谈谈Spring中的对象跟Bean,你知道Spring怎么创建对象的吗?
本系列文章:
推荐阅读:
本系列文章将会带你一行行的将Spring的源码吃透,推荐阅读的文章是阅读源码的基础!
两个问题
在开始探讨源码前,我们先思考两个问题:
1、在Spring中,什么是Bean?跟对象有什么区别?
通过new关键字,反射,克隆等手段创建出来的就是对象。在Spring中,Bean一定是一个对象,但是对象不一定是一个Bean,一个被创建出来的对象要变成一个Bean要经过很多复杂的工序,例如需要被我们的
BeanPostProcessor处理,需要经过初始化,需要经过AOP(AOP本身也是由后置处理器完成的)等。
2、在创建对象前,Spring还做了其它什么事情吗?
我们还是回到流程图中,其中相关的步骤如下:
在前面的三篇文章中,我们已经分析到了第3-5步的源码,而如果你对Spring源码稍有了解的话,就是知道创建对象以及将对象变成一个Bean的过程发生在第3-11步骤中。中间的五步分别做了什么呢?
1、registerBeanPostProcessors
就像名字所说的那样,注册BeanPostProcessor,这段代码在Spring官网阅读(八)容器的扩展点(三)(BeanPostProcessor)已经分析过了,所以在本文就直接跳过了,如果你没有看过之前的文章也没有关系,你只需要知道,在这里Spring将所有的BeanPostProcessor注册到了容器中
2、initMessageSource
初始化容器中的messageSource,如果程序员没有提供,默认会创建一个org.springframework.context.support.DelegatingMessageSource,Spring官网阅读(十一)ApplicationContext详细介绍(上) 已经介绍过了。
3、initApplicationEventMulticaster
初始化事件分发器,如果程序员没有提供,那么默认创建一个org.springframework.context.event.ApplicationEventMulticaster,Spring官网阅读(十二)ApplicationContext详解(中)已经做过详细分析,不再赘述
4、onRefresh
留给子类复写扩展使用
5、registerListeners
注册事件监听器,就是将容器中所有实现了org.springframework.context.ApplicationListener接口的对象放入到监听器的集合中。
创建对象的源码分析
在完成了上面的一些准备工作后,Spring开始来创建Bean了,按照流程,首先被调用的就是
finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory)方法,我们就以这个方法为入口,一步步跟踪源码,看看Spring中的Bean到底是怎么创建出来的,当然,本文主要关注的是创建对象的这个过程,对象变成Bean的流程我们在后续文章中再分析
1、finishBeanFactoryInitialization
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// 初始化一个ConversionService用于类型转换,这个ConversionService会在实例化对象的时候用到
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
// 添加一个StringValueResolver,用于处理占位符,可以看到,默认情况下就是使用环境中的属性值来替代占位符中的属性
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
// 创建所有的LoadTimeWeaverAware
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// 静态织入完成后将临时的类加载器设置为null,所以除了创建LoadTimeWeaverAware时可能会用到临时类加载器,其余情况下都为空
beanFactory.setTempClassLoader(null);
// 将所有的配置信息冻结
beanFactory.freezeConfiguration();
// 开始进行真正的创建
beanFactory.preInstantiateSingletons();
}
上面的方法最终调用了org.springframework.beans.factory.support.DefaultListableBeanFactory#preInstantiateSingletons来创建Bean。
其源码如下:
2、preInstantiateSingletons
public void preInstantiateSingletons() throws BeansException {
// 所有bd的名称
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// 遍历所有bd,一个个进行创建
for (String beanName : beanNames) {
// 获取到指定名称对应的bd
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
// 对不是延迟加载的单例的Bean进行创建
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 判断是否是一个FactoryBean
if (isFactoryBean(beanName)) {
// 如果是一个factoryBean的话,先创建这个factoryBean,创建factoryBean时,需要在beanName前面拼接一个&符号
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
final FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged((PrivilegedAction<Boolean>)
((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
// 判断是否是一个SmartFactoryBean,并且不是懒加载的,就意味着,在创建了这个factoryBean之后要立马调用它的getObject方法创建另外一个Bean
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
// 不是factoryBean的话,我们直接创建就行了
getBean(beanName);
}
}
}
// 在创建了所有的Bean之后,遍历
for (String beanName : beanNames) {
// 这一步其实是从缓存中获取对应的创建的Bean,这里获取到的必定是单例的
Object singletonInstance = getSingleton(beanName);
// 判断是否是一个SmartInitializingSingleton,最典型的就是我们之前分析过的EventListenerMethodProcessor,在这一步完成了对已经创建好的Bean的解析,会判断其方法上是否有 @EventListener注解,会将这个注解标注的方法通过EventListenerFactory转换成一个事件监听器并添加到监听器的集合中
if (singletonInstance instanceof SmartInitializingSingleton) {
final SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
上面这段代码整体来说应该不难,不过它涉及到了一个点就是factoryBean,如果你对它不够了解的话,请参考我之前的一篇文章:Spring官网阅读(七)容器的扩展点(二)FactoryBean
3、doGetBean
从上面的代码分析中我们可以知道,Spring最终都会调用到getBean方法,而getBean并不是真正干活的,doGetBean才是。另外doGetBean可以分为两种情况
- 创建的是一个
FactoryBean,此时实际传入的name = & + beanName - 创建的是一个普通Bean,此时传入的
name = beanName
其代码如下:
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
// 前面我们说过了,传入的name可能时& + beanName这种形式,这里做的就是去除掉&,得到beanName
final String beanName = transformedBeanName(name);
Object bean;
// 这个方法就很牛逼了,通过它解决了循环依赖的问题,不过目前我们只需要知道它是从单例池中获取已经创建的Bean即可,循环依赖后面我单独写一篇文章
// 方法作用:已经创建的Bean会被放到单例池中,这里就是从单例池中获取
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
// 如果直接从单例池中获取到了这个bean(sharedInstance),我们能直接返回吗?
// 当然不能,因为获取到的Bean可能是一个factoryBean,如果我们传入的name是 & + beanName 这种形式的话,那是可以返回的,但是我们传入的更可能是一个beanName,那么这个时候Spring就还需要调用这个sharedInstance的getObject方法来创建真正被需要的Bean
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
// 在缓存中获取不到这个Bean
// 原型下的循环依赖直接报错
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// 核心要义,找不到我们就从父容器中再找一次
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
return ((AbstractBeanFactory) parentBeanFactory).doGetBean(
nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else if (requiredType != null) {
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
else {
return (T) parentBeanFactory.getBean(nameToLookup);
}
}
// 如果不仅仅是为了类型推断,也就是代表我们要对进行实例化
// 那么就将bean标记为正在创建中,其实就是将这个beanName放入到alreadyCreated这个set集合中
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
// 检查合并后的bd是否是abstract,这个检查现在已经没有作用了,必定会通过
checkMergedBeanDefinition(mbd, beanName, args);
// @DependsOn注解标注的当前这个Bean所依赖的bean名称的集合,就是说在创建当前这个Bean前,必须要先将其依赖的Bean先完成创建
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
// 遍历所有申明的依赖
for (String dep : dependsOn) {
// 如果这个bean所依赖的bean又依赖了当前这个bean,出现了循环依赖,直接报错
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// 注册bean跟其依赖的依赖关系,key为依赖,value为依赖所从属的bean
registerDependentBean(dep, beanName);
try {
// 先创建其依赖的Bean
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
// 我们目前只分析单例的创建,单例看懂了,原型自然就懂了
if (mbd.isSingleton()) {
// 这里再次调用了getSingleton方法,这里跟方法开头调用的getSingleton的区别在于,这个方法多传入了一个ObjectFactory类型的参数,这个ObjectFactory会返回一个Bean
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 省略原型跟域对象的相关代码
return (T) bean;
}
配合注释看这段代码应该也不难吧,我们重点关注最后在调用的这段方法即可
4、getSingleton(beanName,ObjectFactory)
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
// 从单例池中获取,这个地方肯定也获取不到
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 工厂已经在销毁阶段了,这个时候还在创建Bean的话,就直接抛出异常
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
// 在单例创建前,记录一下正在创建的单例的名称,就是把beanName放入到singletonsCurrentlyInCreation这个set集合中去
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 这里调用了singletonFactory的getObject方法,对应的实现就是在doGetBean中的那一段lambda表达式
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// 省略异常处理
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 在单例完成创建后,将beanName从singletonsCurrentlyInCreation中移除
// 标志着这个单例已经完成了创建
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 添加到单例池中
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
分析完上面这段代码,我们会发现,核心的创建Bean的逻辑就是在singletonFactory.getObject()这句代码中,而其实现就是在doGetBean方法中的那一段lambda表达式,如下:
实际就是通过createBean这个方法创建了一个Bean然后返回,createBean又干了什么呢?
5、createBean
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
RootBeanDefinition mbdToUse = mbd;
// 解析得到beanClass,为什么需要解析呢?如果是从XML中解析出来的标签属性肯定是个字符串嘛
// 所以这里需要加载类,得到Class对象
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// 对XML标签中定义的lookUp属性进行预处理,如果只能根据名字找到一个就标记为非重载的,这样在后续就不需要去推断到底是哪个方法了,对于@LookUp注解标注的方法是不需要在这里处理的,AutowiredAnnotationBeanPostProcessor会处理这个注解
try {
mbdToUse.prepareMethodOverrides();
}
// 省略异常处理...
try {
// 在实例化对象前,会经过后置处理器处理
// 这个后置处理器的提供了一个短路机制,就是可以提前结束整个Bean的生命周期,直接从这里返回一个Bean
// 不过我们一般不会这么做,它的另外一个作用就是对AOP提供了支持,在这里会将一些不需要被代理的Bean进行标记,就本文而言,你可以暂时理解它没有起到任何作用
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
// 省略异常处理...
try {
// doXXX方法,真正干活的方法,doCreateBean,真正创建Bean的方法
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
// 省略异常处理...
