常见算法与数据结构
生活应用
- 找对象:以第二个为准,以后找比他好的就是最优方案
- 工作任务安排:不要以队列(先进先出)和栈为标准,优先队列,从最困难开始入手。
- 扑克游戏
- 加密货币与区块链
学习原因
- 算法是内功,招式是其次
- 大厂
- 有趣且实用(当红技术)
基本介绍
-
定义:一个计算过程,解决问题的方法,而程序=数据结构+算法。
-
时间复杂度:⽤来评估算法运⾏效率的⼀个式⼦。
print('hello world') # 时间复杂度为O(1) for i in range(n): print('hello world') # 时间复杂度为O(n) for i in range(n): print('hello world') for i in range(n): print('hello world') # 时间复杂度为O(n^2) for i in range(n): print('hello world') for i in range(n): print('hello world') for i in range(n): print('hello world') # 时间复杂度为O(n^3)def func(n): while n > 1: print(n) n = n // 2 func(64) #当算法过程出现循环折半时,时间复杂度记为O(logn) # 64 # 32 # 16 # 8 # 4 # 2 -
如何简单快速的判断时间复杂度(适用于大多数情况)?
- 确定问题规模n
- 循环减半过程——logn
- k层关于n的循环——n^k
-
空间复杂度:⽤来评估算法内存占⽤⼤⼩的式⼦。空间换时间,表达式跟时间复杂度一样,如下:
- 算法使⽤了⼏个变量:O(1)
- 算法使⽤了⻓度为n的⼀维列表:O(n)
- 算法使⽤了m⾏n列的⼆维列表:O(mn)
递归函数
-
定义:既调用自身,又有结束条件的函数,称为合法递归,否则称为死递归。
def func1(x): print(x) func1(x - 1) func1(10) # 死递归 def func2(x): print(x) func2(x + 1) func2(10) # 死递归 def func3(x): if x > 0: print(x) func3(x - 1) func3(10) # 合法递归 def func4(x): if x > 0: func4(x - 1) print(x) func4(10) # 合法递归 #递归必须要有两个明确的阶段: #递推:一层一层递归调用下去,进入下一层递归的问题规模都将会减小 #回溯:递归必须要有一个明确的结束条件,在满足该条件开始一层一层回溯。注:递归之所以会出现最大递归深度是因为每递归一次重新开辟内存空间,占用内存;而while循环是每循环一次,虽然开辟内存空间,但是上一次的内存地址被回收。
-
汉诺塔问题
印度大梵天创造世界时做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘,大梵天命令婆罗门把圆盘从下面开始按大小顺序重新摆放在另一根柱子上。在小圆盘不能放大圆盘,在三根柱子之间一次只能移动一个圆盘。64根柱子移动完毕之日,就是世界毁灭之时。
当n=2时:
- 把小圆盘从A移动到B
- 把大圆盘从A移动到C
- 把小圆盘从B移动到C
当n个盘子时:
- 把n-1个圆盘从A经过C移动到B
- 把第n个圆盘从A移动到C
- 把n-1个小圆盘从B经过A移动到C
总结:
- 汉诺塔移动次数的递归式:h(x)=2h(x-1)+1
- 假设婆罗门每秒钟搬一个盘子,则需要5800亿年
# n表示n个盘子,a表示从哪个盘子,b表示经过哪个盘子,c表示到哪个盘子 def hanoi(n, a, b, c): if n > 0: hanoi(n - 1, a, c, b) print(f'moving from {a} to {c}') hanoi(n - 1, b, a, c) hanoi(4, 'A', 'B', 'C')
列表排序
- 定义:将⼀组“⽆序”的记录序列调整为“有序”的记录序列。
冒泡排序(bubble sort)
-
定义:列表每两个相邻的数,如果前⾯⽐后⾯⼤,则交换这两个数。 ⼀趟排序完成后,则⽆序区减少⼀个数,有序区增加⼀个数。
#代码关键点:趟、无序区范围 import random def bubble_sort(li): for i in range(len(li) - 1): # 第i趟 for j in range(len(li) - i - 1): # 指针位置 if li[j] > li[j + 1]: li[j], li[j + 1] = li[j + 1], li[j] print(li) li = [random.randint(1, 100) for i in range(10)] print(li) bubble_sort(li) # 优化:如果冒泡排序中的⼀趟排序没有发⽣交换,则说明列表已经有序,可以直接结束算法。 import random def bubble_sort(li): for i in range(len(li) - 1): # 第i趟 for j in range(len(li) - i - 1): # 指针位置 exchange = False if li[j] > li[j + 1]: li[j], li[j + 1] = li[j + 1], li[j] exchange = True if not exchange: return None print(li) li = [random.randint(1, 100) for i in range(10)] print(li) bubble_sort(li) # 时间复杂度o(n^2)
选择排序(select sort)
-
定义:⼀趟排序记录最⼩的数,放到第⼀个位置 ,再⼀趟排序记录记录列表⽆序区最⼩的数,放到第⼆个位置.....
# 算法关键点:有序区和⽆序区、⽆序区最⼩数的位置 def select_sort(li): for i in range(len(li) - 1): # 第i趟 min_loc = i # 假设最小值索引为i for j in range(i + 1, len(li)): if li[j] < li[min_loc]: min_loc = j li[i], li[min_loc] = li[min_loc], li[i] print(li) li = [9, 1, 2, 3, 8, 7, 6, 4, 5] select_sort(li) print(li) # 时间复杂度o(n^2)
插入排序(insert sort)
定义:初始时⼿⾥(有序区)只有⼀张牌,每次(从⽆序区)摸⼀张牌,插⼊到⼿⾥已有牌的正确位置 。
def insert_sort(li):
for i in range(1, len(li)): # i 表示摸到的牌的下标
tmp = li[i] # 临时变量
j = i - 1 # j 表示手里的牌的下标
while j >= 0 and tmp < li[j]:
li[j + 1] = li[j]
j = j - 1
li[j + 1] = tmp
li = [9, 4, 3, 2, 1, 5, 6, 7, 8]
insert_sort(li)
print(li)
#时间复杂度为o(n^2)
快速排序(quick sort)

解题思路:
- 取⼀个元素p(第⼀个元素),使元素p归位;
- 列表被p分成两部分,左边都⽐p⼩,右边都⽐p⼤;
- 递归完成排序。
快速排序的时间复杂度:O(nlogn),完全倒序时间复杂度时:O(n^2)
特殊情况:达到最大递归深度,但是可以修改。
p如何实现归位,以上图为例:先将5拿出来,左指针left和右指针right分别放于两端,假设按顺序升序排序,当右指针移到2时比5小移到5原来的位置,再从左边开始,发现7比5大,将7移到原来2的位置,再从右边开始发现1比5小,将1移动到原来7的位置,再从左边开始移动,4比5小不移动,发现6比5大,所以将6移动到原来1的位置,再从右边开始,发现3比5小,将3移动到原来6的位置,此时3和6之间存在一个空位置,就将5放到该位置,实现了p归位。
# 框架
def quick_sort(data, left, right): # 参数:列表、左指针位置、右指针位置
if left < right:
mid = partition(data, left, right) # 归位位置
quick_sort(data, left, mid - 1) # 递归原函数
quick_sort(data, mid + 1, right)
def partition(li, left, right):
"""求归位元素函数"""
tmp = li[left] # 初始值:归位元素
while left < right:
while left < right and li[right] >= tmp: right -= 1 # 从右面找比tmp小的元素,若右面元素大于等于tmp往左移动一位且如果碰上跳出本次循环
li[left] = li[right] # 把右边的值赋值给左边空位上
while left < right and li[left] <= tmp: left += 1 # 从左面找比tmp大的元素,若左面元素小于等于tmp往右移动一位且如果碰上跳出本次循环
li[right] = li[left] # 把左边的值赋值给右边空位上
li[left] = tmp
return left
def quick_sort(li, left, right):
"""快速排序函数"""
if left < right:
mid = partition(li, left, right)
quick_sort(li, left, mid - 1)
quick_sort(li, mid + 1, right)
li = [5, 7, 4, 6, 3, 1, 2, 9, 8]
quick_sort(li, 0, len(li) - 1)
print(li)
# 装饰器不能直接加在递归函数上,不然装饰器跟着递归,需要换马甲,如下:
import time
import random
def cal_time(func):
def wrapper(*args, **kwargs):
t1 = time.time()
res = func(*args, **kwargs)
t2 = time.time()
print(f'{func.__name__} running time:{t2 - t1} secs')
return res
return wrapper
def partition(li, left, right):
"""求归位元素函数"""
tmp = li[left] # 初始值:归位元素
while left < right:
while left < right and li[right] >= tmp: right -= 1 # 从右面找比tmp小的元素,若右面元素大于等于tmp往左移动一位且如果碰上跳出本次循环
li[left] = li[right] # 把右边的值赋值给左边空位上
while left < right and li[left] <= tmp: left += 1 # 从左面找比tmp大的元素,若左面元素小于等于tmp往右移动一位且如果碰上跳出本次循环
li[right] = li[left] # 把左边的值赋值给右边空位上
li[left] = tmp
return left
def _quick_sort(li, left, right): # 换马甲
if left < right:
mid = partition(li, left, right)
_quick_sort(li, left, mid - 1)
_quick_sort(li, mid + 1, right)
@cal_time
def quick_sort(li, left, right):
_quick_sort(li, left, right)
li = list(range(10000))
random.shuffle(li)
quick_sort(li, 0, len(li) - 1)
堆排序(heap sort)
树的基础知识
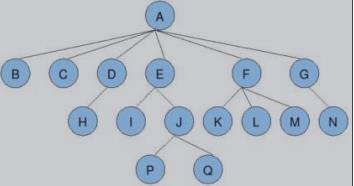
-
树是⼀种数据结构,树也是⼀种可以递归定义的数据结构 ,⽐如:⽬录结构
-
树是由n个节点组成的集合:
-
如果n=0,那这是⼀棵空树;
-
如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身⼜是⼀棵树。
-
-
基本概念:
- 根节点:如A
- 叶子节点:如B、C、H、I、P、Q、K、L、M、N
- 根的深度(高度):4
- 树的度(节点分几个叉):6
- 孩子节点:I是E的孩子节点,反之E是I的父节点。
- 子树:B是A的子树、D和H也是A的子树。
-
需求:模拟文件系统
class Node: def __init__(self, name, type='dir'): self.name = name self.type = type self.children = [] self.parent = None # 链式存储 def __repr__(self): return self.name class FileSystemTree: def __init__(self): self.root = Node("/") self.now = self.root def mkdir(self, name): if name[-1] != "/": name += "/" if name == "../": self.now = self.now.parent return node = Node(name) self.now.children.append(node) node.parent = self.now def ls(self): return self.now.children def cd(self, name): if name[-1] != "/": name += "/" for child in self.now.children: if child.name == name: self.now = child return raise ValueError("invalid dir") tree = FileSystemTree() tree.mkdir("var/") tree.mkdir("bin/") tree.mkdir("usr/") tree.cd("bin/") tree.mkdir("python/") print(tree.root.children) print(tree.ls())
二叉树的基本知识
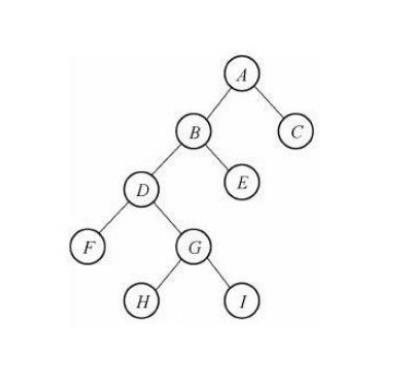
⼆叉树:度不超过2的树,即每个节点最多有两个孩⼦节点。而两个孩⼦节点被区分为左孩⼦节点和右孩⼦节点
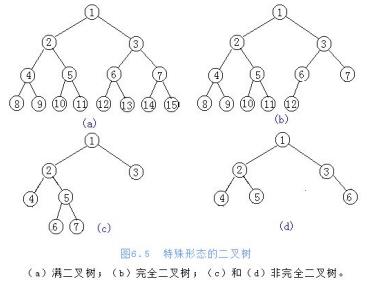
满⼆叉树:⼀个⼆叉树,如果每⼀个层的结点数都达到最⼤值。
完全⼆叉树:叶节点只能出现在最下层和次下层,并且最下⾯⼀层的结点都集中在该层最左边的若⼲位置的⼆叉树。
二叉树的存储方式(表示方式):链式存储方式和顺序存储方式
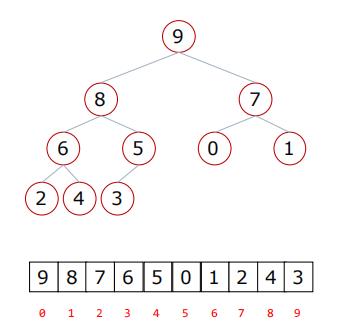
二叉树的顺序存储方式:
⽗节点和左孩⼦节点的编号下标有什么关系?
