并发编程
操作系统介绍
计算机三大组成:应用程序、操作系统、硬件。
执行程序结构:硬盘、内存、CPU。
操作系统:协调、管理和控制计算机软硬件资源的控制程序。
操作系统作用:
- 隐藏复杂的硬件接口,提供良好的抽象接口。
- 管理、调度接口,并且将多个进程对硬件的竞争变得有序。
第一代计算机:真空管和穿孔卡片
特点:
- 没有操作系统的概念
- 所有程序设计都是直接操控硬件
优点:程序员独占资源,即时调试程序
缺点:浪费计算机资源,一个时间段只有一个人使用
第二代计算机:晶体管和批处理系统

特点:
- 各人员和计算机明确分工
- 有了操作系统概念
优点:批处理节省机时
缺点:
- 需要人参与,将磁带搬来搬去
- 计算过程仍是串行
- 不利于调试
第三代计算机:集成电路芯片和多道技术
多道技术:时间多路复用和空间多路复用+硬件上(物理层)支持隔离,以达到将一个单独的CPU变成多个虚拟的CPU。
- 产生背景:针对单核,实现并发。现在的主机一般是多核,那么每个核都会利用多道技术,有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个cpu中的任意一个,具体由操作系统调度算法决定。
- 空间多路复用:内存中同时有多道程序
- 时间多路复用:复用一个CPU的时间片。但遇到IO切换(提升效率)或占用CPU时间过长(降低效率)也切换,核心在于切换之前将进程的状态保存下来,这样才能保证下次切换回来时,能基于上次切走的位置继续运行。
分时操作系统:多个联机终端+多道技术
多进程
进程理论
进程:一个程序的执行过程,而负责执行任务是CPU。
并发:伪并行,即看起来是同时运行,单个CPU+多道技术就可实现。
串行:一个进程执行完才执行下一个。
并行:同时运行,只有具备多个CPU才能实现。
阻塞:进程在等待输入(即I/O)时的状态。
进程的状态:运行、阻塞、就绪。
句柄:在创建进程时,父进程得到一个特别的令牌,该令牌可控制子进程,但是父进程有权把该句柄传给其他子进程。
进程的层次结构:无论UNIX还是windows,进程只有一个父进程,不同的是
- 在UNIX中所有的进程,都是以init进程为根,组成树形结构。
- 在windows中,没有进程层次的概念,所有的进程地位相同。
开启子进程的两种方式
# 方式一:利用Process类
from multiprocessing import Process
import time
import os
def task(name):
print(f'{name} is running,子进程号:{os.getpid()},子父进程号:{os.getppid()}')
time.sleep(2)
print(f'{name} is done')
if __name__ == '__main__':
p = Process(target=task, args=('allen',)) # 实例化
p.start() # 仅仅给操作系统发送一个开启子进程信号
print(f'主,主进程号:{os.getpid()},主父进程号:{os.getppid()}')
# 利用终端查看pycharm进程号
# E:\练习>tasklist |findstr pycharm
# 方式二:继承Process类
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name): # 重写init方法
super().__init__() # 继承父类init方法
self.name = name
def run(self) -> None: # 固定写法
print(f'{self.name} is running')
time.sleep(2)
print(f'{self.name} is done')
if __name__ == '__main__':
p = MyProcess('allen') # 实例化
p.start() # 仅仅给操作系统发送一个开启子进程信号
print('主')
僵尸进程和孤儿进程
僵尸进程:当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程。
- 危害:导致系统不能产生新的进程,因pid号有限。
- 解决方式:可用kill-SIGKILL父进程ID来解决。
孤儿进程:当父进程退出,而它的一个或多个子进程还在运行,那么子进程将成为孤儿进程。
开启多进程(multiprocess.process)
from multiprocessing import Process
import time
def task(name):
print(f'{name} is running')
time.sleep(2)
print(f'{name} is done')
if __name__ == '__main__':
p1 = Process(target=task, args=('allen',), name='子进程1') # 让关键参数来指定进程名
p2 = Process(target=task, args=('nick',))
p3 = Process(target=task, args=('tank',))
p_list = [p1, p2, p3]
for p in p_list:
p.start()
p1.terminate() # 给操作系统发信号关闭进程,不会立即关闭
for p in p_list:
p.join() # 让主进程等待p的结束,这是并发并非串行
print(p1.is_alive()) # 判断子进程是否存活
print('主')
print(p1.pid) # 查看子进程号
print(p1.name) # 查看子进程名
基于多进程实现并发的套接字通信
# server.py
import socket
from multiprocessing import Process
def talk(conn): # 通信循环函数
while True:
try:
data = conn.recv(1024)
print(data)
conn.send(data.upper())
except Exception:
break
conn.close()
def server(ip, port): # 连接循环函数
server = socket.socket()
server.bind((ip, port))
server.listen(5)
while True:
conn, addr = server.accept()
p = Process(target=talk, args=(conn,)) # 实例化进程对象
p.start() # 开启进程
server.close()
if __name__ == '__main__':
server('127.0.0.1', 8000)
# client.py
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8000))
while True:
msg = input('>>>:').strip()
if not msg: continue
client.send(bytes(msg, encoding='utf-8'))
data = client.recv(1024)
print(data)
# 每来一个客户端,服务端就开启一个新的进程来服务它,这种实现方式导致系统越来越卡。
# 进程之间的内存空间是隔离的。
守护进程
定义:主进程创建子进程,然后将该进程设置成守护自己的进程。守护进程会在主进程代码执行结束后就终止。
from multiprocessing import Process
import time
def talk(name):
print(f'{name} is running')
time.sleep(2)
print(f'{name} is done')
if __name__ == '__main__':
p = Process(target=talk, kwargs={'name': 'allen'})
p.daemon = True # 一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行
p.start()
print('主') # 主 #只要终端打印出这一行内容,那么守护进程p也就跟着结束掉了
进程同步(multiprocess.Lock)
进程锁metux
定义:把并发变成了串行,牺牲了效率,但保证了数据安全。也称为互斥锁
由来:进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,而共享带来的是竞争,竞争带来的结果就是错乱。
# 并发运行,效率高,但竞争同一打印终端,带来了打印错乱
from multiprocessing import Process
import time, os
def task():
print(f'{os.getpid()} is running')
time.sleep(1)
print(f'{os.getpid()} is done')
if __name__ == '__main__':
for i in range(3):
p = Process(target=task)
p.start()
解决方案:加锁处理。互斥锁的工作原理就是把并发改成串行,降低了效率,但保证了数据安全不错乱。如果把多个进程比喻为多个人,多个人都要去争抢同一个资源:卫生间,一个人抢到卫生间后上一把锁,其他人都要等着,等到这个完成任务后释放锁。
# 由并发变成了串行,牺牲了运行效率,但避免了竞争
from multiprocessing import Process, Lock
import time, os
def task(lock):
lock.acquire() # 加锁
print(f'{os.getpid()} is running')
time.sleep(1)
print(f'{os.getpid()} is done')
lock.release() # 释放锁
if __name__ == '__main__':
lock = Lock() # 锁对象
for i in range(3):
p = Process(target=task, args=(lock,))
p.start()
模拟抢票
方案一:多个进程共享同一文件,我们可以把文件当数据库,用多个进程模拟多个人执行抢票任务,并发运行,效率高,但竞争写同一文件,数据写入错乱,只有一张票,卖成功给了10个人,故不成立。
#文件db.txt的内容为:{"count":1}
#注意一定要用双引号,不然json无法识别
from multiprocessing import Process
import time
import json
def search(name):
dic = json.load(open('db.txt', 'r', encoding='utf-8'))
time.sleep(1) # 模拟网络延迟
print(f'路人{name}查询了还有{dic["count"]}张余票')
def get(name):
dic = json.load(open('db.txt', 'r', encoding='utf-8'))
time.sleep(1)
if dic["count"] > 0:
dic["count"] -= 1
time.sleep(1)
json.dump(dic, open('db.txt', 'w', encoding='utf-8'))
print(f'{name}抢票成功')
def task(name):
search(name)
get(name)
if __name__ == '__main__':
for i in range(8):
p = Process(target=task, args=(f'路人{i}',))
p.start()
方案二:加锁处理:购票行为由并发变成了串行,牺牲了运行效率,但保证了数据安全
from multiprocessing import Process, Lock
import time
import json
def search(name):
"""查票函数"""
dic = json.load(open('db.txt', 'r', encoding='utf-8'))
time.sleep(1) # 模拟网络延迟
print(f'路人{name}查询了还有{dic["count"]}张余票')
def get(name):
"""抢票函数"""
dic = json.load(open('db.txt', 'r', encoding='utf-8'))
time.sleep(1)
if dic["count"] > 0:
dic["count"] -= 1
time.sleep(1)
json.dump(dic, open('db.txt', 'w', encoding='utf-8'))
print(f'{name}抢票成功')
def task(name, lock):
search(name)
lock.acquire() # 加锁
get(name)
lock.release() # 释放锁
if __name__ == '__main__':
lock = Lock() # 在抢票环节加锁,而非查票加锁
for i in range(8):
p = Process(target=task, args=(f'路人{i}', lock))
p.start()
方案三:join方法处理,虽然保证了数据安全,但问题是连查票操作也变成只能一个一个人去查了,很明显大家查票时应该是并发地去查询而无需考虑数据准确与否。
from multiprocessing import Process, Lock
import time
import json
def search(name):
"""查票函数"""
dic = json.load(open('db.txt', 'r', encoding='utf-8'))
time.sleep(1) # 模拟网络延迟
print(f'路人{name}查询了还有{dic["count"]}张余票')
def get(name):
"""抢票函数"""
dic = json.load(open('db.txt', 'r', encoding='utf-8'))
time.sleep(1)
if dic["count"] > 0:
dic["count"] -= 1
time.sleep(1)
json.dump(dic, open('db.txt', 'w', encoding='utf-8'))
print(f'{name}抢票成功')
def task(name):
search(name)
get(name)
if __name__ == '__main__':
for i in range(8):
p = Process(target=task, args=(f'路人{i}', ))
p.start()
p.join()
综上所述:join是将一个任务整体串行,而互斥锁的好处则是可以将一个任务中的某一段代码串行,比如只让task函数中的get任务串行。
def task(name,):
search(name) # 并发执行
lock.acquire()
get(name) #串行执行
lock.release()
虽然可以用文件共享数据实现进程间通信,但问题是:效率低(共享数据基于文件,而文件是硬盘上的数据)和需要自己加锁处理
因此我们最好找寻一种解决方案能够兼顾:效率高(多个进程共享一块内存的数据)和帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC(inter-process-communication)通信机制:队列和管道。
队列和管道都是将数据存放于内存中,而队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来,因而队列才是进程间通信的最佳选择。我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
进程间通信IPC(multiprocess.Queue)
队列Queue
定义:可创建共享的进程队列,可保证多进程安全的队列,实现多进程之间的数据传递。
from multiprocessing import Queue
q = Queue(3) # 创建共享的进程队列
q.put(1) # 插入数据到队列中
q.put('hello')
q.put([1, 2, 3])
print(q.full()) # True
# q.put(4) # 再放就阻塞了
q.get() # 从队列读取并且删除一个元素
q.get()
q.get()
print(q.empty()) # True
q.get() # 再取就阻塞了
生产者和消费者模型
定义:生产者是生产数据的任务,消费者是处理数据的任务,而生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。
# 基于Queue实现消费者和生产者模型
from multiprocessing import Process, Queue
import time
def producer(q):
for i in range(3):
res = f'包子{i}'
time.sleep(1)
print(f'生产者生产了{res}')
q.put(res)
def costumer(q):
while True:
res = q.get()
if res is None: break
time.sleep(1)
print(f'消费者吃了{res}包子')
if __name__ == '__main__':
# 容器
q = Queue()
# 生产者们
p1 = Process(target=producer, args=(q,))
p2 = Process(target=producer, args=(q,))
# 消费者们
c1 = Process(target=costumer, args=(q,))
p1.start()
p2.start()
c1.start()
p1.join()
p2.join()
q.put(None)
q.put(None)#有几个消费者就需要发送几次结束信号:相当low
print('主')
# 基于JoinableQueue实现生产者消费者模型
from multiprocessing import Process, JoinableQueue
import time
def producer(q):
for i in range(3):
res = f'包子{i}'
time.sleep(1)
print(f'生产者生产了{res}')
q.put(res)
q.join() # 等到消费者把自己放入队列中的所有的数据都取走之后,生产者才结束
def costumer(q):
while True:
res = q.get()
if res is None: break
time.sleep(1)
print(f'消费者吃了{res}包子')
q.task_done() # 发送信号给q.join(),说明已经从队列中取走一个数据并处理完毕了
if __name__ == '__main__':
# 容器
q = JoinableQueue()
# 生产者们
p1 = Process(target=producer, args=(q,))
p2 = Process(target=producer, args=(q,))
# 消费者们
c1 = Process(target=costumer, args=(q,))
c1.daemon = True
p1.start()
p2.start()
c1.start()
p1.join()
p2.join()
# 1、主进程等生产者p1、p2结束
# 2、而p1、p2是在消费者把所有数据都取干净之后才会结束
# 3、所以一旦p1、p2结束了,证明消费者也没必要存在了,应该随着主进程一块死掉,因而需要将生产者们设置成守护进程
print('主')
生产者消费者模型总结:
- 程序中有两类角色
- 一类负责生产数据(生产者)
- 一类负责处理数据(消费者)
- 引入生产者消费者模型为了解决的问题是
- 平衡生产者与消费者之间的速度差
- 程序解开耦合
- 如何实现生产者消费者模型
- 生产者<--->队列<--->消费者
多线程
线程理论
进程:正在执行的程序,是一个资源单位,并不能真正意义上执行。
线程:被包含在进程之中,是进程中负责程序执行的实际运作单位。每启动一个进程,进程内至少有一个线程,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
进程与线程的区别:
- 进程间相互独立,而同一个进程内的多个线程共享该进程内的地址资源
- 创建线程的开销要远小于创建进程的开销——因为线程/进程对象.start()发信号时,前者几乎同时将线程开启,而后者发给操作系统后,操作系统要申请内存空间,让拷贝父进程地址空间到子进程,开销远大于线程,所以在主进程下开线程比在主进程下开子进程速度快。
- pid号——在主进程下开启多个线程,每个线程都跟主进程的pid一样,而开多个进程,每个进程都有不同的pid。
线程的应用:开启一个文本处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程。只能在一个进程里并发地开启三个线程,如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
开启线程的两种方式
# 方式一:利用Thread类
from threading import Thread
import threading
import time
def task(name):
print(f'{name} is running')
time.sleep(1)
print(f'{name} is done')
if __name__ == '__main__':
# 在主进程下开启线程
t = Thread(target=task, args=('allen',))
t.start()
print(t.isAlive()) # 判断线程是否存活
t.setName('线程一') # 设置线程名
print(t.getName()) # 获取线程名
print(threading.currentThread()) # 返回当前的线程变量
print(threading.enumerate()) # 返回正在运行的线程列表
print(threading.activeCount()) # 返回正在运行的线程数量
t.join() # 让主线程等待子线程结束
print('主线程')
# 注:当程序运行时,从资源角度是一个进程,从执行角度默认有一个线程,当执行到main函数再发出信号开启线程。
# 方式二:继承Thread类
from threading import Thread
import time
class MyThread(Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self) -> None:
print(f'{self.name} is running')
time.sleep(1)
print(f'{self.name} is done')
if __name__ == '__main__':
t = MyThread('allen') # 注意用法
t.start()
print('主线程')
守护线程
无论是进程还是线程,都遵循:守护xx会等待主xx运行完毕后被销毁。需要强调的是:运行完毕并非终止运行。
- 对主进程而言,运行完毕指主进程代码运行完毕(主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束)。
- 对主线程而言,运行完毕指主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕(主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束)。
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(1)
print(f'{name} is done')
if __name__ == '__main__':
t = Thread(target=task, args=('allen',))
t.daemon = True # 守护线程一定要设置在start()之前
t.start()
print('主线程')
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(1)
print(f'{name} is done')
def talk(name):
print(f'{name} is running')
time.sleep(3)
print(f'{name} is done')
if __name__ == '__main__':
t1 = Thread(target=task, args=('allen',))
t2 = Thread(target=task, args=('tank',))
t1.daemon = True # 守护线程一定要设置在start()之前
t1.start()
t2.start()
print('主线程')
线程锁mutex
定义:把并发变成了串行,牺牲了效率,但保证了数据安全,同时保护不同的数据就应该加不同的锁。也称为互斥锁
# 加锁前
from threading import Thread
import time
n = 100
def task():
global n
tmp = n
time.sleep(0.1) # 此时100个线程在等待,效率高,但导致数据不安全,结果n=99
n = tmp - 1
if __name__ == '__main__':
t_lis = []
for i in range(100):
t = Thread(target=task)
t_lis.append(t)
t.start()
for t in t_lis:
t.join()
print('主线程', n) # 主线程 99
# 加锁后
from threading import Thread, Lock
import time
n = 100
def task():
global n
mutex.acquire() # 加锁
tmp = n
time.sleep(0.1)
n = tmp - 1
mutex.release() # 释放锁
if __name__ == '__main__':
mutex = Lock()
t_lis = []
for i in range(100):
t = Thread(target=task)
t_lis.append(t)
t.start()
for t in t_lis:
t.join()
print('主线程', n) # 主线程 0 由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
GIL全局解释器锁
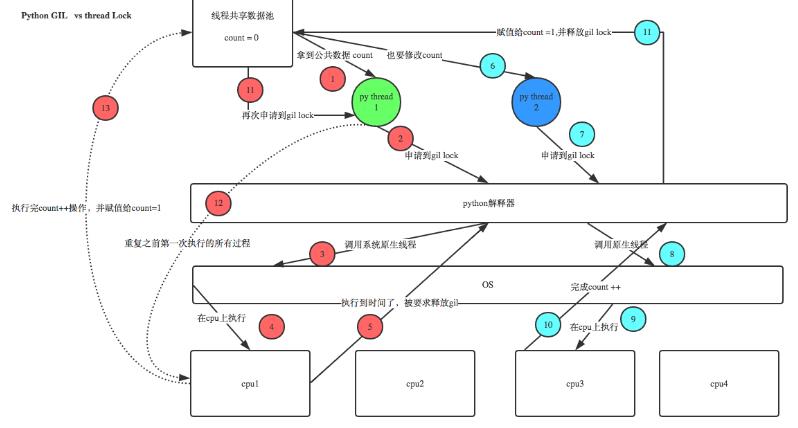
定义:本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。肯定的是保护不同的数据的安全,就应该加不同的锁。但是导致的问题是在Cpython解释器(并不是Python的特性)中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势,除非开多个进程。
- 每一次执行Python文件,就是启动一个python解释器的进程。
- 每运行python文件执行三步:
- 先把python解释器的代码(相当于C语言的代码)加载到进程内存空间中。
- 再把python文件由硬盘加载到进程内存空间中。
- 最后将python文件代码(自身不能执行)当做普通字符串交给cpython解释器的代码去执行。
详解:解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
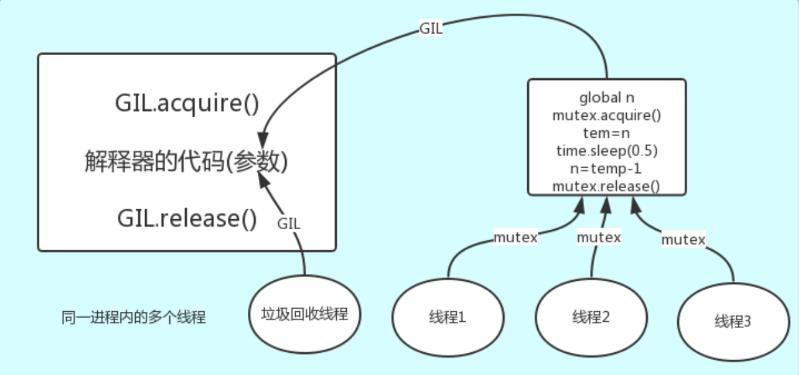
GIL与自定义互斥锁的区别
- GIL保证一个进程多个线程同一时间只有一个线程执行,原因是保证解释器垃圾回收线程是安全的。
- 针对不同的数据应该加不同的锁,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock。
GIL与多线程
-
对计算来说,cpu越多越好,但是对于I/O阻塞来说,再多的cpu也没用。
-
当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O,所以我们只能相对的去看一个程序到底是计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用武之地。
-
现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。目前市面上大多数都是基于IO密集型。
-
应用:多线程用于IO密集型,如socket,爬虫,web;多进程用于计算密集型,如金融分析。
# 如果并发的多个任务是计算密集型:多进程效率高 from multiprocessing import Process from threading import Thread import os,time def work(): res=0 for i in range(100000000): res*=i if __name__ == '__main__': l=[] print(os.cpu_count()) #本机为4核 start=time.time() for i in range(4): p=Process(target=work) #耗时5s多 p=Thread(target=work) #耗时18s多 l.append(p) p.start() for p in l: p.join() stop=time.time() print('run time is %s' %(stop-start))# 如果并发的多个任务是I/O密集型:多线程效率高 from multiprocessing import Process from threading import Thread import threading import os,time def work(): time.sleep(2) print('===>') if __name__ == '__main__': l=[] print(os.cpu_count()) #本机为4核 start=time.time() for i in range(400): # p=Process(target=work) #耗时12s多,大部分时间耗费在创建进程上 p=Thread(target=work) #耗时2s多 l.append(p) p.start() for p in l: p.join() stop=time.time() print('run time is %s' %(stop-start))
死锁现象与递归锁
死锁现象: 两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去,这些永远在互相等待的进程称为死锁进程。
from threading import Thread,Lock
import time
mutexA=Lock()
mutexB=Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('\033[41m%s 拿到A锁\033[0m' %self.name)
mutexB.acquire()
print('\033[42m%s 拿到B锁\033[0m' %self.name)
mutexB.release()
mutexA.release()
def func2(self):
mutexB.acquire()
print('\033[43m%s 拿到B锁\033[0m' %self.name)
time.sleep(2)
mutexA.acquire()
print('\033[44m%s 拿到A锁\033[0m' %self.name)
mutexA.release()
mutexB.release()
if __name__ == '__main__':
for i in range(10):
t=MyThread()
t.start()
#Thread-1 拿到A锁
#Thread-1 拿到B锁
#Thread-1 拿到B锁
#Thread-2 拿到A锁 #出现死锁,整个程序阻塞住
递归锁是死锁现象的解决方法,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁,二者的区别是:递归锁可以连续acquire多次,而互斥锁只能acquire一次
from threading import Thread,RLock
import time
mutexA=mutexB=RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('\033[41m%s 拿到A锁\033[0m' %self.name)
mutexB.acquire()
print('\033[42m%s 拿到B锁\033[0m' %self.name)
mutexB.release()
mutexA.release()
def func2(self):
mutexB.acquire()
print('\033[43m%s 拿到B锁\033[0m' %self.name)
time.sleep(2)
mutexA.acquire()
print('\033[44m%s 拿到A锁\033[0m' %self.name)
mutexA.release()
mutexB.release()
if __name__ == '__main__':
for i in range(10):
t=MyThread()
t.start()
信号量
定义:信号量也是一把锁,可以指定信号量为5,对比互斥锁同一时间只能有一个任务抢到锁去执行,信号量同一时间可以有5个任务拿到锁去执行,如果说互斥锁是合租房屋的人去抢一个厕所,那么信号量就相当于一群路人争抢公共厕所,公共厕所有多个坑位,意味着同一时间可以有多个人上公共厕所,但公共厕所容纳的人数是一定的,这是信号量的大小。
from threading import Thread, currentThread, Semaphore
import random, time
sem = Semaphore(3) # 设置信号量大小,即锁个数
def task():
# with sem:#利用with管理上下文写法
# print(f'{currentThread().name} is running')
# time.sleep(random.randint(1, 3))
sem.acquire() # 加锁
print(f'{currentThread().name} is running')
time.sleep(random.randint(1, 3))
sem.release() # 释放锁
if __name__ == '__main__':
for i in range(10):
t = Thread(target=task)
t.start()
解析:Semaphore管理一个内置的计数器,每当调用acquire()时内置计数器-1;调用release() 时内置计数器+1;计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
Event事件
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行。
案例一:学生等待老师说下课
from threading import Thread, Event
import time
event = Event()
def student(name):
print(f'学生{name} 正在听课')
print(event.is_set()) # 返回event的状态值False
event.wait() # 如果 event.isSet()==False将阻塞线程
print(f'学生{name} 课间活动')
def teacher(name):
print(f'{name} 正在讲课')
time.sleep(3)
event.set() # 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度
print(event.is_set()) # True
if __name__ == '__main__':
t1 = Thread(target=student, args=('allen',))
t2 = Thread(target=student, args=('tank',))
t3 = Thread(target=teacher, args=('fuck',))
t1.start()
t2.start()
t3.start()
案例二:有多个工作线程尝试链接MySQL,我们想要在链接前确保MySQL服务正常才让那些工作线程去连接MySQL服务器,如果连接不成功,都会去尝试重新连接。那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作。
from threading import Thread,Event
import threading
import time,random
def conn_mysql():
count=1
while not event.is_set():
if count > 3:
raise TimeoutError('链接超时')
print('<%s>第%s次尝试链接' % (threading.current_thread().getName(), count))
event.wait(0.5)
count+=1
print('<%s>链接成功' %threading.current_thread().getName())
def check_mysql():
print('\033[45m[%s]正在检查mysql\033[0m' % threading.current_thread().getName())
time.sleep(random.randint(2,4))
event.set()
if __name__ == '__main__':
event=Event()
conn1=Thread(target=conn_mysql)
conn2=Thread(target=conn_mysql)
check=Thread(target=check_mysql)
conn1.start()
conn2.start()
check.start()
定时器
定义:指定n秒后执行某操作
案例一:延缓函数执行
from threading import Timer
def talk():
print('hello world')
t = Timer(2, talk)#时间间隔2s执行函数
t.start()
案例二:定期发送验证码
from threading import Timer
import random
class Code:
def __init__(self):
self.make_cashe()
def make_cashe(self, interval=10):
self.cashe = self.make_code()
print(self.cashe)
self.t = Timer(interval, self.make_cashe)
self.t.start()
def make_code(self, n=6):
res = ''
for i in range(n):
s1 = str(random.randint(0, 9))
s2 = chr(random.randint(65, 90))
s3 = chr(random.randint(97, 122))
res += random.choice([s1, s2, s3])
return res
def check(self):
while True:
code = input('请输入你的验证码:').strip()
if code.upper() == self.cashe:
print('验证码输入正确')
self.t.cancel()
break
obj = Code()
obj.check()
线程queue的三种用法
由于进程之间数据是不共享的,所以不会出现多线程GIL带来的问题。多进程之间的通信通过Queue()或Pipe()来实现,而多线程之间的通信通过queue来实现。
# 用法一:先进先出——>队列
import queue
q = queue.Queue(3) # 创建队列数
q.put('hello')
q.put(2)
q.put([1, 2])
# q.put(4,block=True,timeout=3)#再放值,默认阻塞,超过3s报错
q.get()
q.get()
q.get()
q.get(block=True, timeout=2) # 再取值,默认阻塞,超过2s报错
# 用法二:后进来出——>堆栈(last in for out)
import queue
q = queue.LifoQueue() # 创建队列数
q.put('hello')
q.put(2)
q.put([1, 2])
print(q.get())
print(q.get())
print(q.get())
# 用法三:优先级队列:存储数据时可设置优先级的队列
import queue
q = queue.PriorityQueue()
# put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((20, 'a'))
q.put((10, 'b'))
q.put((30, 'c'))
print(q.get())
print(q.get())
print(q.get())
多线程实现并发的套接字通信
# server.py
import socket
from threading import Thread
def test(conn):
while True:
data = conn.recv(1024)
print(data)
conn.send(data.upper())
def server(ip,port):
server = socket.socket()
server.bind((ip,port))
server.listen(5)
while True:
conn, addr = server.accept()
t = Thread(target=test, args=(conn,))
t.start()
if __name__ == '__main__':
server.bind('127.0.0.1', 8000)
# client.py
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8000))
while True:
msg = input('>>>:')
if not msg: continue
client.send(bytes(msg, encoding='utf-8'))
data = client.recv(1024)
print(data)
进程池与线程池
定义:存放进程或线程的池子。
用途:基于多进程或多线程实现并发的套接字通信,都会存在一个致命性问题——服务的开启的进程数或线程数都会随着并发的客户端数目地增多而增多,这会对服务端主机带来巨大的压力,甚至于不堪重负而瘫痪。所以必须对服务端开启的进程数和线程数加以控制,让机器在承受范围内运行。
# 进程池
from concurrent.futures import ProcessPoolExecutor
import os, time, random
def task(name):
print(f'name:{name} pid:{os.getpid()} is running')
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
pool = ProcessPoolExecutor(4) # 第一步:指定进程池大小,默认CPU的核数,已封装好四个进程对象
for i in range(10):
pool.submit(task, f'allen{i}') # 第二步:往进程池中提交任务
pool.shutdown(
wait=True) # 第三步:相当于进程池的关闭pool.close()+等待pool.join()操作,默认wait=True,等待池内所有任务执行完毕回收完资源后才继续,wait=False,立即返回,并不会等待池内的任务执行完毕,但不管wait参数为何值,整个程序都会等到所有任务执行完毕
print('主')
# 线程池
from concurrent.futures import ThreadPoolExecutor
from threading import currentThread
import time, random,os
def task(name):
print(f'线程名:{currentThread().getName()} 代号:{name} is running')
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
pool = ThreadPoolExecutor(4) # 第一步:指定进程池大小,默认CPU的核数,已封装好四个进程对象
for i in range(10):
pool.submit(task, f'allen{i}') # 第二步:往进程池中提交任务
pool.shutdown(wait=True) # 第三步:相当于进程池的关闭pool.close()+等待pool.join()操作,默认wait=True,等待池内所有任务执行完毕回收完资源后才继续,wait=False,立即返回,并不会等待池内的任务执行完毕,但不管wait参数为何值,整个程序都会等到所有任务执行完毕
print('主')
# 线程池
from concurrent.futures import ThreadPoolExecutor
from threading import currentThread
import time, random, os
def task(name):
print(f'线程名:{currentThread().getName()} 代号:{name} is running')
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
pool = ThreadPoolExecutor(4)
# for i in range(10):
# pool.submit(task, f'allen{i}')
pool.map(task, range(10)) # 提交任务也可这样操作,简化了for+submit的操作
pool.shutdown(
wait=True)
print('主')
异步调用与回调机制
提交任务的两种方式:
同步调用:提交任务后,就在原地等待任务执行完毕,拿到返回结果,再执行下一行代码,导致程序是串行执行。
异步调用:提交任务后,不在原地等待任务执行完毕,不用拿到返回结果,就可执行下一行代码。
案例:拉shi大赛
# 同步调用:
from concurrent.futures import ThreadPoolExecutor
import time, random
def la(name):
print(f'{name} is laing')
time.sleep(random.randint(1, 3))
res = random.randint(7, 13) * '*'
return {'name': name, 'res': res}
def weigh(dic):
name = dic['name']
size = len(dic['res'])
print(f'{name} 拉了 {size} kg')
if __name__ == '__main__':
pool = ThreadPoolExecutor(10)
dic1 = pool.submit(la, 'egon').result() # 提交任务得到对象并拿到结果
weigh(dic1) # 获得比赛结果
dic2 = pool.submit(la, 'alex').result()
weigh(dic2)
dic3 = pool.submit(la, 'nick').result()
weigh(dic3)
# 异步调用:
from concurrent.futures import ThreadPoolExecutor
import time, random
def la(name):
"""拉屎函数"""
print(f'{name} is laing')
time.sleep(random.randint(1, 3))
res = random.randint(7, 13) * '*'
return {'name': name, 'res': res}
# weigh({'name': name, 'res': res})#这种方式不能实现解耦合
def weigh(dic):
"""称重函数"""
dic=dic.result()
name = dic['name']
size = len(dic['res'])
print(f'{name} 拉了 {size} kg')
if __name__ == '__main__':
pool = ThreadPoolExecutor(10)
print(pool.submit(la, 'egon'))#<Future at 0x211e87f2978 state=running>
pool.submit(la, 'egon').add_done_callback(weigh) # 提交任务得到future对象后自动触发回调函数并当做参数传入,此时拿不到返回结果
pool.submit(la, 'alex').add_done_callback(weigh)
pool.submit(la, 'nick').add_done_callback(weigh)
练习一:利用线程池爬取多个网站数据
from concurrent.futures import ThreadPoolExecutor
import requests, time
def get(url):
"""获取数据"""
print(f'正在爬取:{url}')
res = requests.get(url).text
time.sleep(2)
return {'name': url, 'content': res}
def parse(res):
"""解析函数"""
res = res.result()
print(f'{res["name"]}获取的长度为:{len(res["content"])}')
if __name__ == '__main__':
urls = [
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/'
]
pool = ThreadPoolExecutor(2)
for url in urls:
pool.submit(get, url).add_done_callback(parse)
练习二:基于线程池实现并发的套接字编程,解决服务端开启过多进程线程崩溃的问题
# server.py
from socket import *
from concurrent.futures import ThreadPoolExecutor
def talk(conn):
"""通信函数"""
while True:
try:
data = conn.recv(1024)
if not data: break
print(data)
conn.send(data.upper())
except ConnectionResetError:
break
conn.close()
def server(ip, port):
"""链接函数"""
server = socket(AF_INET, SOCK_STREAM)
server.bind((ip, port))
server.listen(5)
while True:
conn, addr = server.accept()
pool.submit(talk, conn)
server.close()
if __name__ == '__main__':
pool = ThreadPoolExecutor(2)
server('127.0.0.1', 8000)
# client.py
from socket import *
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8000))
while True:
msg = input('>>>:').strip()
if not msg: continue
client.send(bytes(msg, encoding='utf8'))
data = client.recv(1024)
print(data)
# 注:以上服务端不会出现崩溃的现象,因限制客户端出现两个,第三个在队列中等待。
协程
到目前如何实现并发呢?多进程或多线程。那单线程下能否实现并发呢?答案是肯定的。本小节是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个,无法实现并行)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态,cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长或有一个优先级更高的程序替代了它。
协程理论
协程:单线程下实现并发,由程序员控制切换+保存状态,又称微线程,纤程。英文名Coroutine。
def func1():
pass
def func2():
pass
def func3():
pass
def func4():
pass
def func5():
pass
func1()
func2()
func3()
func4()
func5()
# 一个进程下五个任务,并没有实现并发,程序员要找到一种解决方案,从应用级别出发,让这5个任务切换+保存状态,让看起来同时运行,达到并发的效果。
强调:
- python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
- 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
- 一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
优点:
- 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
- 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点:
- 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
- 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
gevent模块
作用:监测程序中IO操作,实现单线程下并发。
# 方案一:利用gevent操作但未实现遇到IO切换
import gevent, time
def eat(name):
print(f'{name} eat 1')
time.sleep(3)
print(f'{name} eat 2')
def play(name):
print(f'{name} play 1')
time.sleep(2)
print(f'{name} play 2')
start_time = time.time()
g1 = gevent.spawn(eat, 'tank') # 创建协程对象
g2 = gevent.spawn(play, 'allen') # 创建协程对象
g1.join()
g2.join()
end_time = time.time()
print(end_time - start_time) # 5.081852674484253