}
6、doCreateBean
本文只探讨对象是怎么创建的,至于怎么从一个对象变成了Bean,在后面的文章我们再讨论,所以我们主要就关注下面这段代码
// 这个方法真正创建了Bean,创建一个Bean会经过 创建对象 > 依赖注入 > 初始化 这三个过程,在这个过程中,BeanPostPorcessor会穿插执行,本文主要探讨的是创建对象的过程,所以关于依赖注入及初始化我们暂时省略,在后续的文章中再继续研究
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
// 这行代码看起来就跟factoryBean相关,这是什么意思呢?
// 在下文我会通过例子介绍下,你可以暂时理解为,这个地方返回的就是个null
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
// 这里真正的创建了对象
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 省略依赖注入,初始化
}
这里我先分析下this.factoryBeanInstanceCache.remove(beanName)这行代码。这里需要说一句,我写的这个源码分析的系列非常的细节,之所以选择这样一个个扣细节是因为我自己在阅读源码过程中经常会被这些问题阻塞,那么借着这些文章将自己踩过的坑分享出来可以减少作为读者的你自己在阅读源码时的障碍,其次也能够提升自己阅读源码的能力。如果你对这些细节不感兴趣的话,可以直接跳过,能把握源码的主线即可。言归正传,我们回到这行代码this.factoryBeanInstanceCache.remove(beanName)。什么时候factoryBeanInstanceCache这个集合中会有值呢?这里我还是以示例代码来说明这个问题,示例代码如下:
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(Config.class);
}
}
// 没有做什么特殊的配置,就是扫描了需要的组件,测试时换成你自己的包名
@ComponentScan("com.dmz.source.instantiation")
@Configuration
public class Config {
}
// 这里申明了一个FactoryBean,并且通过@DependsOn注解申明了这个FactoryBean的创建要在orderService之后,主要目的是为了在DmzFactoryBean创建前让容器发生一次属性注入
@Component
@DependsOn("orderService")
public class DmzFactoryBean implements FactoryBean<DmzService> {
@Override
public DmzService getObject() throws Exception {
return new DmzService();
}
@Override
public Class<?> getObjectType() {
return DmzService.class;
}
}
// 没有通过注解的方式将它放到容器中,而是通过上面的DmzFactoryBean来管理对应的Bean
public class DmzService {
}
// OrderService中需要注入dmzService
@Component
public class OrderService {
@Autowired
DmzService dmzService;
}
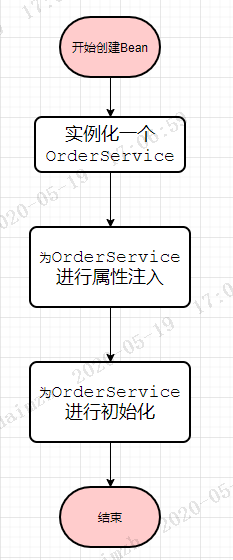
在这段代码中,因为我们明确的表示了DmzFactoryBean是依赖于orderService的,所以必定会先创建orderService再创建DmzFactoryBean,创建orderService的流程如下:
其中的属性注入阶段,我们需要细化,也可以画图如下:
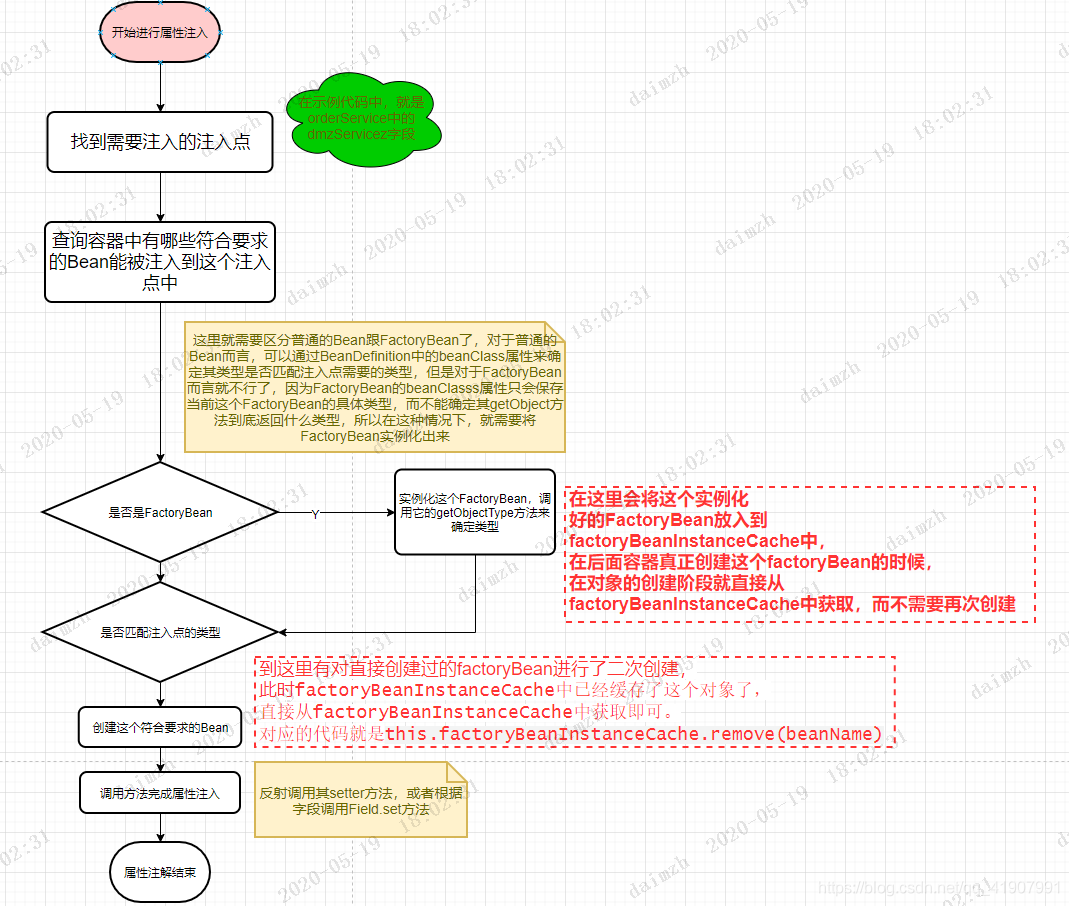
为orderService进行属性注入可以分为这么几步
-
找到需要注入的注入点,也就是orderService中的dmzService字段
-
根据字段的类型以及名称去容器中查询符合要求的Bean
-
当遍历到一个FactroyBean时,为了确定其getObject方法返回的对象的类型需要创建这个FactroyBean(只会到对象级别),然后调用这个创建好的FactroyBean的getObjectType方法明确其类型并与注入点需要的类型比较,看是否是一个候选的Bean,在创建这个FactroyBean时就将其放入了
factoryBeanInstanceCache中。 -
在确定了唯一的候选Bean之后,Spring就会对这个Bean进行创建,创建的过程又经过三个步骤
- 创建对象
- 属性注入
- 初始化
在创建对象时,因为此时
factoryBeanInstanceCache已经缓存了这个Bean对应的对象,所以直接通过this.factoryBeanInstanceCache.remove(beanName)这行代码就返回了,避免了二次创建对象。
7、createBeanInstance
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
Class<?> beanClass = resolveBeanClass(mbd, beanName);
// 省略异常
// 通过bd中提供的instanceSupplier来获取一个对象
// 正常bd中都不会有这个instanceSupplier属性,这里也是Spring提供的一个扩展点,但实际上不常用
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
// bd中提供了factoryMethodName属性,那么要使用工厂方法的方式来创建对象,工厂方法又会区分静态工厂方法跟实例工厂方法
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
// 在原型模式下,如果已经创建过一次这个Bean了,那么就不需要再次推断构造函数了
boolean resolved = false; // 是否推断过构造函数
boolean autowireNecessary = false; // 构造函数是否需要进行注入
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
if (autowireNecessary) {
return autowireConstructor(beanName, mbd, null, null);
}
else {
return instantiateBean(beanName, mbd);
}
}
// 推断构造函数
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// 调用无参构造函数创建对象
return instantiateBean(beanName, mbd);
}
上面这段代码在Spring官网阅读(一)容器及实例化 已经分析过了,但是当时我们没有深究创建对象的细节,所以本文将详细探讨Spring中的这个对象到底是怎么创建出来的,这也是本文的主题。
在Spring官网阅读(一)容器及实例化 这篇文章中,我画了下面这么一张图
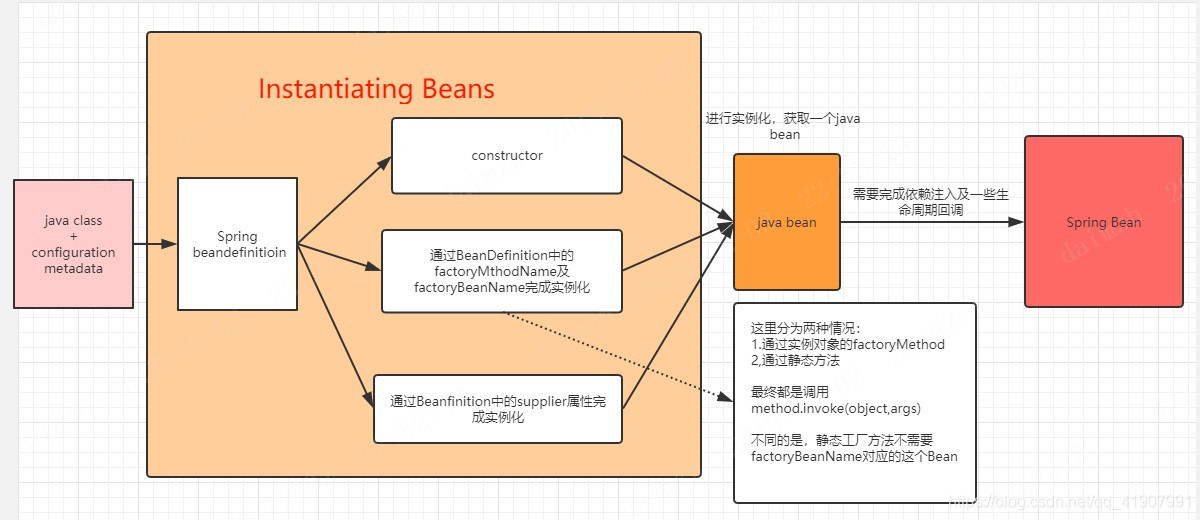
从上图中我们可以知道Spring在实例化对象的时候有这么几种方式
- 通过bd中的supplier属性
- 通过bd中的factoryMethodName跟factoryBeanName
- 通过构造函数
我们接下来就一一分析其中的细节:
》通过bd中的supplier属性实例化对象
在Spring官网阅读(一)容器及实例化 文中介绍过这种方式,因为这种方式我们基本不会使用,并不重要,所以这里就不再赘述,我这里就直接给出一个使用示例,大家自行体会吧
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
// 直接注册一个Bean,并且指定它的supplier就是Service::new
ac.registerBean("service", Service.class,Service::new,zhe'sh);
ac.refresh();
System.out.println(ac.getBean("service"));
}
》通过bd中的factoryMethodName跟factoryBeanName实例化对象
对应代码如下:
protected BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
return new ConstructorResolver(this).instantiateUsingFactoryMethod(beanName, mbd, explicitArgs);
}
上面这段代码主要干了两件事
- 创建一个
ConstructorResolver对象,从类名来看,它是一个构造器解析器 - 调用了这个构造器解析器的
instantiateUsingFactoryMethod方法,这个方法见名知意,使用FactoryMethod来完成实例化
基于此,我们解决一个问题,ConstructorResolver是什么?