- 0-1 1-3 2-5 3-7 4-9 规律:i → 2i+1 (i表示父节点编号下标)
⽗节点和右孩⼦节点的编号下标有什么关系?
- 0-2 1-4 2-6 3-8 4-10 规律:i → 2i+2(i表示父节点编号下标)
堆的基础知识
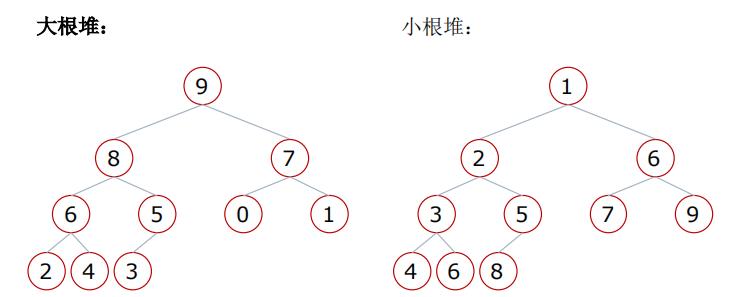
堆:⼀种特殊的完全⼆叉树结构
-
⼤根堆:⼀棵完全⼆叉树,满⾜任⼀节点都⽐其孩⼦节点⼤
-
⼩根堆:⼀棵完全⼆叉树,满⾜任⼀节点都⽐其孩⼦节点⼩
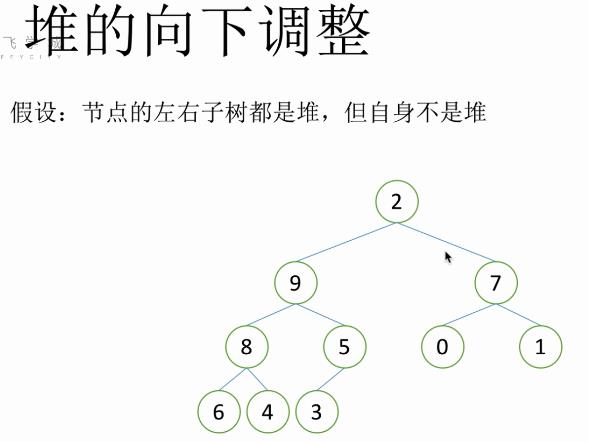
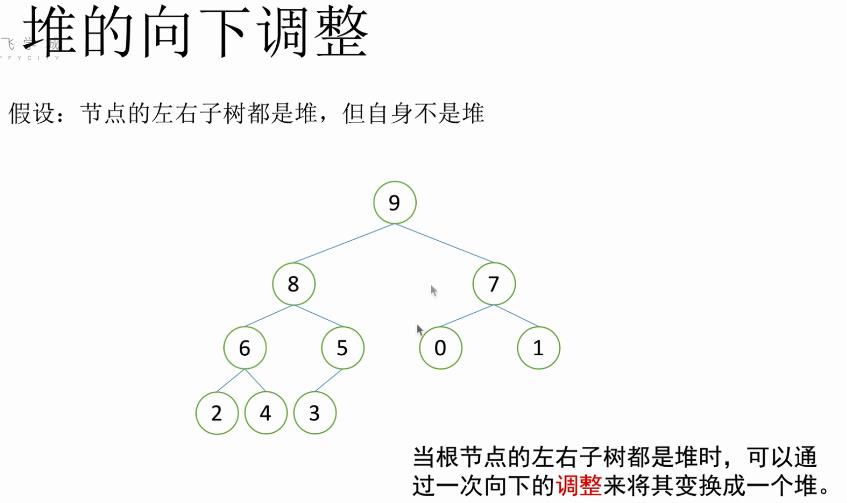
堆的向下调整性质:假设根节点的左右⼦树都是堆,但根节点不满⾜堆的性质,可以通过⼀次向下的调整来将其变成⼀个堆。
堆排序过程 :
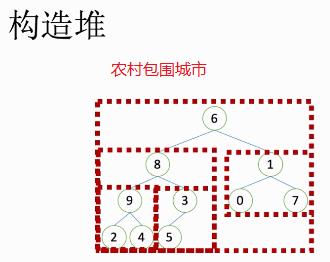
-
建⽴堆(农村包围城市)。
-
得到堆顶元素,为最⼤元素
-
去掉堆顶,将堆最后⼀个元素放到堆顶,此时可通过⼀次调整重新使堆有序。
-
堆顶元素为第⼆⼤元素。
-
重复步骤3,直到堆变空。
import random def sift(li, low, high): """ 向下调整函数 :param li:列表 :param low: 堆的根节点位置 :param high:堆的最后一个元素的位置 :return: """ i = low # i最开始指向根节点 j = 2 * i + 1 # j最开始是左孩子 tmp = li[low] # 把堆顶存起来 while j <= high: # 只要j位置有数 if j + 1 <= high and li[j + 1] > li[j]: # 如果右孩子有且比左孩子大 j = j + 1 # j指向右孩子 if li[j] > tmp: # 向下调整 li[i] = li[j] # 交换父子节点值 i = j # 往下看一层 j = 2 * i + 1 else: li[i] = tmp # tmp更大,把tmp放到i的位置上, break else: li[i] = tmp # 把tmp放到叶子节点上 def heap_sort(li): """堆排序函数""" n = len(li) # 列表长度 for i in range((n - 1 - 1) // 2, -1, -1): # 倒序从子节点位置到根节点0的循环,挨个出数,从底部开始出 # i表示建堆时调整的部分的下标 sift(li, i, n - 1) # 默认最后一个元素 # 建堆完成 for i in range(n - 1, -1, -1): # i指向当前堆最后一个位置 li[0], li[i] = li[i], li[0] # 交换位置挨个出数 sift(li, 0, i - 1) # 此时i-1是high的新位置 li = list(range(100)) random.shuffle(li) heap_sort(li) print(li) # 向下调整函数的时间复杂度是logn,而堆排序的时间复杂度是nlogn
堆的内置模块
import heapq # q指优先队列
import random
lis = list(range(100))
random.shuffle(lis)
heapq.heapify(lis) # 默认建小跟堆,见源码
for i in range(len(lis)):
print(heapq.heappop(lis), end=',') # 每次取出最小那个数
topk问题
定义:现在有n个数,设计算法得到前k⼤的数。(k<n)
应用:热搜、排行榜
解题思路:
-
排序后切⽚ O(nlogn)
-
排序LowB三⼈组 O(kn)
-
堆排序思路 O(nlogk)
-
取列表前k个元素建⽴⼀个⼩根堆。堆顶就是⽬前第k⼤的数。
-
依次向后遍历原列表,对于列表中的元素,如果⼩于堆顶,则忽略该元素;如果⼤于堆顶,则将堆顶更换为该元素,并且对堆进⾏⼀次调整;
-
遍历列表所有元素后,倒序弹出堆顶。
import random def sift(li, low, high): """向上调整函数——建小跟堆 """ i = low j = 2 * i + 1 tmp = li[low] while j <= high: if j + 1 <= high and li[j + 1] < li[j]: # 取小的部分 j = j + 1 if li[j] < tmp: li[i] = li[j] i = j j = 2 * i + 1 else: li[i] = tmp break else: li[i] = tmp def topk(li, k): heap = li[0:k] # 取列表前k部分 for i in range((k - 1 - 1) // 2, -1, -1): sift(heap, i, k - 1) # 建小跟堆 for i in range(k, len(li) - 1): if li[i] > heap[0]: # 如果大于堆顶值,覆盖堆顶的值 heap[0] = li[i] sift(heap, 0, k - 1) # 遍历 for i in range(k - 1, -1, -1): heap[0], heap[i] = heap[i], heap[0] sift(heap, 0, i - 1) return heap li = list(range(1000)) random.shuffle(li) print(topk(li, 10))
-
归并排序(merge sort)
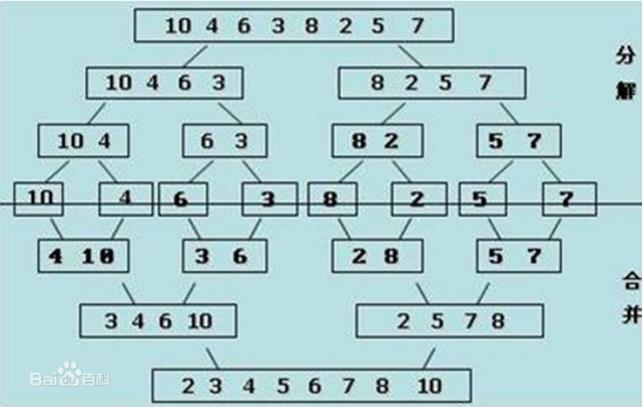
一次归并操作:假设现在的列表分两段有序,如何将其合成为⼀个有序列表,如[2,5,7,8,9,1,3,4,6]。
归并解题思路:
- 分解:将列表越分越⼩,直⾄分成⼀个元素。
- 终⽌条件:⼀个元素是有序的。
- 合并:将两个有序列表归并,列表越来越⼤。
import random
def merge(li, low, mid, high):
"""
一次归并函数
:param li: 列表
:param low: 开始位置索引
:param mid: 中间位置索引
:param high: 末位置索引
:return:
"""
i = low
j = mid + 1
tmp = []
while i <= mid and j <= high: # 保证两边都有值,循环完肯定有一边没数了。
if li[i] < li[j]:
tmp.append(li[i])
i += 1
else:
tmp.append(li[j])
j += 1
while i <= mid: # 假设左边有数,循环左边
tmp.append(li[i])
i += 1
while j <= high: # 假设右边有数,循环右边
tmp.append(li[j])
j += 1
li[low:high + 1] = tmp # 重新赋值
def merge_sort(li, low, high):
"""归并排序"""
if low < high: # 保证至少有两个元素才能递归
mid = (low + high) // 2
merge_sort(li, low, mid)
merge_sort(li, mid + 1, high)
merge(li, low, mid, high)
li = list(range(20))
random.shuffle(li)
merge_sort(li, 0, len(li) - 1)
print(li)
# 时间复杂度:O(nlogn);空间复杂度:O(n)
常见排序总结
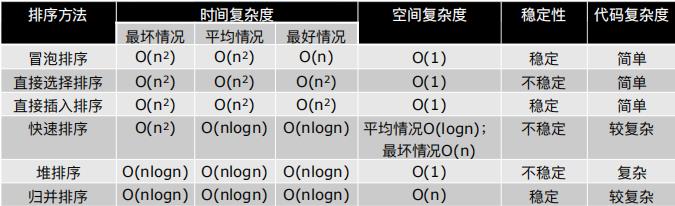
快速排序、堆排序、归并排序算法的时间复杂度都是O(nlogn)
⼀般情况下,就运⾏时间⽽⾔: 快速排序 < 归并排序 < 堆排序
三种排序算法的缺点:
快速排序:极端情况下排序效率低
归并排序:需要额外的内存开销
堆排序:在快的排序算法中相对较慢
希尔排序(shell sort)
定义:分组插⼊排序算法。思路如下:
-
⾸先取⼀个整数d1=n/2,将元素分为d1个组,每组相邻两元素之间距离为d1,在各组内进⾏直接插⼊排序;
-
取第⼆个整数d2=d1/2,重复上述分组排序过程,直到di=1,即所有元素在同⼀组内进⾏直接插⼊排序。
-
希尔排序每趟并不使某些元素有序,⽽是使整体数据越来越接近有序;最后⼀趟排序使得所有数据有序。
def insert_sort_gap(li, gap): """ :param li: 列表 :param gap: 分组数 :return: """ for i in range(gap, len(li)): # i表示摸到的牌的下标 tmp = li[i] j = i - gap # j表示的是手里的牌的下标 while j >= 0 and li[j] > tmp: li[j + gap] = li[j] j -= gap li[j + gap] = tmp def shell_sort(li): d = len(li) // 2 while d >= 1: insert_sort_gap(li, d) d //= 2 li=list(range(1000)) import random random.shuffle(li) shell_sort(li) print(li) # 希尔排序的时间复杂度讨论⽐较复杂,并且和选取的gap序列有关。
计数排序(count sort)
定义:对列表进⾏排序,已知列表中的数范围都在0到100之间。设计时间复杂度为O(n)的算法。
def count_sort(li, max_count=100):
count = [0 for _ in range(max_count + 1)]
for val in li:
count[val] += 1
li.clear()
for ind, val in enumerate(count):
for i in range(val):
li.append(ind)
import random
li = [random.randint(0, 100) for _ in range(1000)]
count_sort(li)
print(li)
桶排序(bucket sort)
定义:⾸先将元素分在不同的桶中,在对每个桶中的元素排序。在计数排序中,如果元素的范围⽐较⼤(⽐如在1到1亿之间), 如何改造算法?
