDFS下载jar文件和修改后的配置,然后运行相应的task。TaskManager也会与APPMaster中的JobManager进行交互,维持心跳等。
5.Flink Standalone集群部署
安装Flink之前需要提前安装好JDK,这里我们安装的是JDK1.8版本。

5.1下载
可以到官网:https://archive.apache.org/dist/flink/ 将Flink1.6.2版本下载到本地。

5.2解压
将下载的flink-1.6.2-bin-hadoop26-scala_2.11.tgz上传至主节点

使用tar -zxvf flink-1.6.2-bin-hadoop26-scala_2.11.tgz命令解压flink安装包
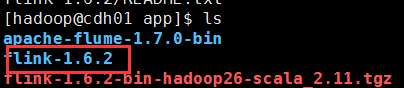
方便后期flink多版本的使用,可以创建flink软连接
ln -s flink-1.6.2 flink
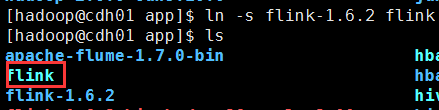
5.3配置环境变量
vi ~/.bashrc
export FLINK_HOME=/home/hadoop/app/flink
export PATH=$FLINK_HOME/bin:$PATH
使配置文件生效
source ~/.bashrc
查看flink版本
flink -v
5.4修改配置文件
1.修改flink-conf.yaml配置文件
vi flink-conf.yaml
#JobManager地址
jobmanager.rpc.address: cdh01
#槽位配置为3
taskmanager.numberOfTaskSlots: 3
#设置并行度为3
parallelism.default: 3
2.修改masters配置
vi masters
cdh01:8081
3.修改slaves配置
vi slaves
cdh01
cdh02
cdh03
5.5主节点安装目录同步到从节点
通过deploy.sh脚本将flink安装目录同步到其他节点。
deploy.sh flink-1.6.2 /home/hadoop/app/ slave
在从节点分别创建flink软连接
ln -s flink-1.6.2 flink
5.6启动服务
进入flink bin目录执行启动集群脚本start-cluster.sh
bin/start-cluster.sh
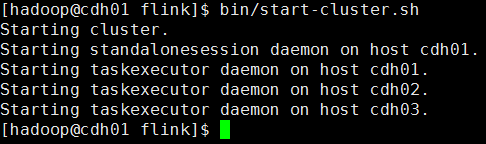
通过web查看flink集群,查看相关集群信息。
5.7测试运行
查看官网案例:https://ci.apache.org/projects/flink/flink-docs-release-1.6/
1.启动nc服务
nc -l 9000
2.提交flink作业
bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
3.输入测试数据
5.7测试运行
查看官网案例:https://ci.apache.org/projects/flink/flink-docs-release-1.6/
1.启动nc服务
nc -l 9000
2.提交flink作业
bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
3.输入测试数据
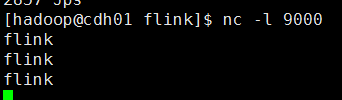
4.查看运行结果
在TaskManager界面查看Flink运行结果

(5)Flink开发环境搭建
1. 创建Flink项目及依赖管理
1.1创建Flink项目
官网创建Flink项目有两种方式:
https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/java_api_quickstart.html
方式一:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.6.2
方式二
$ curl https://flink.apache.org/q/quickstart.sh | bash -s 1.6.2
这里我们仍然使用第一种方式创建Flink项目。
打开终端,切换到对应的目录,通过maven创建flink项目
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.6.2
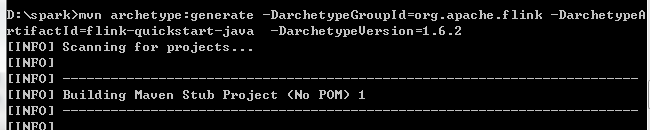
项目构建过程中需要输入groupId,artifactId,version和package
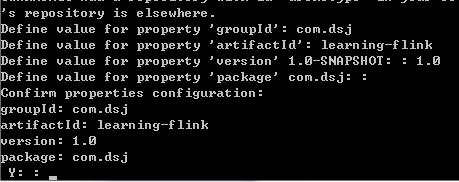
Flink项目创建成功
打开IDEA工具,点击open。

选择刚刚创建的flink项目
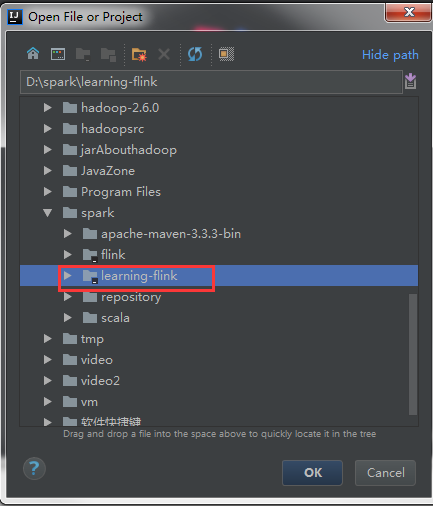
Flink项目已经成功导入IDEA开发工具
通过maven打包测试运行
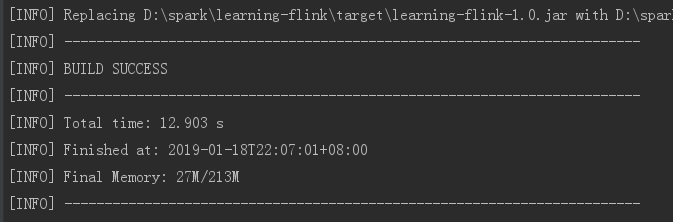
mvn clean package
刷新target目录可以看到刚刚打包的flink项目
1.2. Flink依赖
Core Dependencies(核心依赖):
1.核心依赖打包在flink-dist*.jar里
2.包含coordination, networking, checkpoints, failover, APIs, operations (such as windowing), resource management等必须的依赖
