06-K8S Basic-Pod资源管理进阶(Pod声明周期、相位、资源限制)
一、Pod资源生命周期(健康状态检查)
1.1、pod生命周期的介绍
Pod的生命周期涵盖了前面所说的PostStart 和 PreStop在内
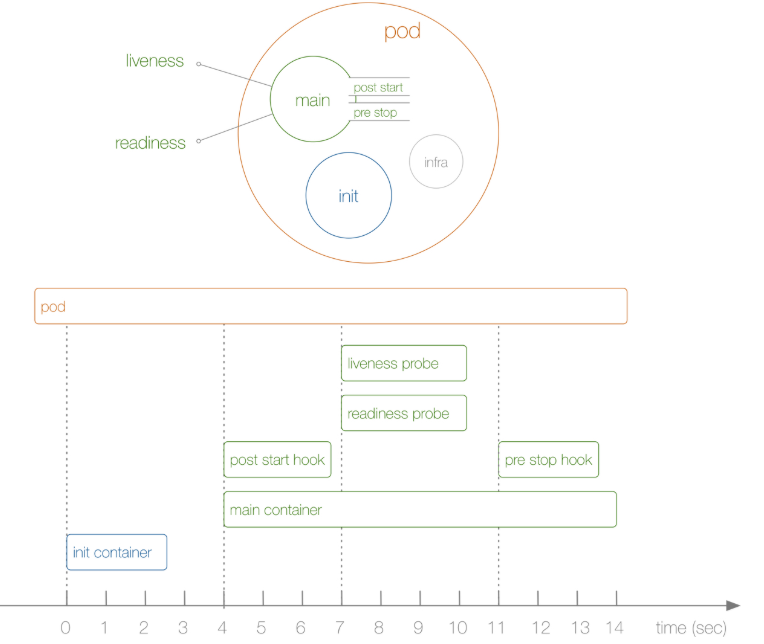
Pod生命周期中的重要阶段
- 初始化容器
- 生命周钩子函数
- postStart
- preStop
- 容器探测
- 探测类型
- 存活状态探测 :liveness probe
- 就绪状态探测 : readiness probe
- 探测行为
- ExecAction
- TCPSocketAction
- HTTPGetAction
- 探测类型
1.1.1、Pod phase
- Pod的status定义在 PodStatus对象中,其中有一个phase字段。
- Pod的运行阶段是Pod在其生命周期中的简单宏观概述。
- 下面是phase可能的值:
Pending 挂起:该状态标识Pod没有调度到节点上,可能下载镜像耗费时间,容器还未启动。Running 运行中: Pod已经绑定到一个节点上,Pod中的容器已经全部创建,至少有一个容器正在运行,或者证处于启动状态或重启状态。Succeeded 成功: Pod中所有的容器都被成功终止,并且不会被重启。Failed 失败:Pod中的所有容器都已经终止了,并且至少有一个容器是因为失败终止。容器退出状态非0或被系统终止。Unknown 未知: 因为某些原因无法取得Pod状态,通常因为与Pod所在节点失去通信造成失联。
1.1.2、Pod 状态
- Pod 有一个 PodStatus 对象,其中包含一个 PodCondition 数组。 PodCondition 数组的每个元素都有一个 type 字段和一个 status 字段。type 字段是字符串,可能的值有 PodScheduled、Ready、Initialized 和 Unschedulable。status 字段是一个字符串,可能的值有 True、False 和 Unknown。
1.1.3、Pod健康检查
- 查看官网文档,探针是有kubelet对容器状态的一种定期监控和检查,要执行诊断,kubelet可以调用由容器实现的Handler。有三种执行方式:
HTTPGetAction(http):对指定端口和路径上的容器的IP地址执行HTTP Get请求。如果状态码大于等于200且小于400,则认为诊断成功。ExecAction(exec): 在容器内部执行指定命令,执行后退出状态码为0则诊断成功。TCPSocketAction(tcp:): kubelet 对指定容器IP和Port进行TCP检查,如果端口打开,则被认为诊断成功
- 诊断状态有三种:
- 成功: 容器状态健康,通过了检测
- 失败: 容器未通过诊断
- 未知: 诊断失败,不会采取任何行动
1.1.3.1、容器探针
- 供kubelet对容器诊断的探针有两种:
LivenessProbe: 存活探针,指容器是否正在运行。如果检测失败,则kubelet会杀死容器,并且容器会受重启策略的影响而是否重启, 如果容器不提供探针,则默认状态为success。ReadnessProbe: 就绪探针,指容器是否准备就绪,接受服务请求。如果就绪探针失败,端点控制器将从与Pod匹配的所有service的端点中移除该Pod的IP 地址。初始延迟之前的就绪状态默认是Failure,如果容器不提供就绪探针,则默认状态为Success。
1.1.3.2、什么时候选择livenessProbe 存活探针和readnessProbe就绪探针?
