简单视频爬取
今天浅浅的学习了一下爬取,我爬取的是视频,我发现有些爬取不了,他们那个视频url前有blob:,这个的视频需要其他手段爬取,反正我是没学到那里。
import urllib.request url = "https://vd4.bdstatic.com/mda-jkf4n2sz3tmbh03a/sc/mda-jkf4n2sz3tmbh03a.mp4?v_from_s=hkapp-haokan-hbf&auth_key=1680787625-0-0-af01f4b70e069a7b1b6a462f47045630&bcevod_channel=searchbox_feed&pd=1&cd=0&pt=3&logid=3425246186&vid=11837937437364669902&abtest=107353_1-109133_1&klogid=3425246186" re=urllib.request.urlopen(url) # s=re.read().decode("utf-8") head={ 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36' } urllib.request.urlretrieve(url,'s1.mp4')
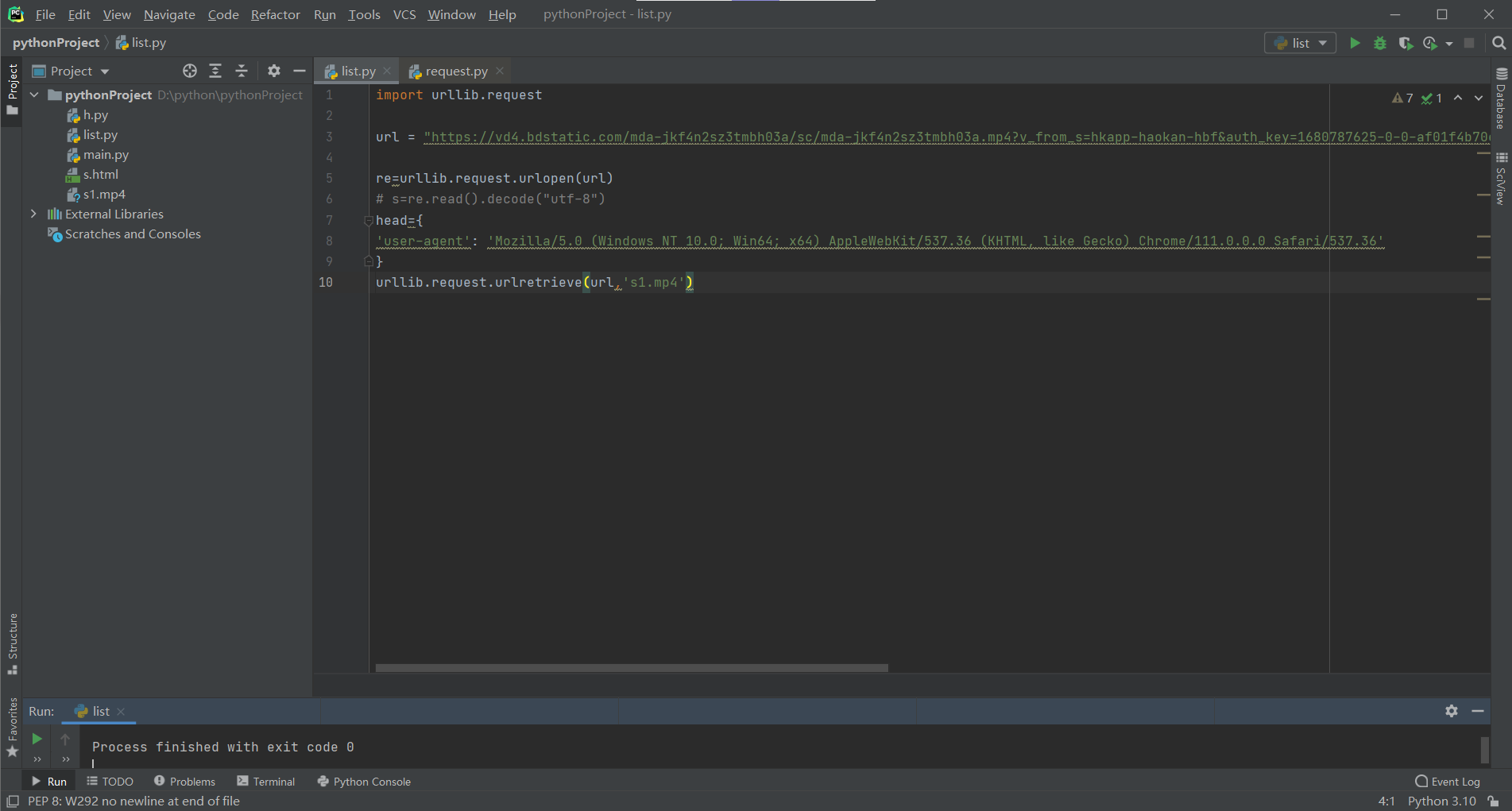
爬取的视频名我设置的名是s1,我还爬取我的网站html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号