

论文笔记《Spatial Memory for Context Reasoning in Object Detection》
好久不写论文笔记了,不是没看,而是很少看到好的或者说值得记的了,今天被xinlei这篇paper炸了出来,这篇被据老大说xinlei自称idea of the year,所以看的时候还是很认真的,然后最后确实也发现了不少干货。
一、introduction
这篇文章主要还是解决detection中如何有效的利用context信息的问题,这里作者提出了有两种context信息:1、image-level的信息,也就是当前场景的信息,例如一张床出现在卧室里面,一个篮球出现在篮球场里面,都是极其合理的 2、obeject-object relationship,例如一个人手上拿着一个球,比一个人手上拿着一辆车还是要合理很多很多的。。
首先传统的faster rcnn的pipeline中几乎没有利用过任何的context信息,作者提出特别实在NMS的时候,暴力去除掉那些候选框并不是一个好主意,因此提出来spatial memory network来解决这个问题。这个方法的核心就是,当你在图片中检测到车,记住它,然后在下次迭代的时候作为先验知识会帮助下一次的检测得到一些之前漏检的结果。
二、insight&&contribution
具体的内容其实还是要看paper,文章太长了然后mac截图好麻烦,记几点关键的吧。
1.首先将在图片中的检测物体的行为model成一个公式

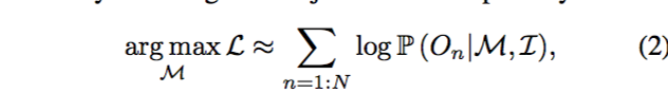

这些推导当然都是合理的,不过其实一般DL的论文,怎么解释都有道理。。
2.下图式整个算法的pipeline,灰色的是原来的faster rcnn的步骤,只不过把conv5的feature换成了m_conv5的feature,并且在每次迭代的时候,通过memory S得到更好的detection结果,然后再根据新的结果更新S,如此迭代优化。
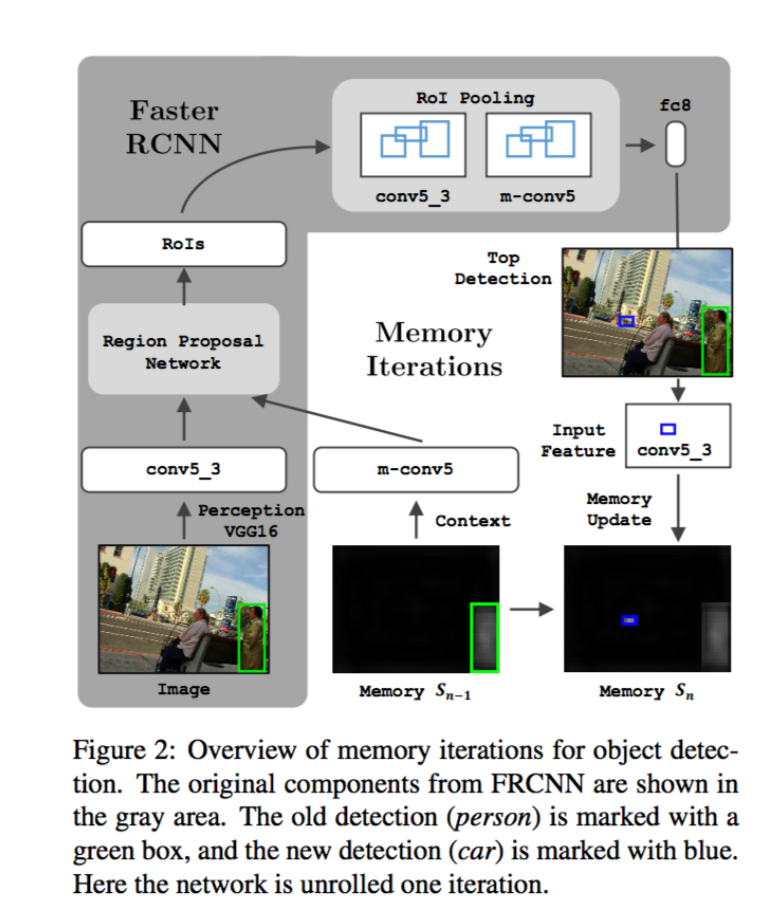
这里为决定memory S的选择也是比较合理的,如下图所示:

细节就不说了,主要是融合了conv5_3的feature以及softmax的的score,前者具有spatial的fearure,后者更多的是semantic的信息。
3.最后一个比较合理的地方就是训练的一个关键了,很多时候你有一个很好的idea,最后的结果不好,未必是你的idea不好,而是有些地方没有处理好。
如下图所示,一开始训练的时候并不收敛,作者经过实验和推导发现了问题所在,那就是memory和detection的在bp的时候是有contract的,我们希望第一次之后的迭代是不会检测到前面的物体的,所以网络会不停的接受矛盾的signal,一个希望它尽量检测一切物体,一个希望不要检测太多,这样的矛盾是的detecor的更新是不合理的,所以最后作者发现,第一次没有memory的时候更新detector M,后面的迭代就不BP了。

三、conclusion
让我最喜欢的是两点,一个是context信息的object-obejct的阐述,还有一个是训练的时候bp的细节,到了这个份上,这个工作到底work不work对于我来说已经不是关键了。。。。