- 如果容器中的进程能够在出现服务故障的时候自动崩溃,那么这种时候是不需要提供livenessProbe ,kubelet将根据Pod的restartPolicy自动执行正确的操作
- 如果希望容器在探测失败时被杀死并重新启动,那么请指定一个livenessPRobe存活探针,并指定restartPolicy为Always或OnFailure。
- 如果要在探测成功才开始向Pod发送流量,就需要指定一个readnessProbe 。在这种情况下,就绪探针可能和存活探针同时存在,这种情况下的readnessProbe意味容器在没有接受到任何 流量的情况下启动,并且只有在探针成功后才接收流量。如果希望容器能够自行维护,那就指定一个readnessProbe探针,和livenessProbe探测不同的端点。
- 注意,如果只想在pod被删除时能够排除请求,则不一定需要使用就绪探针;在删除Pod时,Pod将自动将自身置于未完成状态,无论是否有就绪探针。当等待Pod中的容器停止时,Pod仍处于未完成状态。
1.1.3.3、模板 使用exec方式指定command
apiVersion: v1
kind: Pod
metadata:
name: probe
spec:
containers:
- name: probe
image: busybox
argx:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5 #等待容器启动5秒后发起探针
periodSeconds: 5 #发起探针的间隔5秒一次
- 使用kubectl 部署这个yaml文件,创建一个Pod,可以发现在启动完成后等待5秒后开始发起探针诊断,每隔5秒后发起一次诊断,而这里使用的是exec方式,在30秒后容器会执行删除/tmp/healthy 文件操作,这之后再发起探针诊断则诊断失败,容器将被kubelet 杀掉然后重启。
1.1.3.4、livenessProbe和readnessProbe一起使用
apiVersion: v1
kind: Pod
metadata:
name: probe-http
label:
app: probe-http
sepc:
containers:
- name: probe-http
image: nginx
containerPort:
- name: http
port: 80
livenessProbe:
# 当没有定义 "host" 时,使用 "PodIP"
# host: my-host
# 当没有定义 "scheme" 时,使用 "HTTP" scheme 只允许 "HTTP" 和 "HTTPS"
# scheme: HTTPS
path: / #路径可以是想要检查的能访问到的任何路径,如:/healthy
port: 80
# httpHeaders: 设置http请求头
# - name: X-Custom-Header
# value: Awesome
initialDelaySeconds: 15
timeoutSeconds: 1 #超时时间
readnessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 20
- 从上面的YAML文件我们可以看出readiness probe的配置跟liveness probe很像,基本上一致的。唯一的不同是使用readinessProbe而不是livenessProbe。两者如果同时使用的话就可以确保流量不会到达还未准备好的容器,准备好过后,如果应用程序出现了错误,则会重新启动容器。
1.1.3.6、探针参数
- timeoutSeconds:探测超时时间,默认1秒,最小1秒。
- successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是 1,但是如果是
liveness则必须是 1。最小值是 1。 - failureThreshold:探测成功后,最少连续探测失败多少次才被认定为失败。默认是 3,最小值是 1。
1.1.3.7、重启策略
- dSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为 Always。 restartPolicy 适用于 Pod 中的所有容器。restartPolicy 仅指通过同一节点上的 kubelet 重新启动容器。失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒…)重新启动,并在成功执行十分钟后重置。如 Pod 文档 中所述,一旦绑定到一个节点,Pod 将永远不会重新绑定到另一个节点。
tartPolicy:- ways 容器失效时,kubelet 自动重启该容器
- Failure 容器终止运行且退出码不为0时重启
- ver 不论状态为何, kubelet 都不重启该容器
1.1.4.Pod 的生命
- 来说,Pod 不会消失,直到人为销毁他们。这可能是一个人或控制器。这个规则的唯一例外是成功或失败的 phase 超过一段时间(由 master 确定)的Pod将过期并被自动销毁。
- 种可用的控制器:
- Job 运行预期会终止的 Pod,例如批量计算。Job 仅适用于重启策略为 OnFailure 或 Never 的 Pod。
- 期不会终止的 Pod 使用 ReplicationController、ReplicaSet 和 Deployment ,例如 Web 服务器。 ReplicationController 仅适用于具有 restartPolicy 为 Always 的 Pod。
- 特定于机器的系统服务,使用 DaemonSet 为每台机器运行一个 Pod 。
- 这三种类型的控制器都包含一个 PodTemplate。建议创建适当的控制器,让它们来创建 Pod,而不是直接自己创建 Pod。这是因为单独的 Pod 在机器故障的情况下没有办法自动复原,而控制器却可以。
- 节点死亡或与集群的其余部分断开连接,则 Kubernetes 将应用一个策略将丢失节点上的所有 Pod 的 phase 设置为 Failed
二、Pod生命周期实战
-
