

基于openpyxl处理.xlsx过程遇到的小问题
前提
偶然一次遇到要处理大量的表格- -,处理步骤不难但是大量重复性劳作比较麻烦,尝试使用python来处理,以下是在过程中遇到的一些小问题记录一下
基于Python 3.10.11,使用openpyxl库
openpyxl库的简单使用介绍
安装openpyxl库
pip install openpyxl
增
1、打开/创建 一个工作簿并添加数据
import openpyxl
# 打开已有文件
# file_path = "E:\xxx\xxx\Examples.xlsx"
file_path = "Examples.xlsx"
wb = openpyxl.load_workbook(file_path)
# 创建一个新的Excel文件
# wb = openpyxl.Workbook()
# 获取工作表
ws = wb.active
print("选择的工作表:", ws)
# 在工作表中添加数据
ws['A1'] = 'Hello'
ws['B1'] = 'World!'
ws['C2'] = 11
ws['D2'] = 22
# 保存 不保存上面做的更改是不会写入到文件中的
wb.save(file_path)
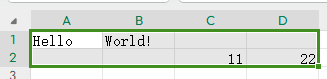
第一个坑 wb.active这个属性,在网上找资料时介绍这个是获取默认的工作表,但在实际使用中感觉应该是获取“活动”的工作表(这里可能是本人理解失误导致的)
先执行一次上述代码后数据会写入sheet1中,打开Excel表格,只要选择其他sheet页面后保存,此时再次执行上述代码数据会写入到刚才最后所停留的sheet页面中
例如第一次写入后打开文件选择了Sheet3页面后保存,再执行上述的代码会如下输出
第一次执行
>>>选择的工作表: <Worksheet "Sheet1">
第二次执行
>>>选择的工作表: <Worksheet "Sheet3">
2、打开现有的工作簿并写入一行数据
import openpyxl
new_row_data = ["Dai", 23, "boy"]
# 打开现有的工作簿
file_path = "Examples.xlsx"
wb = openpyxl.load_workbook(file_path)
# 获取指定的工作表
ws = wb["Sheet1"]
# 添加一行数据
ws.append(new_row_data)
wb.save(file_path)
ws.append() 该函数会在最下面一行内没有任何数据的位置写入数据

删
3、删除已有的工作表
import openpyxl
# 打开已有文件
# file_path = "E:\xxx\xxx\Examples.xlsx"
file_path = "Examples.xlsx"
wb = openpyxl.load_workbook(file_path)
ws = wb['Sheet1'] # 选择要删除的工作表
wb.remove(ws) # 删除工作表
# 保存 不保存上面做的更改是不会写入到文件中的
wb.save(file_path)
改
4、修改已有的数据
改数据与添加数据基本一致,找到对应的索引,然后赋值,保存即可
import openpyxl
# 打开已有文件
# file_path = "E:\xxx\xxx\Examples.xlsx"
file_path = "Examples.xlsx"
wb = openpyxl.load_workbook(file_path)
# 创建一个新的Excel文件
# wb = openpyxl.Workbook()
# 获取工作表
ws = wb.active
print("选择的工作表:", ws)
# 在工作表中更改数据
ws['A1'] = 'New Value'
ws['B2'] = 'New Value2'
ws['C2'] = 33
ws['D2'] = 44
# 保存 不保存上面做的更改是不会写入到文件中的
wb.save(file_path)
查
5、打开现有的工作簿并读取数据
import openpyxl
# 打开现有的工作簿
file_path = "Examples.xlsx"
wb= openpyxl.load_workbook(file_path)
# 获取指定的工作表
ws= wb["Sheet1"]
# 读取单元格数据
value1 = ws['A1'].value # 通过索引获取数据
value2 = ws.cell(row=2, column=3).value # 第二行第3列
print(value1) # 输出:Hello
print(value2) # 输出:11
ws.cell(row=2, column=3).value中row对应Excel的行column对应Excel的列,需要注意Excel中行列都是从1开始的,没有第0行/列
6、打开现有的工作簿并读取数据
import openpyxl
wb = load_workbook('xxx.xlsx')
ws = wb.active
for row in ws.iter_rows(min_row=1, max_row=ws.max_row, values_only=True):
for cell_value in row:
print(cell_value)
实际应用
前提:有不固定行数的若干行数据,需要提出其中4列的数据,计算平均值、标准差等数据
OK我们基于上述的增删改查再进行一点适当的更改,一个简易的脚本文件就写完了
点击查看代码
import os
import numpy as np
import openpyxl
# out数据页面索引
_STD_ROWINDEX = 2 # 标准差行索引
_STD_COLINDEX = 6 # 标准差列索引
_MEAN_ROWINDEX = 2 # 最终平均值行索引
_MEAN_COLINDEX = 7 # 最终平均值列索引
_COLMEAN_ROWINDEX = 4 # 4列的平均值行索引
_COLMEAN_COLINDEX = 6 # 4列的平均值列索引
_ROWMEAN_COLINDEX = 5 # 每4行平均值列索引
# integrated页面索引
_START_ROW_INDEX = 2
_START_COL_INDEX = 1
# 导出文件
_NEW_EXCEL = {
"file_name": "Output.xlsx",
"fpage_name": "Integrated_data",
"page_name": "out",
}
# 筛选对应列
_COLUMN_NAMES = ["27_dis", "28_dis", "35_dis", "36_dis"]
# 实际对应数据
_TRUTH_VALUE = [
0.1,
0.2,
0.3,
0.4,
0.5,
0.6,
0.7,
0.8,
0.9,
1,
1.5,
2,
2.38,
4,
]
_TRUTH_VALUE_100K = [
0.2,
0.3,
0.4,
0.5,
0.6,
0.7,
0.8,
0.9,
1,
1.1,
]
final_data = []
is_100k = 1
# 获取当前脚本所在路径
def get_dir():
return os.listdir(os.getcwd())
# 创建新的xlsx文件与工作表,用来输出最终存储文件
def new_xlsx(path=_NEW_EXCEL["file_name"], title=_NEW_EXCEL["fpage_name"]):
wb = openpyxl.Workbook()
ws = wb.active
ws.title = title
wb.save(path)
print(f"文件 {path} 创建成功")
return wb
def delete_workbook(path=_NEW_EXCEL["file_name"]):
try:
os.remove(path)
