记得在大学里不止一次关注网站架构方面的东西了,但每次都是泛泛了解,也没有着重记录,一段时间后对各种架构的思想也就模糊了。这几天不知怎么的又心血来潮(可能是快毕业了冲动了)想深入了解一下网站架构方面的知识,并想通过这次来总结一下网站架构,记录一点东西供自己以后翻阅,也给那些希望了解这方面知识的朋友提供一点点有用的信息,下面是我这次学习的总结笔记,有什么写得不妥的地方还请大家指出,还有希望这篇随笔能抛砖引玉,大家各抒己见。
1、MySpace架构
回顾了MySpace的成长史,真是让人惊叹,他的架构基本经历了五个里程碑,每个阶段都是显得那么仓促,那么无奈,那么坎坷,又是那么的精彩,网站为了生存只能想尽一切办法去优化系统架构,让用户满意。他给我们后人的启示是要尽早发现系统的瓶颈,设计师在设计时要有前瞻思想,否则今后有可能也要这样仓促的升级你的产品。
这里是“五个里程碑”的具体介绍。
回顾MySpace架构的坎坷之路
说起MySpace,可能很多人对他印象很深,MySpace.com成立于2003年9月,是目前全球最大的社交网站。它为全球用户提供了一个集交友、个人信息分享、即时通讯等多种功能于一体的互动平台,同时他也是.NET应用最出色的网站之一。下面我们一起来回顾一下MySpace架构的改革之路,或许我们能从中得到一点点架构方面的经验和教训。
1、50万用户
最早myspace网站由一台数据库服务器和两台Web服务器构成,此后一段时间又加了几台web服务器。但在2004年早期,用户增加到50万时一台数据库服务器就显得力不从心了。
他们设计了第一代架构,在此架构中他们运行3个SQL Server2000服务器,一个为主,所有的新数据都提交给他,然后再复制给其他两个数据库服务器。另外两台服务器用来给用户提供信息浏览,也就是只做数据读取。在一段时间内效果不错,只需要增加数据库服务器,扩大硬盘,就可以应对用户数和访问量的增加了。
2、100万-200万用户
当达到这个数字时,myspace数据库服务器遇到了I/O瓶颈,即他们存取数据的速度跟不上了。而这时据他们第一个架构只要5个月。有人花5分钟都无法完成留言,很多用户认为myspace完蛋了。
这个时候新的架构被快速提出来了,这一次他们把数据库架构按照分割模式设计,以网站功能分出多种,如登陆、现实用户资料、博客信息、等分门别类存储在不同的数据库服务器里。这种垂直分割策略利于多个数据库分担访问压力(天涯曾经就这么做过)。后来myspace从存储设备与数据库服务器直接交互的方式SAN(用高带宽和专门设计的网络将大量磁盘存储设备链接在一起,而数据库链接到SAN)。
3、300万用户
到300万用户时,这种架构开始也不行了,因为每个数据库都必须有每个用户表副本,意识是一个用户注册后,他的信息会分别存在每个数据库中,但这种做法有可能某台数据库服务器挂掉了,用户使用一些服务可能会有问题。另一个问题是比如博客信息增长太快,专门为他服务的数据库的压力过大,而其他一些功能很少被使用又在闲置。这就好像有人忙的要死,有人闲的要死。
于是他们购买了更好更贵的服务器来解决管理更大数据库的问题。但专家预测他们即使昂贵专业的服务器到最后也会不堪重负,他们必须调整架构而不是掏钱买更好的服务器。于是他们的第三代架构出现了。分布式计算架构,他们分布众多服务器,但从逻辑上看成是一台服务器。拿数据库来说,不能再按功能拆分了,看成只有一个数据库服务器。数据库模型中维护一个用户表、博客信息表、等等同看作在一个数据库服务器中。
然后他们开始把用户按每百万一组分割,每一组的用户访问指定的数据库服务器。另外一个特殊服务器保存所有用户的帐号和密码。他们的设计师说如果按照这种模式以更小粒度划分架构是可以进一步优化负荷负担的(50万用户为一组 或者更少)。
4、900万-1700万用户
myspace在这个时候把网站代码全部改为.net语言,事实证明网站跑的比以前快了很多、执行用户的请求消耗非常少的资源,后来他们把所有的程序都改成.net了。但问题到1000万时还是出来了。
用户注册量太快,按每100万分割数据库的策略不是那么完美,比如他们的第7台数据库服务器上线仅仅7天就被塞满了。主要原因是佛罗里达一个乐队的歌迷疯狂注册。而且某台数据库服务器可以在任何原因 任何时候遭遇特别大的负荷。他们的解决办法是人工把崩溃的数据库里的用户迁移走。但这不是一个好办法。
这个时候myspace购买了3PAdata设备,他的牛逼之处是真正把所有的数据库看成一个整体。他会根据情况把负荷平均分配出去,比如当用户提交一个信息,他会看哪个数据区域空闲然后分配给他,然后会在其他多处地方留有副本,不会出现一台数据库服务器崩溃,而这台数据库里的信息没有办法读取的情况,这样做看起来好极了。
另外他们增加了缓存层,以前用户查询一个信息,就请求一次数据库,现在当一个用户请求数据库后,缓存层就会保留下来一个副本,当其他用户再访问时就不需要再请求数据库了,直接请求缓存就够了。
5、2600万用户
他们把服务器更换到运行64位的服务器,这样服务器上可最多挂上32G内存,这无疑有提升了网站性能,用户感觉这个网站开始稳定快起来了。但一个新问题意外出现了。他们放数据库服务中心的洛杉矶全市停电了。这导致整个系统停止运行长达12个小时。
这时他们实现了在地理上分布多个数据中心以防止洛杉矶事件再次出现,在几个重要城市的数据中心的部署可以防止某一处出现故障,整个系统照样提供服务,如果几个地方都出现故障,那么这就意味着国家出现了重大灾难,这种几率是非常低的。
6、总结
这个架构变化升级相当有意思,架构随着用户量的提升作仓促的变化,但又恰到好处,看来MySpace又验证了一句古话“有压力才会有动力”。同时他给我们后人的启示是要尽早发现系统的瓶颈,设计师在设计时要有前瞻思想,否则今后有可能也要这样仓促的升级你的产品。
2、Flickr网站架构总结
Flickr.com 是网上最受欢迎的照片共享网站之一,还记得那位给Windows Vista拍摄壁纸的Hamad Darwish吗?他就是将照片上传到Flickr,后而被微软看中成为Vista壁纸御用摄影师。
--Pair of ServerIron's做负载均衡
--Squid做html和照片的缓存
--Memcached做数据缓存
--尤其是mysql数据库采用master-slave和shards技术实现了mysql数据库的负载均衡,解决了数据库的瓶颈,达到了数据库横向扩展的目标。
Flickr 网站架构分析
Flickr.com 是网上最受欢迎的照片共享网站之一,还记得那位给Windows Vista拍摄壁纸的Hamad Darwish吗?他就是将照片上传到Flickr,后而被微软看中成为Vista壁纸御用摄影师。
Flickr.com 是最初由位于温哥华的Ludicorp公司开发设计并于2004年2月正式发布的,由于大量应用了WEB 2.0技术,注重用户体验,使得其迅速获得了大量的用户,2007年11月,Flickr迎来了第20亿张照片,一年后,这个数字就达到了30亿,并且还在以加速度增长。 2005年3月,雅虎公司以3千500万美元收购了Ludicorp公司和Flickr.com。虽然Flickr并不是最大的照片共享网站(Facebook以超过100亿张照片排名第一),但这笔收购仍然被认为是WEB 2.0浪潮中最精明的收购,因为仅仅一年后,Google就以16亿美元的高价收购了YouTube,而2007年10月,微软斥资2.4亿美元收购 Facebook 1.6%股份,此举使Facebook估值高达150亿美元。估计Ludicorp公司的创始人Stewart Butterfield和Caterina Fake夫妇现在还在后悔吧。
在2005年温哥华PHP协会的简报以及随后的一系列会议上,Flickr的架构师Cal Henderson公开了大部分Flickr所使用的后台技术,使得我们能有机会来分享和研究其在构建可扩展Web站点的经验。本文大部分资料来自互联网和自己的一点点心得,欢迎大家参与讨论,要是能够起到抛砖引玉的作用,本人将不胜荣幸。
Flickr整体框架图