注意:核心依赖不会随着应用打包(<scope>provided</scope>)
3.核心依赖项尽可能小,并避免依赖项冲突
Pom文件中添加核心依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
注意:不会随着应用打包。
User Application Dependencies(应用依赖):
connectors, formats, or libraries(CEP, SQL, ML)、
注意:应用依赖会随着应用打包(scope保持默认值就好)
Pom文件中添加应用依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>1.6.2</version>
</dependency>
注意:应用依赖按需选择,会随着应用打包,可以通过Maven Shade插件进行打包。
1.3. 关于Scala版本
Scala各版本之间是不兼容的(你基于Scala2.12开发Flink应用就不能依赖Scala2.11的依赖包)。
只使用Java的开发人员可以选择任何Scala版本,Scala开发人员需要选择与他们的应用程序的Scala版本匹配的Scala版本。
1.4. Hadoop依赖
不要把Hadoop依赖直接添加到Flink application,而是:
export HADOOP_CLASSPATH=`hadoop classpath`
Flink组件启动时会使用该环境变量的
特殊情况:如果在Flink application中需要用到Hadoop的input-/output format,只需引入Hadoop兼容包即可(Hadoop compatibility wrappers)
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>1.6.2</version>
</dependency>
1.5 Flink项目打包
Flink 可以使用maven-shade-plugin对Flink maven项目进行打包,具体打包命令为mvn clean
package。
2. 自己编译Flink
2.1安装maven
1.下载
到maven官网下载安装包,这里我们可以选择使用apache-maven-3.3.9-bin.tar.gz。
2.解压
将apache-maven-3.3.9-bin.tar.gz安装包上传至主节点的,然后使用tar命令进行解压
tar -zxvf apache-maven-3.3.9-bin.tar.gz
3.创建软连接
ln -s apache-maven-3.3.9 maven
4.配置环境变量
vi ~/.bashrc
export MAVEN_HOME=/home/hadoop/app/maven
export PATH=$MAVEN_HOME/bin:$PATH
5.生效环境变量
source ~/.bashrc
6.查看maven版本
mvn –version
7. settings.xml配置阿里镜像
添加阿里镜像
<mirror>
<id>nexus-osc</id>
<mirrorOf>*</mirrorOf>
<name>Nexus osc</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
</mirror>
2.2安装jdk
编译flink要求jdk8或者以上版本,这里已经提前安装好jdk1.8,具体安装配置不再赘叙,查看版本如下:
[hadoop@cdh01 conf]$ java -version
java version "1.8.0_51"
Java(TM) SE Runtime Environment (build 1.8.0_51-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.51-b03, mixed mode)
2.3下载源码
登录github:https://github.com/apache/flink,获取flink下载地址:https://github.com/apache/flink.git
打开Flink主节点终端,进入/home/hadoop/opensource目录,通过git clone下载flink源码:
git clone https://github.com/apache/flink.git
错误1:如果Linux没有安装git,会报如下错误:
bash: git: command not found
解决:git安装步骤如下所示:
1.安装编译git时需要的包(注意需要在root用户下安装)
yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel
yum install gcc perl-ExtUtils-MakeMaker
2.删除已有的git
yum remove git
3.下载git源码
先安装wget
yum -y install wget
使用wget下载git源码
wget https://www.kernel.org/pub/software/scm/git/git-2.0.5.tar.gz
解压git
tar xzf git-2.0.5.tar.gz
编译安装git
cd git-2.0.5
make prefix=/usr/local/git all
sudo make prefix=/usr/local/git install
