kafka学习--第一章 kafka的基本架构与角色
一、kafka的基础架构
kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
kafka的具体架构如图:
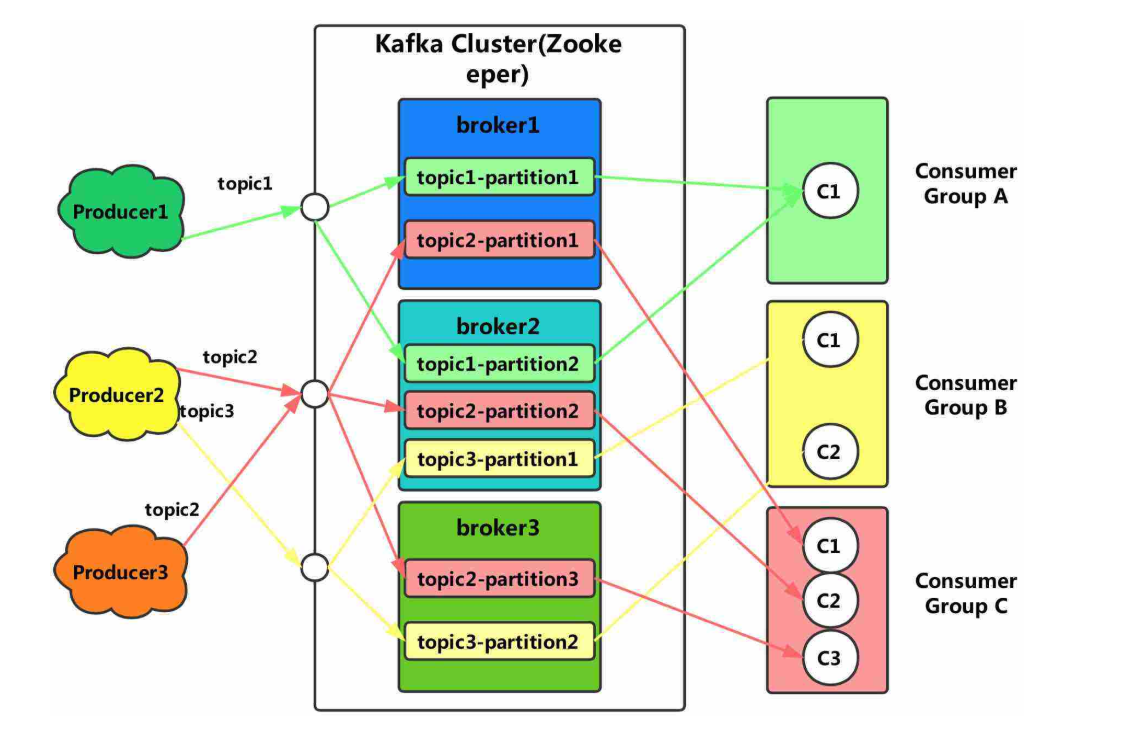
学习kafka的架构前,我们需要了解图中的每个角色:
(1)consumer group 消费者组:这是kafka消息队列特有的角色,它是一堆消费组组合成的。消费者组中的每个消费者负责消费不同分区的数据,一个分区只能一个消费者消费,它们互不影响。
(2)broker:一台kafka服务器就是一个broker,一个broker可以有多个topic。
(3)topic:可以看做是一个队列。
(4)partition:为了实现扩展性,一个非常大的topic可以有分成多个partition,它们可以分布在多个broker上。
了解完角色后,我们就可以来分析它的架构图了:
(1)kafka为了方便扩展和提高吞吐量,引入了一个partition角色,实际上就是为了对一个大队列进行分区操作。
(2)同样的,在为了配合kafka中的分区设计,也给了消费者端提供了一个消费者组的概念,组内的每个消费者并行消费信息。
(3)为了提供可用性,kafka给每个分区partition增加了若干个副本,这些副本采用了leader与flower的机制进行工作。
二、kafka生产者以及队列topic
1.partition分区的原则
在kafka提供的API中,生存者发送消息时需要传递三个参数:
(1)String value 要发送的消息。
(2)String key kafka自定义的分区。
(3)Integer partition 用户指定的分区。
kafaka的分区原则就和这三个参数有关,大致如下:
(1)如果传递时指定了partition的值,那么kafka会往指定的分区发送数据。
(2)如果没有指定partition的值,但是传递了key,kafka会自动生成一个partition值,它是将key的hash值与topic的partition值进行取余,得到的值就是kafka生成的partition的值。
