Redis学习-分布式锁
在高并发环境下,我们往往会对同一个数据进行操作,比如说商品的库存数据。如果有多个线程都要来对库存数据进行操作,那势必会造成线程的安全性问题,如何来解决这个问题就是我们今天要介绍的。
一、线程锁
根据上面的问题,我们可以立刻想到一种解决方案,那就是在给线程加锁。

上图是我们最常见的一种对线程加锁的方式,方式很简单只需要在对库存数据操作的过程中,加上锁就行,我们来看这段加锁的代码:
/** * 操作商品的数量 * * @param goods 商品名称 * @param number 要购买的数量 * @return */ public String findStock(String goods,Integer number) { //对同样的商品加锁 synchronized (goods){ //先找到原来的数量 Integer shopNumber=shop.getNumber(); //如果不够直接返回 if (shopNumber< number){ return "商品库存不够"; } //如果够则扣除库存,并返回 shop.setNumber(shopNumber-number); } return "商品购买成功"; }
可以看到上图是直接对同一商品进行了加锁,那么当第一个线程获取了锁,第二个就无法再次进入。
这种模式在单机情况是可行的,但是在我们的分布式业务中,不同的项目是在不同的服务器上运行,即使同一服务器,也是在多个JVM上面运行。而这里提供的方式是线程锁,它的使用条件是在同一进程中使用,因此在分布式系统中,这种方式显然是行不通的,这就需要一种新的方法来解决-分布式锁。
二、分布式锁
分布式锁是指:在应用场景是在分布式或集群环境下,多个服务(每个服务可以看做是一个进程)处理同一的数据,防止多进程处理数据时出现的进程间安全问题的锁。
一般来说在java应用中,分布式锁的的解决方案就是redis
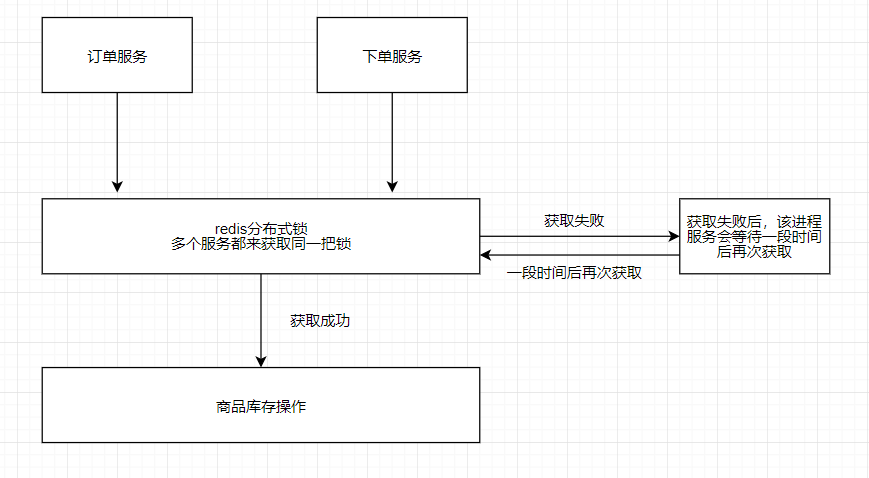
可以看到,分布式锁的实现和线程锁的实现几乎是一致的,最大的区别在于,进程获取锁失败后,不能像线程那样当锁释放后能够及时进行操作。
分布式锁的使用逻辑:
/** * 分布式事务锁的设计 * @param goods 商品名称 * @param number 要购买的数量 * @return */ public String findStockByRedis(String goods,Integer number) throws InterruptedException { //如果锁获取失败,那证明其他服务正在使用 while (!lock(goods)) { //获取失败时,我们直接等待一段时间 //每5秒一次,再去获取锁 TimeUnit.SECONDS.sleep(5); } //获取成功后,操作商品的数量 String str= findStock(goods,number); //操作完成后,记得解锁 unlock(goods); return str; }
我们重点来看两个锁的方法:
在Redis中,实现锁的方法就是setnx命令 ,这个命令的作用是:命令在指定的 key 不存在时,为 key 设置指定的值。
因此如果当一个客户端设置了key后,其他客户端就不能在去生成,这样就能够实现一个锁。
lock方法:
/** * 获取锁 * @param goods * @return */ public Boolean lock(String goods){ Boolean lockStatic= redisTemplate.opsForValue().setIfAbsent(goods,"lock",30,TimeUnit.SECONDS); if (lockStatic == null) { lockStatic=false; } return lockStatic; }
可以看到我们添加了一个商品的key,如果有一个用户在操作这个商品,其他用户来操作都是失败的。
其次还必须给key加上过期时间,这样做主要是防止该服务意外宕机时,不会一直占用锁。
unlock解锁方法:
解锁方法非常简单,只需要删除这个key就可以实现解锁功能。
public Boolean unlock(String goods){ return redisTemplate.delete(goods); }
分布式锁的总结:
上述的方法其实还有许多问题:
第一点,在进程中如果获取锁失败后,会一直尝试获取锁,这就类似于一个自旋锁的状态。我们知道自旋锁都是非常损耗性能的,因此那一部分还能进行优化处理。
第二点,其实我们讨论的都是在单机redis情况下的解决方案,如果是在redis集群环境下的话,这个方案显然是不行的。解决redis集群环境下的分布式锁,可以使用redisson框架。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号