livenessProbe和readnessProbe:一般支持的命令都是三种exec执行命令来做健康状态检测且此命令一定时容器内部支持的命令httpGet如果资源为web服务,也可以直接服务请求一个资源,如果请求成功为成功,无响应则为不健康tcpSocket探测服务监听的某个端口,发起请求,根据响应判断健康与否failureThreshold(错误阈值)探测的多少次没有响应才视为服务出现问题,默认为三次successThreshold(成功阈值) 探测连续成功多少次才视为成功,默认值为1,成功探测一次则视为成功,不可修改periodSeconds(检查周期)每次探测的时间间隔,默认为10s,最低值为1sinitialDelaySeconds资源初始化多久以后在进行探测检查,如果不定义默认为启动资源则开始执行探测timeoutSeconds(探测的超时时间间隔)每次检查资源未响应等待时间,比如请求发出一直等待响应的时间,默认1s
-
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动。
2.1、livenessProbe 存活探针
2.1.1、查看livenessProbe 存活探针帮助
1、克隆马哥的书看示例
~]# git clone https://github.com/iKubernetes/Kubernetes_Advanced_Practical.git
~]# cd Kubernetes_Advanced_Practical/chapter4/
chapter4]# ls
lifecycle-demo-pod.yaml memleak-pod.yaml pod-example-update.yaml pod-with-nodeselector.yaml stress-pod.yaml
liveness-exec.yaml namespace-example.yaml pod-use-hostnetwork.yaml pod-with-seccontext.yaml
liveness-http.yaml pod-alpine.yaml pod-with-labels.yaml readiness-exec.yaml
2、参考官方命令文档
# kubectl explain pods.spec.containers.livenessProbe
KIND: Pod
VERSION: v1
RESOURCE: livenessProbe <Object>
exec command 的方式探测 例如 ps 一个进程
failureThreshold 探测几次失败 才算失败 默认是连续三次
periodSeconds 每次的多长时间探测一次 默认10s
timeoutSeconds 探测超市的秒数 默认1s
initialDelaySeconds 初始化延迟探测,第一次探测的时候,因为主程序未必启动完成
tcpSocket 检测端口的探测
httpGet http请求探测
2.1.2、livenessProbe 实战示例
2.1.2.1、exec示例(执行命令来做健康状态检测且此命令一定时容器内部支持的命令)
示例一:
# 自主式pods
1、定义pod资源并指定存活探针
chapter4]# cat liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
#pod标签
labels:
test: liveness-exec
#pod名称
name: liveness-exec
spec:
containers:
#容器的名称
- name: liveness-demo
#该容器使用的镜像运行
image: busybox
#容器内部运行的命令如下
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 20; rm -rf /tmp/healthy; sleep 600
#存活探针-状态检测
livenessProbe:
#探测执行下面命令,探测容器中的/tmp/healthy文件是否存在,如果存在则视为健康
exec:
command:
- test
- -e
- /tmp/healthy
2、创建pod资源
chapter4]# kubectl apply -f liveness-exec.yaml
3、使用-w选项实时监控pod运行
chapter4]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 0 19s
4、使用describe查看pods详细信息
chapter4]# kubectl describe pods liveness-exec
Name: liveness-exec
Namespace: default
Priority: 0
Node: 192.168.1.51/192.168.1.51
Start Time: Wed, 19 Feb 2020 22:23:03 +0800
Labels: test=liveness-exec #容器标签
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"test":"liveness-exec"},"name":"liveness-exec","namespace":"default...
Status: Running #容器状态
IP: 192.168.1.125
IPs:
IP: 192.168.1.125
Containers:
liveness-demo:
Container ID: docker://2fc372b2707e4a474c0899f7b3fce6ecd2dd530d5b67ffc0f4774629837f251e
Image: busybox
Image ID: docker-pullable://busybox@sha256:6915be4043561d64e0ab0f8f098dc2ac48e077fe23f488ac24b665166898115a
Port: <none>
Host Port: <none>
Args: #容器内部运行的命令
/bin/sh
-c
touch /tmp/healthy; sleep 20; rm -rf /tmp/healthy; sleep 600
State: Running