在讨论Flickr 网站架构之前,让我们先来看一组统计数据(数据来源:April 2007 MySQL Conf and Expo和Flickr网站)
- 每天多达40亿次的查询请求
- squid总计约有3500万张照片(硬盘+内存)
- squid内存中约有200万张照片
- 总计有大约4亿7000万张照片,每张图片又生成不同尺寸大小的4-5份图片
- 每秒38,000次Memcached请求 (Memcached总共存储了1200万对象)
- 超过2 PB 存储,其中数据库12TB
- 每天新增图片超过 40万(周日峰值超过200万,约1.5TB)
- 超过8百50万注册用户
- 超过1千万的唯一标签(tags)
- 响应4万个照片访问请求
- 处理10万个缓存操作
- 运行13万个数据库查询
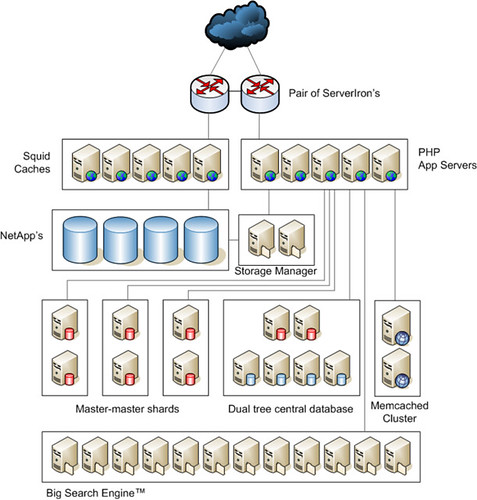
- Pair of ServerIron's做负载均衡方案
- Squid Caches 代理,用于缓存静态的HTML和照片
- Net App公司的Filer, NAS存储设备,用于存储照片
- PHP App Servers
- 运行REDHAT LINUX,Apache上的PHP应用,Flickr网站的主体是大约6万行PHP代码
- 没有使用PHP session, 应用是stateless,便于扩展,并避免PHP Server故障所带来的Session失效。
- 每个页面有大约27~35个查询(不知道为什么这么设计,个人觉得没有必要)
- 另有专门的Apache Web Farm 服务于静态文件(HTML和照片)的访问 - Storage Manager 运行私有的,适用于海量文件存储的Flickr File System
- Dual Tree Central Database
- MySQL 数据库,存放用户表,记录的信息是用户主键以及此用户对以的数据库Shard区,从中心用户表中查出用户数据所在位置,然后直接从目标Shard中取出数据。
- “Dual Tree"架构是”Master-Master"和“Master-Slave"的有效结合,双Master 避免了“单点故障”,Master-Slave又提高了读取速度,因为用户表的操作90%以上是读。 - Master-master shards
- MySQL 数据库,存储实际的用户数据和照片的元数据(Meta Data),每个Shard 大约40万个用户,120GB 数据。每个用户的所有数据存放在同一个shard中。
- Shard中的每一个server的负载只是其可最大负载的50%,这样在需要的时候可以Online停掉一半的server进行升级或维护而不影响系统性能。
- 为了避免跨Shard查询所带来的性能影响,一些数据有在不同的Shard有两份拷贝,比如用户对照片的评论,通过事务来保证其同步。 - Memcached Cluster 中间层缓存服务器,用于缓存数据库的SQL查询结果等。
- Big Search Engine
- 复制部分Shard数据(Owner’s single tag)到Search Engine Farm以响应实时的全文检索。
- 其他全文检索请求利用Yahoo的搜索引擎处理(Flickr是Yahoo旗下的公司![F]() )
) - 服务器的硬件配置:
- Intel或AMD 64位CPU,16GB RAM
- 6-disk 15K RPM RAID-10.
- 2U boxes. - 服务器数量:(数据来源:April 2008 MySQL Conference & Expo)
166 DB servers, 244 web servers(不知道是否包括 squid server?), 14 Memcached servers
 )
)数据库最初的扩展-Replication
也许有人不相信,不过Flickr确实是从一台服务器起步的,即Apache/PHP和MySQL是运行在同一台服务器上的,很快MySQL服务器就独立 了出来,成了双服务器架构。随着用户和访问量的快速增长,MySQL数据库开始承受越来越大的压力,成为应用瓶颈,导致网站应用响应速度变慢,MySQL 的扩展问题就摆在了Flickr的技术团队面前。
不幸的是,在当时,他们的选择并不多。一般来说,数据库的扩展无外是两条路,Scale-Up和Scale-Out,所谓Scale-Up,简单的说就是 在同一台机器内增加CPU,内存等硬件来增加数据库系统的处理能力,一般不需要修改应用程序;而Scale-Out,就是我们通常所说的数据库集群方式, 即通过增加运行数据库服务器的数量来提高系统整体的能力,而应用程序则一般需要进行相应的修改。在常见的商业数据库中,Oracle具有很强的 Scale-Up的能力,很早就能够支持几十个甚至数百个CPU,运行大型关键业务应用;而微软的SQL SERVER,早期受Wintel架构所限,以Scale-Out著称,但自从几年前突破了Wintel体系架构8路CPU的的限制,Scale-Up的 能力一路突飞猛进,最近更是发布了SQL 2008在Windows 2008 R2版运行256个CPU核心(core)的测试结果,开始挑战Oracle的高端市场。而MySQL,直到今年4月,在最终采纳了GOOGLE公司贡献 的SMP性能增强的代码后,发布了MySQL5.4后,才开始支持16路CPU的X86系统和64路CPU的CMT系统(基于Sun UltraSPARC 的系统)。
从另一方面来说,Scale-Up受软硬件体系的限制,不可能无限增加CPU和内存,相反Scale-Out却是可以"几乎"无限的扩展,以Google 为例,2006年Google一共有超过45万台服务器(谁能告诉我现在他们有多少?!);而且大型SMP服务器的价格远远超过普通的双路服务器,对于很 多刚刚起步或是业务增长很难预测的网站来说,不可能也没必要一次性投资购买大型的硬件设备,因而虽然Scale-Out会随着服务器数量的增多而带来管 理,部署和维护的成本急剧上升,但确是大多数大型网站当然也包括Flickr的唯一选择。
经过统计,Flickr的技术人员发现,查询即SELECT语句的数量要远远大于添加,更新和
删除的数量,比例达到了大约13:1甚至更多,所以他们采用了“Master-Slave”的复制模式,即所有的“写”操作都在发生在“Master", 然后”异步“复制到一台或多台“Slave"上,而所有的”读“操作都转到”Slave"上运行,这样随着“读”交易量的增加,只需增加Slave服务器 就可以了。 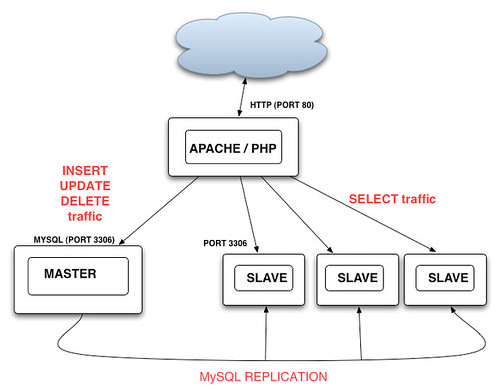
让我们来看一下应用系统应该如何修改来适应这样的架构,除了”读/写“分离外,对于”读“操作最基本的要求是:1)应用程序能够在多个”Slave“上进 行负载均分;2)当一个或多个”slave"出现故障时,应用程序能自动尝试下一个“slave”,如果全部“Slave"失效,则返回错误。 Flickr曾经考虑过的方案是在Web应用和”Slave“群之间加入一个硬件或软件的”Load Balancer“,如下图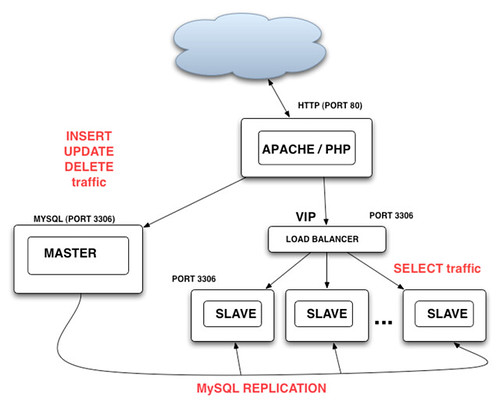
这样的好处是应用所需的改动最小,因为对于应用来说,所有的读操作都是通过一个虚拟的Slave来进行,添加和删除“Slave"服务器对应用透 明,Load Balancer 实现对各个Slave服务器状态的监控并将出现故障的Slave从可用节点列表里删除,并可以实现一些复杂的负载分担策略,比如新买的服务器处理能力要高 过Slave群中其他的老机器,那么我们可以给这个机器多分配一些负载以最有效的利用资源。一个简单的利用Apache proxy_balancer_module的例子如下:
|
1
2
3
4
5
6
7
8
9
10
11 |
。。。。。。。。。。。。。。 LoadModule proxy_module modules/mod_proxy.so LoadModule proxy_balancer_module modules/mod_proxy_balancer.so LoadModule proxy_http_module modules/mod_proxy_http.so 。。。。。。。。。。。。。。。。。。。。 <Proxy balancer://mycluster> BalancerMember "http://slave1:8008/App" loadfactor=4 BalancerMember "http://slave2:8008/App" loadfactor=3 BalancerMember "http://slave3:8008/App" loadfactor=3 .................... ///slave load ratio 4:3:3. |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14 |
function db_connect($hosts, $user, $pass){ shuffle($hosts); //shuffle()是PHP函数,作用是将数组中每个元素的顺序随机打乱。 foreach($hosts as $host){ debug("Trying to connect to $host..."); $dbh = @mysql_connect($host, $user, $pass, 1); if ($dbh){ debug("Connected to $host!"); return $dbh; } debug("Failed to connect to $host!"); } debug("Failed to connect to all hosts in list - giving up!"); return 0; } |
“Master”-"Slave"模式的缺点是它并没有对于“写'操作提供扩展能力,而且存在单点故障,即一旦Master故障,整个网站将丧失“更新” 的能力。解决的办法采用“Master"-"Master"模式,即两台服务器互为”Master“-"Slave",这样不仅”读/写“能力扩展了一 倍,而且有效避免了”单点故障“,结合已有的“Master"-"Slave",整个数据库的架构就变成了下面的”双树“结构,
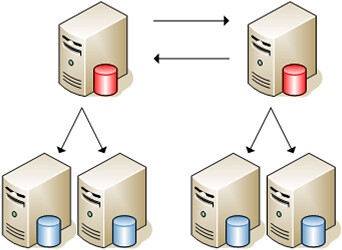 。
。“双树”架构并没有支撑太久的时间,大概6个月后,随着用户的激增,系统再一次达到了极限,不仅”写”操作成为了瓶颈,而且“异步复制"也由于 ”Slave“服务器过于繁忙而出现了严重的滞后而造成读数据的不一致。那么,能不能在现有架构加以解决,比如说增加新的”Master“服务器和考虑采 用”同步复制“呢?答案是否定的,在Master超过两台的设置中,只能采用”闭环链“的方式进行复制,在大数据量的生产环境中,很容易造成在任意时刻没 有一个Master或Slave节点是具有全部最新数据的(有点类似于”人一次也不能踏进同一条河“?),这样很难保障数据的一致性,而且一旦其中一个Master出现故障,将中断整个复制链;而对于”同步复制“,当然这是消除”复制滞后“的最好办法,不过在当时MySQL的同步复制还远没有成熟到可以运用在投产环境中。
Flickr网站的架构,需要一次大的变化来解决长期持续扩展的问题。
Shard - 大型网站数据库扩展的终极武器?
2005年7月,另一位大牛(MySQL 2005、2006年度 "Application of the Year Award"获得者)Dathan Pattishall加入了Flickr团队。一个星期之内,Dathan解决了Flickr数据库40%的问题,更重要的是,他为Flickr引进了 Shard架构,从而使Flickr网站具备了真正“线性”Scale-Out的增长能力,并一直沿用至今,取得了巨大的成功。
Shard主要是为了解决传统数据库Master/Slave模式下单一Master数据库的“写”瓶颈而出现的,简单的说Shard就是将一个大表分 割成多个小表,每个小表存储在不同机器的数据库上,从而将负载分散到多个机器并行处理而极大的提高整个系统的“写”扩展能力。相比传统方式,由于每个数据 库都相对较小,不仅读写操作更快,甚至可以将整个小数据库缓存到内存中,而且每个小数据库的备份,恢复也变得相对容易,同时由于分散了风险,单个小数据库 的故障不会影响其他的数据库,使整个系统的可靠性也得到了显著的提高。
对于大多数网站来说,以用户为单位进行Shard分割是最合适不过的,常见的分割方法有按地域(比如邮编),按Key值(比如Hash用户ID),这些 方法可以简单的通过应用配置文件或算法来实现,一般不需要另外的数据库,缺点是一旦业务增加,需要再次分割Shard时要修改现有的应用算法和重新计算所 有的Shard KEY值;而最为灵活的做法是以“目录”服务为基础的分割,即在Shard之前加一个中央数据库(Global Lookup Cluster),应用要先根据用户主键值查询中央数据库,获得用户数据所在的Shard,随后的操作再转向Shard所在数据库,例如下图:
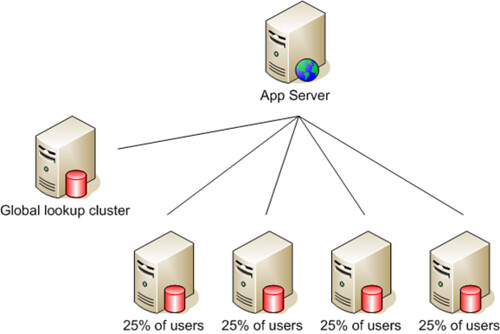
而应用的主要修改在于要添加一个Lookup访问层,例如将以下的代码:
|
1
2
3 |
string connectionString = @"Driver={MySQL};SERVER=dbserver;DATABASE=CustomerDB;"; OdbcConnection conn = new OdbcConnection(connectionString); conn.Open(); |
|
1
2
3 |
string connectionString = GetDatabaseFor(customerId); OdbcConnection conn = new OdbcConnection(connectionString); conn.Open(); |
对应我们前面所提到过的Flickr架构
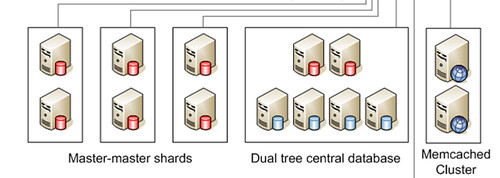
Dual Tree Central Database就是中央数据库,存放用户表,记录的信息是用户主键以及此用户对以的数据库Shard区;而Master-Master Shards就是一个个的Shard用户数据库,存储实际的用户数据和照片的元数据(Meta Data)。
Flickr Shard的设计我们在Flickr 网站架构研究(1)中已经总结过了,在此不再赘述。我们在此谈一下Shard架构的主要问题和Flickr的解决办法:1)Shard只适用于不需要 join操作的表,因为跨Shard join操作的开销太大,解决的办法是将一个用户的所有数据全部存放在同一个Shard里,对于一些传统方式下需要 跨Shard查询的数据,只能采取冗余的方法,比如Shard1的用户A对Shard2的用户B的照片进行了评论,那么这条评论将同时存放在Shard1 和Shard2中。这样就存在一个数据一致性的问题,常规的做法是用数据库事务(Transaction)、”两阶段提交“(2 phase commit)来解决,但做过两阶段提交(2PC)应用的都知道,2PC的效率相对较差,而且实际上也不能100%保证数据的完整性和一致性;另外,一旦 由于其中一个Shard故障而提交失败回滚,用户只能放弃或再试一遍,用户体验较差。Flickr对于数据一致性的解决方案是Queue(Flickr用 PHP开发了一个强大的Queue系统,将所有可以异步的任务都用Queue来实现,每天处理高达1千万以上的任务。),事实上当用户A对用户B的照片进 行评论时,他并不关心这条评论什么时候出现在用户B的界面上,即将这条评论添加到用户B的交易是可以异步的,允许一定的迟延,通过Queue处理,既保证 了数据的一致性,又缩短了用户端的相应时间,提高了系统性能。2)Shard的另一个主要问题Rebalancing,既当现有Shard的负载达到一定 的阀值,如何将现有数据再次分割,Flickr目前的方式依然是手工的,既人工来确定哪些用户需要迁移,然后运行一个后台程序进行数据迁移,迁移的过程用 户账户将被锁住。(据说Google做到了完全自动的Rebalancing,本着”萨大“坑里不再挖坑的原则,如果有机会的话,留到下一个系列再研究 吧)
Memcached的应用和争论
大家应该已经注意到,Flickr为中央数据库配置了Memcached作为数据库缓存,接下来的问题是,为什么用Memcached?为什么 Shard不需要Memcached?Memcached和Master,Slave的关系怎样?笔者将试图回答这些问题供大家参考,网上的相关争论很 多,有些问题尚未有定论。
Memecached是一个高性能的,分布式的,开源的内存对象缓存系统,顾名思义,它的主要目的是将经常读取的对象放入内存以提高整个系统,尤其是数 据库的扩展能力。Memcached的主要结构是两个Hash Table,Server端的HashTable以key-value pair的方式存放对象值,而Client端的HashTable的则决定某一对象存放在哪一个Memcached Server.举个例子说,后台有3个Memecached Server,A、B、C,Client1需要将一个对象名为”userid123456“,值为“鲁丁"的存入,经过Client1的Hash计 算,"userid123456"的值应该放入Memcached ServerB, 而这之后,Client2需要读取"userid123456"的值,经过同样的Hash计算,得出"userid123456"的值如果存在的话应该在 Memcached ServerB,并从中取出。最妙的是Server之间彼此是完全独立的,完全不知道对方的存在,没有一个类似与Master或Admin Server的存在,增加和减少Server只需在Client端"注册"并重新Hash就可以了。
Memcached作为数据库缓存的作用主要在于减轻甚至消除高负载数据库情况下频繁读取所带来的Disk I/O瓶颈,相对于数据库自身的缓存来说,具有以下优点:1)Memecached的缓存是分布式的,而数据库的缓存只限于本机;2)Memcached 缓存的是对象,可以是经过复杂运算和查询的最终结果,并且不限于数据,可以是任何小于1MB的对象,比如html文件等;而数据库缓存是以"row"为单 位的,一旦"row"中的任何数据更新,整个“row"将进行可能是对应用来说不必要的更新;3)Memcached的存取是轻量的,而数据库的则相对较 重,在低负载的情况下,一对一的比较,Memcached的性能未必能超过数据库,而在高负载的情况下则优势明显。
Memcached并不适用于更新频繁的数据,因为频繁更新的数据导致大量的Memcached更新和较低的缓冲命中率,这可能也是为什么Shard没 有集成它的原因;Memcached更多的是扩展了数据库的”读“操作,这一点上它和Slave的作用有重叠,以至于有人争论说应该 让"Relication"回到它最初的目的”Online Backup"数据库上,而通过Memcached来提供数据库的“读”扩展。(当然也有人说,考虑到Memcached的对应用带来的复杂性,还是慎 用。)
然而,在体系架构中增加Memecached并不是没有代价的,现有的应用要做适当的修改来同步Memcached和数据库中的数据,同时Memcached不提供任何冗余和“failover”功能,这些复杂的控制都需要应用来实现。基本的应用逻辑如下:
对于读操作:
|
1
2
3
4
5 |
$data = memcached_fetch( $id ); return $data if $data$data = db_fetch( $id ); memcached_store( $id, $data ); return $data; |
|
1
2 |
db_store( $id, $data ); memcached_store( $id, $data ); |
复制滞后和同步问题的解决
我们知道复制滞后的主要原因是数据库负载过大而造成异步复制的延迟,Shard架构有效的分散了系统负载,从而大大减轻了这一现象,但是并不能从根本上消除,解决这一问题还是要靠良好的应用设计。
当用户访问并更新Shard数据时,Flickr采用了将用户“粘”到某一机器的做法,
$id = intval(substr($user_id, -10));
$id % $count_of_hosts_in_shard
即同一用户每次登录的所有操作其实都是在Shard中的一个Master上运行的,这样即使复制到Slave,也就是另一台Master的时候有延时,也不会对用户有影响,除非是用户刚刚更新,尚未复制而这台Master就出现故障了,不过这种几率应该很小吧。
对于Central Database的复制滞后和同步问题,Flickr采用了一种复杂的“Write Through Cache"的机制来处理:
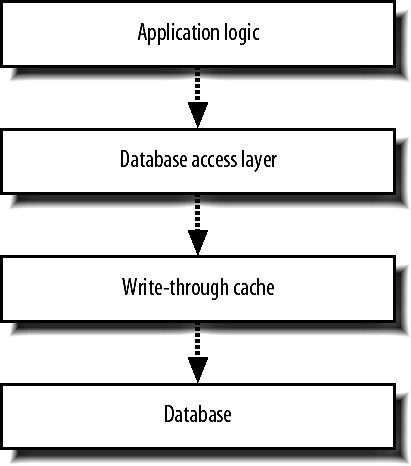
"Write Through Cache"就是将所有的数据库”写“操作都先写入”Cache",然后由Cache统一去更新数据库的各个Node,“Write Through Cache"维护每一个Node的更新状态,当有读请求时,即将请求转向状态为”已同步“的Node,这样即避免了复制滞后和Memcached的同步问 题,但缺点是其实现极为复杂,“Write Throug Cache"层的代码需要考虑和实现所有”journal","Transaction“,“failover”,和“recovery"这些数据库已经 实现的功能,另外还要考虑自身的"failover"问题。我没有找到有关具体实现的说明,只能猜测这一部分的处理可能也是直接利用或是实现了类似于 Flickr的Queue系统吧。
3、YouTube架构总结
这个貌似在国内是被和谐的,要fan qiang才能访问(不知到底何故)。看看他的架构:--NetScaler用于负载均衡和静态内容缓存
--使用lighttpd作为Web服务器来提供视频服务
--CDN在多个地方备份内容,这样内容离用户更近的机会就会更高
--使用Google的BigTable,一个分布式数据存储、数据库分成shards,不同的用户指定到不同的shards、使用BigTable将图片备份到不同的数据中心,代码查看谁是最近的
YouTube架构学习
- 博客分类:
- Architecture
YouTube发展迅速,每天超过1亿的视频点击量,但只有很少人在维护站点和确保伸缩性。
平台
Apache
Python
Linux(SuSe)
MySQL
psyco,一个动态的Python到C的编译器
lighttpd代替Apache做视频查看
状态
支持每天超过1亿的视频点击量
成立于2005年2月
于2006年3月达到每天3千万的视频点击量
于2006年7月达到每天1亿的视频点击量
2个系统管理员,2个伸缩性软件架构师
2个软件开发工程师,2个网络工程师,1个DBA
处理飞速增长的流量