def bucket_sort(li, n=100, max_num=10000):
buckets = [[] for _ in range(n)] # 创建桶
for var in li:
i = min(var // (max_num // n), n - 1) # i表示var放到几号桶里
buckets[i].append(var)
for j in range(len(buckets[i]) - 1, 0, -1):
if buckets[i][j] < buckets[i][j - 1]:
buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j]
else:
break
sorted_li = []
for buc in buckets:
sorted_li.extend(buc)
return sorted_li
import random
li = [random.randint(0, 10000) for i in range(100000)]
li = bucket_sort(li)
print(li)
#桶排序的表现取决于数据的分布。也就是需要对不同数据排序时采取不同的分桶策略。
#平均情况时间复杂度:O(n+k)
#最坏情况时间复杂度:O(n2k)
#空间复杂度:O(nk)
基数排序
多关键字排序:加⼊现在有⼀个员 ⼯表,要求按照薪资排序,年龄相同的员⼯按照年龄排序。 先按照年龄进⾏排序,再按照薪资进⾏稳定的排序。 对32,13,94,52,17,54,93排序,是否可以看做多关键字排序?
def list_to_buckets(li, base, iteration):
buckets = [[] for _ in range(base)]
for number in li:
digit = (number // (base ** iteration)) % base
buckets[digit].append(number)
return buckets
def buckets_to_list(buckets):
return [x for bucket in buckets for x in bucket]
def radix_sort(li, base=10):
maxval = max(li)
it = 0
while base ** it <= maxval:
li = buckets_to_list(list_to_buckets(li, base, it))
it += 1
return li
# 时间复杂度:O(kn)
# 空间复杂度:O(k+n)
# k表示数字位数
数据结构
基本介绍
数据结构定义:设计数据以何种方式组织并存储在计算机中。N.Wirth: “程序=数据结构+算法”
数据结构分类:
- 线性结构:数据结构中的元素存在一对一的相互关系,如列表,字典
- 树结构:数据结构中的元素存在一对多的相互关系,如目录结构
- 图结构:数据结构中的元素存在多对多的相互关系,如地图
列表(数组)
列表中的元素是如何存储的?答:顺序存储
列表的基本操作:按下标查找、插入元素、删除元素……
这些操作的时间复杂度是多少?答:O(1)、O(n)、O(n)
扩展:Python的列表是如何实现的?答:内存地址
数组与列表的区别:
1.数组元素类型要相同
2.数组长度固定
注:32位机器上,一个整数占4个字节,相当于一个地址占四个字节。
栈
栈(Stack)是一个数据集合,可以理解为只能在一端进行插入或删除操作的列表。
栈的特点:后进先出 LIFO(last-in, first-out)
栈的概念:栈顶、栈底
栈的基本操作:
- 进栈(压栈):push
- 出栈:pop
- 取栈顶:gettop
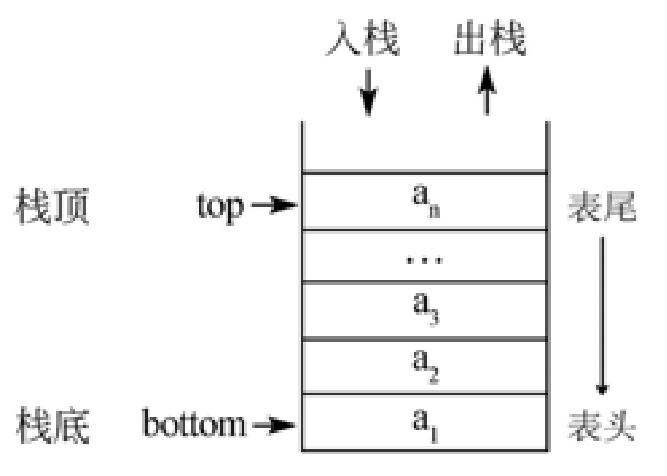
栈的实现
使用一般的列表结构即可实现栈:
- 进栈:li.append
- 出栈:li.pop
- 取栈顶:li[-1]
class Stack:
def __init__(self):
self.stack = []
def push(self, element): # 进栈
self.stack.append(element)
def pop(self): # 出栈
return self.stack.pop()
def get_top(self): # 取栈顶
if len(self.stack) > 0:
return self.stack[-1]
else:
return None
stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.pop())
栈的应用
括号匹配问题:给一个字符串,其中包含小括号、中括号、大括号,求该字符串中的括号是否匹配。
例如:
- ()()[]{} 匹配
- ([{()}]) 匹配
- []( 不匹配
- [(]) 不匹配
class Stack:
def __init__(self):
self.stack = []
def push(self, element): # 进栈
self.stack.append(element)
def pop(self): # 出栈
return self.stack.pop()
def get_top(self): # 取栈顶
if len(self.stack) > 0:
return self.stack[-1]
else:
return None
def is_empty(self):
return len(self.stack) == 0
def brace_match(s):
match = {'}': '{', ']': '[', ')': '('}
stack = Stack()
for ch in s:
if ch in {'(', '{', '['}:
stack.push(ch) # 进栈
else:
if stack.is_empty():
return False
elif stack.get_top() == match[ch]: # 取栈顶
stack.pop()
else:
return False
if stack.is_empty():
return True
else:
return False
print(brace_match('([{()}])['))
队列
队列(Queue)是一个数据集合,仅允许在列表的一端进行插入,另一端进行删除。
进行插入的一端称为队尾(rear),插入动作称为进队或入队
进行删除的一端称为队头(front),删除动作称为出队
队列的性质:先进先出(First-in, First-out)
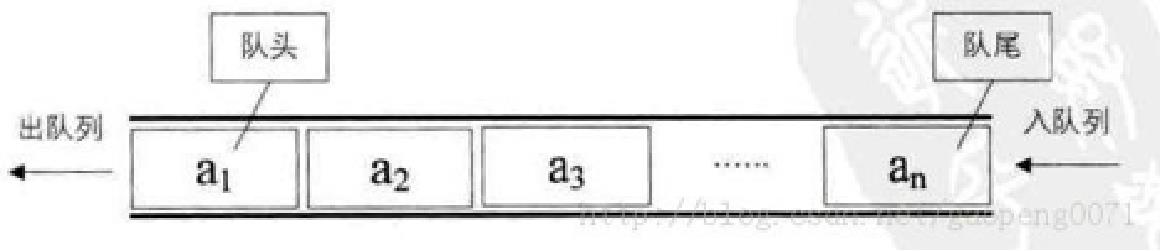
双向队列
双向队列的两端都支持进队和出队操作。双向队列的基本操作:
队首进队
队首出队
队尾进队
队尾出队
队列能否用列表简单实现?为什么?答:能实现,但是太浪费资源,最好采用环形队列实现。
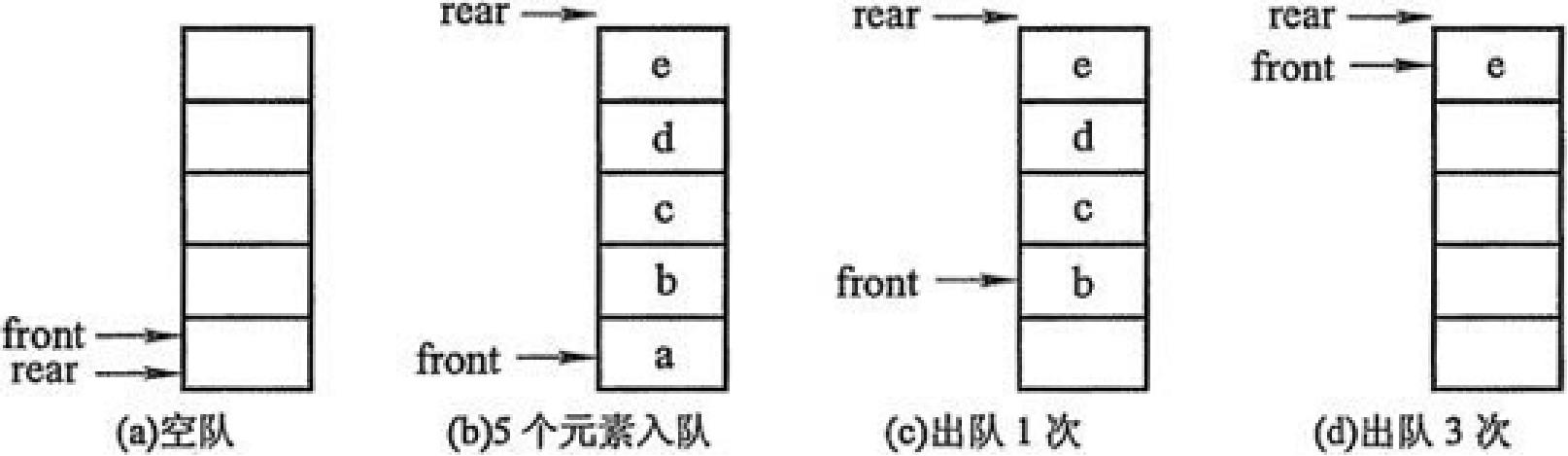
队列的实现方式
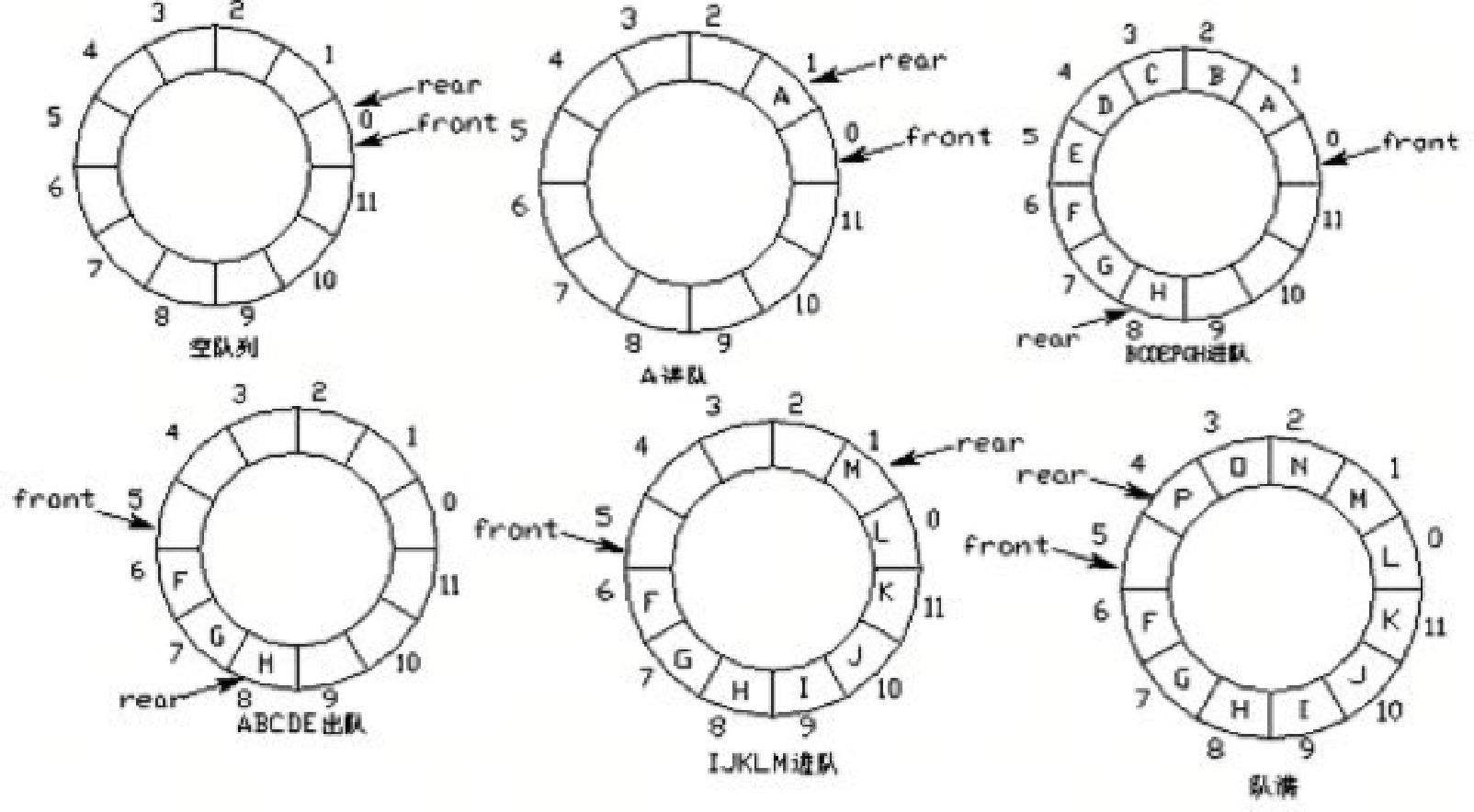
环形队列:当队尾指针front == Maxsize - 1时,再前进一个位置就自动到0.
