实验14-1使用cnn完成MNIST手写体识别(tf)+实验14-2使用cnn完成MNIST手写体识别(keras)
版本python3.7 tensorflow版本为tensorflow-gpu版本2.6
实验14-1使用cnn完成MNIST手写体识别(tf)运行结果:

代码:
import tensorflow as tf # Tensorflow提供了一个类来处理MNIST数据 from tensorflow.examples.tutorials.mnist import input_data import time # 载入数据集 mnist = input_data.read_data_sets('MNIST', one_hot=True) # 设置批次的大小 batch_size = 100 # 计算一共有多少个批次 n_batch = mnist.train.num_examples // batch_size # 定义初始化权值函数 def weight_variable(shape): initial = tf.compat.v1.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) # 定义初始化偏置函数 def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) # 卷积层 def conv2d(input, filter): return tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME') # 池化层 def max_pool_2x2(value): return tf.nn.max_pool(value, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 输入层 # 定义两个placeholder tf.compat.v1.disable_eager_execution() x = tf.compat.v1.placeholder(tf.float32, [None, 784]) # 28*28 y = tf.compat.v1.placeholder(tf.float32, [None, 10]) # 改变x的格式转为4维的向量[batch,in_hight,in_width,in_channels] x_image = tf.reshape(x, [-1, 28, 28, 1]) # 卷积、激励、池化操作 # 初始化第一个卷积层的权值和偏置 W_conv1 = weight_variable([5, 5, 1, 32]) # 5*5的采样窗口,32个卷积核从1个平面抽取特征 b_conv1 = bias_variable([32]) # 每一个卷积核一个偏置值 # 把x_image和权值向量进行卷积,再加上偏置值,然后应用于relu激活函数 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) # 进行max_pooling 池化层 # 初始化第二个卷积层的权值和偏置 W_conv2 = weight_variable([5, 5, 32, 64]) # 5*5的采样窗口,64个卷积核从32个平面抽取特征 b_conv2 = bias_variable([64]) # 把第一个池化层结果和权值向量进行卷积,再加上偏置值,然后应用于relu激活函数 h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2) # 池化层 # 28*28的图片第一次卷积后还是28*28,第一次池化后变为14*14 # 第二次卷积后为14*14,第二次池化后变为了7*7 # 经过上面操作后得到64张7*7的平面 # 全连接层 # 初始化第一个全连接层的权值 W_fc1 = weight_variable([7 * 7 * 64, 1024]) # 经过池化层后有7*7*64个神经元,全连接层有1024个神经元 b_fc1 = bias_variable([1024]) # 1024个节点 # 把池化层2的输出扁平化为1维 h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64]) # 求第一个全连接层的输出 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # keep_prob用来表示神经元的输出概率 keep_prob = tf.compat.v1.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 初始化第二个全连接层 W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) # 输出层 # 计算输出 prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # 交叉熵代价函数 cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction)) # 使用AdamOptimizer进行优化 train_step = tf.compat.v1.