(3)如果partition和key都没有进行传递,kafka则会随机生成一个key,是一个整数,以后每次生成都是在这个整数上加一。
2.数据的可靠性
kafka是一个非常强大的消息队列,它能够保存数据的可靠性。简单的来说它能够保证不会丢数据。那么它是如何完成的呢,如图:
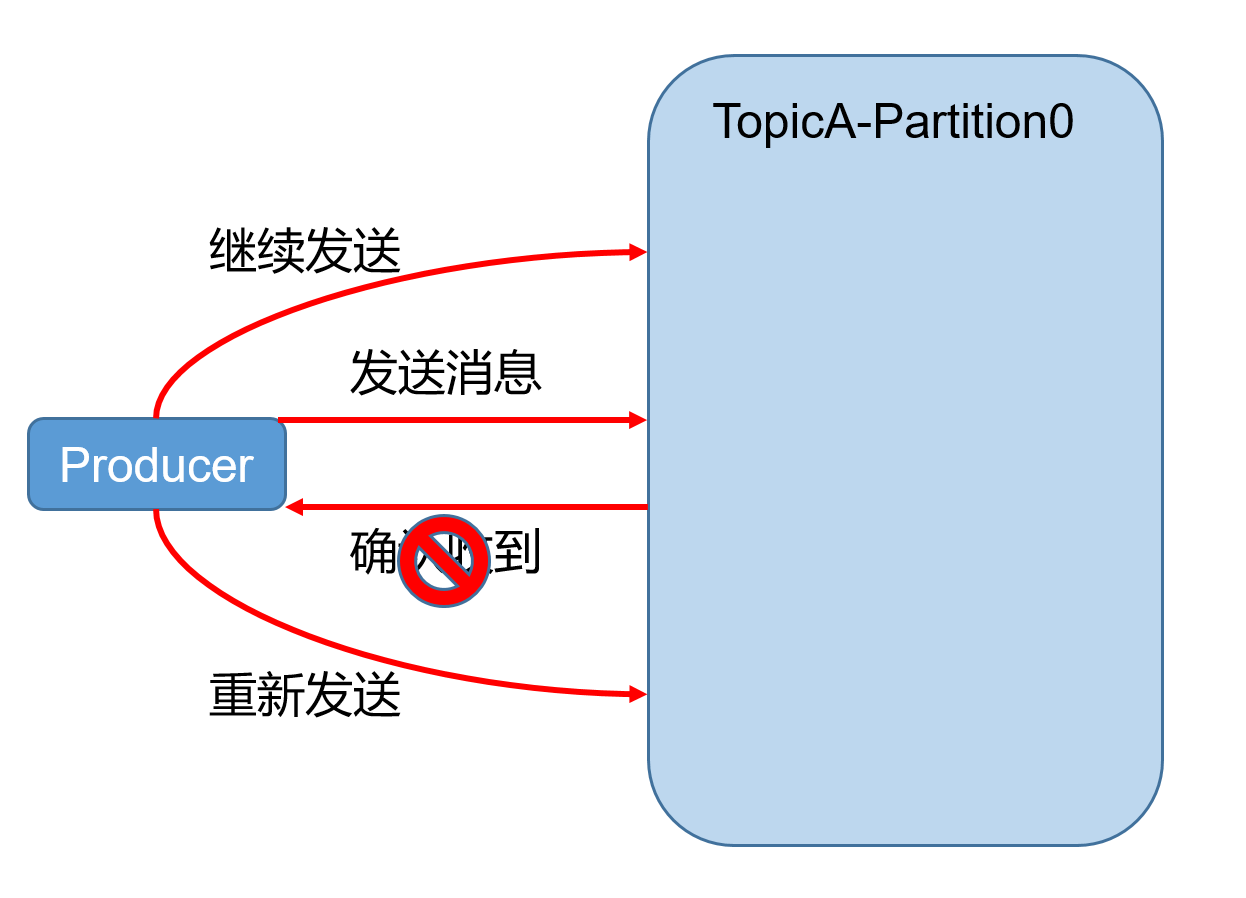
在生产者端可以看到,kafka是有一个失败重试的机制,当消息发送失败时会再次尝试发送,那么生产者是如何判定消息发送失败了呢。
为了实现数据的可靠性,kafka引入了一个对象:ack。生产者发送消息后,会收到kafka发送的这个ack对象,如果在一定时间后生产者还没有收到ack,那么生产者会尝试再次发送消息。
对于ack还有一个问题,就是在什么时候发送ack给生产者。因为我们在前面介绍了,kafka中每个partition是有个多个副本的,这些副本的leader接收数据,follwer则进行同步数据,因此ack是在同步完成后发送ack,还是leader接收后进行发送ack呢。
在kafka中采用的是所有的follwer都同步完成后再发送ack,这样虽然会照成网络的延迟,但是网络延迟对于kafka来说影响较小。
3.副本的集合ISR
ISR是和leader保持同步的follwer集合。当ISR中所有follwer同步完成后,leader给生产者ack。如果有那个follwer长时间没有进行数据同步,那么ISR会踢掉这个follwer。
三、消费者
1.kafka的消费方式
kafka采用的是pull(拉)模式进行消费数据,也就是消费者能读取多少数据则拉多少数据进行消费。但是pull模式有一个缺点:如果队列中没有数据,消费者会一直去拉取数据。为了解决这个问题,kafka设置了空数据检测机制。
2.分区分配策略
在kafka中发送的消息指定的不是单个消费者,而是整个消费者组,因此每个消费者消费的分区也是有规则的:
a.轮询规则 roundrobin
轮询分配的方式非常简单,将每个分区通过轮询的方式分配给消费者
b.范围规则 range
指定消费者消费指定范围的分区。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号