echo "export PATH=$PATH:/usr/local/git/bin" >> ~/.bashrc
source ~/.bashrc
查看git版本
git –version
错误2:git clone https://github.com/apache/flink.git
Cloning into 'flink'...
fatal: unable to access 'https://github.com/apache/flink.git/': SSL connect error
解决:
升级 nss 版本:yum update nss
2.4切换对应flink版本
使用如下命令查看flink版本分支
git tag
切换到flink对应版本(这里我们使用flink1.6.2)
git checkout release-1.6.2
2.5编译flink
进入flink 源码根目录:/home/hadoop/opensource/flink,通过maven编译flink
mvn clean install -DskipTests -Dhadoop.version=2.6.0
报错:
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 06:58 min
[INFO] Finished at: 2019-01-18T22:11:54-05:00
[INFO] Final Memory: 106M/454M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project flink-mapr-fs: Could not resolve dependencies for project org.apache.flink:flink-mapr-fs:jar:1.6.2: Could not find artifact com.mapr.hadoop:maprfs:jar:5.2.1-mapr in nexus-osc (http://maven.aliyun.com/nexus/content/repositories/central) -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :flink-mapr-fs
报错缺失flink-mapr-fs,需要手动下载安装。
解决:
1.下载maprfs jar包
通过手动下载maprfs-5.2.1-mapr.jar包,下载地址地址:https://repository.mapr.com/nexus/content/groups/mapr-public/com/mapr/hadoop/maprfs/5.2.1-mapr/
2.上传至主节点
将下载的maprfs-5.2.1-mapr.jar包上传至主节点的/home/hadoop/downloads目录下。
3.手动安装
手动安装缺少的包到本地仓库
mvn install:install-file -DgroupId=com.mapr.hadoop -DartifactId=maprfs -Dversion=5.2.1-mapr -Dpackaging=jar -Dfile=/home/hadoop/downloads/maprfs-5.2.1-mapr.jar
4.继续编译
使用maven继续编译flink(可以排除刚刚已经安装的包)
mvn clean install -Dmaven.test.skip=true -Dhadoop.version=2.7.3 -rf :flink-mapr-fs
报错:
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 05:51 min
[INFO] Finished at: 2019-01-18T22:39:20-05:00
[INFO] Final Memory: 108M/480M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.1:compile (default-compile) on project flink-mapr-fs: Compilation failure: Compilation failure:
[ERROR] /home/hadoop/opensource/flink/flink-filesystems/flink-mapr-fs/src/main/java/org/apache/flink/runtime/fs/maprfs/MapRFileSystem.java:[70,44] package org.apache.hadoop.fs does not exist
[ERROR] /home/hadoop/opensource/flink/flink-filesystems/flink-mapr-fs/src/main/java/org/apache/flink/runtime/fs/maprfs/MapRFileSystem.java:[73,45] cannot find symbol
[ERROR] symbol: class Configuration
[ERROR] location: package org.apache.hadoop.conf
[ERROR] /home/hadoop/opensource/flink/flink-filesystems/flink-mapr-fs/src/main/java/org/apache/flink/
runtime/fs/maprfs/MapRFileSystem.java:[73,93] cannot find symbol