ConstructorResolver是什么?
在要研究一个类前,我们最先应该从哪里入手呢?很多没有经验的同学可能会闷头看代码,但是实际上最好的学习方式是先阅读类上的javaDoc
ConstructorResolver上的javaDoc如下:

上面这段javaDoc翻译过来就是这个类就是用来解析构造函数跟工厂方法的代理者,并且它是通过参数匹配的方式来进行推断构造方法或者工厂方法。
看到这里不知道小伙伴们是否有疑问,就是明明这个类不仅负责推断构造函数,还会负责推断工厂方法,那么为什么类名会叫做ConstructorResolver呢?我们知道Spring的代码在业界来说绝对是最规范的,没有之一,这样来说的话,这个类最合适的名称应该是ConstructorAndFactoryMethodResolver才对,因为它不仅负责推断了构造函数还负责推断了工厂方法嘛!
这里我需要说一下我自己的理解。对于一个Bean,它是通过构造函数完成实例化的,或者通过工厂方法实例化的,其实在这个Bean看来都没有太大区别,这两者都可以称之为这个Bean的构造器,因为通过它们都能构造出一个Bean。所以Spring就把两者统称为构造器了,所以这个类名也就被称为ConstructorResolver了。
Spring在很多地方体现了这种实现,例如在XML配置的情况下,不论我们是使用构造函数创建对象还是使用工厂方法创建对象,其参数的标签都是使用constructor-arg。比如下面这个例子
<bean id="dmzServiceGetFromStaticMethod"
factory-bean="factoryBean"
factory-method="getObject">
<constructor-arg type="java.lang.String" value="hello" name="s"/>
<constructor-arg type="com.dmz.source.instantiation.service.DmzFactory" ref="factoryBean"/>
</bean>
<!--测试静态工厂方法创建对象-->
<bean id="service"
class="com.dmz.official.service.MyFactoryBean"
factory-method="staticGet">
<constructor-arg type="java.lang.String" value="hello"/>
</bean>
<bean id="dmzService" class="com.dmz.source.instantiation.service.DmzService">
<constructor-arg name="s" value="hello"/>
</bean>
在对这个类有了大概的了解后,我们就需要来分析它的源码,这里我就不把它单独拎出来分析了,我们借着Spring的流程看看这个类干了什么事情
instantiateUsingFactoryMethod方法做了什么?
核心目的:推断出要使用的factoryMethod以及调用这个FactoryMethod要使用的参数,然后反射调用这个方法实例化出一个对象
这个方法的代码太长了,所以我们将它拆分成为一段一段的来分析
方法参数分析
在分析上面的代码之前,我们先来看看这个方法的参数都是什么含义
方法上关于参数的介绍如图所示

beanName:当前要实例化的Bean的名称mbd:当前要实例化的Bean对应的BeanDefinitionexplicitArgs:这个参数在容器启动阶段我们可以认定它就是null,只有显示的调用了getBean方法,并且传入了明确的参数,例如:getBean("dmzService","hello")这种情况下才会不为null,我们分析这个方法的时候就直接认定这个参数为null即可。
第一段
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代码:创建并初始话一个BeanWrapperImpl
BeanWrapperImpl bw = new BeanWrapperImpl();
this.beanFactory.initBeanWrapper(bw);
// ......
}
BeanWrapperImpl是什么呢?如果你看过我之前的文章:Spring官网阅读(十四)Spring中的BeanWrapper及类型转换,那么你对这个类应该不会陌生,它就是对Bean进行了一层包装,并且在创建Bean的时候以及进行属性注入的时候能够进行类型转换。就算你没看过之前的文章也没关系,只要记住两点
- BeanWrapperImpl包装了一个实例化好的对象
- BeanWrapperImpl能够对属性进行类型转换
其层级关系如下:
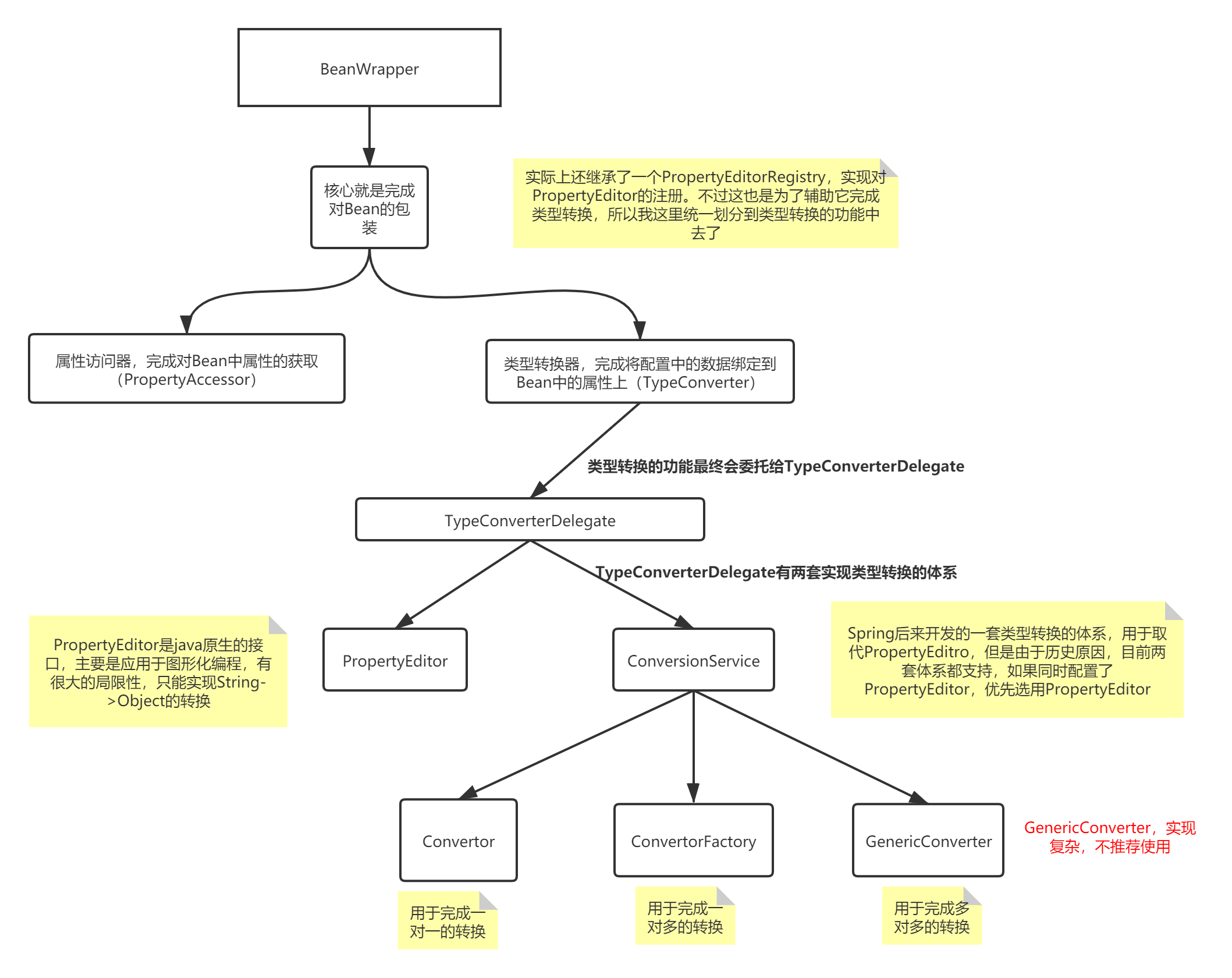
回到我们的源码分析,我们先来看看new BeanWrapperImpl()做了什么事情?
