摘要:  深入解析 Flink SQL 四大 Join(Regular, Interval, Temporal, Lookup),结合电商场景实战,剖析生产环境中的 State 爆炸、乱序数据处理及性能优化策略。 阅读全文
深入解析 Flink SQL 四大 Join(Regular, Interval, Temporal, Lookup),结合电商场景实战,剖析生产环境中的 State 爆炸、乱序数据处理及性能优化策略。 阅读全文
深入解析 Flink SQL 四大 Join(Regular, Interval, Temporal, Lookup),结合电商场景实战,剖析生产环境中的 State 爆炸、乱序数据处理及性能优化策略。 阅读全文
posted @ 2026-03-08 20:29
代码匠心
阅读(118)
评论(0)
推荐(2)
 手把手教你安装 Claude Code 并配置国内大模型,结合 frontend-design 技能,零代码快速构建高颜值的技术博客首页。
手把手教你安装 Claude Code 并配置国内大模型,结合 frontend-design 技能,零代码快速构建高颜值的技术博客首页。  通过 Hive Catalog 将 Flink SQL 的表结构等元数据持久化到 Hive Metastore,打造生产级实时数仓元数据中心,让 SQL 不再“重启就丢”。
通过 Hive Catalog 将 Flink SQL 的表结构等元数据持久化到 Hive Metastore,打造生产级实时数仓元数据中心,让 SQL 不再“重启就丢”。  以电商订单实时数仓为例,演示如何在 Flink SQL 中通过维表时态 Join 将事实流与维度数据关联,构建带用户属性的明细宽表,并结合 Kafka 与 MySQL 环境完成一套可落地的实时数仓入门实践。
以电商订单实时数仓为例,演示如何在 Flink SQL 中通过维表时态 Join 将事实流与维度数据关联,构建带用户属性的明细宽表,并结合 Kafka 与 MySQL 环境完成一套可落地的实时数仓入门实践。  通过订单与支付双流关联的实战案例,系统讲解 Flink SQL 中的双流 JOIN 类型、时间条件与实现方式,帮助你理解流计算场景下的关联查询思路和坑点。