[ERROR] symbol: class Configuration
缺失org.apache.hadoop.fs包,报错找不到。
解决:
flink-mapr-fs模块的pom文件中添加如下依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
继续往后编译:
mvn clean install -Dmaven.test.skip=true -Dhadoop.version=2.7.3 -rf :flink-mapr-fs
又报错:
[ERROR] Failed to execute goal on project flink-avro-confluent-registry: Could not resolve dependencies for project org.apache.flink:flink-avro-confluent-registry:jar:1.6.2: Could not find artifact io.confluent:kafka-schema-registry-client:jar:3.3.1 in nexus-osc (http://maven.aliyun.com/nexus/content/repositories/central) -> [Help 1]
[ERROR]
报错缺少kafka-schema-registry-client-3.3.1.jar 包
解决:
手动下载kafka-schema-registry-client-3.3.1.jar包,下载地址如下:
将下载的kafka-schema-registry-client-3.3.1.jar上传至主节点的目录下/home/hadoop/downloads
手动安装缺少的kafka-schema-registry-client-3.3.1.jar包
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=3.3.1 -Dpackaging=jar -Dfile=/home/hadoop/downloads/kafka-schema-registry-client-3.3.1.jar
继续往后编译
mvn clean install -Dmaven.test.skip=true -Dhadoop.version=2.7.3 -rf :flink-mapr-fs

(6)Flink API 通用基本概念
1. 继续侃Flink编程基本套路
1.1 DataSet and DataStream
DataSet and DataStream表示Flink app中的分布式数据集。它们包含重复的、不可变数据集。DataSet有界数据集,用在Flink批处理。DataStream可以是无界,用在Flink流处理。它们可以从数据源创建,也可以通过各种转换操作创建。
1.2共同的编程套路
DataSet and DataStream 这里以WordCount为例,共同的编程套路如下所示:
1.获取执行环境(execution environment)
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2.加载/创建初始数据集
// 读取输入数据
DataStream<String> text;
if (params.has("input")) {
// 读取text文件
text = env.readTextFile(params.get("input"));
} else {
System.out.println("Executing WordCount example with default input data set.");
System.out.println("Use --input to specify file input.");
// 读取默认测试数据集
text = env.fromElements(WordCountData.WORDS);
}
3.对数据集进行各种转换操作(生成新的数据集)
// 切分每行单词
text.flatMap(new Tokenizer())
//对每个单词分组统计词频数
.keyBy(0).sum(1);
4.指定将计算的结果放到何处去
// 输出统计结果
if (params.has("output")) {
//写入文件地址
counts.writeAsText(params.get("output"));
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
//数据打印控制台
counts.print();
}
5.触发APP执行
// 执行flink 程序
env.execute("Streaming WordCount");
1.3惰性计算
Flink APP都是延迟执行的,只有当execute()被显示调用时才会真正执行,本地执行还是在集群上执行取决于执行环境的类型。好处:用户可以根据业务构建复杂的应用,Flink可以整体进优化并生成执行计划。
2. 指定键(Specifying Keys)
2.1谁需要指定键
哪些操作需要指定key呢?常见的操作如join, coGroup, keyBy, groupBy,Reduce, GroupReduce, Aggregate, Windows等。
Flink编程模型的key是虚拟的,不需要你创建键值对,可以在具体算子通过参数指定,如下代码所示:
DataSet<...> input = // [...]
