


2009年3月27日23:52:20更新

 using System;
using System;
using System.Collections;
using System.Text;
using System.Text.RegularExpressions;
namespace Common
{
 /// <summary>
/// <summary>
 /// 内容分页 v0.1.2
/// 内容分页 v0.1.2
/// http://cn795.cnblogs.com
 /// </summary>
/// </summary>
public class ContentPage
{
/// <summary>
/// 内容分页
/// </summary>
/// <param name="strContent">要分页的字符串内容</param>
/// <param name="intPageSize">分页大小</param>
/// <param name="isOpen">最后一页字符小于intPageSize的1/4加到上一页</param>
/// <returns></returns>
public static ArrayList GetPageContent(string strContent, int intPageSize, bool isOpen)
{
ArrayList arrlist = new ArrayList();
string strp = strContent;
int num = RemoveHtml(strp.ToString()).Length;//除html标记后的字符长度
int bp = (intPageSize + (intPageSize / 5));
for (int i = 0; i < ((num % bp == 0) ? (num / bp) : ((num / bp) + 1)); i++)
{
arrlist.Add(SubString(intPageSize, ref strp));
num = RemoveHtml(strp.ToString()).Length;
if (isOpen && num < (intPageSize / 4))
{ // 小于分页1/4字符加到上一页
arrlist[arrlist.Count - 1] = arrlist[arrlist.Count - 1] + strp;
strp = "";
}
i = 0;
}
if (strp.Length > 0) arrlist.Add(strp); //大于1/4字符 小于intPageSize
return arrlist;
}
/// <summary>
/// < 符号搜索
/// </summary>
/// <param name="cr"></param>
/// <returns></returns>
private static bool IsBegin(char cr)
{
return cr.Equals('<');
}
/// <summary>
/// > 符号搜索
/// </summary>
/// <param name="cr"></param>
/// <returns></returns>
private static bool IsEnd(char cr)
{
return cr.Equals('>');
}
/// <summary>
/// 截取分页内容
/// </summary>
/// <param name="index">每页字符长度</param>
/// <param name="str"></param>
/// <returns></returns>
private static string SubString(int index, ref string str)
{
ArrayList arrlistB = new ArrayList();
ArrayList arrlistE = new ArrayList();
string strTag = "";
char strend = '0';
bool isBg = false;
bool IsSuEndTag = false;
index = Gindex(str, index);
string substr = CutString(str, 0, index); //截取分页长度
string substr1 = CutString(str, index, str.Length - substr.Length); //剩余字符
int iof = substr.LastIndexOf("<"), iof1 = 0;
 防止标记截断
防止标记截断
//分析截取字符内容提取标记
foreach (char cr in substr)
{
if (IsBegin(cr)) isBg = true;
if (isBg) strTag += cr;
if (isBg && cr.Equals('/') && strend.Equals('<')) IsSuEndTag = true;
if (IsEnd(cr))
{
if (strend.Equals('/')) //跳出 <XX />标记
{
isBg = false;
IsSuEndTag = false;
strTag = "";
}
if (isBg)
{
if (!CutString(strTag.ToLower(), 0, 3).Equals("<br"))
{
if (IsSuEndTag)
arrlistE.Add(strTag); //结束标记
else
arrlistB.Add(strTag); //开始标记
}
IsSuEndTag = false;
strTag = "";
isBg = false;
}
}
strend = cr;
}
//找到未关闭标记
for (int b = 0; b < arrlistB.Count; b++)
{
for (int e = 0; e < arrlistE.Count; e++)
{
string strb = arrlistB[b].ToString().ToLower();
int num = strb.IndexOf(' ');
if (num > 0) strb = CutString(strb, 0, num) + ">";
if (strb.ToLower().Replace("<", "</").Equals(arrlistE[e].ToString().ToLower()))
{
arrlistB.RemoveAt(b);
arrlistE.RemoveAt(e);
b = -1;
break;
}
}
}
//关闭被截断标记
for (int i = arrlistB.Count; i > 0; i--)
{
string stral = arrlistB[i - 1].ToString();
substr += (stral.IndexOf(" ") == -1 ? stral.Replace("<", "</") : CutString(stral, 0, stral.IndexOf(" ")).Replace("<", "</") + ">");
}
//补全上页截断的标签
string strtag = "";
