Netty学习第三章 Linux网络编程使用的I/O模型
一、同步阻塞IO:blocking IO(BIO)
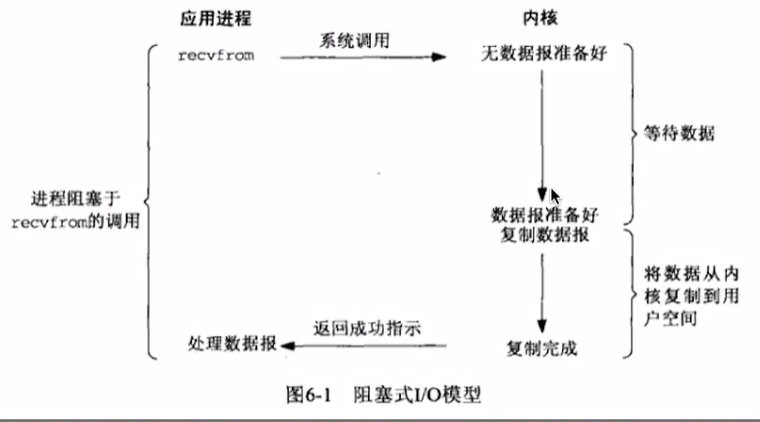
1.过程分析:
当进程进行系统调用时,内核就会去准备数据,当数据准备好后就复制数据到内核缓冲器,复制完成后将数据拷贝到用户进程内存,整个过程都是阻塞的。
2.特点:
优点:能及时响应数据
缺点:因为整个过程都是阻塞的,所以高并发下性能非常差
二、同步非阻塞IO:nonblocking IO(NIO)
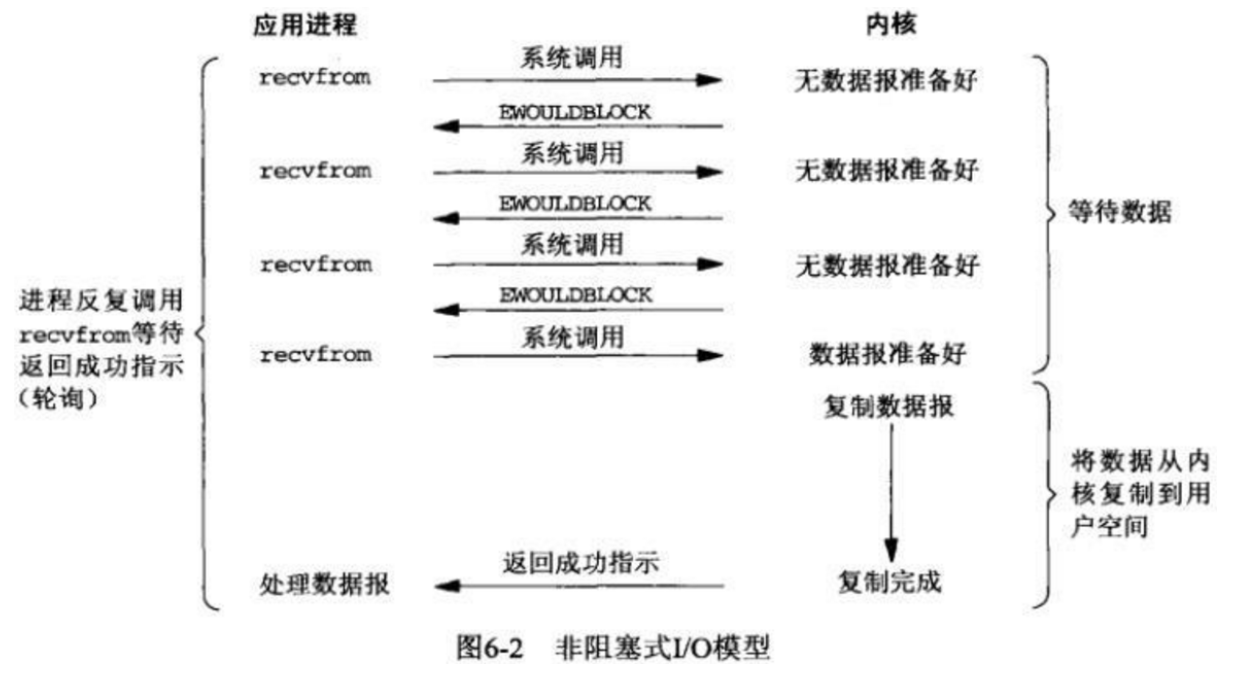
1.过程分析:
当进程调用系统时,会立即返回error,当用户知道返回的是error后就知道数据没有准备好,此时进程进行等待,这一个过程是非阻塞的,因此可以有多个调用请求。当请求来到时,内核会去准备数据,就和BIO的模式一样,当数据准备好后,复制给用户进程内存,这一个过程是阻塞的,但是用户进程会一直去轮询判断数据是否已经准备好了。
2.特点:
优点:能够在数据处理好之前去做其他的事情
缺点:性能还是很差,第一需要不断去判断数据是否准备好了;第二在拷贝数据这个过程中,进程依旧是阻塞的;第三因为是轮询去找数据,所以数据会有延迟
三、IO多路复用