- while (true)
- {
- identify_and_fix_bottlenecks();
- drink();
- sleep();
- notice_new_bottleneck();
- }
每天运行该循环多次
Web服务器
1,NetScaler用于负载均衡和静态内容缓存
2,使用mod_fast_cgi运行Apache
3,使用一个Python应用服务器来处理请求的路由
4,应用服务器与多个数据库和其他信息源交互来获取数据和格式化html页面
5,一般可以通过添加更多的机器来在Web层提高伸缩性
6,Python的Web层代码通常不是性能瓶颈,大部分时间阻塞在RPC
7,Python允许快速而灵活的开发和部署
8,通常每个页面服务少于100毫秒的时间
9,使用psyco(一个类似于JIT编译器的动态的Python到C的编译器)来优化内部循环
10,对于像加密等密集型CPU活动,使用C扩展
11,对于一些开销昂贵的块使用预先生成并缓存的html
12,数据库里使用行级缓存
13,缓存完整的Python对象
14,有些数据被计算出来并发送给各个程序,所以这些值缓存在本地内存中。这是个使用不当的策略。应用服务器里最快的缓存将预先计算的值发送给所有服务器也花不了多少时间。只需弄一个代理来监听更改,预计算,然后发送。
视频服务
1,花费包括带宽,硬件和能源消耗
2,每个视频由一个迷你集群来host,每个视频被超过一台机器持有
3,使用一个集群意味着:
-更多的硬盘来持有内容意味着更快的速度
-failover。如果一台机器出故障了,另外的机器可以继续服务
-在线备份
4,使用lighttpd作为Web服务器来提供视频服务:
-Apache开销太大
-使用epoll来等待多个fds
-从单进程配置转变为多进程配置来处理更多的连接
5,大部分流行的内容移到CDN:
-CDN在多个地方备份内容,这样内容离用户更近的机会就会更高
-CDN机器经常内存不足,因为内容太流行以致很少有内容进出内存的颠簸
6,不太流行的内容(每天1-20浏览次数)在许多colo站点使用YouTube服务器
-长尾效应。一个视频可以有多个播放,但是许多视频正在播放。随机硬盘块被访问
-在这种情况下缓存不会很好,所以花钱在更多的缓存上可能没太大意义。
-调节RAID控制并注意其他低级问题
-调节每台机器上的内存,不要太多也不要太少
视频服务关键点
1,保持简单和廉价
2,保持简单网络路径,在内容和用户间不要有太多设备
3,使用常用硬件,昂贵的硬件很难找到帮助文档
4,使用简单而常见的工具,使用构建在Linux里或之上的大部分工具
5,很好的处理随机查找(SATA,tweaks)
缩略图服务
1,做到高效令人惊奇的难
2,每个视频大概4张缩略图,所以缩略图比视频多很多
3,缩略图仅仅host在几个机器上
4,持有一些小东西所遇到的问题:
-OS级别的大量的硬盘查找和inode和页面缓存问题
-单目录文件限制,特别是Ext3,后来移到多分层的结构。内核2.6的最近改进可能让Ext3允许大目录,但在一个文件系统里存储大量文件不是个好主意
-每秒大量的请求,因为Web页面可能在页面上显示60个缩略图
-在这种高负载下Apache表现的非常糟糕
-在Apache前端使用squid,这种方式工作了一段时间,但是由于负载继续增加而以失败告终。它让每秒300个请求变为20个
-尝试使用lighttpd但是由于使用单线程它陷于困境。遇到多进程的问题,因为它们各自保持自己单独的缓存
-如此多的图片以致一台新机器只能接管24小时
-重启机器需要6-10小时来缓存
5,为了解决所有这些问题YouTube开始使用Google的BigTable,一个分布式数据存储:
-避免小文件问题,因为它将文件收集到一起
-快,错误容忍
-更低的延迟,因为它使用分布式多级缓存,该缓存与多个不同collocation站点工作
-更多信息参考Google Architecture,GoogleTalk Architecture和BigTable
数据库
1,早期
-使用MySQL来存储元数据,如用户,tags和描述
-使用一整个10硬盘的RAID 10来存储数据
-依赖于信用卡所以YouTube租用硬件
-YouTube经过一个常见的革命:单服务器,然后单master和多read slaves,然后数据库分区,然后sharding方式
-痛苦与备份延迟。master数据库是多线程的并且运行在一个大机器上所以它可以处理许多工作,slaves是单线程的并且通常运行在小一些的服务器上并且备份是异步的,所以slaves会远远落后于master
-更新引起缓存失效,硬盘的慢I/O导致慢备份
-使用备份架构需要花费大量的money来获得增加的写性能
-YouTube的一个解决方案是通过把数据分成两个集群来将传输分出优先次序:一个视频查看池和一个一般的集群
2,后期
-数据库分区
-分成shards,不同的用户指定到不同的shards
-扩散读写
-更好的缓存位置意味着更少的IO
-导致硬件减少30%
-备份延迟降低到0
-现在可以任意提升数据库的伸缩性
数据中心策略
1,依赖于信用卡,所以最初只能使用受管主机提供商
2,受管主机提供商不能提供伸缩性,不能控制硬件或使用良好的网络协议
3,YouTube改为使用colocation arrangement。现在YouTube可以自定义所有东西并且协定自己的契约
4,使用5到6个数据中心加CDN
5,视频来自任意的数据中心,不是最近的匹配或其他什么。如果一个视频足够流行则移到CDN
6,依赖于视频带宽而不是真正的延迟。可以来自任何colo
7,图片延迟很严重,特别是当一个页面有60张图片时
8,使用BigTable将图片备份到不同的数据中心,代码查看谁是最近的
学到的东西
1,Stall for time。创造性和风险性的技巧让你在短期内解决问题而同时你会发现长期的解决方案
2,Proioritize。找出你的服务中核心的东西并对你的资源分出优先级别
3,Pick your battles。别怕将你的核心服务分出去。YouTube使用CDN来分布它们最流行的内容。创建自己的网络将花费太多时间和太多money
4,Keep it simple!简单允许你更快的重新架构来回应问题
5,Shard。Sharding帮助隔离存储,CPU,内存和IO,不仅仅是获得更多的写性能
6,Constant iteration on bottlenecks:
-软件:DB,缓存
-OS:硬盘I/O
-硬件:内存,RAID
7,You succeed as a team。拥有一个跨越条律的了解整个系统并知道系统内部是什么样的团队,如安装打印机,安装机器,安装网络等等的人。With a good team all things are possible。
4、PlentyOfFish架构总结
这个我觉的最神奇了,一个人每天花2个小时,可以维护一个每天3000W PV的,而且是基于.NET的(呵呵,终于给我们.net程序员一个好榜样了)。简述他的架构:
--用Microsoft Windows操作系统作为服务器
--使用ASP.NET技术
--使用IIS作为Web容器
--用Akamai CDN来缓存网页
--用Foundry ServerIron 来做负载均衡
--sqlserver采用master-slave架构,两台负责read操作,master那台负责写操作
--所有的request数据都使用了gzip压缩
PlentyOfFish.com .NET网站的又一传奇
PlentyOfFish(以下简称POF)是一家在美国广受欢迎的婚介交友网站,平均每月有4千5百万的访问者,每天有3千万的访问量(这是前一段时间的数据了),但你万万想不到的是,这个被估值$1000000000的网站却只有一个人每天只干两小时活。
POF对网友是100%免费的,所有的收入来自于Google广告点击,不像中国有的婚介交友网站广告纷乱,POF只有一个广告通栏,此外没有任何弹出广告,感觉非常的简洁。 它的成功的关键因素可能就是在基本功能方面能很符合用户的需要,在UE方面做的也比较贴心,同时也让用户能够坦然接受这个免费网站的UI的丑陋和服务的不稳定性,而更为愿意通过这个平台来发布一些内容,share一些个人图片,通过这个网站来找靓妞或者帅哥dating了。
我们先暂且不谈他在用户体验上是如何胜出的,光是系统架构上就值得我们好好体味一下了,毕竟一个人花那么少点时间就可以维护如此庞大的系统,由此可见其架构是如此的简单、灵活、高效。那我们就简单来分析他的架构吧。
- 用Microsoft Windows操作系统作为服务器
该网站采用的是Windows x64 Server 2003。采用Windows的原因是并不是站长认为Windows适合POF,而是因为站长本人建站时候的技术很差,完全不会使用Linux和 Unix。他办这个网站的初衷其实是学习ASP。也因为如此,整个网站的标准就是简单、简单、再简单。对于大流量负载均衡的处理,站长目前没有使用 Windows 的负载均衡Network Load Balancing (NLB),他认为NLB不能保持sessions状态。对于不能保持sessions状态,倒也可以存储session状态到数据库,或者共享文件系统。8-12个NLB服务器可以共同放入一个farm,而且farm的数量也是没有限制的。然后将一个 DNS轮转调度策略(round-robin scheme)用在farm之间。其实这样的架构,也曾经一度被用在POF——总计70个前端Web服务器(front end web servers),可以支持30万人的并发访问。NLB也是一个不错的选择。但是这样的软件解决方案显得有点贵,而且很麻烦,最终站长选择了硬件来完成负载均衡任务。 - 使用ASP.NET技术
ASP.NET中的缓存功能完全没有启用。因为该网站的动态特性,往往还没等缓存储存,数据就已经改变或消失了。另外,该站点也没有用ASP.NET开发什么组件,所有的组件都是现成的,一切都以简单出发。 - 使用IIS作为Web容器
由于IIS限制了最大64000的连接数,所以POF不得不添加负载均衡器来处理为数众多的并发连接。站长曾经考虑过添加第二IP,并采用轮转调度(Round-Robin)来解决访问量过大的问题,但是这样太过复杂,有悖于一个人的简单管理,最后被放弃了。其实用多个Web服务器就可以简单解决。 - 用Akamai CDN来缓存网页
该站点部署了Akamai CDN(网页缓存加速),每天处理大约1亿幅图片的缓存加速。CDN的原理是将你站点部分的内容,分发到CDN服务商的服务器上,因为CDN服务商广泛分布的服务器可以更加接近最终用户的地域,这样速度就会更快。假如你当前的POF页面有8幅图片,每幅图片的下载需要100毫秒,那么光下载这些图片就需要花上一秒钟。所以分配这些图片到离用户更近的区域是非常必要的,而且CDN也一定程度缓解了不同网络服务商之间的线路差异。当然,也不是所有的图片都采用了CDN,一些小于2KB的图片还是缓存于本地内存。可能因为部署了CDN,POF虽然是国外网站,但速度却非常快,与国内网站无二。有关CDN技术,可以参考http://baike.baidu.com/view/21895.htm - 用Foundry ServerIron 来做负载均衡
POF采用了网捷网络公司的Web交换器ServerIron,ServerIron 能够有效地处理超过 16,000,000个并发连接,而且能够改善服务器负载均衡和缓冲转换。正如上文所述,最终站长放弃了NLB而采用了ServerIron 负载均衡,经过详细计算之后,他发现部署ServerIron要比NLB便宜。其实也不只是POF,很多大网站都采用ServerIron来处理TCP 连接pooling和bot自动监察。ServerIron除了负载均衡还能做很多事情,因此还是值得的考虑的。 - 数据库优化
3台SQL Server,采用master-slave架构,两台负责read操作,master那台负责写操作。这个和myspace早期的后台数据库架构是一样,看来这种架构很流行嘛。POF 有一个主要的数据库,两个搜索数据库。监测使用任务管理器来完成。过去,有些问题会将数据库堵塞,其实这都是数据库自己的问题,好在POF没用.net的 library,找出问题相对容易一些。不过假如你使用了framework的很多层级,找出问题就可能很困难了。对于POF而言,数据库不仅仅是不出问题,还需要稳定和快速。由于POF网站的动态特性,基本用不到缓存,所以站长几年来花了很大功夫,在很多细节上优化了数据库,让数据库的相应更加迅速。 - Memory和CPU
把最近常使用的图片直接放在内存中,所以内存会那么大;CPU配置也挺好,gzip是相当耗费CPU计算的。Markus说他碰到问题基本上是IO操作方面的瓶颈,很少是被.Net block住。Markus在Session,Farm,以及数据库反范式等很多方面都有很不错的经验,很值得我们学习和借鉴,更多的细节大家可以参考后面的链接的几篇文章。
- 压缩
所有的request数据都使用了gzip压缩,大概耗费了30%的CPU,但是降低了带宽成本。欧美的带宽不便宜。
中国的经济环境持续向好,所以很多公司的IT部门都得到了更多的预算,但这些预算被合理的使用了吗?这些预算往往被用来采购更好的服务器硬件,更新的操作系统和数据库软件,还有各式各样的行业应用。倒不是说这些部署不好,只是说我们的IT部署一定要以实用为出发点,少做一些可有可无的投资。我们要多向 POF学习,其实稳定、快速、便捷才是制胜的关键。正如POF站长一再强调的简单哲学,所有复杂的东西都尽量不去使用。
虽然站长一开始的技术一般,但是随着建站时间的加长,他现在也已经是一个网站架构专家,他花了很多力气来优化数据库和维护系统,而且他也采用了CDN来加快不同地域的用户访问网站空间。不过其实该网站的搭建可以更加合理,比如可以采用S3来外包其图片存储,采用更轻质化的操作系统或者Web服务器等等。这些年来,类似于这样的建议非常多,但是站长还是坚持了他的简单策略,而且也拒绝对主页面进行美工优化,因为他认为多余的工作只会引来他人反感,实用才是关键。可见,保持简单性,和持续勤劳的维护是服务器运行良好的法宝。
相信我们可以从POF上学习的东西还有很多,毕竟该网站以一己之力,达到了史无前例的高度,净利润竟然逼近了500多人的大型IT网站。POF的成功必然有它的深刻理由,不仅是网站的整体的服务器和软件架构、很多细节的处理也同样值得我们借鉴。
5、WikiPedia架构总结
维基百科(Wikipedia)是一个基于Wiki技术的全球性多语言百科全书协作计划,同时也是一部在网际网路上呈现的网路百科全书,其目标及宗旨是为全人类提供自由的百科全书──用他们所选择的语言来书写而成的,是一个动态的、可自由和的全球知识体。
使用MediaWiki软件
--
网址: http://www.dbanotes.net/opensource/wikipedia_arch.html
维基百科(WikiPedia.org)位列世界十大网站,目前排名第八位。这是开放的力量。
来点直接的数据:
- 峰值每秒钟3万个 HTTP 请求
- 每秒钟 3Gbit 流量, 近乎375MB
- 350 台 PC 服务器(数据来源)
架构示意图如下: Copy @Mark Bergsma
Copy @Mark Bergsma
GeoDNS
在我写的这些网站架构的 Blog 中,GeoDNS 第一次出现,这东西是啥? "A 40-line patch for BIND to add geographical filters support to the existent views in BIND", 把用户带到最近的服务器。GeoDNS 在 WikiPedia 架构中担当重任当然是由 WikiPedia 的内容性质决定的--面向各个国家,各个地域。
负载均衡:LVS
WikiPedia 用 LVS 做负载均衡, 是章文嵩博士发起的项目,也算中国人为数不多的在开源领域的骄傲啦。LVS 维护的一个老问题就是监控了,维基百科的技术人员用的是 pybal.
图片服务器:Lighttpd
Lighttpd 现在成了准标准图片服务器配置了。不多说。
Wiki 软件: MediaWiki
对 MediaWiki 的应用层优化细化得快到极致了。用开销相对比较小的方法定位代码热点,参见实时性能报告,瓶颈在哪里,看这样的图树展示一目了然。另外一个十分值得重视的经验是,尽可能抛弃复杂的算法、代价昂贵的查询,以及可能带来过度开销的 MediaWiki 特性。Cache! Cache! Cache!
维基百科网站成功的第一关键要素就是 Cache 了。CDN(其实也算是 Cache) 做内容分发到不同的大洲、Squid 作为反向代理. 数据库 Cache 用 Memcached,30 台,每台 2G 。对所有可能的数据尽可能的Cache,但他们也提醒了 Cache 的开销并非永远都是最小的,尽可能使用,但不能过度使用。
数据库: MySQL
MediaWiki 用的DB 是 MySQL. MySQL 在 Web 2.0 技术上的常见的一些扩展方案他们也在使用。 复制、读写分离......应用在 DB 上的负载均衡通过 LoadBalancer.php 来做到的,可以给我们一个很好的参考。
运营这样的站点,WikiPedia 每年的开支是 200 万美元,技术人员只有 6 个,惊人的高效。
各大网站架构总结笔记(续)
前段时间给大家介绍过各大网站架构总结笔记(MySpace、Flickr、YouTube、PlentyOfFish、WikiPedia),喜欢架构的朋友可以去看看。这两天,我又陆续从互联网上整理了几个优秀网站的架构信息,并将部分文章整理到了自己的另一个博客,今天把它们拿出来分享给大家,希望能给大家带来一点启发,另外,欢迎一起讨论,有比较好的架构信息大家也可以拿出来一起分享一下:)
1、Google架构
老大当然要放第一位,Google的架构非我们这些平凡之辈一两天能够了解的,这里也只是大概地整理一下:
--GFS,Google的强有力的面向大规模数据密集型应用的、可伸缩的分布式文件系统
--MapReduce,Google的分布式并行计算系统,GFS存储数据,而MapReduce则是以最快最可靠的方式处理数据。
--BigTable,Google基于GFS和MapReduce之上的用来存储结构化数据的解决方案,有了它,不仅可以存储结构化的数据,而且可以更好的管理和做出负载均衡决策。
毕业生浅谈Google架构
首先声明:
1、我并非是网站架构师,我刚毕业,只是对网站架构这方面比较感兴趣,于是就把自己学习的心得和大家分享,欢迎大家拍砖,但请稍微拍轻点,毕竟刚毕业的孩子伤不起啊:-)
2、如果喜欢本文的朋友可以以任何形式转载,开心的话留个链接,不开心就算了,因为文中很多资料也是来自网络的。
其实不久前我在园子里也分享过一篇有关架构方面的文章各大网站架构总结笔记,感谢大家的点评和支持,让我在大家的讨论中又学到了很多东西。今天,我要和大家一起来谈谈Google的架构,鉴于Google的高不可测和本人的能力有限,所以只能浅谈,园子里牛的人可以在评论中补充哦(好东西拿出来一起分享,让我们共同进步,不要让人家嘲笑我们中国的程序员封闭)。
Google主要以GFS、MapReduce、BigTable这三大平台来支撑其庞大的业务系统,我称他们为Google三剑客,网上也有说是Google的三架马车。
一、GFS(Google File System)
这是Google独特的一个面向大规模数据密集型应用的、可伸缩的分布式文件系统,由于这个文件系统是通过软件调度来实现的,所以Google可以把GFS部署在很多廉价的PC机上,来达到用昂贵服务器一样的效果。
下面是一张Google GFS的架构图:

从上图我们可看到Google的GFS主要由一个master和很多chunkserver组成,master主要是负责维护系统中的名字空间、访问控制信息、从文件到块的映射以及块的当前位置等元素据,并通过心跳信号与chunkserver通信,搜集并保存chunkserver的状态信息。chunkserver主要是用来存储数据块,google把每个数据块的大小设计成64M,至于为什么这么大后面会提到,每个chunk是由master分配的chunk-handle来标识的,为了提高系统的可靠性,每个chunk会被复制3个副本放到不同的chunkserver中。
当然这样的单master设计也会带来单点故障问题和性能瓶颈问题,Google是通过减少client与master的交互来解决的,client均是直接与chunkserver通信,master仅仅提供查询数据块所在的chunkserver以及详细位置。下面是在GFS上查询的一般流程:
1、client使用固定的块大小将应用程序指定的文件名和字节偏移转换成文件的一个块索引(chunk index)。
2、给master发送一个包含文件名和块索引的请求。
3、master回应对应的chunk handle和副本的位置(多个副本)。
4、client以文件名和块索引为键缓存这些信息。(handle和副本的位置)。
5、Client 向其中一个副本发送一个请求,很可能是最近的一个副本。请求指定了chunk handle(chunkserver以chunk handle标识chunk)和块内的一个字节区间。
6、除非缓存的信息不再有效(cache for a limited time)或文件被重新打开,否则以后对同一个块的读操作不再需要client和master间的交互。
不过我还是有疑问,google可以通过减少client与master通信来解决性能瓶颈问题,但单点问题呢,一台master挂掉岂不是完蛋了,总感觉不太放心,可能是我了解不够透彻,不知道哪位朋友能解释一下,谢谢:)
二、MapReduce,Google的分布式并行计算系统
如果上面的GFS解决了Google的海量数据的存储,那这个MapReduce则是解决了如何从这些海量数据中快速计算并获取指定数据的问题。我们知道,Google的每一次搜索都在零点零几秒,能在这么短时间里环游世界一周,这里MapReduce有很大的功劳。
Map即映射,Reduce即规约,由master服务器把map和reduce任务分发到各自worker服务器中运行计算,最后把结果规约合并后返回给用户。这个过程可以由下图来说明。

