
实验8-1tensorboard可视化+实验8-2tensorboard案例
版本python3.7 tensorflow版本为tensorflow-gpu版本2.6
实验8-1tensorboard可视化运行结果:
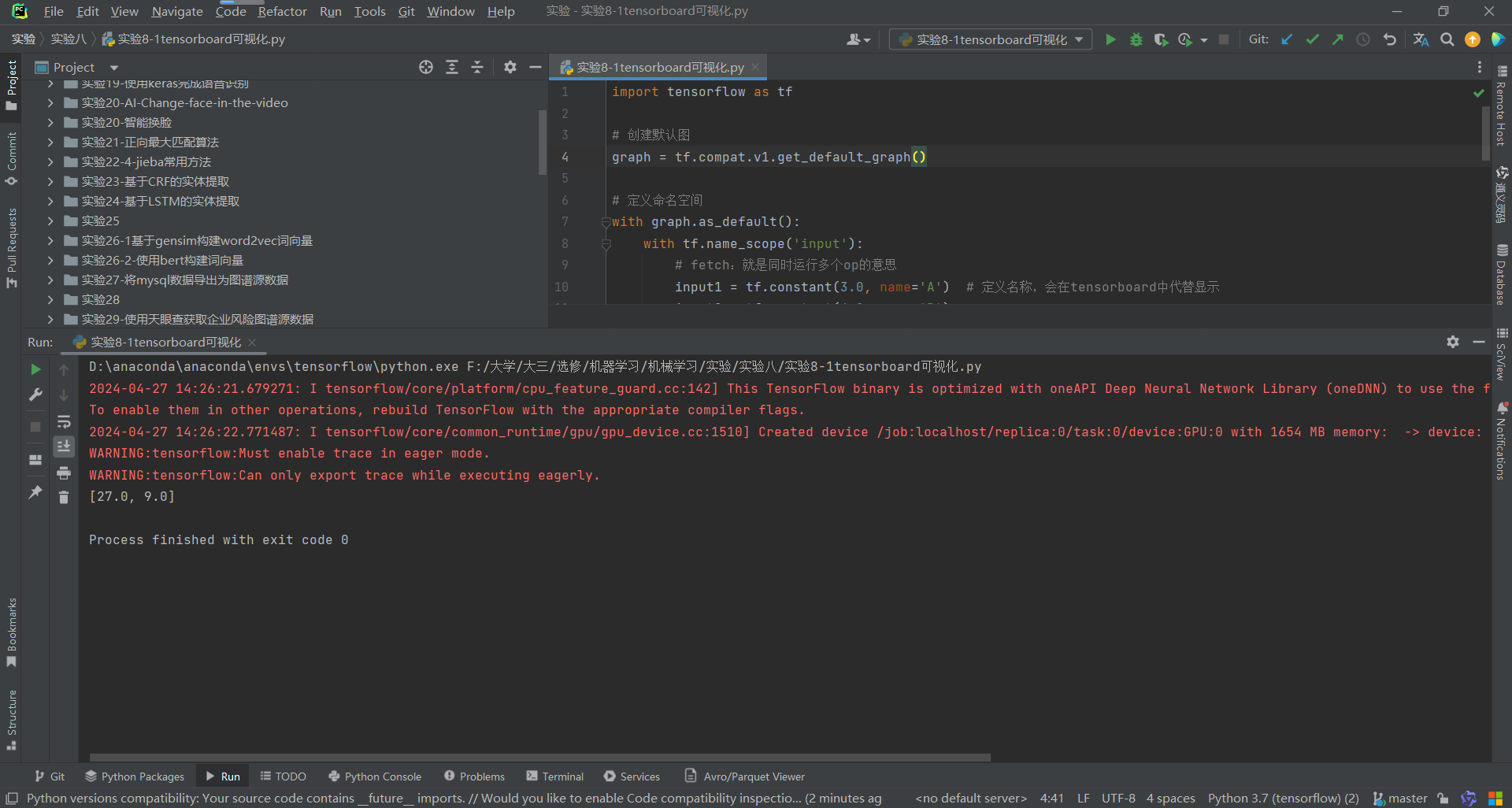
代码:
import tensorflow as tf # 创建默认图 graph = tf.compat.v1.get_default_graph() # 定义命名空间 with graph.as_default(): with tf.name_scope('input'): # fetch:就是同时运行多个op的意思 input1 = tf.constant(3.0, name='A') # 定义名称,会在tensorboard中代替显示 input2 = tf.constant(4.0, name='B') input3 = tf.constant(5.0, name='C') with tf.name_scope('op'): # 加法 add = tf.add(input2, input3) # 乘法 mul = tf.multiply(input1, add) with tf.compat.v1.Session() as ss: # 默认在当前py目录下的logs文件夹,没有会自己创建 result = ss.run([mul, add]) # 使用create_file_writer创建一个文件写入器 writer = tf.summary.create_file_writer('logs/demo/') # 在这个上下文中,所有的tensorboard操作都会被写入logs/demo/目录中 with writer.as_default(): # 将计算图写入日志文件 tf.summary.trace_on(graph=True, profiler=True) # 执行计算 tf.summary.trace_export(name="model_trace", step=0, profiler_outdir='logs/demo/') print(result)
实验8-2tensorboard案例运行结果:
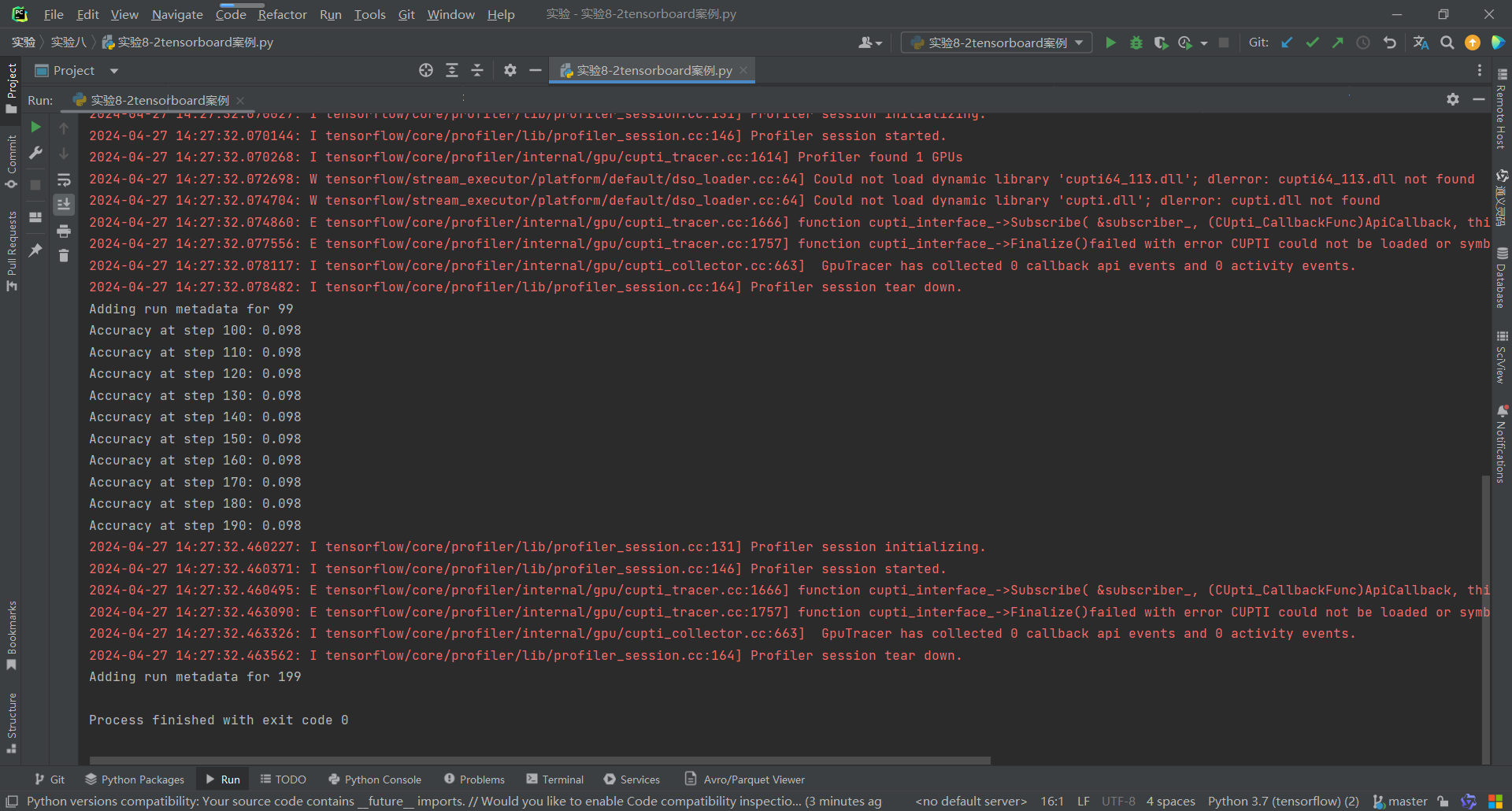
代码:
#!/usr/bin/env python # -*- coding: utf-8 -*- from __future__ import absolute_import from __future__ import division from __future__ import print_function import argparse import sys import os import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data max_steps = 200 # 最大迭代次数 默认1000 learning_rate = 0.001 # 学习率 dropout = 0.9 # dropout时随机保留神经元的比例 data_dir = os.path.join('data', 'mnist')# 样本数据存储的路径 if not os.path.exists('log'): os.mkdir('log') log_dir = 'log' # 输出日志保存的路径 mnist = input_data.read_data_sets("MNIST_data",one_hot=True) sess = tf.compat.v1.InteractiveSession() with tf.name_scope('input'): tf.compat.v1.disable_eager_execution() x = tf.compat.v1.placeholder(tf.float32, [None, 784], name='x-input') y_ = tf.compat.v1.placeholder(tf.float32, [None, 10], name='y-input') with tf.name_scope('input_reshape'): image_shaped_input = tf.reshape(x, [-1, 28, 28, 1]) tf.summary.image('input', image_shaped_input, 10) def weight_variable(shape): """Create a weight variable with appropriate initialization.""" initial = tf.random.