for (int i = 0; i < arrlistB.Count; i++) strtag += arrlistB[i].ToString();
str = strtag + substr1; //更改原始字符串
return substr; //返回截取内容
}
/// <summary>
/// 返回真实字符长度
/// </summary>
/// <param name="str"></param>
/// <param name="index"></param>
/// <returns></returns>
private static int Gindex(string str, int index)
{
bool isBg = false;
bool isSuEndTag = false;
bool isNbsp = false,isRnbsp=false;;
string strnbsp="";
int i = 0, c = 0;
foreach (char cr in str)
{
if (!isBg && IsBegin(cr)) { isBg = true; isSuEndTag = false; }
if (isBg && IsEnd(cr)) { isBg = false; isSuEndTag = true; }
if (isSuEndTag && !isBg) //不在html标记内
{
if (cr.Equals('&')) isNbsp = true;
if (isNbsp)
{
strnbsp += cr.ToString();
if (strnbsp.Length > " ".Length) { isNbsp = false; strnbsp = ""; }
if (cr.Equals(';')) isNbsp = false;//
}
if (!isNbsp && !"".Equals(strnbsp)) isRnbsp = strnbsp.ToLower().Equals(" ");
}
if ((isSuEndTag || (!isBg && !isSuEndTag)) && !cr.Equals('\n') && !cr.Equals('\r') && !cr.Equals(' ')) { c++; }
if (isRnbsp) { c = c - 6; isRnbsp = false; strnbsp = ""; }
i++;
if (c == index) return i;
}
return i;
}
/// <summary>
/// 移除Html标记
/// </summary>
/// <param name="content"></param>
/// <returns></returns>
public static string RemoveHtml(string content)
{
content=Regex.Replace(content, @"<[^>]*>", string.Empty, RegexOptions.IgnoreCase);
return Regex.Replace(content, " ", string.Empty, RegexOptions.IgnoreCase);
}
/// <summary>
/// 从字符串的指定位置截取指定长度的子字符串
/// </summary>
/// <param name="str">原字符串</param>
/// <param name="startIndex">子字符串的起始位置</param>
/// <param name="length">子字符串的长度</param>
/// <returns>子字符串</returns>
public static string CutString(string str, int startIndex, int length)
{
if (startIndex >= 0)
{
if (length < 0)
{
length = length * -1;
if (startIndex - length < 0)
{
length = startIndex;
startIndex = 0;
}
else
{
startIndex = startIndex - length;
}
}
if (startIndex > str.Length) return "";
}
else
{
if (length < 0)
{
return "";
}
else
{
if (length + startIndex > 0)
{
length = length + startIndex;
startIndex = 0;
}
else
{
return "";
}
}
}
if (str.Length - startIndex < length) length = str.Length - startIndex;
try
{
return str.Substring(startIndex, length);
}
catch
{
return str;
}
}
}
 }
}
最近网站要做静态生成内容必须分页所以在网上找了N多实例都不理想,所以花了点时间自己写了个方法
目前来说没发现什么问题(已用方法生成20W以上的html)
所以把代码贴出来与大家分享。
不足之处或有更好的方法请大家告知我不胜感激。
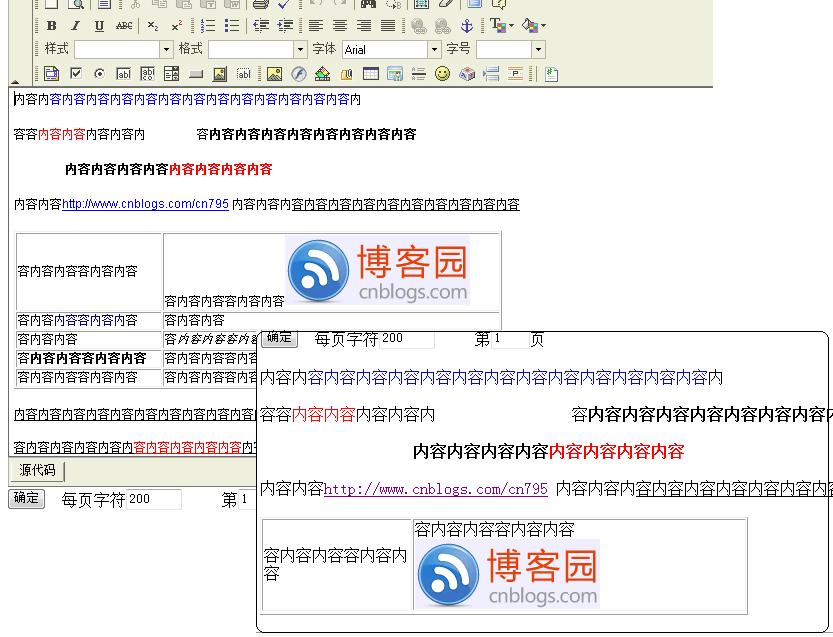
调用ArrayList arrlt=ContentPage.GetPageContent("分页内容", 分页大小,true);
using System;using System.Collections;using System.Text;using System.Text.RegularExpressions;namespace Common{
 /// <summary> /// 内容分页 v0.1.2 /// http://cn795.cnblogs.com /// </summary> public class ContentPage { /// <summary> /// 内容分页 /// </summary> /// <param name="strContent">要分页的字符串内容</param> /// <param name="intPageSize">分页大小</param> /// <param name="isOpen">最后一页字符小于intPageSize的1/4加到上一页</param> /// <returns></returns> public static ArrayList GetPageContent(string strContent, int intPageSize, bool isOpen) { ArrayList arrlist = new ArrayList(); string strp = strContent; int num = RemoveHtml(strp.ToString()).Length;//除html标记后的字符长度 int bp = (intPageSize + (intPageSize / 5)); for (int i = 0; i < ((num % bp == 0) ? (num / bp) : ((num / bp) + 1)); i++) { arrlist.Add(SubString(intPageSize, ref strp)); num = RemoveHtml(strp.ToString()).Length; if (isOpen && num < (intPageSize / 4)) { // 小于分页1/4字符加到上一页 arrlist[arrlist.Count - 1] = arrlist[arrlist.Count - 1] + strp; strp = ""; } i = 0; } if (strp.Length > 0) arrlist.Add(strp); //大于1/4字符 小于intPageSize return arrlist; } /// <summary> /// < 符号搜索 /// </summary> /// <param name="cr"></param> /// <returns></returns> private static bool IsBegin(char cr) { return cr.Equals('<'); } /// <summary> /// > 符号搜索 /// </summary> /// <param name="cr"></param> /// <returns></returns> private static bool IsEnd(char cr) { return cr.Equals('>'); } /// <summary> /// 截取分页内容 /// </summary> /// <param name="index">每页字符长度</param> /// <param name="str"></param> /// <returns></returns> private static string SubString(int index, ref string str) { ArrayList arrlistB = new ArrayList(); ArrayList arrlistE = new ArrayList(); string strTag = ""; char strend = '0'; bool isBg = false; bool IsSuEndTag = false; index = Gindex(str, index); string substr = CutString(str, 0, index); //截取分页长度 string substr1 = CutString(str, index, str.Length - substr.Length); //剩余字符 int iof = substr.LastIndexOf("<"), iof1 = 0; 防止标记截断 //分析截取字符内容提取标记 foreach (char cr in substr) { if (IsBegin(cr)) isBg = true; if (isBg) strTag += cr; if (isBg && cr.Equals('/') && strend.Equals('<')) IsSuEndTag = true; if (IsEnd(cr)) { if (strend.Equals('/')) //跳出 <XX />标记 { isBg = false; IsSuEndTag = false; strTag = ""; } if (isBg) { if (!CutString(strTag.ToLower(), 0, 3).Equals("<br")) { if (IsSuEndTag) arrlistE.Add(strTag); //结束标记 else arrlistB.Add(strTag); //开始标记 } IsSuEndTag = false; strTag = ""; isBg = false; } } strend = cr; } //找到未关闭标记 for (int b = 0; b < arrlistB.Count; b++) { for (int e = 0; e < arrlistE.Count; e++) { string strb = arrlistB[b].ToString().ToLower(); int num = strb.IndexOf(' '); if (num > 0) strb = CutString(strb, 0, num) + ">"; if (strb.ToLower().Replace("<", "</").Equals(arrlistE[e].ToString().ToLower())) { arrlistB.RemoveAt(b); arrlistE.RemoveAt(e); b = -1; break; } } } //关闭被截断标记 for (int i = arrlistB.Count; i > 0; i--) { string stral = arrlistB[i - 1].ToString(); substr += (stral.IndexOf(" ") == -1 ? stral.Replace("<", "</") : CutString(stral, 0, stral.IndexOf(" ")).Replace("<", "</") + ">"); } //补全上页截断的标签 string strtag = ""; for (int i = 0; i < arrlistB.Count; i++) strtag += arrlistB[i].ToString(); str = strtag + substr1; //更改原始字符串 return substr; //返回截取内容 } /// <summary> /// 返回真实字符长度 /// </summary> /// <param name="str"></param> /// <param name="index"></param> /// <returns></returns> private static int Gindex(string str, int index) { bool isBg = false; bool isSuEndTag = false; bool isNbsp = false,isRnbsp=false;; string strnbsp=""; int i = 0, c = 0; foreach (char cr in str) { if (!isBg && IsBegin(cr)) { isBg = true; isSuEndTag = false; } if (isBg && IsEnd(cr)) { isBg = false; isSuEndTag = true; } if (isSuEndTag && !isBg) //不在html标记内 { if (cr.Equals('&')) isNbsp = true; if (isNbsp) { strnbsp += cr.ToString(); if (strnbsp.Length > " ".Length) { isNbsp = false; strnbsp = ""; } if (cr.Equals(';')) isNbsp = false;// } if (!isNbsp && !"".Equals(strnbsp)) isRnbsp = strnbsp.ToLower().Equals(" "); } if ((isSuEndTag || (!isBg && !isSuEndTag)) && !cr.Equals('\n') && !cr.Equals('\r') && !cr.Equals(' ')) { c++; } if (isRnbsp) { c = c - 6; isRnbsp = false; strnbsp = ""; } i++; if (c == index) return i; } return i; } /// <summary> /// 移除Html标记 /// </summary> /// <param name="content"></param> /// <returns></returns> public static string RemoveHtml(string content) { content=Regex.Replace(content, @"<[^>]*>", string.Empty, RegexOptions.IgnoreCase); return Regex.Replace(content, " ", string.Empty, RegexOptions.IgnoreCase); } /// <summary> /// 从字符串的指定位置截取指定长度的子字符串 /// </summary> /// <param name="str">原字符串</param> /// <param name="startIndex">子字符串的起始位置</param> /// <param name="length">子字符串的长度</param> /// <returns>子字符串</returns> public static string CutString(string str, int startIndex, int length) { if (startIndex >= 0) { if (length < 0) { length = length * -1; if (startIndex - length < 0) { length = startIndex; startIndex = 0; } else { startIndex = startIndex - length; } } if (startIndex > str.Length) return ""; } else { if (length < 0) { return ""; } else { if (length + startIndex > 0) { length = length + startIndex; startIndex = 0; } else { return ""; } } } if (str.Length - startIndex < length) length = str.Length - startIndex; try { return str.Substring(startIndex, length); } catch { return str; } } }}
/// <summary> /// 内容分页 v0.1.2 /// http://cn795.cnblogs.com /// </summary> public class ContentPage { /// <summary> /// 内容分页 /// </summary> /// <param name="strContent">要分页的字符串内容</param> /// <param name="intPageSize">分页大小</param> /// <param name="isOpen">最后一页字符小于intPageSize的1/4加到上一页</param> /// <returns></returns> public static ArrayList GetPageContent(string strContent, int intPageSize, bool isOpen) { ArrayList arrlist = new ArrayList(); string strp = strContent; int num = RemoveHtml(strp.ToString()).Length;//除html标记后的字符长度 int bp = (intPageSize + (intPageSize / 5)); for (int i = 0; i < ((num % bp == 0) ? (num / bp) : ((num / bp) + 1)); i++) { arrlist.Add(SubString(intPageSize, ref strp)); num = RemoveHtml(strp.ToString()).Length; if (isOpen && num < (intPageSize / 4)) { // 小于分页1/4字符加到上一页 arrlist[arrlist.Count - 1] = arrlist[arrlist.Count - 1] + strp; strp = ""; } i = 0; } if (strp.Length > 0) arrlist.Add(strp); //大于1/4字符 小于intPageSize return arrlist; } /// <summary> /// < 符号搜索 /// </summary> /// <param name="cr"></param> /// <returns></returns> private static bool IsBegin(char cr) { return cr.Equals('<'); } /// <summary> /// > 符号搜索 /// </summary> /// <param name="cr"></param> /// <returns></returns> private static bool IsEnd(char cr) { return cr.Equals('>'); } /// <summary> /// 截取分页内容 /// </summary> /// <param name="index">每页字符长度</param> /// <param name="str"></param> /// <returns></returns> private static string SubString(int index, ref string str) { ArrayList arrlistB = new ArrayList(); ArrayList arrlistE = new ArrayList(); string strTag = ""; char strend = '0'; bool isBg = false; bool IsSuEndTag = false; index = Gindex(str, index); string substr = CutString(str, 0, index); //截取分页长度 string substr1 = CutString(str, index, str.Length - substr.Length); //剩余字符 int iof = substr.LastIndexOf("<"), iof1 = 0; 防止标记截断 //分析截取字符内容提取标记 foreach (char cr in substr) { if (IsBegin(cr)) isBg = true; if (isBg) strTag += cr; if (isBg && cr.Equals('/') && strend.Equals('<')) IsSuEndTag = true; if (IsEnd(cr)) { if (strend.Equals('/')) //跳出 <XX />标记 { isBg = false; IsSuEndTag = false; strTag = ""; } if (isBg) { if (!CutString(strTag.ToLower(), 0, 3).Equals("<br")) { if (IsSuEndTag) arrlistE.Add(strTag); //结束标记 else arrlistB.Add(strTag); //开始标记 } IsSuEndTag = false; strTag = ""; isBg = false; } } strend = cr; } //找到未关闭标记 for (int b = 0; b < arrlistB.Count; b++) { for (int e = 0; e < arrlistE.Count; e++) { string strb = arrlistB[b].ToString().ToLower(); int num = strb.IndexOf(' '); if (num > 0) strb = CutString(strb, 0, num) + ">"; if (strb.ToLower().Replace("<", "</").Equals(arrlistE[e].ToString().ToLower())) { arrlistB.RemoveAt(b); arrlistE.RemoveAt(e); b = -1; break; } } } //关闭被截断标记 for (int i = arrlistB.Count; i > 0; i--) { string stral = arrlistB[i - 1].ToString(); substr += (stral.IndexOf(" ") == -1 ? stral.Replace("<", "</") : CutString(stral, 0, stral.IndexOf(" ")).Replace("<", "</") + ">"); } //补全上页截断的标签 string strtag = ""; for (int i = 0; i < arrlistB.Count; i++) strtag += arrlistB[i].ToString(); str = strtag + substr1; //更改原始字符串 return substr; //返回截取内容 } /// <summary> /// 返回真实字符长度 /// </summary> /// <param name="str"></param> /// <param name="index"></param> /// <returns></returns> private static int Gindex(string str, int index) { bool isBg = false; bool isSuEndTag = false; bool isNbsp = false,isRnbsp=false;; string strnbsp=""; int i = 0, c = 0; foreach (char cr in str) { if (!isBg && IsBegin(cr)) { isBg = true; isSuEndTag = false; } if (isBg && IsEnd(cr)) { isBg = false; isSuEndTag = true; } if (isSuEndTag && !isBg) //不在html标记内 { if (cr.Equals('&')) isNbsp = true; if (isNbsp) { strnbsp += cr.ToString(); if (strnbsp.Length > " ".Length) { isNbsp = false; strnbsp = ""; } if (cr.Equals(';')) isNbsp = false;// } if (!isNbsp && !"".Equals(strnbsp)) isRnbsp = strnbsp.ToLower().Equals(" "); } if ((isSuEndTag || (!isBg && !isSuEndTag)) && !cr.Equals('\n') && !cr.Equals('\r') && !cr.Equals(' ')) { c++; } if (isRnbsp) { c = c - 6; isRnbsp = false; strnbsp = ""; } i++; if (c == index) return i; } return i; } /// <summary> /// 移除Html标记 /// </summary> /// <param name="content"></param> /// <returns></returns> public static string RemoveHtml(string content) { content=Regex.Replace(content, @"<[^>]*>", string.Empty, RegexOptions.IgnoreCase); return Regex.Replace(content, " ", string.Empty, RegexOptions.IgnoreCase); } /// <summary> /// 从字符串的指定位置截取指定长度的子字符串 /// </summary> /// <param name="str">原字符串</param> /// <param name="startIndex">子字符串的起始位置</param> /// <param name="length">子字符串的长度</param> /// <returns>子字符串</returns> public static string CutString(string str, int startIndex, int length) { if (startIndex >= 0) { if (length < 0) { length = length * -1; if (startIndex - length < 0) { length = startIndex; startIndex = 0; } else { startIndex = startIndex - length; } } if (startIndex > str.Length) return ""; } else { if (length < 0) { return ""; } else { if (length + startIndex > 0) { length = length + startIndex; startIndex = 0; } else { return ""; } } } if (str.Length - startIndex < length) length = str.Length - startIndex; try { return str.Substring(startIndex, length); } catch { return str; } } }}