队首指针前进1:front = (front + 1) % MaxSize
队尾指针前进1:rear = (rear + 1) % MaxSize
队空条件:rear == front
队满条件:(rear + 1) % MaxSize == front
# 基于环形队列实现
class Queue:
def __init__(self, size=100):
self.queue = [0 for _ in range(size)]
self.size = size
self.rear = 0 # 队尾指针
self.front = 0 # 队首指针
def push(self, element):
if not self.is_filled():
self.rear = (self.rear + 1) % self.size
self.queue[self.rear] = element
else:
raise IndexError('Queue is filled')
def pop(self):
if not self.is_empty():
self.front = (self.front + 1) % self.size
return self.queue[self.front]
else:
raise IndexError('Queue is empty')
# 判断对空
def is_empty(self):
return self.rear == self.front
# 判断堆满
def is_filled(self):
return (self.rear + 1) % self.size == self.front
q = Queue(3)
for i in range(2):
q.push(i)
print(q.pop())
q.push(4)
队列的内置模块
from collections import deque # 双向队列也可用于单向队列
q = deque()#创建队列
q.append(1) # 队尾进队
q.popleft() # 对首出队
q.appendleft(1) # 双向队列对首进队
q.pop() # 双向队列队尾出队
栈的应用-迷宫问题
给一个二维列表,表示迷宫(0表示通道,1表示围墙)。给出算法,求一条走出迷宫的路径。
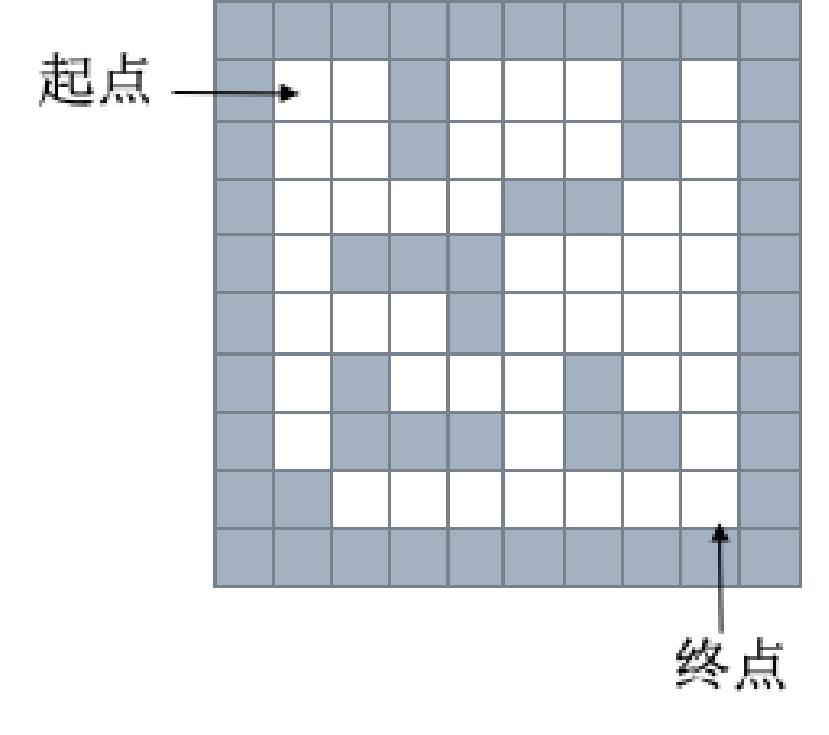
栈——深度优先搜索(回溯法)
思路:从一个节点开始,任意找下一个能走的点,当找不到能走的点时,退回上一个点寻找是否有其他方向的点。
使用栈存储当前路径。
maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
]
dirs = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y - 1),
lambda x, y: (x, y + 1),
] # 四个方向
def maze_path(x1, y1, x2, y2):
stack = []
stack.append((x1, y1))
while len(stack) > 0:
curNode = stack[-1]
if curNode[0] == x2 and curNode[1] == y2:
for p in stack:
print(p)
return True
for dir in dirs:
nextNode = dir(curNode[0], curNode[1])
if maze[nextNode[0]][nextNode[1]] == 0:
stack.append(nextNode)
maze[nextNode[0]][nextNode[1]] = 2
break
else:
maze[nextNode[0]][nextNode[1]] = 2
stack.pop()
else:
print('没有路')
return False
maze_path(1, 1, 8, 8)
队列应用-迷宫问题
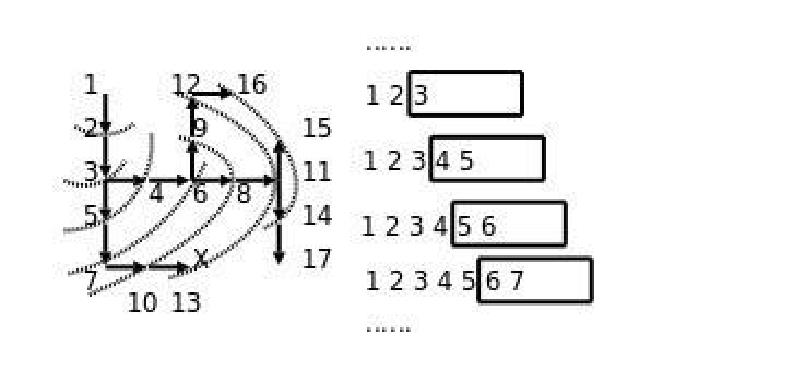
队列——广度优先搜索
思路:从一个节点开始,寻找所有接下来能继续走的点,继续不断寻找,直到找到出口。使用队列存储当前正在考虑的节点。
from collections import deque
maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
]
dirs = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y - 1),
lambda x, y: (x, y + 1),
] # 四个方向
def print_r(path):
real_path = []
i = len(path) - 1
while i >= 0:
real_path.append(path[i][0:2])
i = path[i][2]
real_path.reverse()
for node in real_path:
print(node)
def maze_path_queue(x1, y1, x2, y2):
queue = deque()
path = []
queue.append((x1, y1, -1))
while len(queue) > 0: # 当队列不空时循环
cur_node = queue.popleft()
path.append(cur_node)
if cur_node[0] == x2 and cur_node[1] == y2: # 到达终点
print_r(path)
return True
for dir in dirs:
next_node = dir(cur_node[0], cur_node[1])
if maze[next_node[0]][next_node[1]] == 0:
queue.append((next_node[0], next_node[1], len(path) - 1))
maze[next_node[0]][next_node[1]] = 2 # 标记为已走过
return False
maze_path_queue(1,1,8,8)
链表
链表是由一系列节点组成的元素集合。每个节点包含两部分,数据域item和指向下一个节点的指针next。通过节点之间的相互连接,最终串联成一个链表。

# 链表基本用法
class Node:
def __init__(self, item):
self.item = item
self.next = None
a = Node(1)
b = Node(2)
c = Node(3)
a.next = b
b.next = c
print(a.next) # <__main__.Node object at 0x0000016AC6159CC0>
print(a.next.item) # 2
print(a.next.next.item) # 3
链表创建和遍历
创建方式有两种:头插法和尾插法

class Node:
def __init__(self, item):
self.item = item
self.next = None
def create_linklist_head(li):
"""头插法创建链表"""
head = Node(li[0]) # 头节点
for element in li[1:]:
node = Node(element)
node.next = head
head = node
return head
def create_linklist_tail(li):
"""尾插法创建链表"""
head = Node(li[0])
tail = head
for element in li[1:]:
node = Node(element)
tail.next = node # 这两步在赋值
tail = node
return head
def print_linklist(lk):
"""遍历链表"""
while lk:
print(lk.item, end=',')
lk = lk.next
lk = create_linklist_tail([1, 2, 3]) # 正序打印
lk = create_linklist_head([1, 2, 3]) # 倒序打印
print_linklist(lk)
链表插入和删除
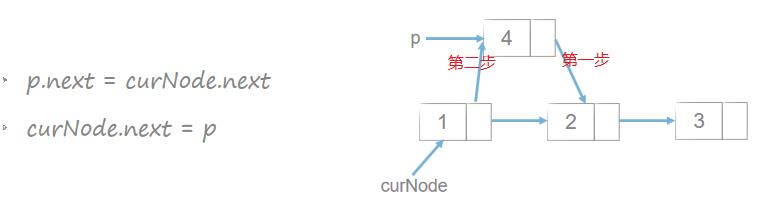
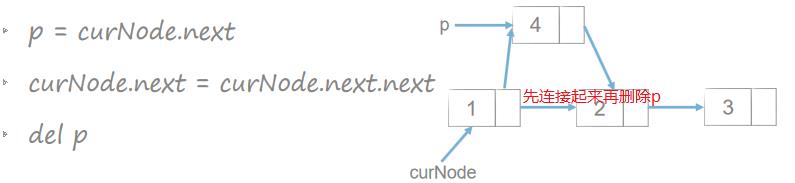
双链表
双链表的每个节点有两个指针:一个指向后一个节点,另一个指向前一个节点。
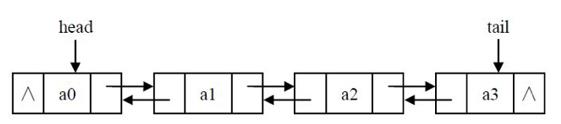
双链表创建和遍历
class Node:
def __init__(self, item=None):
self.item = item
self.next = None
self.prior=None
双链表插入和删除
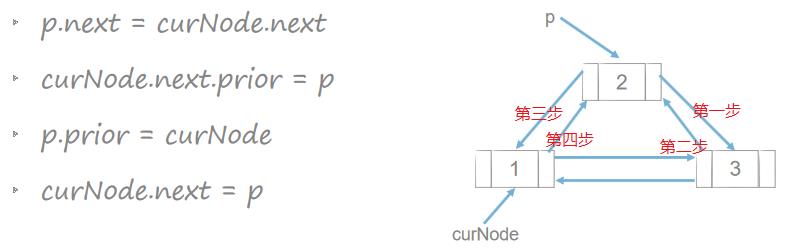
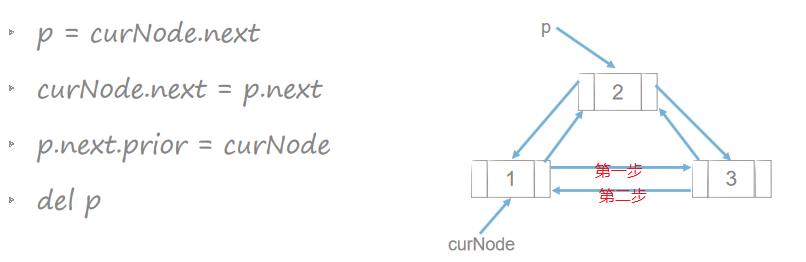
顺序表与链表复杂度分析
按元素值查找:O(n)与O(n)
按下标查找:O(1)与O(n)
在某元素后插入:O(n)与O(1)
删除某元素:O(n)与O(1)
链表在插入和删除的操作上明显快于顺序表
链表的内存可以更灵活的分配——试利用链表重新实现栈和队列
链表这种链式存储的数据结构对树和图的结构有很大的启发性
哈希表
哈希表一个通过哈希函数来计算数据存 储位置的数据结构,通常支持如下操作:
- insert(key, value):插入键值对(key,value)
- get(key):如果存在键为key的键值对则返回其value,否则返回空值
- delete(key):删除键为key的键值对
直接寻址表
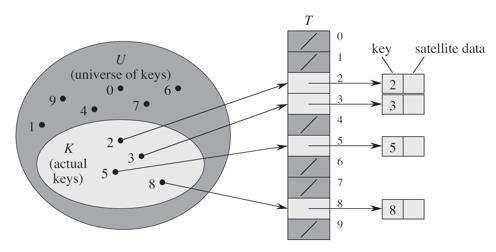
当关键字的全域U比较小时,直接寻址是一种简单而有效的方法。
直接寻址技术缺点:
- 当域U很大时,需要消耗大量内存,很不实际
- 如果域U很大而实际出现的key很少,则大量空间被浪费
- 无法处理关键字不是数字的情况
哈希
直接寻址表:key为k的元素放到k位置上
改进直接寻址表:哈希(Hashing)
构建大小为m的寻址表T,key为k的元素放到h(k)位置上,h(k)是一个函数,其将域U映射到表T[0,1,...,m-1]
哈希表(Hash Table,又称为散列表),是一种线性表的存储结构。哈希表由一个直接寻址表和一个哈希函数组成。哈希函数h(k)将元素关键字k作为自变量,返回元素的存储下标。
假设有一个长度为7的哈希表,哈希函数h(k)=k%7。元素集合{14,22,3,5}的存储方式如下图。

由于哈希表的大小是有限的,而要存储的值的总数量是无限的,因此对于任何哈希函数,都会出现两个不同元素映射到同一个位置上的情况,这种情况叫做哈希冲突。比如h(k)=k%7, h(0)=h(7)=h(14)=...
解决哈希冲突-开放寻址法
开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值。
线性探查:如果位置i被占用,则探查i+1, i+2,……
二次探查:如果位置i被占用,则探查i+1^2,i-1^2,i+2^2,i-2^2,……
二度哈希:有n个哈希函数,当使用第1个哈希函数h1发生冲突时,则尝试使用h2,h3,……
解决哈希冲突-拉链法
拉链法:哈希表每个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后。
常见哈希函数:
除法哈希法:h(k) = k % m
乘法哈希法:h(k) = floor(m(Akey%1))
全域哈希法:ha,b(k) = ((a*key + b) mod p) mod m a,b=1,2,...,p-1
class LinkList:
class Node:
def __init__(self, item=None):
self.item = item
self.next = None
class LinkListIterator:
def __init__(self, node):
self.node = node
def __next__(self):
if self.node:
cur_node = self.node
self.node = cur_node.next
return cur_node.item
else:
raise StopIteration
def __iter__(self):
return self
def __init__(self, iterable=None):
self.head = None
self.tail = None
if iterable:
self.extend(iterable)
def append(self, obj):
s = LinkList.Node(obj)
if not self.head:
self.head = s
self.tail = s
else:
self.tail.next = s
self.tail = s
def extend(self, iterable):
for obj in iterable:
self.append(obj)
def find(self, obj):
for n in self:
if n == obj:
return True
else:
return False
def __iter__(self):
return self.LinkListIterator(self.head)
def __repr__(self):
return "<<" + ",".join(map(str, self)) + ">>"
lk = LinkList([1, 2, 3, 4, 5])
print(lk)
for element in lk:
print(element)
# 类似于集合的结构
class HashTable:
def __init__(self, size=101):
self.size = size
self.T = [LinkList() for i in range(self.size)]
def h(self, k):
return k % self.size
def insert(self, k):
i = self.h(k)
if self.find(k):
print("Duplicated Insert.")