Started: Wed, 19 Feb 2020 22:24:25 +0800
Last State: Terminated
Reason: Error
Exit Code: 137
Started: Wed, 19 Feb 2020 22:23:08 +0800
Finished: Wed, 19 Feb 2020 22:24:21 +0800
Ready: True
Restart Count: 1 #容器重新启动的次数
Liveness: exec [test -e /tmp/healthy] delay=0s timeout=1s period=10s #success=1 #failure=3
#delay=0s:表示延迟检测,0s表示容器启动立即进行状态检测
#timeout=1s 命中的超时时间为1s
#period=10s 检查周期为10s
#success=1 成功一次认为成功
#failure=3 失败三次认为失败
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-25w8t (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
chapter4]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 4 6m43s #容器重启的次数
2.1.2.2、httpGet 示例(如果资源为web服务,也可以直接服务请求一个资源,如果请求成功为成功,无响应则为不健康)
1、定义pod资源并指定存活探针
chapter4]# cat liveness-http.yaml
apiVersion: v1
kind: Pod
metadata:
#pod标签信息
labels:
test: liveness
#pod资源名称
name: liveness-http
spec:
containers:
- name: liveness-demo
#容器运行的镜像
image: nginx:1.14-alpine
#容器端口暴漏
ports:
#容器端口别名
- name: http
#暴漏80端口
containerPort: 80
#lifecycle定义容器启动前和启动后事件
lifecycle:
#定义容器启动后事件
postStart:
#容器启动后执行的命令
exec:
command:
- /bin/sh
- -c
- 'echo Healty > /usr/share/nginx/html/healthz'
#存活探针
livenessProbe:
#httpd get资源请求
httpGet:
#可以使用host,指定ip,请求次ip的资源,如果不指定默认为pod的ip
path: /healthz
port: http # 这里直接调用上面定义的spec中的ports中-name别名,如果没有在前面定义别名仅能使用端口号,例如此例子的80
scheme: HTTP #协议 HTTP / HTTPS
#定义探针延迟间隔
periodSeconds: 2
#错误失败次数
failureThreshold: 2
#容器运行完成延时事件再做探针
initialDelaySeconds: 3
2、声明式创建pod资源
chapter4]# kubectl apply -f liveness-http.yaml
pod/liveness-http created
3、使用-w选项实时监控pod运行
chapter4]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
liveness-exec 0/1 CrashLoopBackOff 9 25m
liveness-http 1/1 Running 0 43s
4、使用describe查看pods详细信息
chapter4]kubectl describe pods liveness-http
Name: liveness-http
Namespace: default
Priority: 0
Node: 192.168.1.51/192.168.1.51
Start Time: Wed, 19 Feb 2020 22:47:26 +0800
Labels: test=liveness
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"test":"liveness"},"name":"liveness-http","namespace":"default"},"s...
Status: Running
IP: 192.168.1.74
IPs:
IP: 192.168.1.74
Containers:
liveness-demo:
Container ID: docker://8663fe18daf2eb48134a5ffdf8e434a3bfce2caf7f2b217b51d14339ea9c61a5
Image: nginx:1.14-alpine
Image ID: docker-pullable://nginx@sha256:485b610fefec7ff6c463ced9623314a04ed67e3945b9c08d7e53a47f6d108dc7
Port: 80/TCP
Host Port: 0/TCP
State: Running # 当前pod运行状态
Started: Wed, 19 Feb 2020 22:47:27 +0800
Ready: True
Restart Count: 0
Liveness: http-get http://:http/healthz delay=3s timeout=1s period=2s #success=1 #failure=2 # 存活探针
# 存活探针,使用http-get,向本机的localhost发起请求:端口别名,这里为80端口
#delay=3s 表示延迟检测,3s表示容器启动3秒后进行状态检测
#timeout=1s 命中的超时时间为1s
#period=2s 检查周期为2s
#success=1 成功一次认为成功
#failure=2 失败2次认为失败