对应代码如下:
// 第一步:调用空参构造
public BeanWrapperImpl() {
// 调用另外一个构造函数,表示要注册默认的属性编辑器
this(true);
}
// 这个构造函数表明是否要注册默认编辑器,上面传入的值为true,表示需要注册
public BeanWrapperImpl(boolean registerDefaultEditors) {
super(registerDefaultEditors);
}
// 调用到父类的构造函数,确定要使用默认的属性编辑器
protected AbstractNestablePropertyAccessor(boolean registerDefaultEditors) {
if (registerDefaultEditors) {
registerDefaultEditors();
}
// 对typeConverterDelegate进行初始化
this.typeConverterDelegate = new TypeConverterDelegate(this);
}
总的来说创建的过程非常简单。第一,确定要注册默认的属性编辑器;第二,对typeConverterDelegate属性进行初始化。
紧接着,我们看看在初始化这个BeanWrapper做了什么?
// 初始化BeanWrapper,主要就是将容器中配置的conversionService赋值到当前这个BeanWrapper上
// 同时注册定制的属性编辑器
protected void initBeanWrapper(BeanWrapper bw) {
bw.setConversionService(getConversionService());
registerCustomEditors(bw);
}
还记得conversionService在什么时候被放到容器中的吗?就是在finishBeanFactoryInitialization的时候啦~!
对conversionService属性完成赋值后就开始注册定制的属性编辑器,代码如下:
// 传入的参数就是我们的BeanWrapper,它同时也是一个属性编辑器注册表
protected void registerCustomEditors(PropertyEditorRegistry registry) {
PropertyEditorRegistrySupport registrySupport =
(registry instanceof PropertyEditorRegistrySupport ? (PropertyEditorRegistrySupport) registry : null);
if (registrySupport != null) {
// 这个配置的作用就是在注册默认的属性编辑器时,可以增加对数组到字符串的转换功能
// 默认就是通过","来切割字符串转换成数组,对应的属性编辑器就是StringArrayPropertyEditor
registrySupport.useConfigValueEditors();
}
// 将容器中的属性编辑器注册到当前的这个BeanWrapper
if (!this.propertyEditorRegistrars.isEmpty()) {
for (PropertyEditorRegistrar registrar : this.propertyEditorRegistrars) {
registrar.registerCustomEditors(registry);
// 省略异常处理~
}
}
// 这里我们没有添加任何的自定义的属性编辑器,所以肯定为空
if (!this.customEditors.isEmpty()) {
this.customEditors.forEach((requiredType, editorClass) ->
registry.registerCustomEditor(requiredType, BeanUtils.instantiateClass(editorClass)));
}
}
第二段
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 省略已经分析的第一段代码,到这里已经得到了一个具有类型转换功能的BeanWrapper
// 实例化这个Bean的工厂Bean
Object factoryBean;
// 工厂Bean的Class
Class<?> factoryClass;
// 静态工厂方法或者是实例化工厂方法
boolean isStatic;
/*下面这段代码就是为上面申明的这三个属性赋值*/
String factoryBeanName = mbd.getFactoryBeanName();
// 如果创建这个Bean的工厂就是这个Bean本身的话,那么直接抛出异常
if (factoryBeanName != null) {
if (factoryBeanName.equals(beanName)) {
throw new BeanDefinitionStoreException(mbd.getResourceDescription(), beanName,
"factory-bean reference points back to the same bean definition");
}
// 得到创建这个Bean的工厂Bean
factoryBean = this.beanFactory.getBean(factoryBeanName);
if (mbd.isSingleton() && this.beanFactory.containsSingleton(beanName)) {
throw new ImplicitlyAppearedSingletonException();
}
factoryClass = factoryBean.getClass();
isStatic = false;
}
else {
// factoryBeanName为null,说明是通过静态工厂方法来实例化Bean的
// 静态工厂进行实例化Bean,beanClass属性必须要是工厂的class,如果为空,直接报错
if (!mbd.hasBeanClass()) {
throw new BeanDefinitionStoreException(mbd.getResourceDescription(), beanName,
"bean definition declares neither a bean class nor a factory-bean reference");
}
factoryBean = null;
factoryClass = mbd.getBeanClass();
isStatic = true;
}
// 省略后续代码
}
小总结:
这段代码很简单,就是确认实例化当前这个Bean的工厂方法是静态工厂还是实例工厂,如果是实例工厂,那么找出对应的工厂Bean。
第三段
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 省略第一段,第二段代码
// 到这里已经得到了一个BeanWrapper,明确了实例化当前这个Bean到底是静态工厂还是实例工厂
// 并且已经确定了工厂Bean
// 最终确定的要用来创建对象的方法
Method factoryMethodToUse = null;
ArgumentsHolder argsHolderToUse = null;
Object[] argsToUse = null;
// 参数分析时已经说过,explicitArgs就是null
if (explicitArgs != null) {
argsToUse = explicitArgs;
}
else {
// 下面这段代码是什么意思呢?
// 在原型模式下,我们会多次创建一个Bean,所以Spring对参数以及所使用的方法做了缓存
// 在第二次创建原型对象的时候会进入这段缓存的逻辑
// 但是这里有个问题,为什么Spring对参数有两个缓存呢?
// 一:resolvedConstructorArguments
// 二:preparedConstructorArguments
// 这里主要是因为,直接使用解析好的构造的参数,因为这样会导致创建出来的所有Bean都引用同一个属性
Object[] argsToResolve = null;
synchronized (mbd.constructorArgumentLock) {
factoryMethodToUse = (Method) mbd.resolvedConstructorOrFactoryMethod;
// 缓存已经解析过的工厂方法或者构造方法
if (factoryMethodToUse != null && mbd.constructorArgumentsResolved) {
// resolvedConstructorArguments跟preparedConstructorArguments都是对参数的缓存
argsToUse = mbd.resolvedConstructorArguments;
if (argsToUse == null) {
argsToResolve = mbd.preparedConstructorArguments;
}
}
}
if (argsToResolve != null) {
// preparedConstructorArguments需要再次进行解析
argsToUse = resolvePreparedArguments(beanName, mbd, bw, factoryMethodToUse, argsToResolve);
}
}
// 省略后续代码
}
小总结:
上面这段代码应该没什么大问题,其核心思想就是从缓存中取已经解析出来的方法以及参数,这段代码只会在原型模式下生效,因为单例的话对象只会创建一次嘛~!最大的问题在于,为什么在对参数进行缓存的时候使用了两个不同的集合,并且缓存后的参数还需要再次解析,这个问题我们暂且放着,不妨带着这个问题往下看。
因为接下来要分析的代码就比较复杂了,所以为了让你彻底看到代码的执行流程,下面我会使用示例+流程图+文字的方式来分析源码。
示例代码如下(这个例子覆盖接下来要分析的所有流程):
配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"
default-autowire="constructor"><!--这里开启自动注入,并且是通过构造函数进行自动注入-->
<!--factoryObject 提供了创建对象的方法-->
<bean id="factoryObject" class="com.dmz.spring.first.instantiation.service.FactoryObject"/>
<!--提供一个用于测试自动注入的对象-->
<bean class="com.dmz.spring.first.instantiation.service.OrderService" id="orderService"/>
<!--主要测试这个对象的实例化过程-->
<bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" scope="prototype">
<constructor-arg name="name" value="dmz"/>
<constructor-arg name="age" value="18"/>
<constructor-arg name="birthDay" value="2020-05-23"/>
</bean>
<!--测试静态方法实例化对象的过程-->
<bean id="indexService" class="com.dmz.spring.first.instantiation.service.FactoryObject"
factory-method="staticGetIndex"/>
<!--提供这个转换器,用于转换dmzService中的birthDay属性,从字符串转换成日期对象-->
<bean class="org.springframework.context.support.ConversionServiceFactoryBean" id="conversionService">
<property name="converters">
<set>
<bean class="com.dmz.spring.first.instantiation.service.ConverterStr2Date"/>
</set>
</property>
</bean>
</beans>
测试代码:
public class FactoryObject {
public DmzService getDmz(String name, int age, Date birthDay, OrderService orderService) {
System.out.println("getDmz with "+"name,age,birthDay and orderService");
return new DmzService();
}
public DmzService getDmz(String name, int age, Date birthDay) {
System.out.println("getDmz with "+"name,age,birthDay");
return new DmzService();
}
public DmzService getDmz(String name, int age) {
System.out.println("getDmz with "+"name,age");
return new DmzService();
}
public DmzService getDmz() {
System.out.println("getDmz with empty arg");
return new DmzService();
}
public static IndexService staticGetIndex() {
return new IndexService();
}
}
public class DmzService {
}
public class IndexService {
}
public class OrderService {
}
public class ConverterStr2Date implements Converter<String, Date> {
@Override
public Date convert(String source) {
try {
return new SimpleDateFormat("yyyy-MM-dd").parse(source);
} catch (ParseException e) {
return null;
}
}
}
/**
* @author 程序员DMZ
* @Date Create in 23:14 2020/5/21
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class Main {
public static void main(String[] args) {
ClassPathXmlApplicationContext cc = new ClassPathXmlApplicationContext();
cc.setConfigLocation("application.xml");
cc.refresh();
cc.getBean("dmzService");
// 两次调用,用于测试缓存的方法及参数
// cc.getBean("dmzService");
}
}
运行上面的代码会发现,程序打印:
getDmz with name,age,birthDay and orderService
具体原因我相信你看了接下来的源码分析自然就懂了
第四段
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代码:到这里已经得到了一个BeanWrapper,并对这个BeanWrapper做了初始化
// 第二段代码:明确了实例化当前这个Bean到底是静态工厂还是实例工厂
// 第三段代码:以及从缓存中取过了对应了方法以及参数
// 进入第四段代码分析,执行到这段代码说明是第一次实例化这个对象
if (factoryMethodToUse == null || argsToUse == null) {
// 如果被cglib代理的话,获取父类的class
factoryClass = ClassUtils.getUserClass(factoryClass);
// 获取到工厂类中的所有方法,接下来要一步步从这些方法中筛选出来符合要求的方法
Method[] rawCandidates = getCandidateMethods(factoryClass, mbd);
List<Method> candidateList = new ArrayList<>();
// 第一步筛选:之前 在第二段代码中已经推断了方法是静态或者非静态的
// 所以这里第一个要求就是要满足静态/非静态这个条件
// 第二个要求就是必须符合bd中定义的factoryMethodName的名称
// 其中第二个要求请注意,如果bd是一个configurationClassBeanDefinition,也就是说是通过扫描@Bean注解产生的,那么在判断时还会添加是否标注了@Bean注解
for (Method candidate : rawCandidates) {
if (Modifier.isStatic(candidate.getModifiers()) == isStatic && mbd.isFactoryMethod(candidate)) {
candidateList.add(candidate);
}
}
// 将之前得到的方法集合转换成数组
// 到这一步得到的其实就是某一个方法的所有重载方法
// 比如dmz(),dmz(String name),dmz(String name,int age)
Method[] candidates = candidateList.toArray(new Method[0]);
// 排序,public跟参数多的优先级越高
AutowireUtils.sortFactoryMethods(candidates);
// 用来保存从配置文件中解析出来的参数
ConstructorArgumentValues resolvedValues = null;
// 是否使用了自动注入,本段代码中没有使用到这个属性,但是在后面用到了
boolean autowiring = (mbd.getResolvedAutowireMode() == AutowireCapableBeanFactory.AUTOWIRE_CONSTRUCTOR);
int minTypeDiffWeight = Integer.MAX_VALUE;
// 可能出现多个符合要求的方法,用这个集合保存,实际上如果这个集合有值,就会抛出异常了
Set<Method> ambiguousFactoryMethods = null;
int minNrOfArgs;
// 必定为null,不考虑了
if (explicitArgs != null) {
minNrOfArgs = explicitArgs.length;
}
else {
// 就是说配置文件中指定了要使用的参数,那么需要对其进行解析,解析后的值就存储在resolvedValues这个集合中
if (mbd.hasConstructorArgumentValues()) {
// 通过解析constructor-arg标签,将参数封装成了ConstructorArgumentValues
// ConstructorArgumentValues这个类在下文我们专门分析
ConstructorArgumentValues cargs = mbd.getConstructorArgumentValues();
resolvedValues = new ConstructorArgumentValues();
// 解析标签中的属性,类似进行类型转换,后文进行详细分析
minNrOfArgs = resolveConstructorArguments(beanName, mbd, bw, cargs, resolvedValues);
}
else {
// 配置文件中没有指定要使用的参数,所以执行方法的最小参数个数就是0
minNrOfArgs = 0;
}
}
// 省略后续代码....