else:
self.T[i].append(k)
def find(self, k):
i = self.h(k)
return self.T[i].find(k)
ht = HashTable()
ht.insert(0)
ht.insert(1)
ht.insert(3)
ht.insert(102)
ht.insert(508)
print(",".join(map(str, ht.T)))
print(ht.find(203))
哈希应用
字典与集合、MD5算法、验证文件、比特币
二叉树
二叉树的链式存储:将二叉树的节点定义为一个对象,节点之间通过类似链表的链接方式来连接。
二叉树的遍历

from collections import deque
class BiTreeNode:
def __init__(self, data):
self.data = data
self.lchild = None # 左孩子
self.rchild = None # 右孩子
a = BiTreeNode("A")
b = BiTreeNode("B")
c = BiTreeNode("C")
d = BiTreeNode("D")
e = BiTreeNode("E")
f = BiTreeNode("F")
g = BiTreeNode("G")
e.lchild = a
e.rchild = g
a.rchild = c
c.lchild = b
c.rchild = d
g.rchild = f
root = e
print(root.lchild.rchild.data)
def pre_order(root):
"""前序遍历函数"""
if root: # 如果不为空
print(root.data, end=",") # 先访问自己
pre_order(root.lchild) # 再访问左子树
pre_order(root.rchild) # 最后访问右子树
pre_order(root) # E,A,C,B,D,G,F,
def in_order(root):
"""中序遍历函数"""
if root:
in_order(root.lchild)
print(root.data, end=',')
in_order(root.rchild)
in_order(root) # A,B,C,D,E,G,F,
def post_order(root):
"""后序遍历函数"""
if root:
post_order(root.lchild)
post_order(root.rchild)
print(root.data, end=',')
post_order(root) # B,D,C,A,F,G,E,
def level_order(root):
"""层次遍历函数"""
queue = deque()
queue.append(root)
while len(queue) > 0:
node = queue.popleft()
print(node.data, end=',')
if node.lchild:
queue.append(node.lchild)
if node.rchild:
queue.append(node.rchild)
level_order(root) # E,A,G,C,F,B,D,
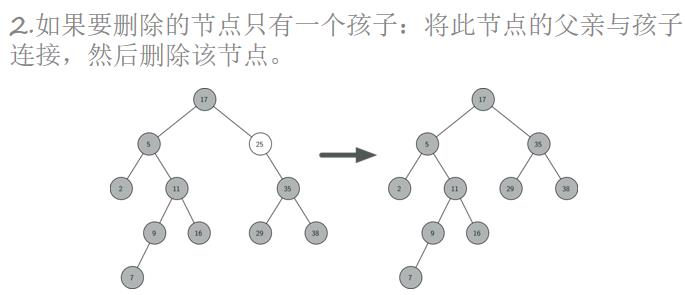
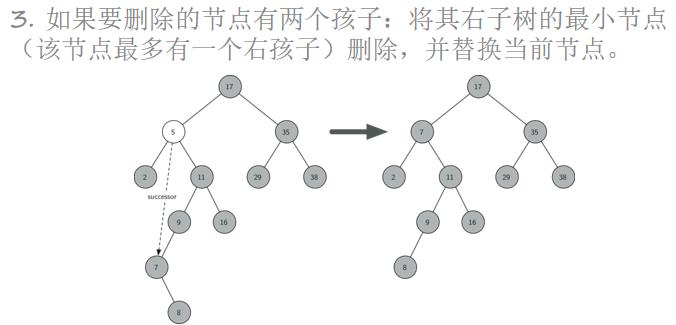
二叉搜索树的插入、查找、删除操作
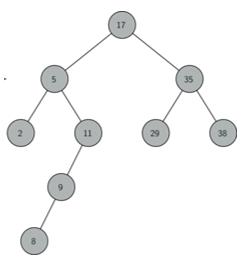
二叉搜索树是一颗二叉树且满足性质:设x是二叉树的一个节点。如果y是x左子树的一个节点,那么y.key ≤ x.key;如果y是x右子树的一个节点,那么y.key ≥ x.key。
二叉搜索树的操作:查询、插入、删除
class BiTreeNode:
def __init__(self, data):
self.data = data
self.lchild = None # 左孩子
self.rchild = None # 右孩子
self.parent = None
class BST:
def __init__(self, li=None):
self.root = None
if li:
for val in li:
self.insert_no_rec(val)
def insert(self, node, val):
"""递归插入函数"""
if not node:
node = BiTreeNode(val)
elif val < node.data:
node.lchild = self.insert(node.lchild, val)
node.lchild.parent = node
elif val > node.data:
node.rchild = self.insert(node.rchild, val)
node.rchild.parent = node
return node
def insert_no_rec(self, val):
"""非递归插入函数"""
p = self.root
if not p: # 空树
self.root = BiTreeNode(val)
return
while True:
if val < p.data:
if p.lchild:
p = p.lchild
else:
p.lchild = BiTreeNode(val)
p.lchild.parent = p
return
elif val > p.data:
if p.rchild:
p = p.rchild
else:
p.rchild = BiTreeNode(val)
p.rchild.parent = p
return
else:
return
def query(self, node, val):
"""递归查询函数"""
if not node:
return None
if node.data < val:
return self.query(node.rchild, val)
elif node.data > val:
return self.query(node.lchild, val)
else:
return node
def query_no_rec(self, val):
"""非递归查询函数"""
p = self.root
while p:
if p.data < val:
p = p.rchild
elif p.data > val:
p = p.lchild
else:
return p
return None
def pre_order(self, root):
"""前序遍历函数"""
if root: # 如果不为空
print(root.data, end=",") # 先访问自己
self.pre_order(root.lchild) # 再访问左子树
self.pre_order(root.rchild) # 最后访问右子树
def in_order(self, root):
"""中序遍历函数"""
if root:
self.in_order(root.lchild)
print(root.data, end=',')
self.in_order(root.rchild)
def post_order(self, root):
"""后序遍历函数"""
if root:
self.post_order(root.lchild)
self.post_order(root.rchild)
print(root.data, end=',')
def __remove_node_1(self, node):
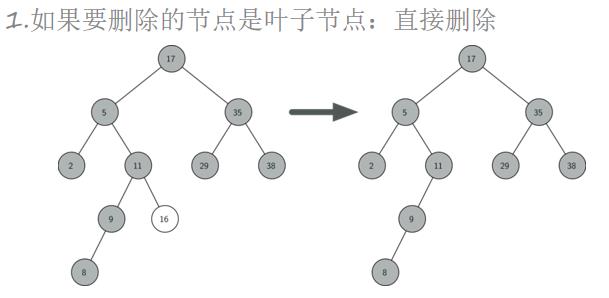
# 情况一:node是叶子节点
if not node.parent:
self.root = None
if node == node.parent.lchild:
node.parent.lchild = None
node.parent = None
else:
node.parent.rchild = None
def __remove_node_21(self, node):
# 情况2.1:node只有一个左孩子
if not node.parent: # 根节点
self.root = node.lchild
node.lchild.parent = None
elif node == node.parent.lchild:
node.parent.lchild = node.lchild
node.lchild.parent = node.parent
else:
node.parent.rchild = node.lchild
node.lchild.parent = node.parent
def __remove_node_22(self, node):
# 情况2.2:node只有一个右孩子
if not node.parent:
self.root = node.rchild
elif node == node.parent.lchild:
node.parent.lchild = node.rchild
node.rchild.parent = node.parent
else:
node.parent.rchild = node.rchild
node.rchild.parent = node.parent
def delete(self, val):
"""删除函数"""
if self.root:
node = self.query_no_rec(val)
if not node:
return False
if not node.lchild and not node.rchild:
self.__remove_node_1(node)
elif not node.rchild:
self.__remove_node_21(node)
elif not node.lchild:
self.__remove_node_22(node)
else:
# 情况3:两个孩子都有
min_node = node.rchild
while min_node.lchild:
min_node = min_node.lchild
node.data = min_node.data
# 删除min_node
if min_node.rchild:
self.__remove_node_22(min_node)
else:
self.__remove_node_1(min_node)
tree = BST([4, 6, 7, 9, 2, 1, 3, 5, 8])
tree.in_order(tree.root)
tree.delete(4)
tree.in_order(tree.root)
平均情况下,二叉搜索树进行搜索的时间复杂度为O(nlgn)。
最坏情况下,二叉搜索树可能非常偏斜,如接近线性结构时。
解决方案:
- 随机化插入
- AVL树
AVL树
AVL树:AVL树是一棵自平衡的二叉搜索树。
AVL树具有以下性质:
-
根的左右子树的高度之差的绝对值不能超过1
-
根的左右子树都是平衡二叉树
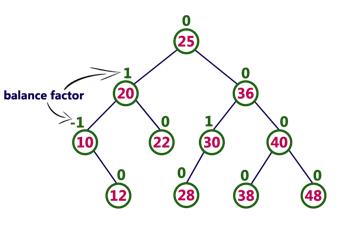
AVL树的插入操作:
插入一个节点可能会破坏AVL树的平衡,可以通过旋转操作来进行修正。
插入一个节点后,只有从插入节点到根节点的路径上的节点的平衡可能被改变。我们需要找出第一个破坏了平衡条件的节点,称之为K。K的两颗子树的高度差2。
不平衡的出现可能有4种情况:
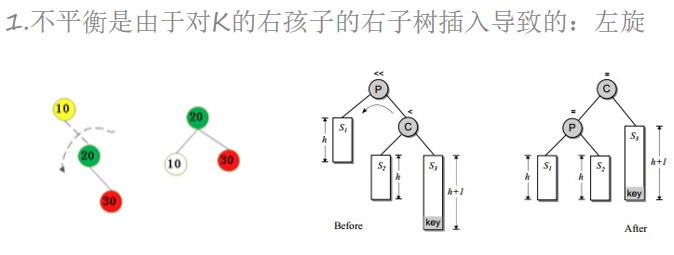
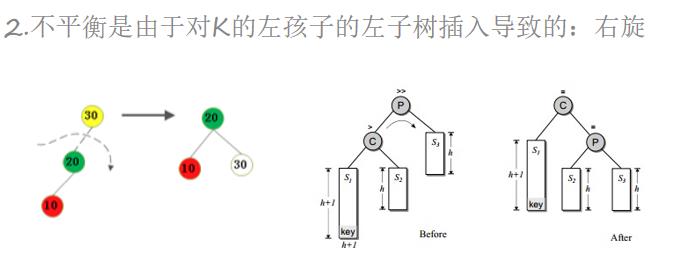
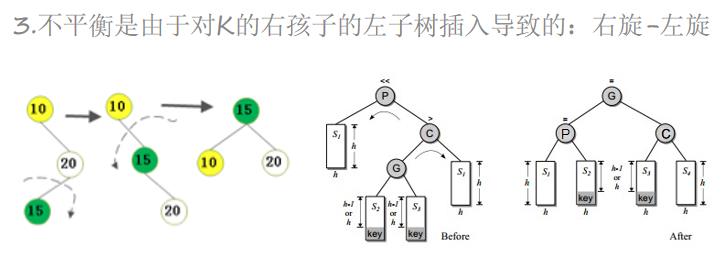
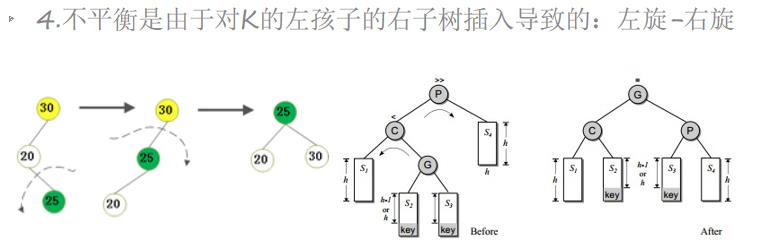
from bst import BiTreeNode, BST #需要导入二叉树中BTS类
class AVLNode(BiTreeNode):
def __init__(self, data):
BiTreeNode.__init__(self, data)
self.bf = 0
class AVLTree(BST):
def __init__(self, li=None):
BST.__init__(self, li)
def rotate_left(self, p, c):
s2 = c.lchild
p.rchild = s2
if s2:
s2.parent = p
c.lchild = p
p.parent = c
p.bf = 0
c.bf = 0
return c
def rotate_right(self, p, c):
s2 = c.rchild
p.lchild = s2
if s2:
s2.parent = p
c.rchild = p
p.parent = c
p.bf = 0
c.bf = 0
return c
def rotate_right_left(self, p, c):
g = c.lchild
s3 = g.rchild
c.lchild = s3
if s3:
s3.parent = c
g.rchild = c
c.parent = g
s2 = g.lchild
p.rchild = s2
if s2:
s2.parent = p
g.lchild = p
p.parent = g
# 更新bf
if g.bf > 0:
p.bf = -1
c.bf = 0
elif g.bf < 0:
p.bf = 0
c.bf = 1
else: # 插入的是g
p.bf = 0
c.bf = 0
return g
def rotate_left_right(self, p, c):
g = c.rchild
s2 = g.lchild
c.rchild = s2
if s2:
s2.parent = c
g.lchild = c
c.parent = g
s3 = g.rchild
p.lchild = s3
if s3:
s3.parent = p
g.rchild = p
p.parent = g
# 更新bf
if g.bf < 0:
p.bf = 1
c.bf = 0
elif g.bf > 0:
p.bf = 0
c.bf = -1
else:
p.bf = 0
c.bf = 0
return g
def insert_no_rec(self, val):
# 1. 和BST一样,插入
p = self.root
if not p: # 空树
self.root = AVLNode(val)
return
while True:
if val < p.data:
if p.lchild:
p = p.lchild
else: # 左孩子不存在
p.lchild = AVLNode(val)
p.lchild.parent = p
node = p.lchild # node 存储的就是插入的节点
break
elif val > p.data:
if p.rchild:
p = p.rchild
else:
p.rchild = AVLNode(val)
p.rchild.parent = p
node = p.rchild
break
else: # val == p.data
return
# 2. 更新balance factor
while node.parent: # node.parent不空
if node.parent.lchild == node: # 传递是从左子树来的,左子树更沉了
# 更新node.parent的bf -= 1
if node.parent.bf < 0: # 原来node.parent.bf == -1, 更新后变成-2
# 做旋转
# 看node哪边沉
g = node.parent.parent # 为了连接旋转之后的子树
x = node.parent # 旋转前的子树的根
if node.bf > 0:
n = self.rotate_left_right(node.parent, node)
else:
n = self.rotate_right(node.parent, node)
# 记得:把n和g连起来
elif node.parent.bf > 0: # 原来node.parent.bf = 1,更新之后变成0
node.parent.bf = 0
break
else: # 原来node.parent.bf = 0,更新之后变成-1
node.parent.bf = -1
node = node.parent
continue
else: # 传递是从右子树来的,右子树更沉了
# 更新node.parent.bf += 1
if node.parent.bf > 0: # 原来node.parent.bf == 1, 更新后变成2
# 做旋转
# 看node哪边沉
g = node.parent.parent # 为了连接旋转之后的子树
x = node.parent # 旋转前的子树的根
if node.bf < 0: # node.bf = 1
n = self.rotate_right_left(node.parent, node)
else: # node.bf = -1
n = self.rotate_left(node.parent, node)
# 记得连起来
elif node.parent.bf < 0: # 原来node.parent.bf = -1,更新之后变成0
node.parent.bf = 0
break
else: # 原来node.parent.bf = 0,更新之后变成1
node.parent.bf = 1
node = node.parent
continue
# 链接旋转后的子树
n.parent = g
if g: # g不是空
if x == g.lchild:
g.lchild = n
else:
g.rchild = n
break
else:
self.root = n
break
tree = AVLTree([9, 8, 7, 6, 5, 4, 3, 2, 1])
tree.pre_order(tree.root)
print("")
tree.in_order(tree.root)
二叉树搜索的应用
B树(B-Tree):B树是一棵自平衡的多路搜索树。常用于数据库的索引。
贪心算法
定义:在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。 贪⼼算法并不保证会得到最优解,但是在某些问题上贪⼼算法的解就是最优解。要会判断⼀个问题能否⽤贪⼼算法来计算。
找零问题
假设商店⽼板需要找零n元钱,钱币的⾯额有:100元、50元、20元、5元、1元,如何找零使得所需钱币的数量最少?