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-25w8t (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
5、连入容器中删除健康状态网页文件并查看状态是否重启
chapter4]# kubectl exec -it liveness-http -- /bin/sh
/ # rm -rf /usr/share/nginx/html/
50x.html healthz index.html
/ # rm -rf /usr/share/nginx/html/healthz
/ # command terminated with exit code 137
chapter4]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 11 28m
liveness-http 1/1 Running 1 4m27s
chapter4]# kubectl exec -it liveness-http -- /bin/sh
/ # ls /usr/share/nginx/html/healthz
/usr/share/nginx/html/healthz
6、可以查看pods上一次运行状态
chapter4]# kubectl describe pods liveness-http
Name: liveness-http
Namespace: default
Priority: 0
Node: k8s.node2/192.168.20.214
Start Time: Sat, 02 May 2020 14:30:10 +0800
Labels: test=liveness
Annotations: Status: Running
IP: 10.244.2.7
IPs:
IP: 10.244.2.7
Containers:
liveness-demo:
Container ID: docker://2bd9de8cf5b3a5f94176f63119afe705adbd8af88d139f497fb94a51f0d626dd
Image: nginx:1.14-alpine
Image ID: docker-pullable://nginx@sha256:485b610fefec7ff6c463ced9623314a04ed67e3945b9c08d7e53a47f6d108dc7
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sat, 02 May 2020 14:40:51 +0800
Last State: Terminated # pods 上一次退出状态
Reason: Completed
Exit Code: 0
Started: Sat, 02 May 2020 14:30:11 +0800
Finished: Sat, 02 May 2020 14:40:51 +0800
Ready: True
Restart Count: 1
Liveness: http-get http://:http/healthz delay=3s timeout=1s period=2s #success=1 #failure=2
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-q97bf (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
2.1.2.3、tcpSocket示例(探测服务监听的某个端口,发起请求,根据响应判断健康与否)
# 资源清单文件,向Pod IP的80/tcp端口发起连接请求,并根据连接建立的状态判断Pod存活状态。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness-tcp
name: liveness-tcp
spec:
containers:
- name: liveness-tcp-demo
image: nginx:1.12-alpine
ports:
- name: http
containerPort: 80
livenessProbe:
tcpSocket:
port: http
2.2、readnessProbe就绪探针
readnessProbe就绪探针无权利重启容器,但是livenessProbe 存活探针是有权利重新启动容器的。readnessProbe就绪探针检测成功,前端service就可以使用的pod资源,如果探针为不健康状态则从service集群中移除
2.2.1、查看readnessProbe就绪探针帮助
- chapter4]# kubectl explain pods.spec.containers.readinessProbe
2.2.2、readnessProbe实战示例
2.2.2.1、exec示例
1、定义pod资源并指定存活探针
chapter4]# cat readiness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: readiness-exec
name: readiness-exec
spec:
containers:
#容器的名称
- name: readiness-demo
#运行此容器使用的镜像
image: busybox
#容器内部运行的命令
args: ["/bin/sh", "-c", "while true; do rm -f /tmp/ready; sleep 30; touch /tmp/ready; sleep 300; done"]
#readnessProbe就绪探针
readinessProbe:
#此探针指定的命令
exec:
command: ["test", "-e", "/tmp/ready"]
#容器运行后延迟检测时间
initialDelaySeconds: 5
#检查周期
periodSeconds: 5
2、声明式创建pod资源
chapter4]# kubectl apply -f readiness-exec.yaml
pod/readiness-exec created
3、使用-w选项实时监控pod运行
chapter4]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
readiness-exec 0/1 Running 0 22s
chapter4]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
readiness-exec 1/1 Running 0 41s
4、使用describe查看pods详细信息
chapter4]# kubectl describe pods readiness-exec
Name: readiness-exec
Namespace: default
Priority: 0
Node: 192.168.1.51/192.168.1.51
Start Time: Wed, 19 Feb 2020 23:10:05 +0800
Labels: test=readiness-exec
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"test":"readiness-exec"},"name":"readiness-exec","namespace":"defau...
Status: Running
IP: 192.168.1.7
IPs:
IP: 192.168.1.7
Containers:
readiness-demo:
Container ID: docker://a07b94cf7566bdb7b918e4c416398580e514ef82a63c02d5f4d74070ec68a96c
Image: busybox
Image ID: docker-pullable://busybox@sha256:6915be4043561d64e0ab0f8f098dc2ac48e077fe23f488ac24b665166898115a
Port: <none>
Host Port: <none>
Args:
/bin/sh
-c
while true; do rm -f /tmp/ready; sleep 30; touch /tmp/ready; sleep 300; done
State: Running
Started: Wed, 19 Feb 2020 23:10:12 +0800
Ready: True
Restart Count: 0
Readiness: exec [test -e /tmp/ready] delay=5s timeout=1s period=5s #success=1 #failure=3
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-25w8t (ro)
5、手动删除探针检测文件
chapter4]# kubectl exec readiness-exec -- rm -f /tmp/ready
# readnessProbe就绪探针无权利重启容器,如果探针为不健康状态则从service集群中移除,虽然此实例没有定义Server
chapter4]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
readiness-exec 0/1 Running 0 3m57s
6、手动创建探针文件
chapter4]# kubectl exec readiness-exec -- touch /tmp/ready
chapter4]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-exec 1/1 Running 0 4m57s
2.2.2.2、httpGet 示例
三、Pod对象的相位
3.1、Pod对象的相位介绍
- Pod对象总是应该处于其生命进程中以下几个相位(phase)之一
Pending- API Serber创建了Pod资源对象并已存入etcd中,但它尚未被调度完成,或仍处于从仓库中下载镜像的过程中
Running- Pod已经被调度至某节点,并且所有容器已经都被kubelet创建完成
Succeeded- Pod中的所有容器都已经成功终止并且不会被重启
Faild- 所有容器已经终止,但至少有一个容器终止失败,即容器返回了非0值得退出状态或已经被系统终止
UnKnown- API Server无法正常获取到Pod对象得状态信息,同城是有其无法与所有工作节点得kubelet通讯所致
3.2、Pod对象创建过程
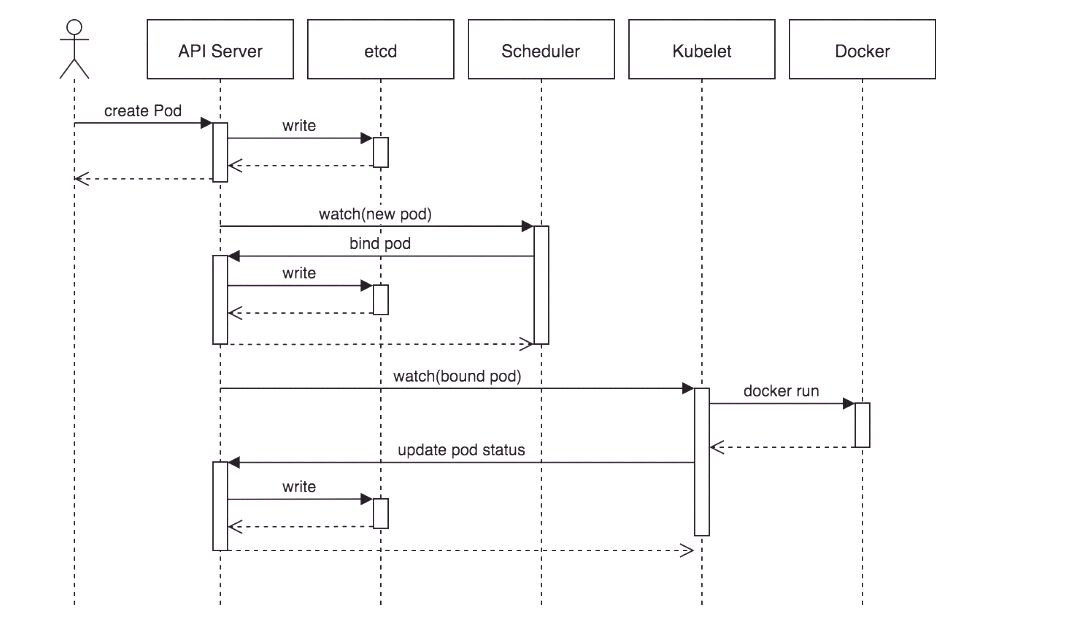
- 具体的创建步骤包括:
- 1、客户端提交创建请求,可以通过API Server的Restful API,也可以使用kubectl命令行工具。支持的数据类型包括JSON和YAML。
- 2、API Server处理用户请求,存储Pod数据到etcd。
- 3、调度器通过API Server查看未绑定的Pod。尝试为Pod分配主机。
- 4、过滤主机 (调度预选):调度器用一组规则过滤掉不符合要求的主机。比如Pod指定了所需要的资源量,那么可用资源比Pod需要的资源量少的主机会被过滤掉。
- 5、主机打分(调度优选):对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把容一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等。
- 6、选择主机:选择打分最高的主机,进行binding操作,结果存储到etcd中。
- 7、kubelet根据调度结果执行Pod创建操作: 绑定成功后,scheduler会调用APIServer的API在etcd中创建一个boundpod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步boundpod信息,一旦发现应该在该工作节点上运行的boundpod对象没有更新,则调用Docker API创建并启动pod内的容器。
3.3、容器的重启策略
- Pod对象因容器程序崩溃或容器申请超出限制的资源等原因都可能导致其被终止,ishi是否重建此它则取决于重启策略(restartPolicy)属性的定义
- Always :但凡Pod对象终止就将其重启,此为默认设定
- OnFailure : 仅在Pod对象出现错误时方才能将其重启
- Never : 从不重启
3.4、Pod的终止过程
-
Pod终止删除过程是通过用户来提交删除申请,之后Kubernetes来做整个Pod的删除操作。
-
当用户提交删除请求之后,系统就会进行强制删除操作的宽限期倒计时,并将TERM信息发送给Pod对象的每个容器中的主进程。宽限期倒计时结束后,这些进程将收到强制终止的KILL信号,Pod对象随即也将由API Server删除。如果在等待进程终止的过程中,kubelet或容器管理器发生了重启,那么终止操作会重新获得一个满额的删除宽限期并重新执行删除操作。
-
整个删除过程,如下图所示:
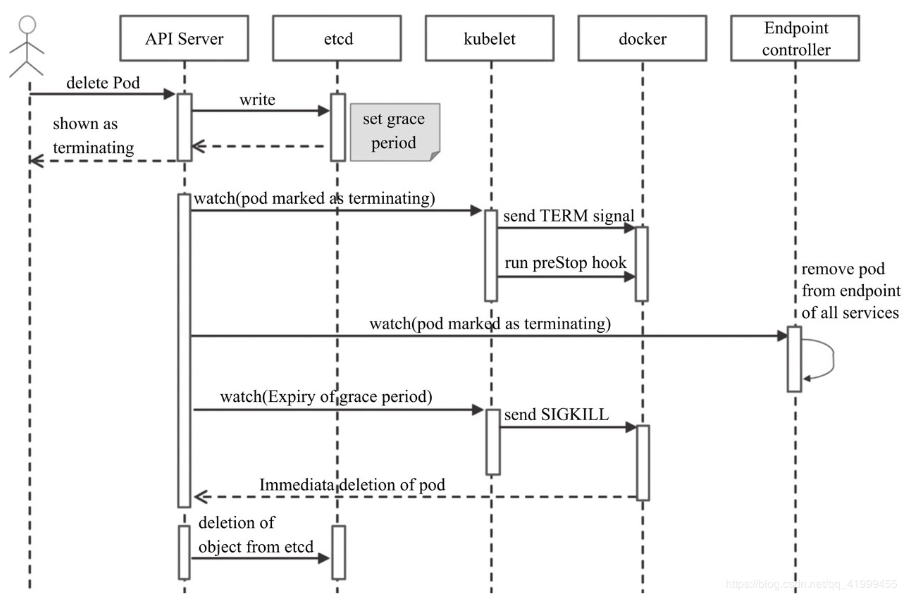
- 1、用户发送删除Pod对象的命令。
- 2、API服务器中的Pod对象会随着时间的推移而更新,在宽限期内(默认为30秒),Pod被视为“dead”。
- 3、将Pod标记为“Terminating”状态。
- 4、(与第3步同时运行)kubelet在监控到Pod对象转为“Terminating”状态的同时启动Pod关闭过程。
- 5、(与第3步同时运行)端点控制器监控到Pod对象的关闭行为时将其从所有匹配到此端点的Service资源的端点列表中移除。
- 6、如果当前Pod对象定义了preStop钩子处理器,则在其标记为“terminating”后即会以同步的方式启动执行;如若宽限期结束后,preStop仍未执行结束,则第2步会被重新执行并额外获取一个时长为2秒的小宽限期。
- 7、Pod对象中的容器进程收到TERM信号。
- 8、宽限期结束后,若存在任何一个仍在运行的进程,那么Pod对象即会收到SIGKILL信号。
- 9、Kubelet请求API Server将此Pod资源的宽限期设置为0从而完成删除操作,它变得对用户不再可见。
3.5、总结
- Pod会处于多种不同的状态,并执行一些操作;
- 其中,创建主容器(main container)为必需的操作,其他可选的操作还包括运行初始化容器(init container)、容器启动后钩子(post start hook)、容器的存活性探测(liveness probe)、就绪性探测(readiness probe)以及容器终止前钩子(pre stop hook)等,这些操作是否执行则取决于Pod的定义
四、securityContext安全上下文
4.1、安全上下文介绍
- 除了让pod使用宿主节点的Linux命名空间,还可以在pod或其所属容器的描述中通过security-context选项配置其他安全相关的特性,这个选项可以运用于整个pod,或者每个pod中的单独容器。
- 安全上下文可以配置的内容:
- 指定容器运行进程的用户(用户ID)
- 阻止容器用root用户启动(容器的默认运行用户通常可以在其镜像中指定,所以可能需要阻止容器以root用户运行)
- 使用特权模式运行容器,使其对宿主节点的内核具有完全的访问权限
- 与上相反,通过添加禁用内核功能,配置细粒度的内核访问权限
- 设置SELinux选项,加强对容器的限制
- 阻止进程写入容器的根文件系统
- 安全上下文可以配置的内容:
4.2、Pod的securityContext安全上下文(安全性要求严格时使用)
- pod的安全上下文,可以限制pod中运行的所有容器的安全策略
kubectl explain pods.spec.securityContext- fsGroup
- runAsGroup : pod中的进程仅能以哪个组的容器运行,指定组ID
- runAsNonRoot : pod中的用户以非管理员的身份运行 (True为指定以管理员身份运行 / False为不以管理员以普通用户身份运行)
- runAsUser : pod指定以哪个身份的用户运行,指定用户的ID号
- seLinuxOptions : 如果启用slinux,借助selinux设置容器的安全,一般情况则不使用
- supplementalGroups : 额外提供一个附属的组,组列表中组都可以被用户作为容器中运行所属的组
- sysctls : 可以设定为pod内的环境设置哪些内核参数
- windowsOptions
4.3、Pod中单一容器的securityContext安全上下文
kubectl explain pods.spec.containers.securityContext- allowPrivilegeEscalatio : 容器使用允许必要时升级使用管理员身份运行 (True为指定以管理员身份运行 / False为不以管理员以普通用户身份运行)
- capabilities : 定义当前的容器能否允许执行或放弃哪种能力(内核级别)
- add
- drop
- privileged : 容器运行是否直接以特权容器运行
- procMount : 是否运行容器运行直接挂载proc目录
- readOnlyRootFilesystem : 容器根文件系统是否设置为只读
- runAsGroup
- runAsNonRoot
- runAsUser
- seLinuxOptions
- windowsOptions
- capabilities :能力,添加或删除容器的哪种能力和内核相关
五、Kubernetes之pod优先级与抢占(priorityClassName)
kubectl explain pods.spec.priorityClassName- 参考博客先有概念:https://blog.csdn.net/dkfajsldfsdfsd/article/details/81190451
六、Pod中容器资源管控(cpu/内存)
kubectl explain pods.spec.containers.resourceslimits: 资源上限requests:(资源需求)资源下限 即启动这个容器至少保证的资源
6.1、资源需求及资源限制
- 容器的计算资源配额
- CPU属于可压缩(compressible)型资源,即资源额度可按需收缩,而内存(当前)则是不可压缩型资源,对其指定收缩操作可能会导致某种程度的问题
- CPU资源的计量方式