}
小总结:
因为在实例化对象前必定要先确定具体要使用的方法,所以这里先做的第一件事就是确定要在哪个范围内去推断要使用的factoryMethod呢?
最大的范围就是这个factoryClass的所有方法,也就是源码中的
rawCandidates其次需要在
rawCandidates中进一步做推断,因为在前面第二段代码的时候已经确定了是静态方法还是非静态方法,并且BeanDefinition也指定了factoryMethodName,那么基于这两个条件这里就需要对rawCandidates进一步进行筛选,得到一个candidateList集合。我们对示例的代码进行调试会发现
确实如我们所料,
rawCandidates是factoryClass中的所有方法,candidateList是所有getDmz的重载方法。在确定了推断factoryMethod的范围后,那么接下来要根据什么去确定到底使用哪个方法呢?换个问题,怎么区分这么些重载的方法呢?肯定是根据方法参数嘛!
所以接下来要做的就是去解析要使用的参数了~
对于Spring而言,方法的参数会分为两种
- 配置文件中指定的
- 自动注入模式下,需要去容器中查找的
在上面的代码中,Spring就是将配置文件中指定的参数做了一次解析,对应方法就是
resolveConstructorArguments。在查看这个方法的源码前,我们先看看
ConstructorArgumentValues这个类public class ConstructorArgumentValues { // 通过下标方式指定的参数 private final Map<Integer, ValueHolder> indexedArgumentValues = new LinkedHashMap<>(); // 没有指定下标 private final List<ValueHolder> genericArgumentValues = new ArrayList<>(); // 省略无关代码..... }在前文的注释中我们也说过了,它主要的作用就是封装解析
constructor-arg标签得到的属性,解析标签对应的方法就是org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parseConstructorArgElement,这个方法我就不带大家看了,有兴趣的可以自行阅读。它主要有两个属性
- indexedArgumentValues
- genericArgumentValues
对应的就是我们两种指定参数的方法,如下:
<bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" scope="prototype"> <constructor-arg name="name" value="dmz"/> <constructor-arg name="age" value="18"/> <constructor-arg index="2" value="2020-05-23"/> <!-- <constructor-arg name="birthDay" value="2020-05-23"/>--> </bean>其中的name跟age属性会被解析为
genericArgumentValues,而index=2会被解析为indexedArgumentValues。在对
ConstructorArgumentValues有一定认知之后,我们再来看看resolveConstructorArguments的代码:// 方法目的:解析配置文件中指定的方法参数 // beanName:bean名称 // mbd:beanName对应的beanDefinition // bw:通过它进行类型转换 // ConstructorArgumentValues cargs:解析标签得到的属性,还没有经过解析(类型转换) // ConstructorArgumentValues resolvedValues:已经经过解析的参数 // 返回值:返回方法需要的最小参数个数 private int resolveConstructorArguments(String beanName, RootBeanDefinition mbd, BeanWrapper bw, ConstructorArgumentValues cargs, ConstructorArgumentValues resolvedValues) { // 是否有定制的类型转换器,没有的话直接使用BeanWrapper进行类型转换 TypeConverter customConverter = this.beanFactory.getCustomTypeConverter(); TypeConverter converter = (customConverter != null ? customConverter : bw); // 构造一个BeanDefinitionValueResolver,专门用于解析constructor-arg中的value属性,实际上还包括ref属性,内嵌bean标签等等 BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this.beanFactory, beanName, mbd, converter); // minNrOfArgs 记录执行方法要求的最小参数个数,一般情况下就是等于constructor-arg标签指定的参数数量 int minNrOfArgs = cargs.getArgumentCount(); for (Map.Entry<Integer, ConstructorArgumentValues.ValueHolder> entry : cargs.getIndexedArgumentValues().entrySet()) { int index = entry.getKey(); if (index < 0) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid constructor argument index: " + index); } // 这是啥意思呢? // 这个代码我认为是有问题的,并且我给Spring官方已经提了一个issue,官方将会在5.2.7版本中修复 // 暂且你先这样理解 // 假设A方法直接在配置文件中指定了index=3上要使用的参数,那么这个时候A方法至少需要4个参数 // 但是其余的3个参数可能不是通过constructor-arg标签指定的,而是直接自动注入进来的,那么在配置文件中我们就只配置了index=3上的参数,也就是说 int minNrOfArgs = cargs.getArgumentCount()=1,这个时候 index=3,minNrOfArgs=1, 所以 minNrOfArgs = 3+1 if (index > minNrOfArgs) { minNrOfArgs = index + 1; } ConstructorArgumentValues.ValueHolder valueHolder = entry.getValue(); // 如果已经转换过了,直接添加到resolvedValues集合中 if (valueHolder.isConverted()) { resolvedValues.addIndexedArgumentValue(index, valueHolder); } else { // 解析value/ref/内嵌bean标签等 Object resolvedValue = valueResolver.resolveValueIfNecessary("constructor argument", valueHolder.getValue()); // 将解析后的resolvedValue封装成一个新的ValueHolder,并将其source设置为解析constructor-arg得到的那个ValueHolder,后期会用到这个属性进行判断 ConstructorArgumentValues.ValueHolder resolvedValueHolder = new ConstructorArgumentValues.ValueHolder(resolvedValue, valueHolder.getType(), valueHolder.getName()); resolvedValueHolder.setSource(valueHolder); resolvedValues.addIndexedArgumentValue(index, resolvedValueHolder); } } // 对getGenericArgumentValues进行解析,代码基本一样,不再赘述 return minNrOfArgs; }可以看到,最终的解析逻辑就在
resolveValueIfNecessary这个方法中,那么这个方法又做了什么呢?// 这个方法的目的就是将解析constructor-arg标签得到的value值进行一次解析 // 在解析标签时ref属性会被封装为RuntimeBeanReference,那么在这里进行解析时就会去调用getBean // 在解析value属性会会被封装为TypedStringValue,那么这里会尝试去进行一个转换 // 关于标签的解析大家有兴趣的话可以去看看org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parsePropertyValue // 这里不再赘述了 public Object resolveValueIfNecessary(Object argName, @Nullable Object value) { // 解析constructor-arg标签中的ref属性,实际就是调用了getBean if (value instanceof RuntimeBeanReference) { RuntimeBeanReference ref = (RuntimeBeanReference) value; return resolveReference(argName, ref); } // ...... /** * <constructor-arg> * <set value-type="java.lang.String"> * <value>1</value> * </set> * </constructor-arg> * 通过上面set标签中的value-type属性对value进行类型转换, * 如果value-type属性为空,那么这里不会进行类型转换 */ else if (value instanceof TypedStringValue) { TypedStringValue typedStringValue = (TypedStringValue) value; Object valueObject = evaluate(typedStringValue); try { Class<?> resolvedTargetType = resolveTargetType(typedStringValue); if (resolvedTargetType != null) { return this.typeConverter.convertIfNecessary(valueObject, resolvedTargetType); } else { return valueObject; } } catch (Throwable ex) { // Improve the message by showing the context. throw new BeanCreationException( this.beanDefinition.getResourceDescription(), this.beanName, "Error converting typed String value for " + argName, ex); } } // 省略后续代码.... }就我们上面的例子而言,经过
resolveValueIfNecessary方法并不能产生实际的影响,因为在XML中我们没有配置ref属性或者value-type属性。画图如下:
第五段
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代码:到这里已经得到了一个BeanWrapper,并对这个BeanWrapper做了初始化
// 第二段代码:明确了实例化当前这个Bean到底是静态工厂还是实例工厂
// 第三段代码:以及从缓存中取过了对应了方法以及参数
// 第四段代码:明确了方法需要的最小的参数数量并对配置文件中的标签属性进行了一次解析
// 进入第五段代码分析
// 保存在创建方法参数数组过程中发生的异常,如果最终没有找到合适的方法,那么将这个异常信息封装后抛出
LinkedList<UnsatisfiedDependencyException> causes = null;
// 开始遍历所有在第四段代码中查询到的符合要求的方法
for (Method candidate : candidates) {
// 方法的参数类型
Class<?>[] paramTypes = candidate.getParameterTypes();
// 候选的方法的参数必须要大于在第四段这推断出来的最小参数个数
if (paramTypes.length >= minNrOfArgs) {
ArgumentsHolder argsHolder;
// 必定为null,不考虑
if (explicitArgs != null) {
// Explicit arguments given -> arguments length must match exactly.