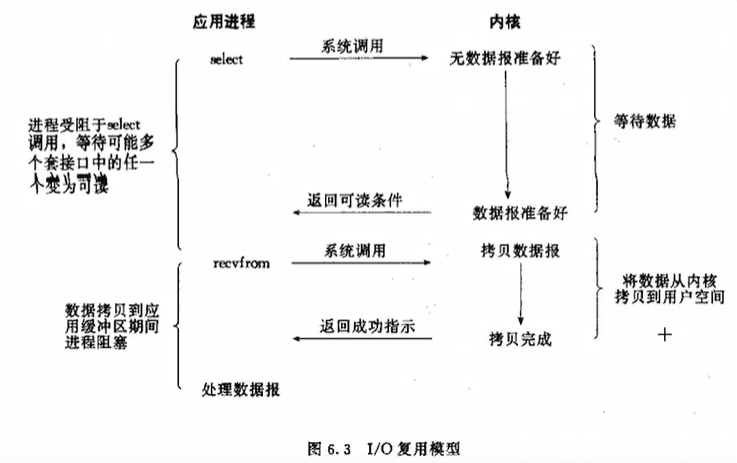
1.定义:
所谓的IO多路复用指的就是一个或多个线程处理多个TCP连接。
2.网络模型:
IO多路复用的网络模型有三种:
①select模型:
调用select函数时会阻塞住进程,等有数据可读、可写、出异常或者超时就会返回。select函数正常返回后,通过遍历fdset整个数组才能发现那些句柄发生了事件,来找到就绪的fd进行相应的IO操作。
优点:所有平台都能够使用这种模型。
缺点:
⑴ select函数采用轮询的方式扫描文件,如果fd多的话,性能就会很差。
⑵ 每次调用select函数,需要把fd集合从用户拷贝到内核中
⑶ 最大缺陷是单个进程打开的fd有限制的(1G的内存大概有10万个句柄)
②poll模型:
这个模型和select模型一样,最大的区别就是poll没有最大文件描述符(fd)的限制
③epoll模型
这个模型是在Linux2.6内核中正式加入的:对比select模型,epoll没有描述符限制,用户拷贝到内核的数据只需使用一次事件通知,通过epoll_ctl函数注册fd,一旦fd就绪,内核就会采用callback的回调机制来激活对应的fd。
我们主要了解下它的工作函数:
epoll_create:这个函数是用来创建一个epoll句柄,创建完成后epoll就会占用一个fd,这个函数返回的是一个epoll对象
epoll_ctl:在epoll对象里添加删除对应的fd,并绑定一个callback函数
epoll_wait:判断并成对应的IO操作
epoll模型的特点:
⑴ 没有fd限制
⑵ 效率高,因为使用的是回调通知机制,不会随着fd的增加而降低性能
⑶ 用户和内核采用同一块内存实现回调
四、信号驱动
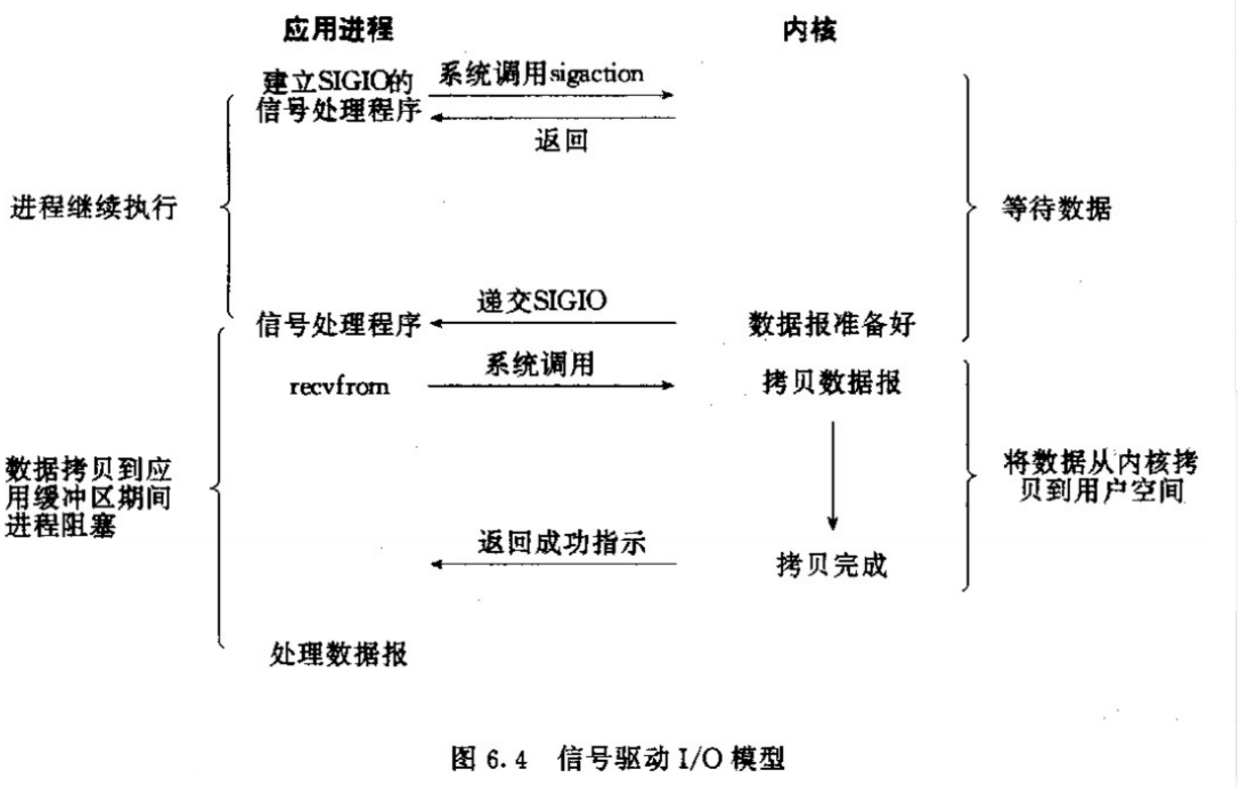
1.过程分析:
这种模型与NIO类似,在第一个阶段进程发起请求时两个模型都是一样的,是非阻塞的,区别在于第二阶段:在信号驱动模型中,当内核准备好数据后会自动通知用户进程,进程收到通知后会自动去内核拷贝数据。
五、异步IO:asynchronous IO(AIO)
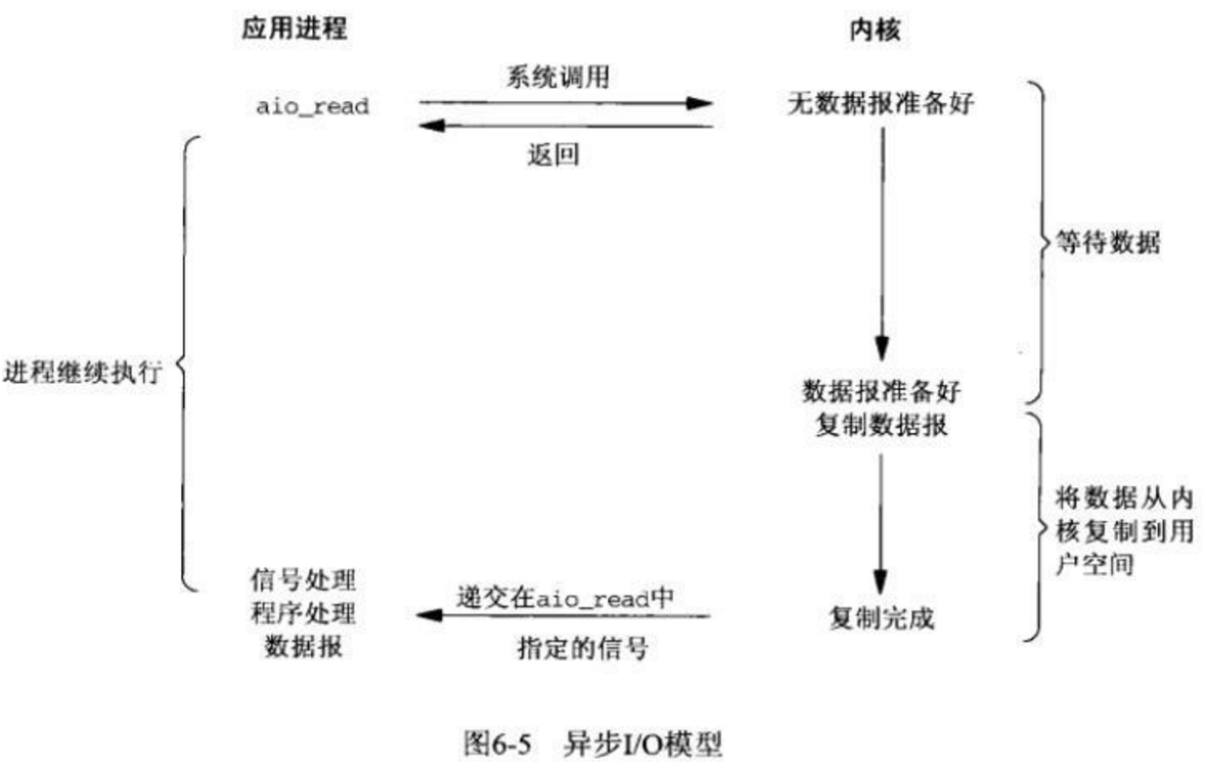
1.过程分析:
用户进程在系统调用后,就能够去继续做其他的事情,数据的第一、第二阶段都不是阻塞的,当数据准备好后。内核会自动通知用户来拷贝数据。
2.特点:
读写操作都交给了内存来处理,用户只需要等待通知来获取就行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号