- 一个核心相当于1000个微核心,即1=1000m, 0.5=500m
- 内存资源的计量方式
- 默认单位为字节,也可以使用E、P、T、G、M和K后缀单位,或者Ei、Pi、Ti、Gi、Mi和Ki形式的单位后缀
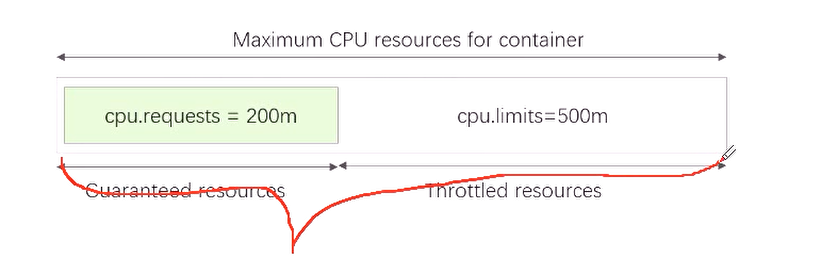
6.2、资源需求限制示例
- 示例一
chapter4]# cat stress-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: stress-pod
spec:
containers:
- name: stress
#容器运行的镜像
image: ikubernetes/stress-ng
#容器中运行的命令
command: ["/usr/bin/stress-ng", "-c 1", "-m 1", "--metrics-brief"]
#资源需求限制
resources:
#设置这个容器资源下限
requests:
memory: "128Mi"
cpu: "200m"
#设置这个容器资源上限
limits:
memory: "512Mi"
cpu: "400m"
- 示例二
chapter4]# cat memleak-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: memleak-pod
spec:
containers:
- name: simmemleak
image: saadali/simmemleak
resources:
requests:
memory: "64Mi"
cpu: "1"
limits:
memory: "64Mi"
cpu: "1"
6.3、Pod服务质量类别
- 根据Pod对象的requests和limits属性,kubernetes把Pod对象归类到BestEffort、Guaranteed三个服务质量类别 (Quality of Service, QoS)类别下
Guaranteed: (必须)每个容器都为CPU资源设置了具有相同值得requests和limits属性,以及每个容器都为内存资源设置了具有相同值得requests和limits属性得pod资源会自动归属此类别,这类pod资源具有最高优先级
-Burstable: (应该)至少有一个容器设置了CPU和呢村资源得requests属性,但不满足Guaranteed类别要求得pod资源会自动归属此类别,它们具有中等优先级BestEffort: (尽量)未为任何容器设置requests或limits属性得pod资源自动归属此类别,它们得优先级为最低级别
~]# kubectl describe pods liveness-exec
Name: liveness-exec
Namespace: default
Priority: 0
Node: k8s.node1/192.168.20.212
Start Time: Sat, 02 May 2020 14:18:03 +0800
Labels: test=liveness-exec
Annotations: Status: Running
IP: 10.244.1.7
IPs:
IP: 10.244.1.7
Containers:
liveness-demo:
Container ID: docker://8d850d5191c3bb5af7e63c124c07e4bf8c98fa708339dab0ed49caec5bcb0615
Image: busybox
Image ID: docker-pullable://busybox@sha256:a8cf7ff6367c2afa2a90acd081b484cbded349a7076e7bdf37a05279f276bc12
Port: <none>
Host Port: <none>
Args:
/bin/sh
-c
touch /tmp/healthy; sleep 20; rm -rf /tmp/healthy; sleep 600
State: Running
Started: Sun, 03 May 2020 00:01:01 +0800
Last State: Terminated
Reason: Error
Exit Code: 137
Started: Sat, 02 May 2020 23:59:17 +0800
Finished: Sun, 03 May 2020 00:00:29 +0800
Ready: True
Restart Count: 142
Liveness: exec [test -e /tmp/healthy] delay=0s timeout=1s period=10s #success=1 #failure=3
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-q97bf (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-q97bf:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-q97bf
Optional: false
QoS Class: BestEffort # 尽量保证
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 27m (x136 over 9h) kubelet, k8s.node1 Successfully pulled image "busybox"
Normal Pulling 18m (x139 over 9h) kubelet, k8s.node1 Pulling image "busybox"
Warning Unhealthy 8m9s (x422 over 9h) kubelet, k8s.node1 Liveness probe failed:
Warning BackOff 3m13s (x1684 over 9h) kubelet, k8s.node1 Back-off restarting failed container
向往的地方很远,喜欢的东西很贵,这就是我努力的目标。