DataSet<...> reduced = input
.groupBy(/*define key here*/)
.reduceGroup(/*do something*/);
2.2为Tuple定义键
Tuple定义键的方式有很多种,接下来我们一起看几个示例:
按照指定属性分组
DataStream<Tuple3<Integer,String,Long>> input = // [...] KeyedStream<Tuple3<Integer,String,Long>,Tuple> keyed = input.keyBy(0)
注意:此时表示使用Tuple3三元组的第一个成员作为keyBy
按照组合键进行分组
DataStream<Tuple3<Integer,String,Long>> input = // [...] KeyedStream<Tuple3<Integer,String,Long>,Tuple> keyed = input.keyBy(0,1)
注意:此时表示使用Tuple3三元组的前两个元素一起作为keyBy
特殊情况:嵌套Tuple
DataStream<Tuple3<Tuple2<Integer, Float>,String,Long>> input = // [...]
KeyedStream<Tuple3<Integer,String,Long>,Tuple> keyed = input.keyBy(0)
注意:这里使用KeyBy(0)指定键,系统将会使用整个Tuple2作为键(整型和浮点型的)。如果想使用Tuple2内部字段作为键,你可以使用字段来表示键,这种方法会在后面阐述。
2.3使用字段表达式定义键
基于字符串的字段表达式可以用来引用嵌套字段(例如Tuple,POJO)
public class WC {
public String word;
public User user;
public int count;
}
public class User{
public int age;
public String zip;
}
示例:通过word字段进行分组
DataStream<WC> words = // [...]
DataStream<WC> wordCounts = words.keyBy("word").window(/*window specification*/);
语法:
1.直接使用字段名选择POJO字段
例如 user 表示 一个POJO的user字段
2.Tuple通过offset来选择
"_1"和"5"分别代表第一和第六个Scala Tuple字段
“f0” and “f5”分别代表第一和第六个Java Tuple字段
3.选择POJO和Tuples的嵌套属性
user.zip
在scala里你可以"_2.user.zip"或"user._4.1.zip”
在java里你可以“2.user.zip”或者" user.f0.1.zip ”
4.使用通配符表达式选择所有属性,java为“*”,scala为 "_"。不是POJO或者Tuple的类型也适用。
2.4字段表达式实例-Java
以下定义两个Java类:
public static class WC {
public ComplexNestedClass complex;
private int count;
public int getCount() {
return count;
}
public void setCount(int c) {
this.count = c;
}
}
public static class ComplexNestedClass {
public Integer someNumber;
public float someFloat;
public Tuple3<Long, Long, String> word;
public IntWritable hadoopCitizen;
}
我们一起看看如下key字段如何理解:
1."count": wc 类的count字段
2."complex":递归的选取ComplexNestedClass的所有字段
3."complex.word.f2": ComplexNestedClass类中的tuple word的第三个字段;
4."complex.hadoopCitizen":选择Hadoop IntWritable类型。
2.5字段表达式实例-Scala
以下定义两个Scala类:
"_1"和"5"分别代表第一和第六个Scala Tuple字段
“f0” and “f5”分别代表第一和第六个Java Tuple字段
3.选择POJO和Tuples的嵌套属性
user.zip
在scala里你可以"_2.user.zip"或"user._4.1.zip”
在java里你可以“2.user.zip”或者" user.f0.1.zip ”
4.使用通配符表达式选择所有属性,java为“*”,scala为 "_"。不是POJO或者Tuple的类型也适用。
2.4字段表达式实例-Java
以下定义两个Java类:
public static class WC {
public ComplexNestedClass complex;
private int count;
public int getCount() {
return count;
}
public void setCount(int c) {
this.count = c;
}
}
public static class ComplexNestedClass {
public Integer someNumber;
public float someFloat;
public Tuple3<Long, Long, String> word;
public IntWritable hadoopCitizen;
}
我们一起看看如下key字段如何理解:
1."count": wc 类的count字段
2."complex":递归的选取ComplexNestedClass的所有字段
3."complex.word.f2": ComplexNestedClass类中的tuple word的第三个字段;
4."complex.hadoopCitizen":选择Hadoop IntWritable类型。
2.5字段表达式实例-Scala
以下定义两个Scala类:

