



大数据学习路线图(转载)
我在人工智能和大数据之间选择学习了大数据,因为脑子笨笨笨
2018大数据培训学习路线图(详细完整版)
2018大数据培训学习路线全课程目录+学习线路详解(详细完整版)
第一阶段:大数据基础Java语言基础阶段
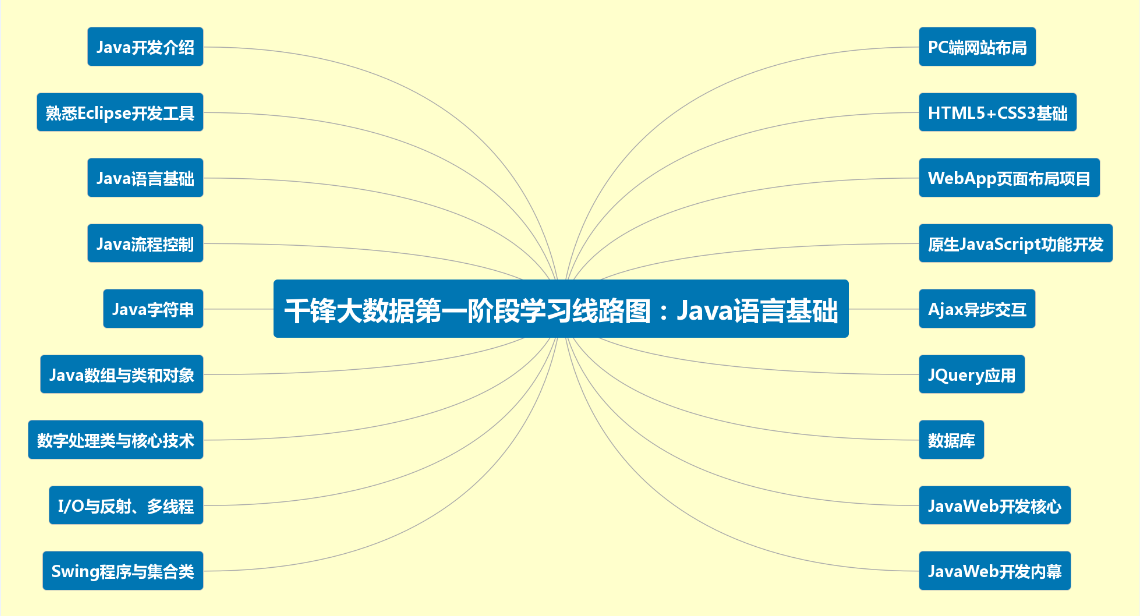
1.1:Java开发介绍
1.1.1 Java的发展历史
1.1.2 Java的应用领域
1.1.3 Java语言的特性
1.1.4 Java面向对象
1.1.5 Java性能分类
1.1.6 搭建Java环境
1.1.7 Java工作原理
1.2:熟悉Eclipse开发工具
1.2.1 Eclipse简介与下载
1.2.2 安装Eclipse的中文语言包
1.2.3 Eclipse的配置与启动
1.2.4 Eclipse工作台与视图
1.2.5 “包资源管理器”视图
1.2.6 使用Eclipse
1.2.7 使用编辑器编写程序代码
1.3:Java语言基础
1.3.1 Java主类结构
1.3.2 基本数据类型
1.3.3 变量与常量
1.3.4 Java运算符
1.3.5 数据类型转换
1.3.6 代码注释与编码规范
1.3.7 Java帮助文档
1.4:Java流程控制
1.4.1 复合语句
1.4.2 条件语句
1.4.3 if条件语句
1.4.4 switch多分支语句
1.4.5 while循环语句
1.4.6 do…while循环语句
1.4.7 for循环语句
1.5:Java字符串
1.5.1 String类
1.5.2 连接字符串
1.5.3 获取字符串信息
1.5.4 字符串操作
1.5.5 格式化字符串
1.5.6 使用正则表达式
1.5.7 字符串生成器
1.6:Java数组与类和对象
1.6.1 数组概述
1.6.2 一维数组的创建及使用
1.6.3 二维数组的创建及使用
1.6.4 数组的基本操作
1.6.5 数组排序算法
1.6.6 Java的类和构造方法
1.6.7 Java的对象、属性和行为
1.7:数字处理类与核心技术
1.7.1 数字格式化与运算
1.7.2 随机数 与大数据运算
1.7.3 类的继承与Object类
1.7.4 对象类型的转换
1.7.5 使用instanceof操作符判断对象类型
1.7.6 方法的重载与多态
1.7.7 抽象类与接口
1.8:I/O与反射、多线程
1.8.1 流概述与File类
1.8.2 文件 输入/输出流
1.8.3 缓存 输入/输出流
1.8.4 Class类与Java反射
1.8.5 Annotation功能类型信息
1.8.6 枚举类型与泛型
1.8.7 创建、操作线程与线程安全
1.9:Swing程序与集合类
1.9.1 常用窗体
1.9.2 标签组件与图标
1.9.3 常用布局管理器 与面板
1.9.4 按钮组件 与列表组件
1.9.5 常用事件监听器
1.9.6 集合类概述
1.9.7 Set集合 与Map集合及接口
1.10:PC端网站布局
1.10.1 HTML基础,CSS基础,CSS核心属性
1.10.2 CSS样式层叠,继承,盒模型
1.10.3 容器,溢出及元素类型
1.10.4 浏览器兼容与宽高自适应
1.10.5 定位,锚点与透明
1.10.6 图片整合
1.10.7 表格,CSS属性与滤镜
1.10.8 CSS优化
1.11:HTML5+CSS3基础
1.11.1 HTML5新增的元素与属性
1.11.2 CSS3选择器
1.11.3 文字字体相关样式
1.11.4 CSS3位移与变形处理
1.11.5 CSS3 2D、3D转换与动画
1.11.6 弹性盒模型
1.11.7 媒体查询
1.11.8 响应式设计
1.12:WebApp页面布局项目
1.12.1 移动端页面设计规范
1.12.2 移动端切图
1.12.3 文字流式/控件弹性/图片等比例的布局
1.12.4 等比缩放布局
1.12.5 viewport/meta
1.12.6 rem/vw的使用
1.12.7 flexbox详解
1.12.8 移动web特别样式处理
1.13:原生JavaScript功能开发
1.13.1 什么是JavaScript
1.13.2 JavaScript使用及运作原理
1.13.3 JavaScript基本语法
1.13.4 JavaScript内置对象
1.13.5 事件,事件原理
1.13.6 JavaScript基本特效制作
1.13.7 cookie存储
1.13.8 正则表达式
1.14:Ajax异步交互
1.14.1 Ajax概述与特征
1.14.2 Ajax工作原理
1.14.3 XMLHttpRequest对象
1.14.4 同步与异步
1.14.5 Ajax异步交互
1.14.6 Ajax跨域问题
1.14.7 Ajax数据的处理
1.14.8 基于WebSocket和推送的实时交互
1.15:JQuery应用
1.15.1 各选择器使用及应用优化
1.15.2 Dom节点的各种操作
1.15.3 事件处理、封装、应用
1.15.4 jQuery中的各类动画使用
1.15.5 可用性表单的开发
1.15.6 jQuery Ajax、函数、缓存
1.15.7 jQuery编写插件、扩展、应用
1.15.8 理解模块式开发及应用
1.16:数据库
1.16.1 Mysql数据库
1.16.2 JDBC开发
1.16.3 连接池和DBUtils
1.16.4 Oracle介绍
1.16.5 MongoDB数据库介绍
1.16.6 apache服务器/Nginx服务器
1.16.7 Memcached内存对象缓存系统
1.17:JavaWeb开发核心
1.17.1 XML技术
1.17.2 HTTP协议
1.17.3 Servlet工作原理解析
1.17.4 深入理解Session与Cookie
1.17.5 Tomcat的系统架构与设计模式
1.17.6 JSP语法与内置对象
1.17.7 JDBC技术
1.17.8 大浏览量系统的静态化架构设计
1.18:JavaWeb开发内幕
1.18.1 深入理解Web请求过程
1.18.2 Java I/O的工作机制
1.18.3 Java Web中文编码
1.18.4 Javac编译原理
1.18.5 class文件结构
1.18.6 ClassLoader工作机制
1.18.7 JVM体系结构与工作方式
1.18.8 JVM内存管理
第二阶段:Linux系统Hadoop生态体系

2.1:Linux体系(1)
2.1.1 VMware Workstation虚拟软件安装过程、CentOS虚拟机安装过程
2.1.2 了解机架服务器,采用真实机架服务器部署linux
2.1.3 Linux的常用命令:常用命令的介绍、常用命令的使用和练习
2.1.4 Linux系统进程管理基本原理及相关管理工具如ps、pkill、top、htop等的使用
2.1:Linux体系(2)
2.1.5 Linux启动流程,运行级别详解,chkconfig详解
2.1.6 VI、VIM编辑器:VI、VIM编辑器的介绍、VI、VIM扥使用和常用快捷键
2.1.7 Linux用户和组账户管理:用户的管理、组管理
2.1.8 Linux磁盘管理,lvm逻辑卷,nfs详解
2.1:Linux体系(3)
2.1.9 Linux系统文件权限管理:文件权限介绍、文件权限的操作
2.1.10 Linux的RPM软件包管理:RPM包的介绍、RPM安装、卸载等操作
2.1.11 yum命令,yum源搭建
2.1.12 Linux网络:Linux网络的介绍、Linux网络的配置和维护
2.1:Linux体系(4)
2.1.13 Shell编程:Shell的介绍、Shell脚本的编写
2.1.14 Linux上常见软件的安装:安装JDK、安装Tomcat、安装mysql,web项目部署
2.2:Hadoop离线计算大纲(1)
2.2.1 Hadoop生态环境介绍
2.2.2 Hadoop云计算中的位置和关系
2.2.3 国内外Hadoop应用案例介绍
2.2.4 Hadoop 概念、版本、历史
2.2.5 Hadoop 核心组成介绍及hdfs、mapreduce 体系结构
2.2.6 Hadoop 的集群结构
2.2.7 Hadoop 伪分布的详细安装步骤
2.2:Hadoop离线计算大纲(2)
2.2.8 通过命令行和浏览器观察hadoop
2.2.9 HDFS底层&& datanode,namenode详解&&shell&&Hdfs java api
2.2.10 Mapreduce四个阶段介绍
2.2.11 Writable
2.2.12 InputSplit和OutputSplit
2.2.13 Maptask
2.2.14 Shuffle:Sort,Partitioner,Group,Combiner
2.2:Hadoop离线计算大纲(3)
2.2.15 Reducer
2.2.16 Mapreducer案例:1) 二次排序
2.2.17 倒排序索引
2.2.18 最优路径
2.2.19 电信数据挖掘之-----移动轨迹预测分析(中国棱镜计划)
2.2.20 社交好友推荐算法
2.2.21 互联网精准广告推送 算法
2.2:Hadoop离线计算大纲(4)
2.2.22 阿里巴巴天池大数据竞赛 《天猫推荐算法》
2.2.23 Mapreduce实战pagerank算法
2.2.24 Hadoop2.x集群结构体系介绍
2.2.25 Hadoop2.x集群搭建
2.2.26 NameNode的高可用性(HA)
2.2.27 HDFS Federation
2.2:Hadoop离线计算大纲(5)
2.2.28 ResourceManager 的高可用性(HA)
2.2.29 Hadoop集群常见问题和解决方法
2.2.30 Hadoop集群管理
2.3:分布式数据库Hbase(1)
2.3.1 Hbase简介
2.3.2 HBase与RDBMS的对比
2.3.3 数据模型
2.3.4 系统架构
2.3.5 HBase上的MapReduce
2.3.6 表的设计
2.3.7 集群的搭建过程讲解
2.3.8 集群的监控
2.3:分布式数据库Hbase(2)
2.3.9 集群的管理
2.3.10 HBase Shell以及演示
2.3.11 Hbase 树形表设计
2.3.12 Hbase 一对多 和 多对多 表设计
2.3.13 Hbase 微博 案例
2.3.14 Hbase 订单案例
2.3.15 Hbase表级优化
2.3:分布式数据库Hbase(3)
2.3.16 Hbase 写数据优化
2.3.17 Hbase 读数据优化
2.3.18 Hbase API操作
2.3.19 hbase mapdreduce 和hive 整合
2.4:数据仓库Hive(1)
2.4.1 数据仓库基础知识
2.4.2 Hive定义
2.4.3Hive体系结构简介
2.4.4 Hive集群
2.4.5客户端简介
2.4.6 HiveQL定义
2.4.7 HiveQL与SQL的比较
2.4.8 数据类型
2.4:数据仓库Hive(2)
2.4.9 外部表和分区表
2.4.10 ddl与CLI客户端演示
2.4.11 dml与CLI客户端演示
2.4.12 select与CLI客户端演示
2.4.13 Operators 和 functions与CLI客户端演示
2.4.14 Hive server2 与jdbc
2.4:数据仓库Hive(3)
2.4.15 用户自定义函数(UDF 和 UDAF)的开发与演示
2.4.16 Hive 优化
2.4.17 serde
2.5:数据迁移工具Sqoop
2.5.1 Sqoop简介以及使用
2.5.2 Sqoop shell使用
2.5.3 Sqoop-import
2.5.4 DBMS-hdfs
2.5.5 DBMS-hive
2.5.6 DBMS-hbase
2.5.7 Sqoop-export
2.6:Flume分布式日志框架(1)
2.6.1 flume简介-基础知识 2.6.2 flume安装与测试
2.6.3 flume部署方式
2.6.4 flume source相关配置及测试
2.6.5 flume sink相关配置及测试
2.6.6 flume selector 相关配置与案例分析
2.6.7 flume Sink Processors相关配置和案例分析
2.6:Flume分布式日志框架(2)
2.6.8 flume Interceptors相关配置和案例分析
2.6.9 flume AVRO Client开发
2.6.10 flume 和kafka 的整合
第三阶段:分布式计算框架:Spark&Storm生态体系
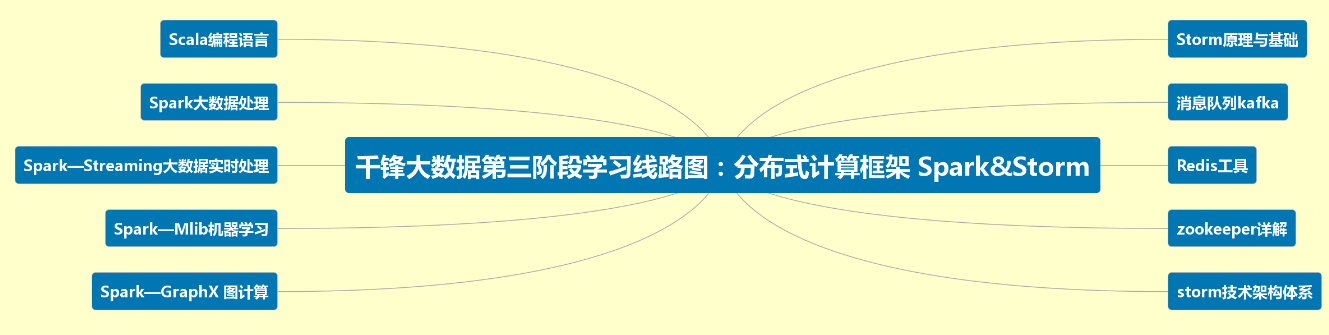
3.1:Scala编程语言(1)
3.1.1 scala解释器、变量、常用数据类型等
3.1.2 scala的条件表达式、输入输出、循环等控制结构
3.1.3 scala的函数、默认参数、变长参数等
3.1.4 scala的数组、变长数组、多维数组等
3.1.5 scala的映射、元组等操作
3.1.6 scala的类,包括bean属性、辅助构造器、主构造器等
3.1:Scala编程语言(2)
3.1.7 scala的对象、单例对象、伴生对象、扩展类、apply方法等
3.1.8 scala的包、引入、继承等概念
3.1.9 scala的特质
3.1.10 scala的操作符
3.1.11 scala的高阶函数
3.1.12 scala的集合
3.1.13 scala数据库连接
3.2:Spark大数据处理(1)
3.2.1 Spark介绍
3.2.2 Spark应用场景
3.2.3 Spark和Hadoop MR、Storm的比较和优势
3.2.4 RDD
3.2.5 Transformation
3.2.6 Action
3.2.7 Spark计算PageRank
3.2:Spark大数据处理(2)
3.2.8 Lineage
3.2.9 Spark模型简介
3.2.10 Spark缓存策略和容错处理
3.2.11 宽依赖与窄依赖
3.2.12 Spark配置讲解
3.2.13 Spark集群搭建
3.2.15 集群搭建常见问题解决
3.2.16 Spark原理核心组件和常用RDD
3.2:Spark大数据处理(3)
3.2.17 数据本地性
3.2.18 任务调度
3.2.19 DAGScheduler
3.2.20 TaskScheduler
3.2.21 Spark源码解读
3.2.22 性能调优
3.2.23 Spark和Hadoop2.x整合:Spark on Yarn原理
3.3:Spark—Streaming大数据实时处理
3.3.1 Spark Streaming:数据源和DStream
3.3.2 无状态transformation与有状态transformation
3.3.3 Streaming Window的操作
3.3.4 sparksql 编程实战
3.3.5 spark的多语言操作
3.3.6 spark最新版本的新特性
3.4:Spark—Mlib机器学习(1)
3.4.1 Mlib简介
3.4.2 Spark MLlib组件介绍
3.4.3 基本数据类型
3.4.4 回归算法
3.4.5 广义线性模型
3.4.6 逻辑回归
3.4.7 分类算法
3.4.8 朴素贝叶斯
3.4:Spark—Mlib机器学习(2)
3.4.9 决策树
3.4.10 随机森林
3.4.11 推荐系统
3.4.12 聚类
a) Kmeans b) Sparse kmeans
c) Kmeans++ d) Kmeans II
e) Streaming kmeans
f) Gaussian Mixture Model
3.5:Spark—GraphX 图计算
3.5.1 二分图
3.5.2 概述
3.5.3 构造图
3.5.4 属性图
3.5.5 PageRank
3.6:storm技术架构体系(1)
3.6.1 项目技术架构体系
3.6.2 Storm是什么
3.6.3 Storm架构分析
3.6.4 Storm编程模型、Tuple源码、并发度分析
3.2.5 Transformation
3.6:storm技术架构体系(2)
3.6.6 Maven环境快速搭建
3.6.7 Storm WordCount案例及常用Api
3.6.8 Storm+Kafka+Redis业务指标计算
3.6.9 Storm集群安装部署
3.6.10 Storm源码下载编译
3.7:Storm原理与基础(1)
3.7.1 Storm集群启动及源码分析
3.7.2 Storm任务提交及源码分析
3.7.3 Storm数据发送流程分析
3.7.4 Strom通信机制分析浅谈
3.7.5 Storm消息容错机制及源码分析
3.7.6 Storm多stream项目分析
3.7.7 Storm Trident和传感器数据
3.7:Storm原理与基础(2)
3.7.8 实时趋势分析
3.8.9 Storm DRPC(分布式远程调用)介绍
3.7.10 Storm DRPC实战讲解
3.7.11 编写自己的流式任务执行框架
3.8:消息队列kafka
3.8.1 消息队列是什么
3.8.2 kafka核心组件
3.8.3 kafka集群部署实战及常用命令
3.8.4 kafka配置文件梳理
3.8.5 kafka JavaApi学习
3.8.6 kafka文件存储机制分析
3.8.7 kafka的分布与订阅
3.8.8 kafka使用zookeeper进行协调管理
3.9:Redis工具
3.9.1 nosql介绍
3.9.2 redis介绍
3.9.3 redis安装
3.9.4 客户端连接
3.9.5 redis的数据功能
3.9.6 redis持久化
3.9.7 redis应用案例
3.10:zookeeper详解
3.10.1 zookeeper简介
3.10.2 zookeeper的集群部署
3.10.3 zookeeper的核心工作机制
3.10.4 zookeeper的命令行操作
3.10.5 zookeeper的客户端API
3.10.6 zookeeper的应用案例
3.10.7 zookeeper的原理补充
第四阶段:大数据项目实战

4.1:阿里巴巴的淘宝电商的大数据流量分析平台(1)
4.1.1项目介绍(1)
淘宝网站的日志分析和订单管理在实战 中学习,技术点非常多,一个访客(UV) 点击进入后计算的一个流量,同时也有 浏览量(PV)指的是一个访客(UV) 在店内所浏览的次数。一个UV最少产 生一个PV,PV/UV就是俗称的访问 深度,一个访客
4.1:阿里巴巴的淘宝电商的大数据流量分析平台(2)
4.1.1项目介绍(2)
(UV)在店内所浏览的次数。一个UV最少产 生一个PV,PV/UV就是俗称的访问 深度,一个访客(UV)点击进入 后计算的一个流量,同时也有浏览 量(PV)指的是一个访客(UV) 在店内所浏览的次数。一个UV最少产生 一个PV,PV/UV就是俗称的访问深度
4.1:阿里巴巴的淘宝电商的大数据流量分析平台(3)
4.1.1项目介绍(3)
影响自然排名自然搜索的叫权重, 权重是决定一个产品是否排在前面 获得更多流量的决定性因素,权重的 构成多达几十种,通常影响权重的有 销量,好评,收藏,DSR,维护时间, 下架时间这类。
4.1:阿里巴巴的淘宝电商的大数据流量分析平台(4)
4.1.2项目特色
怎样实际运用这些点是我们在自学 过程中体验不到的。Cookie日志 分析包括:pv、uv,跳出率,二跳 率、广告转化率、搜索引擎优化等, 订单模块有:产品推荐,商家排名, 历史订单查询,订单报表统计等。
4.1:阿里巴巴的淘宝电商的大数据流量分析平台(5)
4.1.3 项目架构
SDK(JavaaSDK、JSSDK)+
lvs+nginx集群+flume+
hdfs2.x+hive+hbase+MR+MySQL
4.1:阿里巴巴的淘宝电商的大数据流量分析平台(6)
4.1.4 项目流程(1)
a) 数据获取:Web项目和云计算项 目的整合
b) 数据处理:Flume通过avro实 时收集web项目中的日志
c) 数据的ETL
d) 数据展存储:Hive 批量 sql执行 e) Hive 自定义函数
4.1:阿里巴巴的淘宝电商的大数据流量分析平台(7)
4.1.4 项目流程(2)
f) Hive和hbase整合。
g) Hbase 数据支持 sql查询分析
h) 数据分析:数据Mapreduce数 据挖掘
i) Hbase dao处理
j) Sqoop 在项目中的使用。
k) 数据可视化:Mapreduce定时 调用和监控
4.2:实战一:Sina微博基于Spark的推荐系统(1)
4.2.1 项目介绍(1)
个性化推荐是根据用户的兴趣特点 和购买行为,向用户推荐用户感兴 趣的信息和商品。随着电子商务规 模的不断扩大,商品个数和种类快 速增长,顾客需要花费大量的时间 才能找到自己想买的商品。这种浏 览大量无关的信息和产品过程无疑 会使淹没在信息过载
4.2:实战一:Sina微博基于Spark的推荐系统(2)
4.2.1 项目介绍(2)
问题中的消费者不断流失。为了解决这些问题, 个性化推荐系统应运而生。个性化 推荐系统是建立在海量数据挖掘基 础上的一种高级商务智能平台,以 帮助电子商务网站为其顾客购物提 供完全个性化的决策支持和信息服务
4.2:实战一:Sina微博基于Spark的推荐系统(3)
4.2.2 项目特色(1)
推荐系统是个复杂的系统工程, 依赖工程、架构、算法的有机结 合,是数据挖掘技术、信息检索 技术、计算统计学的智慧结晶, 学员只有亲手动手才能体会推荐 系统的各个环节,才能对各种推 荐算法的优缺点有真实的感受。 一方面可以很熟练的完成简单的
4.2:实战一:Sina微博基于Spark的推荐系统(4)
4.2.2 项目特色(2)
推荐算法,如content-based、
item-based CF 等。另一方面
要掌握一些常见的推荐算法库,
如:SvdFeature、LibFM、
Mathout、Mlib等。
4.2:实战一:Sina微博基于Spark的推荐系统(5)
4.2.3 项目技术架构体系(1)
a) 实时流处理 Kafka,Spark Streaming
b) 分布式运算 Hadoop,Spark
c) 数据库 Hbase,Redis
d) 机器学习 Spark Mllib
e) 前台web展示数据 Struts2, echart
4.2:实战一:Sina微博基于Spark的推荐系统(6)
4.2.3 项目技术架构体系(2)
f) 分布式平台 Hadoop,Spark
g) 数据清洗 Hive
h) 数据分析 R RStudio
i) 推荐服务 Dubbox
j) 规则过滤 Drools
k) 机器学习 MLlib
4.3:实战二:Sina门户的DSP广告投放系统(1)
4.3.1 项目介绍
新浪网(www.sina.com.cn),
是知名的门户网站,该项目主要通
过收集新浪的Cookie每个产生的日
志,分析统计出该网站的流量相关
信息和竞价广告位
4.3:实战二:Sina门户的DSP广告投放系统(2)
4.3.2 项目特色
在互联网江湖中,始终流传着三大 赚钱法宝:广告、游戏、电商,在 移动互联网兴起之际,利用其得天 独厚的数据优势,终于能够回答困 扰了广告主几百年的问题:我的广 告究竟被谁看到了?浪费的一半的 钱到底去了哪里?