通过订单与支付双流关联的实战案例,系统讲解 Flink SQL 中的双流 JOIN 类型、时间条件与实现方式,帮助你理解流计算场景下的关联查询思路和坑点。  深入解析 Flink SQL 窗口机制,详解滚动、滑动、累积窗口的语法与场景,结合订单统计实战,助你掌握流处理核心技能。
深入解析 Flink SQL 窗口机制,详解滚动、滑动、累积窗口的语法与场景,结合订单统计实战,助你掌握流处理核心技能。 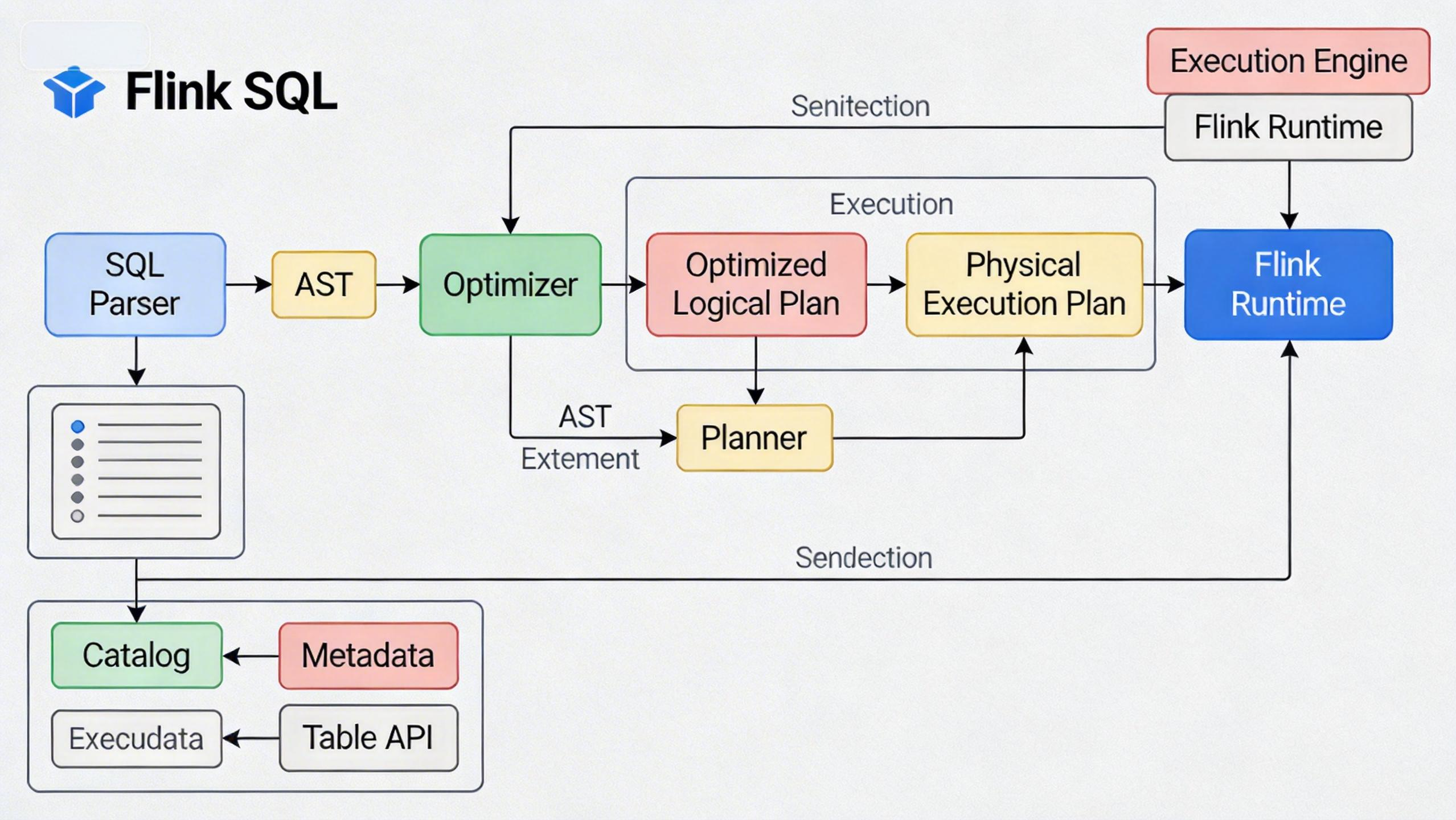 无需Java/Scala代码!本文基于Flink 1.20.1版本,手把手教你在WSL2 Ubuntu环境下搭建开发环境,使用SQL Client体验实时流计算的魅力,轻松跑通第一个数据流任务。
无需Java/Scala代码!本文基于Flink 1.20.1版本,手把手教你在WSL2 Ubuntu环境下搭建开发环境,使用SQL Client体验实时流计算的魅力,轻松跑通第一个数据流任务。  如何在 Trae IDE 中利用 jimeng-api 项目,快速搭建并使用即梦 (Jimeng) 的 AI 绘图能力,实现免费的高质量图像生成。
如何在 Trae IDE 中利用 jimeng-api 项目,快速搭建并使用即梦 (Jimeng) 的 AI 绘图能力,实现免费的高质量图像生成。  本文深入解析 Apache Flink 的核心特性——状态管理(State Management)与容错机制(Fault Tolerance),涵盖状态类型、State Backend 选择、Checkpoint 原理及配置、以及 Savepoint 的生产实践。
本文深入解析 Apache Flink 的核心特性——状态管理(State Management)与容错机制(Fault Tolerance),涵盖状态类型、State Backend 选择、Checkpoint 原理及配置、以及 Savepoint 的生产实践。  本文系统讲解 Apache Flink 的事件驱动编程模型,涵盖 ProcessFunction、定时器与状态、事件时间与 Watermark、与窗口的对比以及最佳实践。
本文系统讲解 Apache Flink 的事件驱动编程模型,涵盖 ProcessFunction、定时器与状态、事件时间与 Watermark、与窗口的对比以及最佳实践。  浙公网安备 33010602011771号
浙公网安备 33010602011771号