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 结果存放在一个布尔列表中(argmax函数返回一维张量中最大的值所在的位置) correct_prediction = tf.equal(tf.argmax(prediction, 1), tf.argmax(y, 1)) # 求准确率(tf.cast将布尔值转换为float型) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 创建会话 with tf.compat.v1.Session() as sess: start_time = time.clock() sess.run(tf.compat.v1.global_variables_initializer()) # 初始化变量 for epoch in range(21): # 迭代21次(训练21次) for batch in range(n_batch): batch_xs, batch_ys = mnist.train.next_batch(batch_size) sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 0.7}) # 进行迭代训练 # 测试数据计算出准确率 acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0}) print('Iter' + str(epoch) + ',Testing Accuracy=' + str(acc)) end_time = time.clock() print('Running time:%s Second' % (end_time - start_time)) # 输出运行时间
实验14-2使用cnn完成MNIST手写体识别(keras):
这个要远程下载数据集,因为有点慢,我就下载数据集到本地,要它读取本地的数据集:
运行结果:
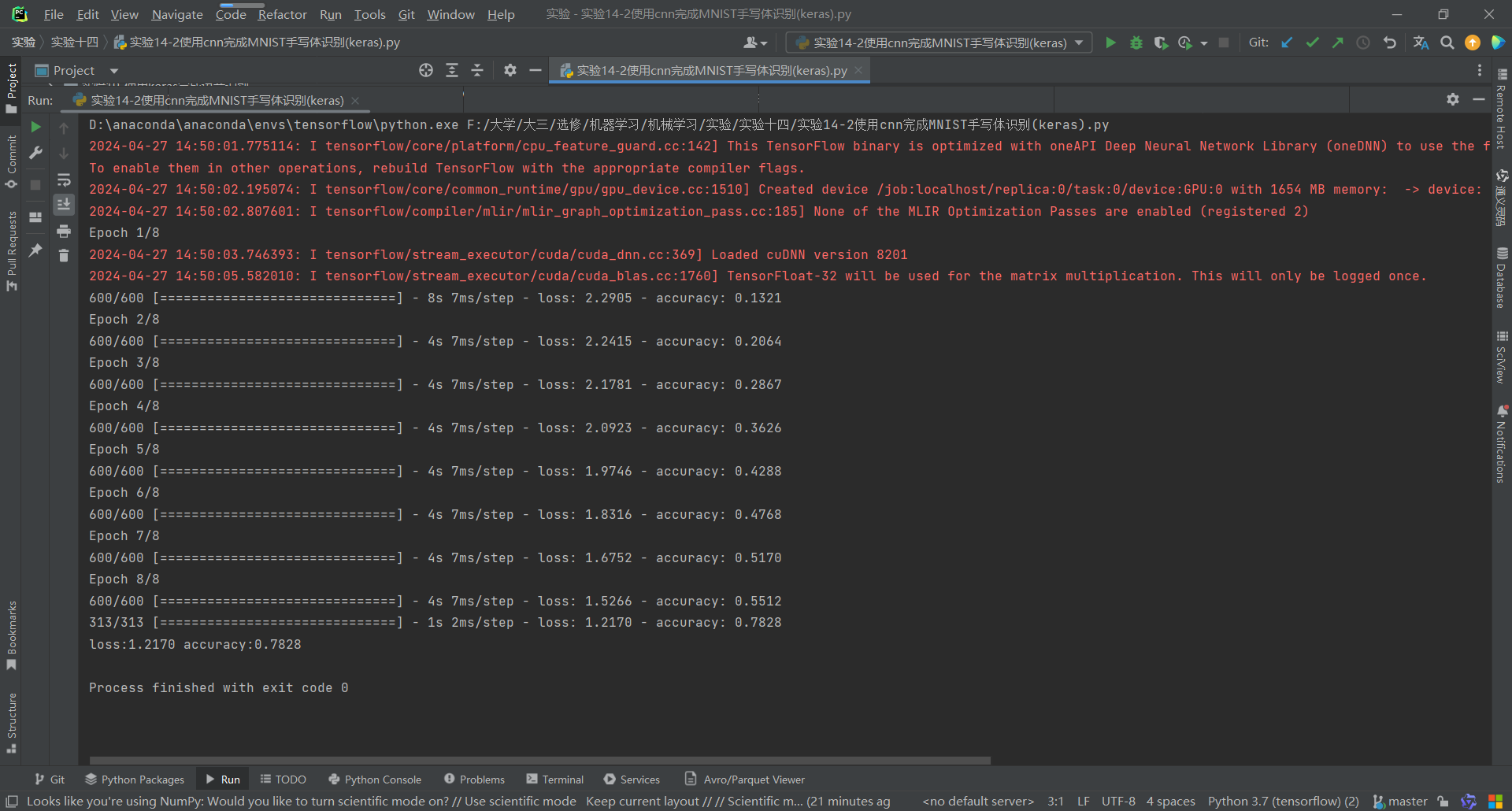
代码;
from keras.datasets import mnist from tensorflow.keras.utils import to_categorical train_X, train_y = mnist.load_data(r"F:\大学\大三\选修\机器学习\机械学习\实验\实验十四\mnist.npz")[0] train_X = train_X.reshape(-1, 28, 28, 1) train_X = train_X.astype('float32') train_X /= 255 train_y = to_categorical(train_y, 10) from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dropout, Dense from keras.losses import categorical_crossentropy from tensorflow.keras.optimizers import Adadelta model = Sequential() model.add(Conv2D(32, (5,5), activation='relu', input_shape=[28, 28, 1])) model.add(Conv2D(64, (5,5), activation='relu')) model.add(MaxPool2D(pool_size=(2,2))) model.add(Flatten()) model.add(Dropout(0.5)) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) model.compile(loss=categorical_crossentropy, optimizer=Adadelta(), metrics=['accuracy']) batch_size = 100 epochs = 8 model.fit(train_X, train_y, batch_size=batch_size, epochs=epochs) test_X, test_y = mnist.load_data(r"F:\大学\大三\选修\机器学习\机械学习\实验\实验十四\mnist.npz")[1] test_X = test_X.reshape(-1, 28, 28, 1) test_X = test_X.astype('float32') test_X /= 255 test_y = to_categorical(test_y, 10) loss, accuracy = model.evaluate(test_X, test_y, verbose=1) print('loss:%.4f accuracy:%.4f' %(loss, accuracy))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号