按照自己的理解,简单对上图加点说明:
1、首先把用户请求的数据文件切割成多份,每一份(即每一个split)被拷贝在集群中不同机器上,然后由集群启动程序中的多份拷贝。
2、master把map和reduce任务交给相对空闲的worker处理,并阻塞等待处理结果。
3、处理map任务的worker接到任务后,把以key/value形式的输入数据传递给map函数进行处理,并将处理结果也以key/value的形式输出,并保存在内存中。
4、上一步内存中的结果是要进行reduce的,于是这些map worker就把这些数据的位置返回给master,这样master知道数据位置就可以继续分配reduce任务,起到了连接map和reduce函数的作用。
5、reduce worker知道这些数据的位置后就去相应位置读取这些数据,并对这些数据按key进行排序。将排序后的数据序列放入reduce函数中进行合并和规约,最后每个reduce任务输出一个结果文件。
6、任务结束,master解除阻塞,唤醒用户。
以上是个人的一些理解,有不对的地方请指出。
三、BigTable,分布式的结构化数据存储系统?
BigTable是基于GFS和MapReduce之上的,那么google既然已经有了GFS,为何还要有BigTable呢(也是我原先的一个疑问)?后来想想这和已经有操作系统文件系统为何还要有SQL SERVER数据库一样的道理,GFS是更底层的文件系统,而BigTable建立在其上面,不仅可以存储结构化的数据,而且可以更好的管理和做出负载均衡决策。
以下是BigTable的架构图:

它完全是一个基于key/value的数据库,和一般的关系型数据库不同,google之所以采用BigTable,因为它在满足需求的同时简化了系统,比如去掉了事务、死锁检测等模块,让系统更高效。更重要的一点是在BigTable中数据是没有格式的,它仅仅是一个个key/value的pairs,用户可以自己去定义数据的格式,这也大大提高了BigTable的灵活性和扩展性。
四、总结
这篇随笔主要是一些总结性的内容,Google架构远远不止这些,不过对于我这个初学者来说,看到这样的架构体系确实让我很激动(可能牛的朋友对这个已经没啥感觉了),就花了差不多一个下午写了这篇文章。我也希望通过自己的努力去更深一步的学习架构方面的知识,也欢迎各位朋友一起探讨。好了,最后我还是希望得到大家的支持,但也欢迎拍砖,不过拍轻点哦,呵呵。
2、优酷网架构
在国内,上不了YouTube,只能看看优酷了,说实在优酷在国内算是做的不错了,视频加载速度明显比土豆什么的要快,那就看看他的架构吧:
--自建的一个模块化的CMS系统,前端十分灵活
--mysql数据库从单台MySQL服务器(Just Running)到简单的MySQL主从复制、SSD优化、垂直分库、水平sharding分库,解决数据库服务器的灵活横向扩展。
--为了避免内存拷贝和内存锁,没有(很少)用内容缓存。
--最核心的是构建了比较完善的CDN网络,就近原则,让你看视频时从离你最近的服务器上获取视频信息,所以我们看优酷比土豆要快,原因就在这里。
优酷网架构学习笔记
记得以前给大家介绍过视频网站龙头老大YouTube的技术架构,相信大家看了都会有不少的感触,互联网就是这么一个神奇的东西。今天我突然想到,优酷网在国内也算是视频网站的老大了,不知道他的架构相对于YouTube是怎么样的,于是带着这个好奇心去网上找了优酷网架构的各方面资料,虽然谈得没有YouTube那么详细,但多少还是挖掘了一点,现在总结一下,希望对喜欢架构的朋友有所帮助。
一、网站基本数据概览
- 据2010年统计,优酷网日均独立访问人数(uv)达到了8900万,日均访问量(pv)更是达到了17亿,优酷凭借这一数据成为google榜单中国内视频网站排名最高的厂商。
- 硬件方面,优酷网引进的戴尔服务器主要以 PowerEdge 1950与PowerEdge 860为主,存储阵列以戴尔MD1000为主,2007的数据表明,优酷网已有1000多台服务器遍布在全国各大省市,现在应该更多了吧。
二、网站前端框架
从一开始,优酷网就自建了一套CMS来解决前端的页面显示,各个模块之间分离得比较恰当,前端可扩展性很好,UI的分离,让开发与维护变得十分简单和灵活,下图是优酷前端的模块调用关系:

这样,就根据module、method及params来确定调用相对独立的模块,显得非常简洁。下面附一张优酷的前端局部架构图:

三、数据库架构
应该说优酷的数据库架构也是经历了许多波折,从一开始的单台MySQL服务器(Just Running)到简单的MySQL主从复制、SSD优化、垂直分库、水平sharding分库,这一系列过程只有经历过才会有更深的体会吧,就像MySpace的架构经历一样,架构也是一步步慢慢成长和成熟的。
1、简单的MySQL主从复制:
MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能,其原来图如下:

其主从复制的过程如下图所示:

但是,主从复制也带来其他一系列性能瓶颈问题:
- 写入无法扩展
- 写入无法缓存
- 复制延时
- 锁表率上升
- 表变大,缓存率下降
那问题产生总得解决的,这就产生下面的优化方案,一起来看看。
2、MySQL垂直分区
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:

然而,尽管业务之间已经足够独立了,但是有些业务之间或多或少总会有点联系,如用户,基本上都会和每个业务相关联,况且这种分区方式,也不能解决单张表数据量暴涨的问题,因此为何不试试水平sharding呢?
3、MySQL水平分片(Sharding)
这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:

如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示:

但是,优酷是如何解决跨shard的查询呢,这个是个难点,据介绍优酷是尽量不跨shard查询,实在不行通过多维分片索引、分布式搜索引擎,下策是分布式数据库查询(这个非常麻烦而且耗性能)
四、缓存策略
貌似大的系统都对“缓存”情有独钟,从http缓存到memcached内存数据缓存,但优酷表示没有用内存缓存,理由如下:
- 避免内存拷贝,避免内存锁
- 如接到老大哥通知要把某个视频撤下来,如果在缓存里是比较麻烦的
而且Squid 的 write() 用户进程空间有消耗,Lighttpd 1.5 的 AIO(异步I/O) 读取文件到用户内存导致效率也比较低下。
但为何我们访问优酷会如此流畅,与土豆相比优酷的视频加载速度略胜一筹?这个要归功于优酷建立的比较完善的内容分发网络(CDN),它通过多种方式保证分布在全国各地的用户进行就近访问——用户点击视频请求后,优酷网将根据用户所处地区位置,将离用户最近、服务状况最好的视频服务器地址传送给用户,从而保证用户可以得到快速的视频体验。这就是CDN带来的优势,就近访问,有关CDN的更多内容,请大家Google一下。
3、Twitter架构
twitter,怎么说呢,说他简单么还真简单,但又是那么复杂,真是纠结。话说这140个字的鼻祖让国内的某某某非常风骚,算了不跑题了,说说他的架构吧:
--平台比较广泛:
- Ruby on Rails:web应用程序的框架
- Erlang:通用的面向并发的编程语言,开源项目地址:http://www.erlang.org/
- AWStats:实时日志分析系统:开源项目地址:http://awstats.sourceforge.net/
- Memcached:分布式内存缓存组建
- Starling:Ruby开发的轻量级消息队列
- Varnish:高性能开源HTTP加速器
- Kestrel:scala编写的消息中间件,开源项目地址:http://github.com/robey/kestrel
- Comet Server:Comet是一种ajax长连接技术,利用Comet可以实现服务器主动向web浏览器推送数据,从而避免客户端的轮询带来的性能损失。
- libmemcached:一个memcached客户端
- 使用mysql数据库服务器
- Mongrel:Ruby的http服务器,专门应用于rails,开源项目地址:http://rubyforge.org/projects/mongrel/
- Munin:服务端监控程序,项目地址:http://munin-monitoring.org/
- Nagios:网络监控系统,项目地址:http://www.nagios.org/
--细化memcached,同时建立向量缓存Vector Cache、行缓存Row Cache、碎片缓存Fragmeng Cache、缓存池Page Cache
--给力的消息队列,用Ruby写的一个分布式队列 Starling
Twitter网站架构学习笔记
作为140个字的缔造者,twitter太简单了,又太复杂了,简单是因为仅仅用140个字居然使有几次世界性事件的传播速度超过任何媒体,复杂是因为要为2亿用户提供这看似简单的140个字的服务,这真的是因为简单,所以复杂。可是比较遗憾的是目前在中国大陆twitter是无法访问的,但作为一个爱好架构的程序猿,这道墙是必须得翻的,墙外的世界更精彩。今天就结合网络上的一些资料,来浅谈一下我对twitter网站架构的学习体会,希望给路过的朋友一点启示.......
一、twitter网站基本情况概览
- 截至2011年4月,twitter的注册用户约为1.75亿,并以每天300000的新用户注册数增长,但是其真正的活跃用户远远小于这个数目,大部分注册用户都是没有关注者或没有关注别人的,这也是与facebook的6亿活跃用户不能相提并论的。
- twitter每月有180万独立访问用户数,并且75%的流量来自twitter.com以外的网站。每天通过API有30亿次请求,每天平均产生5500次tweet,37%活跃用户为手机用户,约60%的tweet来自第三方的应用。
- 平台:Ruby on Rails 、Erlang 、MySQL 、Mongrel 、Munin 、Nagios 、Google Analytics 、AWStats 、Memcached
下图是twitter的整体架构设计图:

二、twitter的平台
twitter平台大致由twitter.com、手机以及第三方应用构成,如下图所示:

其中流量主要以手机和第三方为主要来源。
- Ruby on Rails:web应用程序的框架
- Erlang:通用的面向并发的编程语言,开源项目地址:http://www.erlang.org/
- AWStats:实时日志分析系统:开源项目地址:http://awstats.sourceforge.net/
- Memcached:分布式内存缓存组建
- Starling:Ruby开发的轻量级消息队列
- Varnish:高性能开源HTTP加速器
- Kestrel:scala编写的消息中间件,开源项目地址:http://github.com/robey/kestrel
- Comet Server:Comet是一种ajax长连接技术,利用Comet可以实现服务器主动向web浏览器推送数据,从而避免客户端的轮询带来的性能损失。
- libmemcached:一个memcached客户端
- 使用mysql数据库服务器
- Mongrel:Ruby的http服务器,专门应用于rails,开源项目地址:http://rubyforge.org/projects/mongrel/
- Munin:服务端监控程序,项目地址:http://munin-monitoring.org/
- Nagios:网络监控系统,项目地址:http://www.nagios.org/
三、缓存
讲着讲着就又说到缓存了,确实,缓存在大型web项目中起到了举足轻重的作用,毕竟数据越靠近CPU存取速度越快。下图是twitter的缓存架构图:

大量使用memcached作缓存
- 例如,如果获得一个count非常慢,你可以将count在1毫秒内扔入memcached
- 获取朋友的状态是很复杂的,这有安全等其他问题,所以朋友的状态更新后扔在缓存里而不是做一个查询。不会接触到数据库
- ActiveRecord对象很大所以没有被缓存。Twitter将critical的属性存储在一个哈希里并且当访问时迟加载
- 90%的请求为API请求。所以在前端不做任何page和fragment缓存。页面非常时间敏感所以效率不高,但Twitter缓存了API请求
在memcached缓存策略中,又有所改进,如下所述:
1、创建一个直写式向量缓存Vector Cache,包含了一个tweet ID的数组,tweet ID是序列化的64位整数,命中率是99%
2、加入一个直写式行缓存Row Cache,它包含了数据库记录:用户和tweets。这一缓存有着95%的命中率。
3、引入了一个直读式的碎片缓存Fragmeng Cache,它包含了通过API客户端访问到的sweets序列化版本,这些sweets可以被打包成json、xml或者Atom格式,同样也有着95%的命中率。
4、为页面缓存创建一个单独的缓存池Page Cache。该页面缓存池使用了一个分代的键模式,而不是直接的实效。
四、消息队列
- 大量使用消息。生产者生产消息并放入队列,然后分发给消费者。Twitter主要的功能是作为不同形式(SMS,Web,IM等等)之间的消息桥
- 使用DRb,这意味着分布式Ruby。有一个库允许你通过TCP/IP从远程Ruby对象发送和接收消息,但是它有点脆弱
- 移到Rinda,它是使用tuplespace模型的一个分享队列,但是队列是持久的,当失败时消息会丢失
- 尝试了Erlang
- 移到Starling,用Ruby写的一个分布式队列
- 分布式队列通过将它们写入硬盘用来挽救系统崩溃。其他大型网站也使用这种简单的方式
4、Yupoo网站架构
一个试图做国内最好的图片服务提供商,虽然和Flickr还有点差距,但也不错了,话说搞图片和视频的是很烧服务器和带宽的,在国内这么贵的带宽也挺不容易的,好了,一起看看他的架构吧:
--Squid,这个貌似做图片缓存挺好使的,而且还是分布式的,可以硬盘命中和内存命中,速度都还不错。
--
Yupoo网站架构学习总结
之前向大家介绍过全球最大在线图片服务网站Flickr网站架构,Yupoo(又拍网)作为国内最大的图片服务提供商,我们也一起来看看它的架构,同样是提供图片服务,看看他与Flickr的差别在哪里,大家看完本文可以思考一下。
一、先来看看Yupoo网站的基本信息:

二、关于 Squid 与 Tomcat
Squid 与 Tomcat 似乎在 Web 2.0 站点的架构中较少看到。我首先是对 Squid 有点疑问,对此阿华的解释是"目前暂时还没找到效率比 Squid 高的缓存系统,原来命中率的确很差,后来在 Squid 前又装了层 Lighttpd, 基于 url 做 hash, 同一个图片始终会到同一台 squid 去,所以命中率彻底提高了"
对于应用服务器层的 Tomcat,现在 Yupoo! 技术人员也在逐渐用其他轻量级的东西替代,而 YPWS/YPFS 现在已经用 Python 进行开发了。
名次解释:
- YPWS--Yupoo Web Server YPWS 是用 Python开发的一个小型 Web 服务器,提供基本的 Web 服务外,可以增加针对用户、图片、外链网站显示的逻辑判断,可以安装于任何有空闲资源的服务器中,遇到性能瓶颈时方便横向扩展。
- YPFS--Yupoo File System 与 YPWS 类似,YPFS 也是基于这个 Web 服务器上开发的图片上传服务器。
【Updated: 有网友留言质疑 Python 的效率,Yupoo 老大刘平阳在 del.icio.us 上写到 "YPWS用Python自己写的,每台机器每秒可以处理294个请求, 现在压力几乎都在10%以下"】
三、图片处理层
接下来的 Image Process Server 负责处理用户上传的图片。使用的软件包也是 ImageMagick,在上次存储升级的同时,对于锐化的比率也调整过了(我个人感觉,效果的确好了很多)。”Magickd“ 是图像处理的一个远程接口服务,可以安装在任何有空闲 CPU资源的机器上,类似 Memcached的服务方式。
我们知道 Flickr 的缩略图功能原来是用 ImageMagick 软件包的,后来被雅虎收购后出于版权原因而不用了(?);EXIF 与 IPTC Flicke 是用 Perl 抽取的,我是非常建议 Yupoo! 针对 EXIF 做些文章,这也是潜在产生受益的一个重点。
四、图片存储层
原来 Yupoo! 的存储采用了磁盘阵列柜,基于 NFS 方式的,随着数据量的增大,”Yupoo! 开发部从07年6月份就开始着手研究一套大容量的、能满足 Yupoo! 今后发展需要的、安全可靠的存储系统“,看来 Yupoo! 系统比较有信心,也是满怀期待的,毕竟这要支撑以 TB 计算的海量图片的存储和管理。我们知道,一张图片除了原图外,还有不同尺寸的,这些图片统一存储在 MogileFS 中。
对于其他部分,常见的 Web 2.0 网站必须软件都能看到,如 MySQL、Memcached 、Lighttpd 等。Yupoo! 一方面采用不少相对比较成熟的开源软件,一方面也在自行开发定制适合自己的架构组件。这也是一个 Web 2.0 公司所必需要走的一个途径。
五、分库设计
和很多使用MySQL的2.0站点一样,又拍网的MySQL集群经历了从最初的一个主库一个从库、到一个主库多个从库、 然后到多个主库多个从库的一个发展过程。

