为什么要归一化?
为什么要归一化?
BN是Batch Normalization的缩写,该方法的代表性论文是“Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”,论文中关于BN的解释是训练深度神经网络非常复杂,因为在训练过程中,随着先前各层的参数发生变化,各层输入的分布也会发生变化,图层输入分布的变化带来了一个问题,因为图层需要不断适应新的分布,因此训练变得复杂,随着网络变得更深,网络参数的细微变化也会放大。
由于要求较低的学习率和仔细的参数初始化,这减慢了训练速度,并且众所周知,训练具有饱和非线性的模型非常困难。我们将此现象称为内部协变量偏移,并通过归一化层输入来解决该问题。
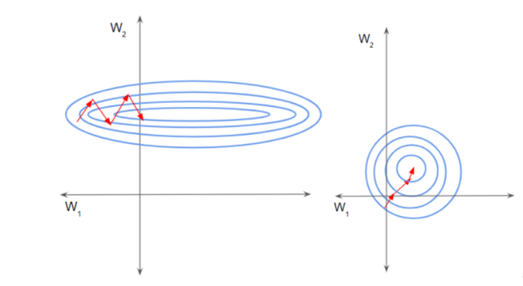
如上图中的左图所示,由于两个数据不在同一范围,但它们是使用相同的学习率,导致梯度下降轨迹沿一维来回振荡,从而需要更多的步骤才能达到最小值。且此时学习率不容易设置,学习率过大则对于范围小的数据来说来回震荡,学习率过小则对范围大的数据来说基本没什么变化。如上图中的右图所示,当进行归一化后,特征都在同一个大小范围,则loss landscape像一个碗,学习率更容易设置,且梯度下降比较平稳。
我的理解就是看图,防止不同维度的尺度不一致,在梯度下降的时候被尺度大的维度主导。
heroes never die!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号