# 思路:
# 1.先生成零钱列表x和找零张数列表m
# 2.然后遍历零钱列表
# 3.利用需要找零钱数和零钱列表取整取余分别得出零钱张数和剩余钱数
x = [100, 50, 20, 5, 1] # 零钱列表
def change_money(x, y):
m = [0 for _ in range(len(x))] # 找零张数列表
for i, money in enumerate(x):
m[i] = y // money # 找零张数
y = y % money # 剩余钱数
return m
print(change_money(x, 380))
背包问题
⼀个⼩偷在某个商店发现有n个商品,第i个商品价值vi元,重wi千克。他希望拿⾛的价值尽量⾼,但他的背包最多只能容纳W千克的东⻄。他应该拿⾛哪些商品?
-
0-1背包:对于⼀个商品,⼩偷要么把它完整拿⾛,要么留下。不能只拿⾛⼀部分,或把⼀个商品拿⾛多次。(商品为⾦条)
-
分数背包:对于⼀个商品,⼩偷可以拿⾛其中任意⼀部分。(商品为⾦砂)
举例:
商品1:v1=60 w1=10
商品2:v2=100 w2=20
商品3:v3=120 w3=30
背包容量:W=50
对于0-1背包和分数背包,贪⼼算法是否都能得到最优解?为什么?
# 思路:
# 1.先获取商品元组列表且按单价降序排序和商品数量列表
# 2.再遍历商品信息列表
# 2.1如果背包重量大于等于商品重量,商品数量为1
# 2.2如果背包重量小于商品重量,商品数量为背包剩余总量除以商品重量
# 3.然后得出剩余商品重量
# 4.最后得出商品总价
goods = [(60, 10), (100, 20), (120, 30)] # 商品元组列表(价值,重量)
goods.sort(key=lambda x: x[0] / x[1], reverse=True) # 按商品单价降序排序
def fractional_backpack(goods, w): # w表示背包总量
m = [0 for _ in range(len(goods))] # 商品数量列表
total_v = 0 # 商品总价
for i, (price, weight) in enumerate(goods):
if w >= weight:
m[i] = 1 # m[i]表示商品数量
w -= weight # 剩余背包重量
total_v += price
else:
m[i] = w / weight
w = 0
total_v += m[i] * price
break
return m, total_v
print(fractional_backpack(goods, 40))
数字拼接问题
有n个⾮负整数,将其按照字符串拼接的⽅式拼接为⼀个整数,如何拼接可以使得得到的整数最⼤? 例:32,94,128,1286,6,71可以拼接除的最⼤整数为 94716321286128
# 思路
# 1.先将列表整型元素转化成字符串元素
# 2.两个字符串拼接长度一样且比较大小
from functools import cmp_to_key
li = [32, 94, 128, 1286, 6, 71]
def xy_cmp(x, y):
if x + y < y + x:
return 1
elif x + y > y + x:
return -1
else:
return 0
def number_join(li):
li = list(map(str, li)) # 将列表中每一个元素转化成字符串形式
print(li) # ['32', '94', '128', '1286', '6', '71']
li.sort(key=cmp_to_key(xy_cmp)) # 对列表元素两两拼接比较,若前者比后者大则位置不变,反之。
print(li) # ['94', '71', '6', '32', '1286', '128']
return ''.join(li)
print(number_join(li))
# 注:lt小于;gt大于;eq等于;le小于等于;ge大于等于
活动选择问题
假设有n个活动,这些活动要占⽤同⼀⽚场地,⽽场地在某时 刻只能供⼀个活动使⽤。每个活动都有⼀个开始时间si和结束时间fi(题⽬中时间以整数 表示),表示活动在[si, fi)区间占⽤场地。 问:安排哪些活动能够使该场地举办的活动的个数最多?
i|1|2|3|4|5|6|7|8|9|10|11
:-😐:-😐:-😐:-😐:-😐:-😐:-😐:-😐:-😐:-😐:-😐:-😐:-😐
si|1|3|0|5|3|5|6|8|8|2|12
fi|4|5|6|7|9|9|10|11|12|14|16
贪⼼结论:最先结束的活动⼀定是最优解的⼀部分。
证明:假设a是所有活动中最先结束的活动,b是最优解中最先结束的活动。
- 如果a=b,结论成⽴。
- 如果a≠b,则b的结束时间⼀定晚于a的结束时间,则此时⽤a替换掉最优解中的b,a⼀定不与最优解中的其他活动时间重叠,因此替换后的解也是最优解。
# 思路
#先生成列表[(活动开始时间,结束时间)]
#再假定最后结束活动的元素
#最后一个活动的开始时间大于等于当前活动的结束时间
activities = [(1, 4), (3, 5), (0, 6), (5, 7), (3, 9), (5, 9), (6, 10), (8, 11), (8, 12), (2, 14), (12, 16)]
activities.sort(key=lambda x: x[1]) # 保证活动是按照结束时间排好序的
def activity_selection(activities):
res = [activities[0]] # 当前活动
for i in range(1, len(activities)):
if activities[i][0] >= res[-1][1]: # 最后一个活动的开始时间大于等于当前活动的结束时间
# 不冲突
res.append(activities[i])
return res
print(activity_selection(activities))
动态规划
从斐波那契数列看动态规划
斐波那契数列:
练习:使⽤递归和⾮递归的⽅法来求解斐波那契数列的第n项
# 子问题重复计算
def fibnacci(n):
if n == 1 or n == 2:
return 1
else:
return fibnacci(n - 1) + fibnacci(n - 2)
print(fibnacci(10))
# 动态规划(DP)的思想:递归式+重复子问题
def fibnacci_no_recurision(n):
f = [0, 1, 1]
if n > 2:
for i in range(n - 2):
num = f[-1] + f[-2]
f.append(num)
print(f) # [0, 1, 1, 2, 3, 5]
return f[n]
print(fibnacci_no_recurision(5))
钢条切割问题
某公司出售钢条,出售价格与钢条⻓度之间的关系如下表:
| 长度i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 价格Pi | 1 | 5 | 8 | 9 | 10 | 17 | 17 | 20 | 24 | 30 |
问题:现有⼀段⻓度为n的钢条和上⾯的价格表,求切割钢条⽅案,使得总收益最⼤。
假如长度为4的钢条的所有切割方案中,按2和2切割方案最优,总收益为10,思考:长度为n的钢条的不同切割方案有几种?答:2的n-1次方。
| 长度i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 最优收益r[i] | 0 | 1 | 5 | 8 | 10 | 13 | 17 | 18 | 22 | 25 | 30 |
递归式
设⻓度为n的钢条切割后最优收益值为r[n],可以得出递推式:
-
第一个参数Pn表示不切割
-
其他n-1个参数分别表示另外n-1种不同切割方案,对方案i=1,2...,n-1
- 将钢条切割为长度为i和n-i两段。
- 方案i的收益为切割两段的的最优收益之和。
-
考察所有的i,选择其中收益最大的方案。
最优子结构
-
可以将求解规模为n的原问题,划分为规模更⼩的⼦问题:完成⼀次切割后,可以将产⽣的两段钢条看成两个独⽴的钢条切个问题。
-
组合两个⼦问题的最优解,并在所有可能的两段切割⽅案中选取组合收益最⼤的,构成原问题的最优解。
-
钢条切割满⾜最优⼦结构:问题的最优解由相关⼦问题的最优解组合⽽成,这些⼦问题可以独⽴求解。
-
钢条切割问题还存在更简单的递归求解方法:
-
从钢条的左边切割下⻓度为i的⼀段,只对右边剩下的⼀段继续进⾏切割,左边的不再切割。
-
递推式简化为:
\[r_n=\max_{1\leq{i}\leq{n}}(p_i+r_{n-i}) \] -
不做切割的⽅案就可以描述为:左边⼀段⻓度为n,收益为pn,剩余⼀段⻓度为0,收益为r0=0。
-
自顶向下递归实现
import time
def cal_time(func):
def wrapper(*args, **kwargs):
t1 = time.time()
res = func(*args, **kwargs)
t2 = time.time()
print(f'{func.__name__} running time:{t2 - t1} secs')
return res
return wrapper
p = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30] # 价格表,如长度为1价格为1
def cut_rod_recurision_1(p, n):
if n == 0:
return 0
else:
res = p[n]
for i in range(1, n):
res = max(res, cut_rod_recurision_1(p, i) + cut_rod_recurision_1(p, n - i))
return res
@cal_time
def c1(p, n):#递归加装饰器报错
return cut_rod_recurision_1(p, n)
def cut_rod_recurision_2(p, n):
if n == 0:
return 0
else:
res = 0
for i in range(1, n + 1):
res = max(res, p[i] + cut_rod_recurision_2(p, n - i)) # 自己、不切割部分、切割部分
return res
@cal_time
def c2(p, n):
return cut_rod_recurision_2(p, n)
print(c1(p, 9))
print(c2(p, 9))
# 为何自顶向下递归实现的效率会这么差?时间复杂度O(2^n)
自底向上动态规划解法
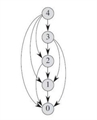
递归算法由于重复求解相同⼦问题,效率极低
动态规划的思想:
- 每个⼦问题只求解⼀次,保存求解结果
- 之后需要此问题时,只需查找保存的结果
import time
def cal_time(func):
def wrapper(*args, **kwargs):
t1 = time.time()
res = func(*args, **kwargs)
t2 = time.time()
print(f'{func.__name__} running time:{t2 - t1} secs')
return res
return wrapper
p = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30] # 价格表,如长度为1价格为1
def cut_rod_recurision_2(p, n):
if n == 0:
return 0
else:
res = 0
for i in range(1, n + 1):
res = max(res, p[i] + cut_rod_recurision_2(p, n - i)) # 自己、不切割部分、切割部分
return res
@cal_time
def c2(p, n):
return cut_rod_recurision_2(p, n)
@cal_time
def cut_rod_dp(p, n):
r = [0]
for i in range(1, n + 1):
res = 0
for j in range(1, i + 1):
res = max(res, p[j] + r[i - j])
r.append(res)
return r[n]
print(c2(p, 9))
print(cut_rod_dp(p, 9))
# 时间复杂度为O(n^2)
重构解
如何修改动态规划算法,使其不仅输出最优解,还输出最优切割⽅案?