# 方案二:利用gevent模块实现遇到IO切换,但是不能识别程序中所有的IO操作
import gevent, time
def eat(name):
print(f'{name} eat 1')
gevent.sleep(3)
print(f'{name} eat 2')
def play(name):
print(f'{name} play 1')
gevent.sleep(2)
print(f'{name} play 2')
start_time = time.time()
g1 = gevent.spawn(eat, 'tank') # 创建协程对象
g2 = gevent.spawn(play, 'allen') # 创建协程对象
g1.join()
g2.join()
end_time = time.time()
print(end_time - start_time) # 3.0671041011810303
# 方案三:利用gevent模块对程序打补丁,监测所有IO操作
import gevent, time
from gevent import monkey;monkey.patch_all()
def eat(name):
print(f'{name} eat 1')
time.sleep(3)
print(f'{name} eat 2')
def play(name):
print(f'{name} play 1')
time.sleep(2)
print(f'{name} play 2')
start_time = time.time()
g1 = gevent.spawn(eat, 'tank') # 提交任务
g2 = gevent.spawn(play, 'allen') # 提交任务
g1.join()
g2.join()
# gevent.joinall([g1, g2]) #相当于上面两行,异步提交任务
end_time = time.time()
print(end_time - start_time) # 3.0271289348602295
# 方案四:利用gevent模块对程序打补丁,监测所有IO操作
基于gevent模块实现单线程下的socket并发编程
# server.py
from gevent import monkey;monkey.patch_all()
from socket import *
import gevent
#如果不想用money.patch_all()打补丁,可以用gevent自带的socket
# from gevent import socket
# s=socket.socket()
def server(server_ip,port):
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind((server_ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
gevent.spawn(talk,conn,addr)
def talk(conn,addr):
try:
while True:
res=conn.recv(1024)
print('client %s:%s msg: %s' %(addr[0],addr[1],res))
conn.send(res.upper())
except Exception as e:
print(e)
finally:
conn.close()
if __name__ == '__main__':
server('127.0.0.1',8080)
# client.py
from threading import Thread
from socket import *
import threading
def client(server_ip,port):
c=socket(AF_INET,SOCK_STREAM) #套接字对象一定要加到函数内,即局部名称空间内,放在函数外则被所有线程共享,则大家公用一个套接字对象,那么客户端端口永远一样了
c.connect((server_ip,port))
count=0
while True:
c.send(('%s say hello %s' %(threading.current_thread().getName(),count)).encode('utf-8'))
msg=c.recv(1024)
print(msg.decode('utf-8'))
count+=1
if __name__ == '__main__':
for i in range(500):
t=Thread(target=client,args=('127.0.0.1',8080))
t.start()
IO模型
对于一个network I/O (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个I/O的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,该操作会经历两个阶段:
- 等待数据准备 (Waiting for the data to be ready)
- 将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
记住这两点很重要,因为这些I/O模型的区别就是在两个阶段上各有不同的情况。
在网络环境下,再通俗的讲,将I/O分为两步:
- 等;
- 数据搬迁。
如果要想提高I/O效率,需要将等的时间降低。
五种I/O模型包括:阻塞I/O、非阻塞I/O、信号驱动I/O、I/O多路转接、异步I/O。其中,前四个被称为同步I/O。
在介绍五种I/O模型时,我会举生活中老王买车票的例子,加深理解。
阻塞I/O模型
以买票的例子举例,该模型小结为:
# 老王去火车站买票,排队三天买到一张退票。
# 耗费:在车站吃喝拉撒睡 3天,其他事一件没干。
blocking I/O的特点就是在I/O执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。
ps:所谓阻塞型接口是指系统调用(一般是I/O接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。
非阻塞I/O模型
以买票的例子举例,该模型小结为
# 老王去火车站买票,隔12小时去火车站问有没有退票,三天后买到一张票。
# 耗费:往返车站6次,路上6小时,其他时间做了好多事。
我们不能否则其优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在“”同时“”执行)。
但是也难掩其缺点:
- 循环调用recv()将大幅度推高CPU占用率;这也是我们在代码中留一句time.sleep(2)的原因,否则在低配主机下极容易出现卡机情况
- 任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
多路复用I/O模型
以买票的例子举例,select/poll模型小结为:
# 老王去火车站买票,委托黄牛,然后每隔6小时电话黄牛询问,黄牛三天内买到票,然后老王去火车站交钱领票。
# 耗费:往返车站2次,路上2小时,黄牛手续费100元,打电话17次
信号驱动I/O模型
以买票的例子举例,该模型小结为:
# 老王去火车站买票,给售票员留下电话,有票后,售票员电话通知老王,然后老王去火车站交钱领票。
# 耗费:往返车站2次,路上2小时,免黄牛费100元,无需打电话
异步I/O模型
以买票的例子举例,该模型小结为:
# 老王去火车站买票,给售票员留下电话,有票后,售票员电话通知老王并快递送票上门。
# 耗费:往返车站1次,路上1小时,免黄牛费100元,无需打电话
I/O模型比较分析
阻塞I/O , 非阻塞I/O ,I/O多路复用 都属于 同步I/O 。
五个模型的阻塞程度由低到高为:阻塞I/O>非阻塞I/O>多路转接I/O>信号驱动I/O>异步I/O,因此效率是由低到高的。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)