print(f"文件 {path} 已成功删除。")
except FileNotFoundError:
print(f"文件 {path} 不存在。")
except Exception as e:
print(f"删除文件 {path} 时出现错误:{e}")
def copy_to_workbook(file_path, column_names, cp_to_path=_NEW_EXCEL["file_name"]):
data_to_copy = [] # 缓存文件
wb = openpyxl.load_workbook(file_path)
ws = wb.worksheets[0]
to_wb = openpyxl.load_workbook(cp_to_path)
to_ws = to_wb.create_sheet(_NEW_EXCEL["page_name"])
for row in ws.iter_rows(min_row=1, max_row=1, values_only=True):
if all(col_name in row for col_name in column_names):
column_indices = [row.index(col_name) for col_name in column_names] # 获取列索引
else:
print("该文件没有对应列")
# 获取源工作表中的四列数据
for row in ws.iter_rows(values_only=True):
data_row = [row[indices] for indices in column_indices]
if "27_dis" not in row:
data_to_copy.append(data_row)
to_ws.append(data_row)
# 获取4列的平均值并导入
column_mean = np.mean(data_to_copy, axis=0)
to_ws.cell(row=3, column=6, value="one_mean:")
to_ws.cell(row=3, column=7, value="two_mean:")
to_ws.cell(row=3, column=8, value="three_mean:")
to_ws.cell(row=3, column=9, value="four_mean:")
colindex_value = _COLMEAN_COLINDEX
for mean_value in column_mean:
to_ws.cell(
row=_COLMEAN_ROWINDEX,
column=colindex_value,
value=mean_value,
)
colindex_value += 1
# 4列平均值的平均值
mean = np.mean(column_mean, axis=0)
to_ws.cell(row=1, column=7, value="mean:")
to_ws.cell(row=_MEAN_ROWINDEX, column=_MEAN_COLINDEX, value=mean)
# 获取4列原数据中每行4个的平均值
row_mean = np.mean(data_to_copy, axis=1)
to_ws.cell(row=1, column=5, value="row_mean")
for rowmean_rowindex, value in enumerate(row_mean, start=1):
to_ws.cell(row=rowmean_rowindex + 1, column=_ROWMEAN_COLINDEX, value=value)
# 标准差
std_data = np.std(row_mean)
to_ws.cell(row=1, column=6, value="std:")
to_ws.cell(row=_STD_ROWINDEX, column=_STD_COLINDEX, value=std_data)
final_data.append([std_data, mean])
to_wb.save(cp_to_path)
def write_to_new(final_data, path=_NEW_EXCEL["file_name"]):
wb = openpyxl.load_workbook(path)
ws = wb[_NEW_EXCEL["fpage_name"]]
# 冒泡排序
n = len(final_data)
for i in range(n):
for j in range(0, n - i - 1):
if final_data[j][1] > final_data[j + 1][1]:
final_data[j], final_data[j + 1] = final_data[j + 1], final_data[j]
# 写入标准差与平均值
to_err = []
ws.cell(row=1, column=1, value="std:")
ws.cell(row=1, column=2, value="mean:")
for row_index, row_data in enumerate(final_data):
for col_index, value in enumerate(row_data):
ws.cell(
row=_START_ROW_INDEX + row_index,
column=_START_COL_INDEX + col_index,
value=value,
)
if col_index == 1:
to_err.append(value)
# 写入真值
ws.cell(row=1, column=3, value="truth:")
if is_100k:
truth = _TRUTH_VALUE_100K
else:
truth = _TRUTH_VALUE
for tv, t_value in enumerate(truth):
ws.cell(row=tv + 2, column=3, value=t_value)
# 写入误差
ws.cell(row=1, column=4, value="error:")
for tv, t_value in enumerate(to_err):
ws.cell(row=tv + 2, column=4, value=t_value - truth[tv])
# 保存文件
wb.save(path)
print("写入完成")
if __name__ == "__main__":
dirs = get_dir()
new_xlsx()
c = 0
for fp in dirs:
# 通过os自带的函数遍历当前文件路径下的文件,寻找到其他.xlsx文件
if os.path.splitext(fp)[1] == ".xlsx":
# 这里是个人的过滤判断所处理的文件都含有Nlink关键字,~是为了防止已打开wps自动生成的临时文件
if "NLink" in fp and "~" not in fp:
print("正在处理" + fp + "...")
copy_to_workbook(fp, _COLUMN_NAMES)
c += 1
if c >= 1:
print("数据处理完成")
print("开始写入目标文件")
write_to_new(final_data)
else:
print("未找到.xlsx文件")
delete_workbook()
在进行测试时发现numpy提供的std标准差的函数与wps和office的标准差函数算出来的结果不同,大概会差0.001左右,百度了一下是因为内部的算法不同导致的,我这里是因为相差不大不影响就没有再研究了,有需求的可以看看网上大佬的解析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号