-
对每个⼦问题,保存切割⼀次时左边切下的⻓度
长度i 1 2 3 4 5 6 7 8 9 10 价格Pi 1 5 8 9 10 17 17 20 24 30 长度i 0 1 2 3 4 5 6 7 8 9 10 最优收益r[i] 0 1 5 8 10 13 17 18 22 25 30 切割一次左边长度s[i] 0 1 2 3 2 2 6 1 2 3 10
def cut_rod_extend(p, n): # 重构解
r = [0]
s = [0]
for i in range(1, n + 1):
res_r = 0 # 价格的最大值
res_s = 0 # 价格最大值对应方案的左边不切割部分的长度
for j in range(1, i + 1):
if p[j] + r[i - j] > res_r:
res_r = p[j] + r[i - j]
res_s = j
r.append(res_r)
s.append(res_s)
return r[n], s
def cut_rod_solution(p, n): # 具体切割方案
r, s = cut_rod_extend(p, n)
lis = []
while n > 0:
lis.append(s[n])
n -= s[n]
return lis
p = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30]
print(cut_rod_extend(p,9))
print(cut_rod_solution(p, 9))
自顶向下和自底向上
动态规划的实现分为两种:递归和迭代。
递归一般是自顶向下,依赖于子问题优化函数的结果,只有子问题完全求出,也就是子问题的递归返回结果,原问题才能求解。
迭代就是巧妙的安排求解顺序,从最小的子问题开始,自下而上求解。每次求新的问题时,子问题的解已经计算出来了。
用两个简单的例子说明一下:
某日小明上数学课,他的老师给了很多个不同的直角三角板让小明用尺子去量三角板的三个边,并将长度记录下来。两个小时过去,小明完成任务,把数据拿给老师。老师给他说,还有一个任务就是观察三条边之间的数量关系。又是两个小时,聪明的小明连蹦带跳走进了办公室,说:“老师,我找到了,三条边之中有两条,它们的平方和约等于另外一条的平方。”老师拍拍小明的头,“你今天学会了一个定理,勾股定理。它就是说直角三角形有两边平方和等于第三边的平方和”。
另一个故事,某日老师告诉小明“今天要教你一个定理,勾股定理。”小明说,“什么是勾股定理呢?”“勾股定理是说,直角三角形中有两条边的平方和等于第三边的平方。”然后老师给了一大堆直角三角板给小明,让他去验证。两个小时后,小明告诉老师定理是正确的.
两个故事刚好是语法分析里面对应的两个方法:第一个故事说的是自底向上的分析方法,第二个故事说的是自顶而下的分析方法。
在三维建模软件里也存在这个问题:
自底向上就是先建零件图,然后去组装装配图!
自顶向下就是先建装配图,再在装配图中建零件图!
或者先建立一个总装配体的零件图,然后切割成各个零件图!
两种分析方法的根本区别是:自底向上的分析,是从具体到抽象;自顶向下的分析,是从抽象到具体。两种分析思路恰恰又是哲学思考问题的两大方向。可见计算机科学与哲学也是相通的.
动态优化关键特征
什么问题可以使⽤动态规划⽅法?
-
最优⼦结构
-
原问题的最优解中涉及多少个⼦问题
-
在确定最优解使⽤哪些⼦问题时,需要考虑多少种选择
-
-
重叠⼦问题
最长公共子序列
⼀个序列的⼦序列是在该序列中删去若⼲元素后得 到的序列。 例:“ABCD”和“BDF”都是“ABCDEFG”的⼦序列,空序列是任意序列的子序列
最⻓公共⼦序列(LCS)问题:给定两个序列X和Y,求X和Y⻓度最⼤的公共⼦序列。 例:X="ABBCBDE" Y="DBBCDB" LCS(X,Y)="BBCD"
应⽤场景:字符串相似度⽐对(模糊查询)、基因工程
思考:暴⼒穷举法的时间复杂度是多少? 答:O(2^n)
思考:最⻓公共⼦序列是否具有最优⼦结构性质?答:是
LCS的最优子结构定理:令X = <x1,x2,...,xn>和Y = <y1,y2,...ym>为两个序列,Z = <z1,z2,...,zk>为X和Y的任意LCS。
- 如果xn = ym,则zk = xn = ym且Zk - 1是Xn - 1和Ym - 1的一个LCS;
- 如果xn ≠ ym且zk ≠ xn,说明Z是Xn - 1和Y的一个LCS;
- 如果xn ≠ ym且zk ≠ ym,说明Z是X和Ym的一个LCS
例如:要求a="ABCBDAB"与b="BDCABA"的LCS:由于最后⼀位"B"≠"A":
因此LCS(a,b)应该来源于LCS(a[:-1],b)与LCS(a,b[:-1])中更⼤的那⼀个。
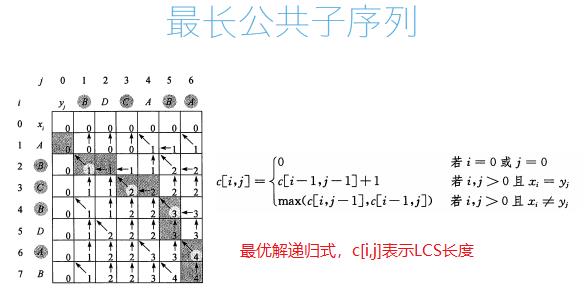
def lcs_length(x, y):
"""LCS长度"""
m = len(x)
n = len(y)
c = [[0 for _ in range(n + 1)] for _ in range(m + 1)] # 生成二维列表,包括空序列
for i in range(1, m + 1):
for j in range(1, n + 1):
if x[i - 1] == y[j - 1]: # 两位置上的字符匹配时,值来自于左上方+1
c[i][j] = c[i - 1][j - 1] + 1
else:
c[i][j] = max(c[i - 1][j], c[i][j - 1])
for _ in c:
print(_) # 打印过程
return c[m][n]
def lcs(x, y):
"""箭头走向"""
m = len(x)
n = len(y)
c = [[0 for _ in range(n + 1)] for _ in range(m + 1)]
b = [[0 for _ in range(n + 1)] for _ in range(m + 1)] # 1表示左上方,2表示上方,3表示左方
for i in range(1, m + 1):
for j in range(1, n + 1):
if x[i - 1] == y[j - 1]: # 两位置上的字符匹配时,值来自于左上方+1
c[i][j] = c[i - 1][j - 1] + 1
b[i][j] = 1
elif c[i - 1][j] >= c[i][j - 1]:
c[i][j] = c[i -1][j]
b[i][j] = 2
else:
c[i][j] = c[i][j - 1]
b[i][j] = 3
return c[m][n], b
def lcs_trackback(x, y):
"""回溯函数"""
c, b = lcs(x, y)
i = len(x)
j = len(y)
res = []
while i > 0 and j > 0:
if b[i][j] == 1: # 来自左上方匹配
res.append(x[i - 1])
i -= 1
j -= 1
elif b[i][j] == 2: # 来自上方不匹配
i -= 1
else: # 来自左方不匹配
j -= 1
return ''.join(reversed(res))
print(lcs_length('ABCBDAB', 'BDCABA'))
c,b=lcs('ABCBDAB', 'BDCABA')
for _ in b:
print(_)
print(lcs_trackback('ABCBDAB', 'BDCABA'))
欧几里得算法
约数:如果整数a能被整数b整除,那么a叫做b的倍数,b叫做a的约数。 给定两个整数a,b,两个数的所有公共约数中的最⼤值即为最 ⼤公约数(Greatest Common Divisor, GCD)。 例:12与16的最⼤公约数是4
如何计算两个数的最⼤公约数:
-
欧⼏⾥得:辗转相除法(欧⼏⾥得算法)
欧⼏⾥得算法:gcd(a, b) = gcd(b, a mod b) # a%b取模 例:gcd(60, 21) = gcd(21, 18) = gcd(18, 3) = gcd(3, 0) = 3 -
《九章算术》:更相减损术
def gcd(a, b):
"""递归解法"""
if b == 0:
return a
else:
return gcd(b, a % b)
def gcd2(a, b):
"""非递归解法"""
while b > 0:
r = a % b
a = b
b = r
return a
print(gcd(12, 16))
print(gcd2(12, 16))
# 利⽤欧⼏⾥得算法实现⼀个分数类,⽀持分数的四则运算。
class Fraction:
"""分数"""
def __init__(self, a, b):
self.a = a
self.b = b
x = self.gcd2(a, b)
self.a /= x
self.b /= x
def gcd2(self, a, b):
while b > 0:
r = a % b
a = b
b = r
return a
def zgs(self, a, b):
"""最小公倍数"""
x = self.gcd2(a, b)
return a * b / x
def __add__(self, other):
"""加法"""
a = self.a
b = self.b
c = other.a
d = other.b
fenmu = self.zgs(b, d)
fenzi = a * fenmu / b + c * fenmu / d
return Fraction(fenzi, fenmu)
def __str__(self):
return f'{int(self.a)}/{int(self.b)}'
print(Fraction(30, 16)) # 约分
a = Fraction(1, 3)
b = Fraction(1, 2)
print(a + b)
RSA算法
传统密码:加密算法是秘密的,如凯撒密码
现代密码系统:加密算法是公开的,密钥是秘密的
-
对称加密
-
⾮对称加密
RSA⾮对称加密系统(Linus、HTTPS):
-
公钥:⽤来加密,是公开的
-
私钥:⽤来解密,是私有的
RSA加密算法过程(暂时无法破解,质数越大越难以破解,难于破解在于质数):
-
随机选取两个质数p和q
-
计算n=pq
-
选取⼀个与φ(n)互质的⼩奇数e,φ(n)=(p-1)(q-1)
-
对模φ(n),计算e的乘法逆元d,即满⾜ (e*d) mod φ(n) = 1 ,用到欧几里得算法。
-
公钥(e, n) 私钥(d, n)
加密过程:c = (m^e) mod n
解密过程:m = (c^d) mod n
p = 53
q = 59
n = p * q
fai = (p - 1) * (q - 1)
e = 3
d = 2001 # 需自行推导
m = 87 # 假设
c = (m ** e) % n # 加密过程
print(c)
m = (c ** d) % n
print(m) # 解密过程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号