

数据结构汇总(线性表→普通二叉搜索树)
首先问自己几个问题,什么是数据结构?为什么要有数据结构?学了之后又能干什么?
接下来我将按自己对其概念的理解一一给出我的答案。
数据结构。也就是data structure; 个人感觉这个词分成两组来理解
1.数据(我们知道计算机,归根结底操作的都是数据,没有数据也就没有任何意义)
2.结构(那么这些数据 在计算机中是以什么方式进行存储呢?)
在日常生活中,房间里的物品是如何摆放的?通常的:鞋子放在鞋架上,衣服放到衣柜里,餐具放到厨柜里等等
那么这样我们在穿鞋的时候自然去鞋架寻找,穿衣服时到衣柜里寻找,吃饭的时候要到橱柜了拿餐具等等。
那么我们为什么要这样做,为什么不直接弄一个'万能柜',把鞋子、衣服、餐具都放到一起。找的时候从一个柜子里来回找就好了
虽然这种方式从理论上可以行通,我想实际中应该没有一个人愿意这样去做。
那么,在计算机中也是如此,如果不对数据进行特殊的组织,所有的数据都堆积到内存中。无疑计算机在进行操作数据的时候想找到当前需要的数据便成了一大难题。
所以总结:数据结构就是指数据在计算机中的存储方式。研究的是如何存储数据才能更快的找到当前所需要的数据。
数据结构的分类:
数据结构从逻辑上可以分为线性结构和非线性结构(注意是逻辑上的划分,而不是真正的存储结构上)
一、线性结构
常见的线性结构有 线性表(向量、数组)、链表(列表)。而栈和队列这两种结构不如说是线性表或者链表的应用。
1.线性表,还是同样问自己几个问题,什么是线性表?线性表优缺点?

如上图所示:
假设计算的内存编号0x1213-121d 中存储了以上数据(假设每个数据只占一个字节)。可以很直观的看出存储数据的地址空间是连续的。这也正是人们最初存储数据的方式。
这样的存储有什么优点呢?
计算机只需要记住第0个数据的存储地址(起始地址),根据所谓的偏移量就可以快速的定位到序列中的其他数据的位置。所以在进行查询和修改操作的时间成本是很低的
只需O(1). 即常数时间。
这样存储的缺点呢?
看以下实例:现在我要将上述的数据8删除:
计算机会做以下两件事:
1.删掉数据8所在位置的数据:

2.将其后边所有的的元素依次往前移动,只到序列再次变为线性表

可见删除操作需要对要删除的每个后继元素进行移动,每次移动即会花费时间。如果删除的元素为数据0,那么剩余所有的元素都将进行一次移动。
接下来再来看看线性表的插入操作。例如再上述4,5中间插入一个数据b。
1.将5后边的数据一次向后移动,留出空位。

2.将新要插入的数据b添加到空位中:

依然可以看的出要进行元素不断移动的过程。如果插入的元素在数据0后边,那么剩余所有的元素的后继也都将进行一次移动。
同删除操作,其平均时间复杂的达到了O(n) 数量级。
总结线性表的操作复杂度:
插入和删除 O(n)
查找和更新 O(1)
在插入和删除操作上显然效率并没有查找那么理想。平均复杂度达到O(n), 如何优化呢? 带着这个问题再来看链表。
2.链表 为什么会有链表?
先看一下链表的存储结构

如上图所示:
在内存的不同位置存储了四组节点,内存地址毫无关联。 每组节点都有数据部分和next指针部分,数据部分存放着自己的data,next指针则指向该节点的后继。
从而产生关联。
现在再来看进行某个节点的删除操作:比如删除上图的Data47
1.只需要将next指针进行更新,指向新的节点即可。

2.再将没有被引用的节点free掉(高级语言中一般会自己释放)

可见删除操作只需要更新其前驱的next指针即可,也可达到O(1)。
同样再来看插入操作:
在上述data35后 插入一个data100
1.修改data100的next指向data39
2.修改data35的next指针指向data100
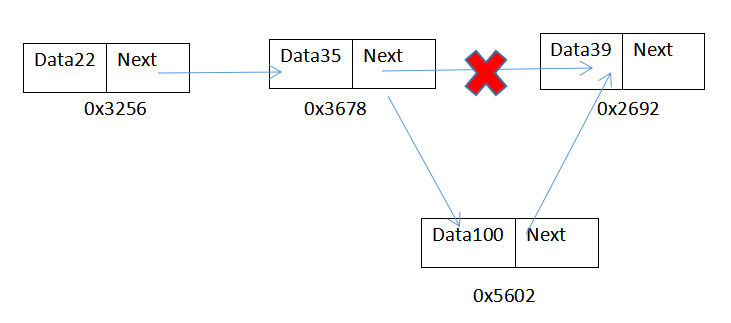