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) def bias_variable(shape): """Create a bias variable with appropriate initialization.""" initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) def variable_summaries(var): """Attach a lot of summaries to a Tensor (for TensorBoard visualization).""" with tf.name_scope('summaries'): # 计算参数的均值,并使用tf.summary.scaler记录 mean = tf.reduce_mean(var) tf.summary.scalar('mean', mean) # 计算参数的标准差 with tf.name_scope('stddev'): stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean))) # 使用tf.summary.scaler记录记录下标准差,最大值,最小值 tf.summary.scalar('stddev', stddev) tf.summary.scalar('max', tf.reduce_max(var)) tf.summary.scalar('min', tf.reduce_min(var)) # 用直方图记录参数的分布 tf.summary.histogram('histogram', var) def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu): """Reusable code for making a simple neural net layer. It does a matrix multiply, bias add, and then uses relu to nonlinearize. It also sets up name scoping so that the resultant graph is easy to read, and adds a number of summary ops. """ # 设置命名空间 with tf.name_scope(layer_name): # 调用之前的方法初始化权重w,并且调用参数信息的记录方法,记录w的信息 with tf.name_scope('weights'): weights = weight_variable([input_dim, output_dim]) variable_summaries(weights) # 调用之前的方法初始化权重b,并且调用参数信息的记录方法,记录b的信息 with tf.name_scope('biases'): biases = bias_variable([output_dim]) variable_summaries(biases) # 执行wx+b的线性计算,并且用直方图记录下来 with tf.name_scope('linear_compute'): preactivate = tf.matmul(input_tensor, weights) + biases tf.summary.histogram('linear', preactivate) # 将线性输出经过激励函数,并将输出也用直方图记录下来 activations = act(preactivate, name='activation') tf.summary.histogram('activations', activations) # 返回激励层的最终输出 return activations hidden1 = nn_layer(x, 784, 500, 'layer1') with tf.name_scope('dropout'): tf.compat.v1.disable_eager_execution() keep_prob = tf.compat.v1.placeholder(tf.float32) tf.compat.v1.summary.scalar('dropout_keep_probability', keep_prob) dropped = tf.nn.dropout(hidden1, keep_prob) y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity) with tf.name_scope('loss'): # 计算交叉熵损失(每个样本都会有一个损失) diff = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y) with tf.name_scope('total'): # 计算所有样本交叉熵损失的均值 cross_entropy = tf.reduce_mean(diff) tf.summary.scalar('loss', cross_entropy) with tf.name_scope('train'): train_step = tf.compat.v1.train.AdamOptimizer(learning_rate).minimize( cross_entropy) with tf.name_scope('accuracy'): with tf.name_scope('correct_prediction'): # 分别将预测和真实的标签中取出最大值的索引,弱相同则返回1(true),不同则返回0(false) correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) with tf.name_scope('accuracy'): # 求均值即为准确率 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) tf.summary.scalar('accuracy', accuracy) # summaries合并 merged = tf.compat.v1.summary.merge_all() # 写到指定的磁盘路径中 #删除src路径下所有文件 def delete_file_folder(src): '''delete files and folders''' if os.path.isfile(src): try: os.remove(src) except: pass elif os.path.isdir(src): for item in os.listdir(src): itemsrc=os.path.join(src,item) delete_file_folder(itemsrc) try: os.rmdir(src) except: pass #删除之前生成的log if os.path.exists(log_dir + '/train'): delete_file_folder(log_dir + '/train') if os.path.exists(log_dir + '/test'): delete_file_folder(log_dir + '/test') train_writer = tf.compat.v1.summary.FileWriter(log_dir + '/train', sess.graph) test_writer = tf.compat.v1.summary.FileWriter(log_dir + '/test') # 运行初始化所有变量 tf.compat.v1.global_variables_initializer().run() def feed_dict(train): """Make a TensorFlow feed_dict: maps data onto Tensor placeholders.""" if train: xs, ys = mnist.train.next_batch(100) k = dropout else: xs, ys = mnist.test.images, mnist.test.labels k = 1.0 return {x: xs, y_: ys, keep_prob: k} for i in range(max_steps): if i % 10 == 0: # 记录测试集的summary与accuracy summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False)) test_writer.add_summary(summary, i) print('Accuracy at step %s: %s' % (i, acc)) else: # 记录训练集的summary if i % 100 == 99: # Record execution stats run_options = tf.compat.v1.RunOptions(trace_level=tf.compat.v1.RunOptions.FULL_TRACE) run_metadata = tf.compat.v1.RunMetadata() summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True), options=run_options, run_metadata=run_metadata) train_writer.add_run_metadata(run_metadata, 'step%03d' % i) train_writer.add_summary(summary, i) print('Adding run metadata for', i) else: # Record a summary summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True)) train_writer.add_summary(summary, i) train_writer.close() test_writer.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号