4.3:实战二:Sina门户的DSP广告投放系统(3)
4.3.3 项目技术架构体系(1)
a)通过flume把日志数据导入到 HDFS中,使用hive进行数据清洗 b)提供web视图供用户使用,输入 查询任务参数,写入MySQL c)使用spark根据用户提交的任 务参数,进行session分析,进 行单挑率分析
4.3:实战二:Sina门户的DSP广告投放系统(4)
4.3.3 项目技术架构体系(2)
d)使用spark sql进行各类型热 门广告统计 e)使用 flume将广告点击日志传 入kafka,使用spark streaming 进行广告点击率的统计 f)web页面显示MySQL中存储的任务 执行结果
4.4:实战三:商务日志告警系统项目(1)
4.4.1 项目介绍(1)
基于的日志进行监控,监控需要一定规 则,对触发监控规则的日志信息进行告 警,告警的方式,是短信和邮件,随着 公司业务发展,支撑公司业务的各种系 统越来越多,为了保证公司的业务正常 发展,急需要对这些线上系统的运行进
4.4:实战三:商务日志告警系统项目(2)
4.4.1 项目介绍(2)
行监控,做到问题的及时发现和处理, 最大程度减少对业务的影响。
4.4.2 项目特色(1)
整体架构设计很完善, 主要架构为应 用 a)应用程序使用log4j产生日志
b)部署flume客户
4.4:实战三:商务日志告警系统项目(3)
4.4.2 项目特色(2)
端监控应用程序产生的日志信息,并发送到kafka集群中
c)storm spout拉去kafka的数据进 行消费,逐条过滤每条日志的进行规 则判断,对符合规则的日志进行邮件 告警。
4.4:实战三:商务日志告警系统项目(4)
4.4.2 项目特色(3)
d)最后将告警的信息保存到mysql数 据库中,用来进行管理。
4.4.3 项目技术架构体系
a)推荐系统基础知识 b)推荐系统开发流程分析 c)mahout协同过滤Api使用 d)Java推荐引擎开发实战 e)推荐系统集成运行
4.5:实战四:互联网猜你喜欢推荐系统实战(1)
4.5.1 项目介绍(1)
到网上购物的人已经习惯了收到系统为 他们做出的个性化推荐。Netflix 会推 荐你可能会喜欢看的视频。TiVo会自动 把节目录下来,如果你感兴趣就可以看。 Pandora会通过预测我们想要听什么歌 曲从而生成个性化的音乐流。所有这些
4.5:实战四:互联网猜你喜欢推荐系统实战(2)
4.5.1 项目介绍(2)
推荐结果都来自于各式各样的推荐系统。 它们依靠计算机算法运行,根据顾客的 浏览、搜索、下单和喜好,为顾客选择 他们可能会喜欢、有可能会购买的商品, 从而为消费者服务。推荐系统的设计初 衷是帮助在线零售商提高销售额,现在 这是一块儿规模巨大且
4.5:实战四:互联网猜你喜欢推荐系统实战(3)
4.5.1 项目介绍(3)
不断增长的业务。与此同时,推荐系统的开发也已经 从上世纪 90 年代中期只有几十个人研 究,发展到了今天拥有数百名研究人员, 分别供职于各高校、大型在线零售商和 数十家专注于这类系统的其他企业。
4.5:实战四:互联网猜你喜欢推荐系统实战(4)
4.5.2 项目特色(1)
有没有想过自己在亚马逊眼中是什么 样子?答案是:你是一个很大、很大 的表格里一串很长的数字。这串数字 描述了你所看过的每一样东西,你点 击的每一个链接以及你在亚马逊网站 上买的每一件商品;表格里的其余部
4.5:实战四:互联网猜你喜欢推荐系统实战(5)
4.5.2 项目特色(2)
分则代表了其他数百万到亚马逊购 物的人。你每次登陆网站,你的数字 就会发生改变;在此期间,你在网站 上每动一下,这个数字就会跟着改变。 这个信息又会反过来影响你在访问的 每个页面上会看到什么,还有你会从 亚马逊公司收到什么邮件和优惠信息。
4.5:实战四:互联网猜你喜欢推荐系统实战(6)
4.5.3 项目技术架构体系
a)推荐系统基础知识
b)推荐系统开发流程分析
c)mahout协同过滤Api使用
d)Java推荐引擎开发实战
e)推荐系统集成运行
第五阶段:大数据分析方向AI(人工智能)