可见插入操作也只是修改了对应的指针,复杂度可达到O(1)
那么查找和修改的操作呢?是否还能保持线性表的优势?
由于存储的地址毫无关联,我们只能通过首节点沿着链路依次比对进行查找。而更新数据的前提也需要先找到该节点。因此此时查找和更新将达到O(n)复杂度。
总结链表的操作复杂度:
插入和删除 O(1)
查找和更新 O(n)
然而,以线性表为例,很多时候我们的查找并不是简单的通过其下标位置去找对应的数据。
而是知道要找的数据,想确定其在线性表中的位置。
那么这类情况就要遍历整个线性表,从而找到自己想要的数据。
例如:
在下边的线性表中找到值为31的所在位置:

由于数据之间的存储没有任何关系,我们只能采取从一端开始一一比较的方式,从头找到尾。找到31的值则返回当前位置。
找到31需要进行8次比较,类比如果找68则需要比较10次。
最坏情况复杂度达到了O(n);
如果数据在存储的时候事先排好序又会有何变化呢?
比如在下边有序的线性表中找到66这个值对应的位置。

由于数据存储是有序的,所以在查找的时候可以采用二分查找(折半查找)法:
主要思路:
设线性表长度为n,先从n/2处进行对比,如果n/2的值小于要查找的值,说明其存在于后半段,反之在前半段。
可见一次对比则排除了一半的数据。 下一次比较在后半段按照这个方法比较即可。
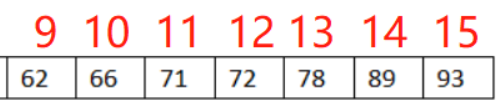
比如上述线性表长度为16,在其中查找66:
第一次比较:找下标为8的位置,发现59<66 因此查找范围变为:
第二次比较:查找下标为12的位置,发现72>66 此时范围缩短为:
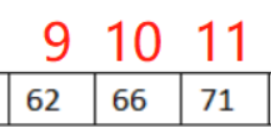
第三次比较:查找下标为10的位置,正好命中。
找到66只需比较3次。
如果当时找的数字为65,在序列中并不存在,也只需要再多比较一次即可跳出查找。
在长度为16的序列,查找任何一个数不会超过4次。即log216。
该方法的平均时间复杂度为log2 N(N为序列的长度) 远远好于无序线性表的O(N)。
2.半线性结构
通过上边的线性结构可以看的出,无论是哪种存储方式都有自己的优点、也有自己不足的地方。
虽然上述的有序序列在查找的时候可以达到log2N,但是在插入,删除数据仍然有着天然的弊端。