if (paramTypes.length != explicitArgs.length) {
continue;
}
argsHolder = new ArgumentsHolder(explicitArgs);
}
else {
// Resolved constructor arguments: type conversion and/or autowiring necessary.
try {
// 获取参数的具体名称
String[] paramNames = null;
ParameterNameDiscoverer pnd = this.beanFactory.getParameterNameDiscoverer();
if (pnd != null) {
paramNames = pnd.getParameterNames(candidate);
}
// 根据方法的参数名称以及配置文件中配置的参数创建一个参数数组用于执行工厂方法
argsHolder = createArgumentArray(
beanName, mbd, resolvedValues, bw, paramTypes, paramNames, candidate, autowiring);
}
// 在创建参数数组的时候可能发生异常,这个时候的异常不能直接抛出,要确保所有的候选方法遍历完成,只要有一个方法符合要求即可,但是如果遍历完所有方法还是没找到合适的构造器,那么直接抛出这些异常
catch (UnsatisfiedDependencyException ex) {
if (logger.isTraceEnabled()) {
logger.trace("Ignoring factory method [" + candidate + "] of bean '" + beanName + "': " + ex);
}
// Swallow and try next overloaded factory method.
if (causes == null) {
causes = new LinkedList<>();
}
causes.add(ex);
continue;
}
// 计算类型差异
// 首先判断bd中是宽松模式还是严格模式,目前看来只有@Bean标注的方法解析得到的Bean会使用严格模式来计算类型差异,其余都是使用宽松模式
// 严格模式下,
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
// 选择一个类型差异最小的方法
if (typeDiffWeight < minTypeDiffWeight) {
factoryMethodToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousFactoryMethods = null;
}
// 省略后续代码.......
}
小总结:这段代码的核心思想就是根据
第四段代码从配置文件中解析出来的参数构造方法执行所需要的实际参数数组。如果构建成功就代表这个方法可以用于实例化Bean,然后计算实际使用的参数跟方法上申明的参数的”差异值“,并在所有符合要求的方法中选择一个差异值最小的方法接下来,我们来分析方法实现的细节
- 构建方法使用的参数数组,也就是
createArgumentArray方法,其源码如下:/* beanName:要实例化的Bean的名称 * mbd:对应Bean的BeanDefinition * resolvedValues:从配置文件中解析出来的并尝试过类型转换的参数 * bw:在这里主要就是用作类型转换器 * paramTypes:当前遍历到的候选的方法的参数类型数组 * paramNames:当前遍历到的候选的方法的参数名称 * executable:当前遍历到的候选的方法 * autowiring:是否时自动注入 */ private ArgumentsHolder createArgumentArray( String beanName, RootBeanDefinition mbd, @Nullable ConstructorArgumentValues resolvedValues, BeanWrapper bw, Class<?>[] paramTypes, @Nullable String[] paramNames, Executable executable, boolean autowiring) throws UnsatisfiedDependencyException { TypeConverter customConverter = this.beanFactory.getCustomTypeConverter(); TypeConverter converter = (customConverter != null ? customConverter : bw); ArgumentsHolder args = new ArgumentsHolder(paramTypes.length); Set<ConstructorArgumentValues.ValueHolder> usedValueHolders = new HashSet<>(paramTypes.length); Set<String> autowiredBeanNames = new LinkedHashSet<>(4); // 遍历候选方法的参数,跟据方法实际需要的类型到resolvedValues中去匹配 for (int paramIndex = 0; paramIndex < paramTypes.length; paramIndex++) { Class<?> paramType = paramTypes[paramIndex]; String paramName = (paramNames != null ? paramNames[paramIndex] : ""); ConstructorArgumentValues.ValueHolder valueHolder = null; if (resolvedValues != null) { // 首先,根据方法参数的下标到resolvedValues中找对应的下标的属性 // 如果没找到再根据方法的参数名/类型去resolvedValues查找 valueHolder = resolvedValues.getArgumentValue(paramIndex, paramType, paramName, usedValueHolders); // 如果都没找到 // 1.是自动注入并且方法的参数长度正好跟配置中的参数数量相等 // 2.不是自动注入 // 那么按照顺序一次选取 if (valueHolder == null && (!autowiring || paramTypes.length == resolvedValues.getArgumentCount())) { valueHolder = resolvedValues.getGenericArgumentValue(null, null, usedValueHolders); } } // 也就是说在配置的参数中找到了合适的值可以应用于这个方法上 if (valueHolder != null) { // 防止同一个参数被应用了多次 usedValueHolders.add(valueHolder); Object originalValue = valueHolder.getValue(); Object convertedValue; // 已经进行过类型转换就不会需要再次进行类型转换 if (valueHolder.isConverted()) { convertedValue = valueHolder.getConvertedValue(); args.preparedArguments[paramIndex] = convertedValue; } else { // 尝试将配置的值转换成方法参数需要的类型 MethodParameter methodParam = MethodParameter.forExecutable(executable, paramIndex); try { // 进行类型转换 convertedValue = converter.convertIfNecessary(originalValue, paramType, methodParam); } catch (TypeMismatchException ex) { // 抛出UnsatisfiedDependencyException,在调用该方法处会被捕获 } Object sourceHolder = valueHolder.getSource(); // 只要是valueHolder存在,到这里这个判断必定成立 if (sourceHolder instanceof ConstructorArgumentValues.ValueHolder) { Object sourceValue = ((ConstructorArgumentValues.ValueHolder) sourceHolder).getValue(); args.resolveNecessary = true; args.preparedArguments[paramIndex] = sourceValue; } } args.arguments[paramIndex] = convertedValue; args.rawArguments[paramIndex] = originalValue; } else { // 方法执行需要参数,但是resolvedValues中没有提供这个参数,也就是说这个参数是要自动注入到Bean中的 MethodParameter methodParam = MethodParameter.forExecutable(executable, paramIndex); // 不是自动注入,直接抛出异常 if (!autowiring) { // 抛出UnsatisfiedDependencyException,在调用该方法处会被捕获 } try { // 自动注入的情况下,调用getBean获取需要注入的Bean Object autowiredArgument = resolveAutowiredArgument(methodParam, beanName, autowiredBeanNames, converter); // 把getBean返回的Bean封装到本次方法执行时需要的参数数组中去 args.rawArguments[paramIndex] = autowiredArgument; args.arguments[paramIndex] = autowiredArgument; // 标志这个参数是自动注入的 args.preparedArguments[paramIndex] = new AutowiredArgumentMarker(); // 自动注入的情况下,在第二次调用时,需要重新处理,不能直接缓存 args.resolveNecessary = true; } catch (BeansException ex) { // 抛出UnsatisfiedDependencyException,在调用该方法处会被捕获 } } } // 注册Bean之间的依赖关系 for (String autowiredBeanName : autowiredBeanNames) { this.beanFactory.registerDependentBean(autowiredBeanName, beanName); if (logger.isDebugEnabled()) { logger.debug("Autowiring by type from bean name '" + beanName + "' via " + (executable instanceof Constructor ? "constructor" : "factory method") + " to bean named '" + autowiredBeanName + "'"); } } return args; }上面这段代码说难也难,说简单也简单,如果要彻底看懂它到底干了什么还是很有难度的。简单来说,它就是从第四段代码解析出来的参数中查找当前的这个候选方法需要的参数。如果找到了,那么尝试对其进行类型转换,将其转换成符合方法要求的类型,如果没有找到那么还需要判断当前方法的这个参数能不能进行自动注入,如果可以自动注入的话,那么调用getBean得到需要的Bean,并将其注入到方法需要的参数中。
第六段
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代码:到这里已经得到了一个BeanWrapper,并对这个BeanWrapper做了初始化
// 第二段代码:明确了实例化当前这个Bean到底是静态工厂还是实例工厂
// 第三段代码:以及从缓存中取过了对应了方法以及参数
// 第四段代码:明确了方法需要的最小的参数数量并对配置文件中的标签属性进行了一次解析
// 第五段代码:到这里已经确定了可以使用来实例化Bean的方法是哪个
// 省略抛出异常的代码,就是在对推断出来的方法做验证
// 1.推断出来的方法不能为null
// 2.推断出来的方法返回值不能为void
// 3.推断出来的方法不能有多个
// 对参数进行缓存
if (explicitArgs == null && argsHolderToUse != null) {
argsHolderToUse.storeCache(mbd, factoryMethodToUse);
}
}
try {
Object beanInstance;
if (System.getSecurityManager() != null) {
final Object fb = factoryBean;
final Method factoryMethod = factoryMethodToUse;
final Object[] args = argsToUse;
beanInstance = AccessController.doPrivileged((PrivilegedAction<Object>) () ->
beanFactory.getInstantiationStrategy().instantiate(mbd, beanName, beanFactory, fb, factoryMethod, args),
beanFactory.getAccessControlContext());
}
else {
// 反射调用对应方法进行实例化