图3:数据库的进化过程
最初是由一台主库和一台从库组成,当时从库只用作备份和容灾,当主库出现故障时,从库就手动变成主库,一般情况下,从库不作读写操作(同步除外)。随着压力的增加,我们加上了memcached,当时只用其缓存单行数据。 但是,单行数据的缓存并不能很好地解决压力问题,因为单行数据的查询通常很快。所以我们把一些实时性要求不高的Query放到从库去执行。后面又通过添加多个从库来分流查询压力,不过随着数据量的增加,主库的写压力也越来越大。
在参考了一些相关产品和其它网站的做法后,我们决定进行数据库拆分。也就是将数据存放到不同的数据库服务器中,一般可以按两个纬度来拆分数据:
垂直拆分:是指按功能模块拆分,比如可以将群组相关表和照片相关表存放在不同的数据库中,这种方式多个数据库之间的表结构不同。
水平拆分:而水平拆分是将同一个表的数据进行分块保存到不同的数据库中,这些数据库中的表结构完全相同。
拆分方式
一般都会先进行垂直拆分,因为这种方式拆分方式实现起来比较简单,根据表名访问不同的数据库就可以了。但是垂直拆分方式并不能彻底解决所有压力问题,另外,也要看应用类型是否合适这种拆分方式。如果合适的话,也能很好的起到分散数据库压力的作用。比如对于豆瓣我觉得比较适合采用垂直拆分, 因为豆瓣的各核心业务/模块(书籍、电影、音乐)相对独立,数据的增加速度也比较平稳。不同的是,又拍网的核心业务对象是用户上传的照片,而照片数据的增加速度随着用户量的增加越来越快。压力基本上都在照片表上,显然垂直拆分并不能从根本上解决我们的问题,所以,我们采用水平拆分的方式。
拆分规则
水平拆分实现起来相对复杂,我们要先确定一个拆分规则,也就是按什么条件将数据进行切分。 一般2.0网站都以用户为中心,数据基本都跟随用户,比如用户的照片、朋友和评论等等。因此一个比较自然的选择是根据用户来切分。每个用户都对应一个数据库,访问某个用户的数据时, 我们要先确定他/她所对应的数据库,然后连接到该数据库进行实际的数据读写。
那么,怎么样对应用户和数据库呢?我们有这些选择:
按算法对应
最简单的算法是按用户ID的奇偶性来对应,将奇数ID的用户对应到数据库A,而偶数ID的用户则对应到数据库B。这个方法的最大问题是,只能分成两个库。另一个算法是按用户ID所在区间对应,比如ID在0-10000之间的用户对应到数据库A, ID在10000-20000这个范围的对应到数据库B,以此类推。按算法分实现起来比较方便,也比较高效,但是不能满足后续的伸缩性要求,如果需要增加数据库节点,必需调整算法或移动很大的数据集, 比较难做到在不停止服务的前提下进行扩充数据库节点。
按索引/映射表对应
这种方法是指建立一个索引表,保存每个用户的ID和数据库ID的对应关系,每次读写用户数据时先从这个表获取对应数据库。新用户注册后,在所有可用的数据库中随机挑选一个为其建立索引。这种方法比较灵活,有很好的伸缩性。一个缺点是增加了一次数据库访问,所以性能上没有按算法对应好。
比较之后,我们采用的是索引表的方式,我们愿意为其灵活性损失一些性能,更何况我们还有memcached, 因为索引数据基本不会改变的缘故,缓存命中率非常高。所以能很大程度上减少了性能损失。

图4:数据访问过程
索引表的方式能够比较方便地添加数据库节点,在增加节点时,只要将其添加到可用数据库列表里即可。 当然如果需要平衡各个节点的压力的话,还是需要进行数据的迁移,但是这个时候的迁移是少量的,可以逐步进行。要迁移用户A的数据,首先要将其状态置为迁移数据中,这个状态的用户不能进行写操作,并在页面上进行提示。 然后将用户A的数据全部复制到新增加的节点上后,更新映射表,然后将用户A的状态置为正常,最后将原来对应的数据库上的数据删除。这个过程通常会在临晨进行,所以,所以很少会有用户碰到迁移数据中的情况。
当然,有些数据是不属于某个用户的,比如系统消息、配置等等,我们把这些数据保存在一个全局库中。
问题
分库会给你在应用的开发和部署上都带来很多麻烦。
不能执行跨库的关联查询
如果我们需要查询的数据分布于不同的数据库,我们没办法通过JOIN的方式查询获得。比如要获得好友的最新照片,你不能保证所有好友的数据都在同一个数据库里。一个解决办法是通过多次查询,再进行聚合的方式。我们需要尽量避免类似的需求。有些需求可以通过保存多份数据来解决,比如User-A和 User-B的数据库分别是DB-1和DB-2, 当User-A评论了User-B的照片时,我们会同时在DB-1和DB-2中保存这条评论信息,我们首先在DB-2中的photo_comments表中插入一条新的记录,然后在DB-1中的user_comments表中插入一条新的记录。这两个表的结构如下图所示。这样我们可以通过查询 photo_comments表得到User-B的某张照片的所有评论, 也可以通过查询user_comments表获得User-A的所有评论。另外可以考虑使用全文检索工具来解决某些需求, 我们使用Solr来提供全站标签检索和照片搜索服务。

图5:评论表结构
不能保证数据的一致/完整性
跨库的数据没有外键约束,也没有事务保证。比如上面的评论照片的例子, 很可能出现成功插入photo_comments表,但是插入user_comments表时却出错了。一个办法是在两个库上都开启事务,然后先插入 photo_comments,再插入user_comments, 然后提交两个事务。这个办法也不能完全保证这个操作的原子性。
所有查询必须提供数据库线索
比如要查看一张照片,仅凭一个照片ID是不够的,还必须提供上传这张照片的用户的ID(也就是数据库线索),才能找到它实际的存放位置。因此,我们必须重新设计很多URL地址,而有些老的地址我们又必须保证其仍然有效。我们把照片地址改成/photos/{username}/{photo_id} /的形式,然后对于系统升级前上传的照片ID, 我们又增加一张映射表,保存photo_id和user_id的对应关系。当访问老的照片地址时,我们通过查询这张表获得用户信息, 然后再重定向到新的地址。
自增ID
如果要在节点数据库上使用自增字段,那么我们就不能保证全局唯一。这倒不是很严重的问题,但是当节点之间的数据发生关系时,就会使得问题变得比较麻烦。我们可以再来看看上面提到的评论的例子。如果photo_comments表中的comment_id的自增字段,当我们在DB- 2.photo_comments表插入新的评论时, 得到一个新的comment_id,假如值为101,而User-A的ID为1,那么我们还需要在DB-1.user_comments表中插入(1, 101 ...)。 User-A是个很活跃的用户,他又评论了User-C的照片,而User-C的数据库是DB-3。 很巧的是这条新评论的ID也是101,这种情况很用可能发生。那么我们又在DB-1.user_comments表中插入一行像这样(1, 101 ...)的数据。 那么我们要怎么设置user_comments表的主键呢(标识一行数据)?可以不设啊,不幸的是有的时候(框架、缓存等原因)必需设置。那么可以以 user_id、 comment_id和photo_id为组合主键,但是photo_id也有可能一样(的确很巧)。看来只能再加上photo_owner_id了, 但是这个结果又让我们实在有点无法接受,太复杂的组合键在写入时会带来一定的性能影响,这样的自然键看起来也很不自然。所以,我们放弃了在节点上使用自增字段,想办法让这些ID变成全局唯一。为此增加了一个专门用来生成ID的数据库,这个库中的表结构都很简单,只有一个自增字段id。 当我们要插入新的评论时,我们先在ID库的photo_comments表里插入一条空的记录,以获得一个唯一的评论ID。 当然这些逻辑都已经封装在我们的框架里了,对于开发人员是透明的。 为什么不用其它方案呢,比如一些支持incr操作的Key-Value数据库。我们还是比较放心把数据放在MySQL里。 另外,我们会定期清理ID库的数据,以保证获取新ID的效率。
实现
我们称前面提到的一个数据库节点为Shard,一个Shard由两个台物理服务器组成, 我们称它们为Node-A和Node-B,Node-A和Node-B之间是配置成Master-Master相互复制的。 虽然是Master-Master的部署方式,但是同一时间我们还是只使用其中一个,原因是复制的延迟问题, 当然在Web应用里,我们可以在用户会话里放置一个A或B来保证同一用户一次会话里只访问一个数据库, 这样可以避免一些延迟问题。但是我们的Python任务是没有任何状态的,不能保证和PHP应用读写相同的数据库。那么为什么不配置成Master- Slave呢?我们觉得只用一台太浪费了,所以我们在每台服务器上都创建多个逻辑数据库。 如下图所示,在Node-A和Node-B上我们都建立了shard_001和shard_002两个逻辑数据库, Node-A上的shard_001和Node-B上的shard_001组成一个Shard,而同一时间只有一个逻辑数据库处于Active状态。 这个时候如果需要访问Shard-001的数据时,我们连接的是Node-A上的shard_001, 而访问Shard-002的数据则是连接Node-B上的shard_002。以这种交叉的方式将压力分散到每台物理服务器上。 以Master-Master方式部署的另一个好处是,我们可以不停止服务的情况下进行表结构升级, 升级前先停止复制,升级Inactive的库,然后升级应用,再将已经升级好的数据库切换成Active状态, 原来的Active数据库切换成Inactive状态,然后升级它的表结构,最后恢复复制。 当然这个步骤不一定适合所有升级过程,如果表结构的更改会导致数据复制失败,那么还是需要停止服务再升级的。