不过在不进行插入删除的序列中进行静态查找,有序线性表还是不错的选择。
然而现实总不那么简单,查找的序列总会有新增删除的时候,序列是在不断的动态更新。
那么是否有一种结构可以中和二者的优点,并且可以完美的适用于动态查找呢?
以上述有序序列为例:
我们可以把它构建成树形结构(如下图):
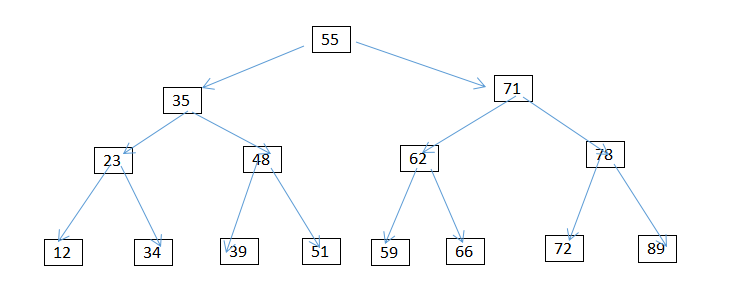
这种树形结构我们可以称之为一种半线性结构。
从该树的根节点向下投影可以看到以下有序序列:(即树的中序遍历结果)
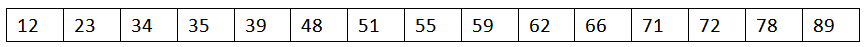
按照二分查找的思想来看从这棵有序树中查找一个元素的过程。从根节点出发每次比较可排除一半的节点。每一层只访问到一个节点。
不难看出:最多的比较次数也不过是要查找的元素在叶子节点()。比较次数为数的高度(log2N)。
删除一个节点:
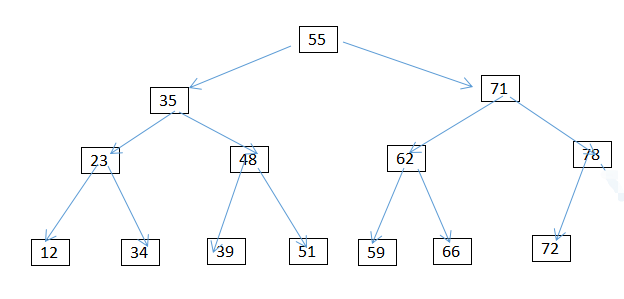
删除一个节点可分为三种情况:
情况1.删除叶子节点(没有左右孩子的节点)删除元素51,按照查询的方式先找到51,直接删除就好了
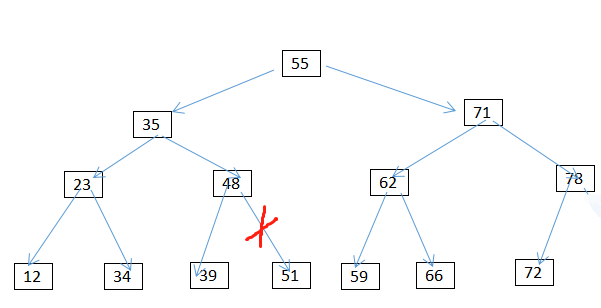
情况2:删除只有一个孩子的节点 譬如删除78 同样也要先查询到78 将其删除,将其删除,其父节点指向其儿子72即可。
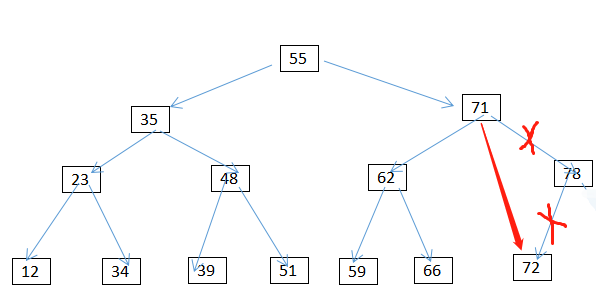
情况3:删除有两个孩子的节点 譬如35
1.用该节点左子树的最大值或者右子树的最小值来替换该节点(因为左子树的最大值与右子树的最小值一定不可能有两个孩子)
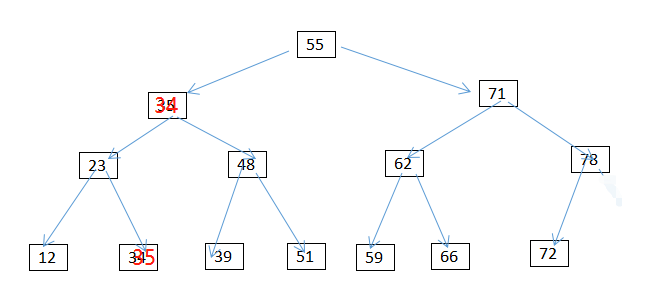
2.将35删除 (即转换为第一种情况的删除)
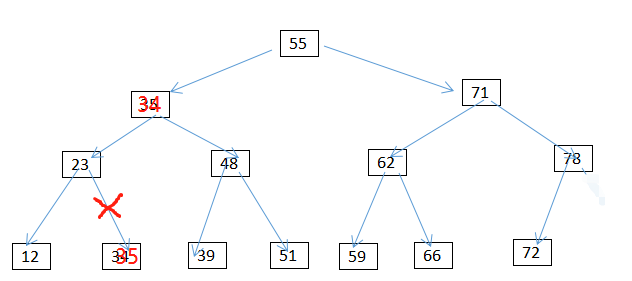
插入节点、更新节点的思路与删除节点基本相同,都是先找到该节点。(即主要耗费时间依然是查询时间log2N)
可见:这种有序的树形结构的增加、删除、更新、以及查询等操作都可以在log2N的时间内完成。比起线性结构最坏
的O(n)已经有了很大的提升。
那么目前的这种结构是否还有存在不足的地方呢?如果有该如何改进呢?
关于上述问题将会在下节的高级搜索树中一一解答。