// 1.获取InstantiationStrategy,主要就是SimpleInstantiationStrategy跟CglibSubclassingInstantiationStrategy,其中CglibSubclassingInstantiationStrategy主要是用来处理beanDefinition中的lookupMethod跟replaceMethod。通常来说我们使用的就是SimpleInstantiationStrateg
// 2.SimpleInstantiationStrateg就是单纯的通过反射调用方法
beanInstance = this.beanFactory.getInstantiationStrategy().instantiate(
mbd, beanName, this.beanFactory, factoryBean, factoryMethodToUse, argsToUse);
}
// beanWrapper在这里对Bean进行了包装
bw.setBeanInstance(beanInstance);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean instantiation via factory method failed", ex);
}
}
上面这段代码的主要目的就是
- 缓存参数,原型可能多次创建同一个对象
- 反射调用推断出来的factoryMethod
》通过构造函数实例化对象
如果上面你对使用factoryMethd进行实例化对象已经足够了解的话,那么下面的源码分析基本没有什么很大区别,我们接着看看代码。
首先,我们回到createBeanInstance方法中,
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// 上面的代码已经分析过了
// 1.使用supplier来得到一个对象
// 2.通过factotryMethod方法实例化一个对象
// 看起来是不是有点熟悉,在使用factotryMethod创建对象时也有差不多这样的一段代码,看起来就是使用缓存好的方法直接创建一个对象
boolean resolved = false;
boolean autowireNecessary = false;
// 不对这个参数进行讨论,就认为一直为null
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
// bd中的resolvedConstructorOrFactoryMethod不为空,说明已经解析过构造方法了
if (mbd.resolvedConstructorOrFactoryMethod != null) {
// resolved标志是否解析过构造方法
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
// 构造函数已经解析过了,并且这个构造函数在调用时需要自动注入参数
if (autowireNecessary) {
// 此时部分解析好的参数已经存在了beanDefinition中,并且构造函数也在bd中
// 那么在这里只会从缓存中去取构造函数以及参数然后反射调用
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 这里就是直接反射调用空参构造
return instantiateBean(beanName, mbd);
}
}
// 推断出能够使用的需要参数的构造函数
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
// 在推断出来的构造函数中选取一个合适的方法来进行Bean的实例化
// ctors不为null:说明存在1个或多个@Autowired标注的方法
// mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR:说明是自动注入
// mbd.hasConstructorArgumentValues():配置文件中配置了构造函数要使用的参数
// !ObjectUtils.isEmpty(args):外部传入的参数,必定为null,不多考虑
// 上面的条件只要满足一个就会进入到autowireConstructor方法
// 第一个条件满足,那么通过autowireConstructor在推断出来的构造函数中再进一步选择一个差异值最小的,参数最长的构造函数
// 第二个条件满足,说明没有@Autowired标注的方法,但是需要进行自动注入,那么通过autowireConstructor会去遍历类中申明的所有构造函数,并查找一个差异值最小的,参数最长的构造函数
// 第三个条件满足,说明不是自动注入,那么要通过配置中的参数去类中申明的所有构造函数中匹配
// 第四个必定为null,不考虑
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// 反射调用空参构造
return instantiateBean(beanName, mbd);
}
因为autowireConstructor方法的执行逻辑跟instantiateUsingFactoryMethod方法的执行逻辑基本一致,只是将Method对象换成了Constructor对象,所以对这个方法我不再做详细的分析。
我们主要就看看determineConstructorsFromBeanPostProcessors这个方法吧,这个方法的主要目的就是推断出候选的构造方法。
determineConstructorsFromBeanPostProcessors方法做了什么?
// 实际调用的就是AutowiredAnnotationBeanPostProcessor中的determineCandidateConstructors方法
// 这个方法看起来很长,但实际确很简单,就是通过@Autowired注解确定哪些构造方法可以作为候选方法,其实在使用factoryMethod来实例化对象的时候也有这种逻辑在其中,后续在总结的时候我们对比一下
public Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, final String beanName)
throws BeanCreationException {
// 这里做的事情很简单,就是将@Lookup注解标注的方法封装成LookupOverride添加到BeanDefinition中的methodOverrides属性中,如果这个属性不为空,在实例化对象的时候不能选用SimpleInstantiationStrateg,而要使用CglibSubclassingInstantiationStrategy,通过cglib代理给方法加一层拦截了逻辑
// 避免重复检查
if (!this.lookupMethodsChecked.contains(beanName)) {
try {
ReflectionUtils.doWithMethods(beanClass, method -> {
Lookup lookup = method.getAnnotation(Lookup.class);
if (lookup != null) {
Assert.state(this.beanFactory != null, "No BeanFactory available"); // 将@Lookup注解标注的方法封装成LookupOverride
LookupOverride override = new LookupOverride(method, lookup.value());
try {
// 添加到BeanDefinition中的methodOverrides属性中
RootBeanDefinition mbd = (RootBeanDefinition)
this.beanFactory.getMergedBeanDefinition(beanName);
mbd.getMethodOverrides().addOverride(override);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(beanName,
"Cannot apply @Lookup to beans without corresponding bean definition");
}
}
});
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName, "Lookup method resolution failed", ex);
}
this.lookupMethodsChecked.add(beanName);
}
// 接下来要开始确定到底哪些构造函数能被作为候选者
// 先尝试从缓存中获取
Constructor<?>[] candidateConstructors = this.candidateConstructorsCache.get(beanClass);
if (candidateConstructors == null) {
// Fully synchronized resolution now...
synchronized (this.candidateConstructorsCache) {
candidateConstructors = this.candidateConstructorsCache.get(beanClass);、
// 缓存中无法获取到,进入正式的推断过程
if (candidateConstructors == null) {
Constructor<?>[] rawCandidates;
try {
// 第一步:先查询这个类所有的构造函数,包括私有的
rawCandidates = beanClass.getDeclaredConstructors();
}
catch (Throwable ex) {
// 省略异常信息
}
List<Constructor<?>> candidates = new ArrayList<>(rawCandidates.length);
// 保存添加了Autowired注解并且required属性为true的构造方法
Constructor<?> requiredConstructor = null;
// 空参构造
Constructor<?> defaultConstructor = null;
// 看方法注释上说明的,这里除非是kotlin的类,否则必定为null,不做过多考虑,我们就将其当作null
Constructor<?> primaryConstructor = BeanUtils.findPrimaryConstructor(beanClass);
int nonSyntheticConstructors = 0;
// 对类中的所有构造方法进行遍历
for (Constructor<?> candidate : rawCandidates) {
// 非合成方法
if (!candidate.isSynthetic()) {
nonSyntheticConstructors++;
}
else if (primaryConstructor != null) {
continue;
}
// 查询方法上是否有Autowired注解
AnnotationAttributes ann = findAutowiredAnnotation(candidate);
if (ann == null) {
// userClass != beanClass说明这个类进行了cglib代理
Class<?> userClass = ClassUtils.getUserClass(beanClass);
if (userClass != beanClass) {
try {
// 如果进行了cglib代理,那么在父类上再次查找Autowired注解
Constructor<?> superCtor =
userClass.getDeclaredConstructor(candidate.getParameterTypes());
ann = findAutowiredAnnotation(superCtor);
}
catch (NoSuchMethodException ex) {
// Simply proceed, no equivalent superclass constructor found...
}
}
}
// 说明当前的这个构造函数上有Autowired注解
if (ann != null) {
if (requiredConstructor != null) {
// 省略异常抛出
}
// 获取Autowired注解中的required属性
boolean required = determineRequiredStatus(ann);
if (required) {
// 类中存在多个@Autowired标注的方法,并且某个方法的@Autowired注解上被申明了required属性要为true,那么直接报错
if (!candidates.isEmpty()) {
// 省略异常抛出
}
requiredConstructor = candidate;
}
// 添加到集合中,这个集合存储的都是被@Autowired注解标注的方法
candidates.add(candidate);
}
// 空参构造函数
else if (candidate.getParameterCount() == 0) {
defaultConstructor = candidate;
}
}
if (!candidates.isEmpty()) {
// 存在多个被@Autowired标注的方法
// 并且所有的required属性被设置成了false (默认为true)
if (requiredConstructor == null) {
// 存在空参构造函数,注意,空参构造函数可以不被@Autowired注解标注
if (defaultConstructor != null) {
// 将空参构造函数也加入到候选的方法中去
candidates.add(defaultConstructor);
}
// 省略日志打印
}
candidateConstructors = candidates.toArray(new Constructor<?>[0]);
}
// 也就是说,类中只提供了一个构造函数,并且这个构造函数不是空参构造函数
else if (rawCandidates.length == 1 && rawCandidates[0].getParameterCount() > 0) {
candidateConstructors = new Constructor<?>[] {rawCandidates[0]};
}
// 省略中间两个判断,primaryConstructor必定为null,不考虑
// .....