图6:数据库布局
前面提到过添加服务器时,为了保证负载的平衡,我们需要迁移一部分数据到新的服务器上。为了避免短期内迁移的必要,我们在实际部署的时候,每台机器上部署了8个逻辑数据库, 添加服务器后,我们只要将这些逻辑数据库迁移到新服务器就可以了。最好是每次添加一倍的服务器, 然后将每台的1/2逻辑数据迁移到一台新服务器上,这样能很好的平衡负载。当然,最后到了每台上只有一个逻辑库时,迁移就无法避免了,不过那应该是比较久远的事情了。
我们把分库逻辑都封装在我们的PHP框架里了,开发人员基本上不需要被这些繁琐的事情困扰。下面是使用我们的框架进行照片数据的读写的一些例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 |
<?php $Photos = new ShardedDBTable("Photos", "yp_photos", "user_id", array( "photo_id" => array("type" => "long", "primary" => true, "global_auto_increment" => true), "user_id" => array("type" => "long"), "title" => array("type" => "string"), "posted_date" => array("type" => "date"), )); $photo = $Photos->new_object(array("user_id" => 1, "title" => "Workforme")); $photo->insert(); // 加载ID为10001的照片,注意第一个参数为用户ID $photo = $Photos->load(1, 10001); // 更改照片属性 $photo->title = "Database Sharding"; $photo->update(); // 删除照片 $photo->delete(); // 获取ID为1的用户在2010-06-01之后上传的照片 $photos = $Photos->fetch(array("user_id" => 1, "posted_date__gt" => "2010-06-01")); ?> |
如果我们要访问全局库中的数据,我们需要定义一个DBTable对象。
|
1
2
3
4
5
6 |
<?php $Users = new DBTable("Users", "yp_users", array( "user_id" => array("type" => "long", "primary" => true, "auto_increment" => true), "username" => array("type" => "string"), )); ?> |
六、缓存
我们的框架提供了缓存功能,对开发人员是透明的。
|
1
2
3 |
<?php $photo = $Photos->load(1, 10001); ?> |
|
1
2
3 |
<?php $photos = $Photos->fetch(array("user_id" => 1, "posted_date__gt" => "2010-06-01")); ?> |
revision信息也是存放在缓存里的,Key为Photos-revision。这样做看起来不错,但是好像列表缓存的利用率不会太高。因为我们是以整个数据类型的revision为缓存Key的后缀,显然这个revision更新的非常频繁,任何一个用户修改或上传了照片都会导致它的更新,哪怕那个用户根本不在我们要查询的Shard里。要隔离用户的动作对其他用户的影响,我们可以通过缩小revision的作用范围来达到这个目的。 所以revision的缓存Key变成Photos-{shard_key}-revision,这样的话当ID为1的用户修改了他的照片信息时, 只会更新Photos-1-revision这个Key所对应的revision。
因为全局库没有shard_key,所以修改了全局库中的表的一行数据,还是会导致整个表的缓存失效。 但是大部分情况下,数据都是有区域范围的,比如我们的帮助论坛的主题帖子, 帖子属于主题。修改了其中一个主题的一个帖子,没必要使所有主题的帖子缓存都失效。 所以我们在DBTable上增加了一个叫isolate_key的属性。
|
1
2
3
4
5
6
7
8
9
10
11 |
<?php $GLOBALS["Posts"] = new DBTable("Posts", "yp_posts", array( "topic_id" => array("type" => "long", "primary" => true), "post_id" => array("type" => "long", "primary" => true, "auto_increment" => true), "author_id" => array("type" => "long"), "content" => array("type" => "string"), "posted_at" => array("type" => "datetime"), "modified_at" => array("type" => "datetime"), "modified_by" => array("type" => "long"), ), "topic_id"); ?> |
ShardedDBTable继承自DBTable,所以也可以指定isolate_key。 ShardedDBTable指定了isolate_key的话,能够更大幅度缩小revision的作用范围。 比如相册和照片的关联表yp_album_photos,当用户往他的其中一个相册里添加了新的照片时, 会导致其它相册的照片列表缓存也失效。如果我指定这张表的isolate_key为album_id的话, 我们就把这种影响限制在了本相册内。
我们的缓存分为两级,第一级只是一个PHP数组,有效范围是Request。而第二级是memcached。这么做的原因是,很多数据在一个 Request周期内需要加载多次,这样可以减少memcached的网络请求。另外我们的框架也会尽可能的发送memcached的gets命令来获取数据, 从而减少网络请求。
全球商品品种最多的网上零售商和全球第2大互联网公司,貌似很风光嘛,那架构一定很犀利的,下面一起来看看:
--平台,Linux、oracle、C++、Perl、Mason、Java、Jboss、Servlets
--Dynamo Key-Value存储架构,有关Dynamo的更多信息请参看:http://baike.baidu.com/view/2982765.html?fromTaglist
好了,先就介绍这几个,有空再找几个看看,说实在看架构比看阿凡达刺激,多看看有益身心健康。
最后欢迎大家有空逛逛我的青藤屋,玩blog没人气太没意思了。。。大家晚安了!
Amazon网站架构学习总结
谁也没想到,之前一个小小的网上书店,现在居然成了全球商品品种最多的网上零售商和全球第2大互联网公司,它叫Amazon。相信很多朋友都知道Amazon,那就不多作介绍了,下面我们主要来探讨一下Amazon的网站架构方面的话题,其实和之前介绍的facebook架构、myspace架构等等大同小异。另外,本文很多内容也是来自互联网,如有侵权方面的内容请留言,我会及时处理。
一、平台以及状态
Linux、oracle、C++、Perl、Mason、Java、Jboss、Servlets
--超过5500万活动顾客帐号
--世界范围内超过100万活动零售合作商
--构建一个页面所需访问的服务介于100至150个之间
二、架构概述
l 我们说的可伸缩性到底意味着什么?对于一个服务来说,当我们增加为其分配的系统资源之后,它的性能增长能够与投入的资源按比例提升,我们就说这个服务具有可伸缩性。通常意义上的性能提升,意味着能够提供更多的服务单元,也可以为更大的工作单元提供服务,比如增长的数据集等。
l Amazon的架构经历了巨大的变化,从一开始时的两层架构,转向了分布式的、去中心化的服务平台,提供许多种不同的应用。
l 最开始只有一个应用来和后端交互,是用C++来完成的。
l 架构会随着时间而演进。多年来,Amazon将增容的主要精力放在后端的数据库上,试图让其容纳更多的商品数据,更多的客户数据,更多的订单数据,并让其支持多个国际站点。到2001年,前端应用很明显不能再做任何增容方面的努力了。数据库被分为很多个小部分,围绕每个部分会创建一个服务接口,并且该接口是访问数据的唯一途径。
l 数据库逐渐演变成共享资源,这样就很难再在全部业务的基础之上进行增容操作了。前端与后端处理的演进受到很大限制,因为他们被太多不同的团队和流程所共享了。
l 他们的架构是松散耦合的的,并且围绕着服务进行构建。面向服务的架构提供给他们的隔离特性,让他们能够快速、独立地完成许多软件组件的开发。
l 逐渐地,Amazon拥有了数百个服务,并有若干应用服务器,从服务中聚合信息。生成Amazon.com站点页面的应用就位于这样的一台应用服务器之上。提供web服务接口、顾客服务应用以及卖家接口的应用也都是类似的情况。
l 许多第三方的技术难以适用Amazon这种网站的规模,特别是通讯基础架构技术。它们在一定范围内工作的很好,但是如果范围再扩大的话,它们就不适用了。因此,Amazon只好自己开发相应的基础技术。
l 不在一种技术上"吊死"。Amazon在有的地方使用jboss/java,不过只是使用servlets,并没有完全使用j2ee中所涉及到的技术。
l C++开发的程序被用来处理请求。Perl/Mason开发的程序用来生成页面中的内容。
l Amazon不喜欢采用中间件技术,因为它看起来更像一种框架而不是一个工具。如果采用了某种中间件,那么就会被那种中间件所采用的软件模式所困扰。你也就只能选用他们的软件。如果你想采用不同的软件几乎是不可能的。你被困住了!经常发生的情况就是消息中间件,数据持久层中间件,Ajax等等。它们都太复杂了。如果中间件能够以更小的组件的方式提供,更像一个工具而不是框架,或许对我们的吸引力会更大一些。
l SOAP 相关的web解决方案看起来想再次解决所有分布式系统的问题。
l Amazon提供SOAP和REST这两种Web 服务。大概有30%的用户采用SOAP这种Web Services。他们看起来似乎是Java和.NET的用户,而且使用WSDL来生成远程对象接口。大概有70%的用户使用REST。他们看起来似乎是 PHP和PERL的用户。
l 无论采用SOAP还是REST,开发人员都可以得到访问Amazon的对象接口。开发人员想要的是把工作完成,而不需要关心网线上传输的是什么东西。
l Amazon想要围绕他们的服务构建一个开放的社区。他们之所以选择Web Services是因为它的简单。事实上它是一个面向服务的体系架构。简单来说,你只有通过接口才能访问到需要的数据,这些接口是用WSDL描述的,不过它们采用自己的封装和传输机制。
l 架构开发团队都是小规模团队,而且都是围绕不同的服务进行组织。
-- 在Amazon服务是独立的功能交付单元。这也是Amazon如何组织他的内部团队的。
-- 如果你有一个新的业务建议,或者想解决一个问题,你就可以组织一个团队。由于沟通上的成本,每个团队都限制到8~10个人。他们被称为two pizza teams。因为用两个比萨饼,就可以让团队成员每个人都吃饱了。
-- 团队都是小规模的。他们被授权可以采取他们所中意的任何方式来解决一个问题或者增强一个服务。
-- 例如,他们创建了这样一个团队,其功能是在一本书中查找特有的文字和短语。这个团队为那个功能创建了一个独立的服务接口,而且有权做任何他们认为需要做的事情。
l 部署
-- 他们创建了一个特殊的基础设施,来完成对依赖性的管理和对完成服务的部署。
-- 目标是让所有正确的服务可以在一个主机中部署。所有的应用代码、监控机制、许可证机制等都应该在一个“主机”中。
-- 每个人都有一个自己的系统来解决这些问题。
-- 部署进程的输出是一个虚拟机,你可以用EC2来运行他们。
l 为了验证新服务的效果,从客户的角度去看待服务,这样做是值得的。
-- 从客户的角度去看待服务,聚焦于你想交付给用户的价值。
-- 强迫开发人员将关注点放在交付给客户的价值上,而不是先考虑如何构建技术再考虑如何使用技术。
-- 从用户将要看到的简要特性开始,再从客户考虑的角度检查你构建的服务是否有价值。
-- 以最小化的设计来结束设计过程。如果想要构建一个很大的分布式系统,简单性是关键。
l 对于大型可伸缩系统来说状态管理是核心问题
-- 内部而言,他们可以提供无限存储空间。
-- 并不是所有的操作是有状态的。结账的步骤是有状态的。
-- 通过分析最近点击过的页面的SessionID,这种服务可以为用户提供推荐商品建议。
-- 他们追踪、保存着所有的数据,所以保持状态不是一个问题。有一些分离的状态需要为一个session来保持。提供的服务们会一直保留信息,所以你只要使用这些服务就可以了。
l Eric Brewers' CAP理论——或称为系统的三个属性
-- 系统的三个属性:一致性,可用性,网络分区容忍度。
-- 对于任何一个共享数据的系统都至少具备这三个属性中的两个。
-- 网络分区容忍度:把节点分割成一些小的分组,它们可以看到其他的分组但是无法看到其他全部节点。
-- 一致性:写入一个值然后再读出来,你得到的返回值应该和写入的是同一个值。在一个分区系统中有些情况并非如此。
-- 可用性:并非总是可读或者可写。系统可能会告诉你无法写入数据因为需要保持数据的一致性。
-- 为了可伸缩性,你必须对系统进行分区,因此针对特定的系统,你要在高一致性或者高可用性之间做出选择。你必须找到可用性和一致性的恰当重叠部分。
-- 基于服务的需要来选择特定的实现方法。
-- 对于结账的过程,你总是想让更多的物品放入顾客的购物车,因为这样可以产生收入。在这种情况下你需要选择高可用性。错误对顾客是隐藏的,过后才会被拿出来分析。
-- 当一个顾客提交订单过来时,我们要将关注点更多的放在保持高一致性上。因为几个不同的服务——信用卡处服务、配送服务、报表功能等——在同时访问那些数据。
上段文字引自:http://www.yaosansi.com/post/1147.html
下面是一张Amazon的Dynamo Key-Value存储架构图:

Dynamo是亚马逊的key-value模式的存储平台,可用性和扩展性都很好,性能也不错:读写访问中99.9%的响应时间都在300ms内。
按分布式系统常用的哈希算法切分数据,分放在不同的node上。Read操作时,也是根据key的哈希值寻找对应的node。Dynamo使用了 Consistent Hashing算法,node对应的不再是一个确定的hash值,而是一个hash值范围,key的hash值落在这个范围内,则顺时针沿ring找,碰到的第一个node即为所需。
Dynamo对Consistent Hashing算法的改进在于:它放在环上作为一个node的是一组机器(而不是memcached把一台机器作为node),这一组机器是通过同步机制保证数据一致的。
有关Dynamo的更多信息请参看:http://baike.baidu.com/view/2982765.html?fromTaglist
Amazon的云架构图如下:

以下是运行原理:
工作启动器——工作从网站或其它软件子系统进入,在队列服务中排队等候处理。工作不一定非是大请求,可以是整个管线中独立的一小部分。不要把状态保存到工作执行器里。把需要做的事打包进工作请求,放回到队列服务中等候处理。
规划服务——它是亚马逊的基础设施,允许实例根据工作负载自动伸缩。这是与自有的虚拟服务器(VPS)或典型的数据中心方案主要的不同之处。它有一套启停AMIS的API,以及自动配置、运行VM的机制。
工作执行器——它们从队列中取出工作,完成具体处理。对SmugMug来说,工作结果存储在S3之上,但你也可以存储在自己的数据库、SimpleDB或其它地方。
队列服务——队列存储工作执行器要接受的工作。SmugMug建立了自己的队列服务,你也可以直接使用亚马逊的SQS,用起来同样简单。创建一个可伸缩、分布式、高性能、高可用的队列服务并非易事,所以你可以考虑一下“Flickr——先完成必不可少的工作,其它的放进队列”中推荐的大量队列产品。
控制器——该组件监控工作流相关的大量变量,并以最优化一小组参数为目标,决定需要多少EC2实例。按需增减实例。
每家供应商都有他们自己的解决方案,预计以后还会出现不同的解决方案。各家的云都还没有得到充分的探究,目前都正在缓慢而稳步地推敲着云的架构解决方案。
好了,有关Amazon架构就介绍到这里,希望能给路过的朋友一点启发,谢谢阅读!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}