5.1 Python编程&&Data Analyze工作环境准备&数据分析基础(1)
5.1.1介绍Python以及特点
5.1.2 Python的安装
5.1.3 Python基本操作(注释、逻辑、 字符串使用等)
5.1.4 Python数据结构(元组、列表、字典)
5.1 Python编程&&Data Analyze工作环境准备&数据分析基础(2)
5.1.5 使用Python进行批量重命名小例子
5.1.6 Python常见内建函数
5.1.7 更多Python函数及使用常见技巧
5.1.8 异常
5.1.9 Python函数的参数讲解
5.1.10 Python模块的导入
5.1 Python编程&&Data Analyze工作环境准备&数据分析基础(3)
5.1.11 Python中的类与继承
5.1.12 网络爬虫案例
5.1.13 数据库连接,以及pip安装模块
5.1.14 Mongodb基础入门
5.1.15 讲解如何连接mongodb
5.1.16 Python的机器学习案例
5.1 Python编程&&Data Analyze工作环境准备&数据分析基础(4)
5.1.17 AI&&机器学习&&深度学习概论
5.1.18 工作环境准备
5.1.19 数据分析中常用的Python技巧
5.1.20 Pandas进阶及技巧
5.1.21 数据的统计分析
5.2:数据可视化
5.2.1 数据可视化的概念
5.2.2 图表的绘制及可视化
5.2.3 动画及交互渲染
5.2.4 数据合并、分组
5.3:Python机器学习-1(1)
5.3.1 机器学习的基本概念
5.3.2 ML工作流程
5.3.3 Python机器学习库scikit-learn
5.3.4 KNN模型
5.3.5 线性回归模型
5.3.6 逻辑回归模型
5.3.7 支持向量机模型
5.3:Python机器学习-1(2)
5.3.8 决策树模型
5.3.9 超参数&&学习参数
5.4:Python机器学习-2
5.4.1 模型评价指标
5.4.2 交叉验证
5.4.3 机器学习经典算法
5.4.4 朴素贝叶斯
5.4.5 随机森林
5.4.6 GBDT
5.5:图像识别&&神经网络
5.5.1 图像操作的工作流程
5.5.2 特征工程
5.5.3 图像特征描述
5.5.4 AI网络的描述
5.5.5 深度学习
5.5.6 TensorFlow框架学习
5.5.7 TensorFlow框架卷积神经网络(CNN)
5.6:自然语言处理&&社交网络处理
5.6.1 Python文本数据处理
5.6.2 自然语言处理及NLTK
5.6.3 主题模型
5.6.4 LDA
5.6.5 图论简介
5.6.6 网络的操作及数据可视化
5.7:实战项目:《户外设备识别分析》(1)
5.7.1 项目介绍:
用户行为识别数据是由用户 腰间的智能手机记录的, 常 建改数据集的目的是用于识 别分类6组不同的用户行为, 通过智能手机的加速计和螺旋 仪能够以50HZ的频率采集3个 方向的加速度和3个方向的角 速度,采集后的数据分成, 70%训练集,30%测试集。
5.7:实战项目:《户外设备识别分析》(2)
5.7.2项目特色(1)
为了保证线路和设备巡检的顺利进 行,减少不必要的经济损失,改革 传统落后巡检方式的呼声越来越 高。如何监督巡检人员巡检路线的 到位情况和工作状态以及巡检工作 的规范化管理已经成为电网管理者 普遍关注和亟待解决的问题。 系统架构
5.7:实战项目:《户外设备识别分析》(3)
5.7.2项目特色(2)
系统硬件构架包括:固定式读写器、 天线、RFID手持设备、标签及服务器。 数据交换方式,可以采用两种方式 进行实施: 1)在线数据交换,通过固定式读写 器将现场数据实时传回后台信息系 统进行处理分析。
5.7:实战项目:《户外设备识别分析》(4)
5.7.2项目特色(3)
2)离线数据交换,通过手持设备 在现场数据采集完数据后,导入至 后台信息系统进行处理分析。
转载自https://www.cnblogs.com/Bigata/p/9566003.html
如有侵权,请立即联系删除