}
else {
// 说明无法推断出来
candidateConstructors = new Constructor<?>[0];
}
this.candidateConstructorsCache.put(beanClass, candidateConstructors);
}
}
}
return (candidateConstructors.length > 0 ? candidateConstructors : null);
}
这里我简单总结下这个方法的作用
获取到类中的所有构造函数
查找到被
@Autowired注解标注的构造函数
- 如果存在多个被
@Autowired标注的构造函数,并且其required属性没有被设置为true,那么返回这些被标注的函数的集合(空参构造即使没有添加@Autowired也会被添加到集合中)- 如果存在多个被
@Autowired标注的构造函数,并且其中一个的required属性被设置成了true,那么直接报错- 如果只有一个构造函数被
@Autowired标注,并且其required属性被设置成了true,那么直接返回这个构造函数如果没有被
@Autowired标注标注的构造函数,但是类中有且只有一个构造函数,并且这个构造函数不是空参构造函数,那么返回这个构造函数上面的条件都不满足,那么
determineCandidateConstructors这个方法就无法推断出合适的构造函数了
可以看到,通过AutowiredAnnotationBeanPostProcessor的determineCandidateConstructors方法可以处理构造函数上的@Autowired注解。
但是,请注意,这个方法并不能决定到底使用哪个构造函数来创建对象(即使它只推断出来一个,也不一定能够使用),它只是通过@Autowired注解来确定构造函数的候选者,在构造函数都没有添加@Autowired注解的情况下,这个方法推断不出来任何方法。真正确定到底使用哪个构造函数是交由autowireConstructor方法来决定的。前文已经分析过了instantiateUsingFactoryMethod方法,autowireConstructor的逻辑基本跟它一致,所以这里不再做详细的分析。
factoryMethod跟构造函数的比较
整体逻辑比较
从上图中可以看到,整体逻辑上它们并没有什么区别,只是查找的对象从factoryMethod换成了构造函数
执行细节比较
细节的差异主要体现在推断方法上
- 推断factoryMethod
- 推断构造函数
它们之间的差异我已经在图中标识出来了,主要就是两点
- 通过构造函数实例化对象,多了一层处理,就是要处理构造函数上的@Autowired注解以及方法上的@LookUp注解(要决定选取哪一种实例化策略,
SimpleInstantiationStrategy/CglibSubclassingInstantiationStrategy)- 在最终的选取也存在差异,对于facotyMehod而言,在宽松模式下(
除ConfigurationClassBeanDefinition外,也就是扫描@Bean得到的BeanDefinition,都是宽松模式),会选取一个最精准的方法,在严格模式下,会选取一个参数最长的方法- 对于构造函数而言,会必定会选取一个参数最长的方法
关于计算类型差异的补充内容
思考了很久,我还是决定再补充一些内容,就是关于上面两幅图的最后一步,对应的核心代码如下:
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
if (typeDiffWeight < minTypeDiffWeight) {
factoryMethodToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousFactoryMethods = null;
}
-
判断bd是严格模式还是宽松模式,上面说过很多次了,bd默认就是宽松模式,只要在
ConfigurationClassBeanDefinition中使用严格模式,也就是扫描@Bean标注的方法注册的bd(对应的代码可以参考:org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader#loadBeanDefinitionsForBeanMethod方法)我们再看看严格模式跟宽松模式在计算差异值时的区别
- 宽松模式
public int getTypeDifferenceWeight(Class<?>[] paramTypes) { // 计算实际使用的参数跟方法申明的参数的差异值 int typeDiffWeight = MethodInvoker.getTypeDifferenceWeight(paramTypes, this.arguments); // 计算没有经过类型转换的参数跟方法申明的参数的差异值 int rawTypeDiffWeight = MethodInvoker.getTypeDifferenceWeight(paramTypes, this.rawArguments) - 1024; return (rawTypeDiffWeight < typeDiffWeight ? rawTypeDiffWeight : typeDiffWeight); } public static int getTypeDifferenceWeight(Class<?>[] paramTypes, Object[] args) { int result = 0; for (int i = 0; i < paramTypes.length; i++) { // 在出现类型转换时,下面这个判断才会成立,也就是在比较rawArguments跟paramTypes的差异时才可能满足这个条件 if (!ClassUtils.isAssignableValue(paramTypes[i], args[i])) { return Integer.MAX_VALUE; } if (args[i] != null) { Class<?> paramType = paramTypes[i]; Class<?> superClass = args[i].getClass().getSuperclass(); while (superClass != null) { // 如果我们传入的值是方法上申明的参数的子类,那么每多一层继承关系,差异值加2 if (paramType.equals(superClass)) { result = result + 2; superClass = null; } else if (ClassUtils.isAssignable(paramType, superClass)) { result = result + 2; superClass = superClass.getSuperclass(); } else { superClass = null; } } // 判断方法的参数是不是一个接口,如果是,那么差异值加1 if (paramType.isInterface()) { result = result + 1; } } } return result; }- 严格模式(主要应用于@Bean标注的方法对应的BeanDefinition)
public int getAssignabilityWeight(Class<?>[] paramTypes) { // 严格模式下,只有三种返回值 // 1.Integer.MAX_VALUE,经过类型转换后还是不符合要求,返回最大的类型差异 // 因为解析后的参数可能返回一个NullBean(创建对象的方法返回了null,Spring会将其包装成一个NullBean),不过一般不会出现这种情况,所以我们可以当这种情况不存在 for (int i = 0; i < paramTypes.length; i++) { if (!ClassUtils.isAssignableValue(paramTypes[i], this.arguments[i])) { return Integer.MAX_VALUE; } } // 2.Integer.MAX_VALUE - 512,进行过了类型转换才符合要求 for (int i = 0; i < paramTypes.length; i++) { if (!ClassUtils.isAssignableValue(paramTypes[i], this.rawArguments[i])) { return Integer.MAX_VALUE - 512; } } // 3.Integer.MAX_VALUE - 1024,没有经过类型转换就已经符合要求了,返回最小的类型差异 return Integer.MAX_VALUE - 1024; }首先,不管是factoryMethod还是constructor,都是采用上面的两个方法来计算类型差异,但是正常来说,只有factoryMethod会采用到严格模式(除非程序员手动干预,比如通过Bean工厂后置处理器修改了bd中的属性,这样通常来说没有很大意义)
所以我们分为三种情况讨论
1、factoryMethod+宽松模式
这种情况下,会选取一个最精确的方法,同时方法的参数要尽量长
测试代码:
public class FactoryObject { public DmzService getDmz() { System.out.println(0); return new DmzService(); } public DmzService getDmz(OrderService indexService) { System.out.println(1); return new DmzService(); } public DmzService getDmz(OrderService orderService, IndexService indexService) { System.out.println(2); return new DmzService(); } public DmzService getDmz(OrderService orderService, IndexService indexService,IA ia) { System.out.println(3); return new DmzService(); } } public class ServiceImpl implements IService { } public class IAImpl implements IA { }<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd" default-autowire="constructor"><!--必须要开启自动注入,并且是通过构造函数进行自动注入,否则选用无参构造--> <!--factoryObject 提供了创建对象的方法--> <bean id="factoryObject" class="com.dmz.spring.instantiation.service.FactoryObject"/> <bean class="com.dmz.spring.instantiation.service.OrderService" id="orderService"/> <bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" /> <bean class="com.dmz.spring.instantiation.service.ServiceImpl" id="iService"/> <bean class="com.dmz.spring.instantiation.service.IndexService" id="indexService"/> </beans>/** * @author 程序员DMZ * @Date Create in 23:59 2020/6/1 * @Blog https://daimingzhi.blog.csdn.net/ */ public class XMLMain { public static void main(String[] args) { ClassPathXmlApplicationContext cc = new ClassPathXmlApplicationContext("application.xml"); } }运行程序发现,选用了第三个(
getDmz(OrderService orderService, IndexService indexService))构造方法。虽然最后一个方法的参数更长,但是因为其方法申明的参数上存在接口,所以它的差异值会大于第三个方法,因为不会被选用2、factoryMethod+严格模式
这种情况下,会选取一个参数尽量长的方法
测试代码:
/** * @author 程序员DMZ * @Date Create in 6:28 2020/6/1 * @Blog https://daimingzhi.blog.csdn.net/ */ @ComponentScan("com.dmz.spring.instantiation") @Configuration public class Config { @Bean public DmzService dmzService() { System.out.println(0); return new DmzService(); } @Bean public DmzService dmzService(OrderService indexService) { System.out.println(1); return new DmzService(); } @Bean public DmzService dmzService(OrderService orderService, IndexService indexService) { System.out.println(2); return new DmzService(); } @Bean public DmzService dmzService(OrderService orderService, IndexService indexService, IA ia) { System.out.println("config " +3); return new DmzService(); } @Bean public DmzService dmzService(OrderService orderService, IndexService indexService, IA ia, IService iService) { System.out.println("config " +4); return new DmzService(); } } /** * @author 程序员DMZ * @Date Create in 6:29 2020/6/1 * @Blog https://daimingzhi.blog.csdn.net/ */ public class Main { public static void main(String[] args) { AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(); ac.register(Config.class); ac.refresh(); } }运行程序,发现选用了最后一个构造函数,这是因为在遍历候选方法时,会先遍历参数最长的,而在计算类型差异时,因为严格模式下,上面所有方法的差异值都是一样的,都会返回
Integer.MAX_VALUE - 1024。实际上,在不进行手动干预的情况下,都会返沪这个值。3、构造函数+宽松模式
这种情况下,也会选取一个参数尽量长的方法
之所以会这样,主要是因为在
autowireConstructor方法中进行了一次短路判断,如下所示:在上图中,如果已经找到了合适的方法,那么直接就不会再找了,而在遍历的时候是从参数最长的方法开始遍历的,测试代码如下:
@Component public class DmzService { // 没有添加@Autowired注解,也会被当作候选方法 public DmzService(){ System.out.println(0); } @Autowired(required = false) public DmzService(OrderService orderService) { System.out.println(1); } @Autowired(required = false) public DmzService(OrderService orderService, IService iService) { System.out.println(2); } @Autowired(required = false) public DmzService(OrderService orderService, IndexService indexService, IService iService,IA ia) { System.out.println("DmzService "+3); } } /** * @author 程序员DMZ * @Date Create in 6:29 2020/6/1 * @Blog https://daimingzhi.blog.csdn.net/ */ public class Main { public static void main(String[] args) { AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(); ac.register(Config.class); ac.refresh(); } }这篇文章就到这里啦~~!
文章很长,希望你耐心看完,码字不易,如果有帮助到你的话点个赞吧~!
扫描下方二维码,关注我的公众号,更多精彩文章在等您!~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号