Python Jenkins-jenkins模块获取jobs的执行状态操作
PS 参考博文,致谢 :https://www.jb51.net/article/186336.htm
一、获取Jobs的当前状态
server_1 = jenkins.Jenkins('http://%s:%s@192.168.37.134:8081/',username, password)
# 获取状态前先确认2019文件夹下的get_node_list任务是否存在:
server_1.assert_job_exists('2019/get_node_list')
# 获取最后一次完成(不包括执行中的)的job任务执行number:
server_1.get_job_info('2019/get_node_list')['lastCompletedBuild']['number']
# 查看job状态(SUCCESS/FAILURE/ABORTED):
server_1.get_build_info('2019/get_node_list',3)['result']
server_1.get_build_console_output('2019/get_node_list',7).split('\n')[-2].split(':')[-1].strip()
# 启动jobs:
server_1.build_job('2019/get_node_list')
- 在job执行结束前使用server_1.get_build_console_output(‘2019/get_node_list',7).split('\n')[-2].split('😂[-1].strip()获取的状态信息不符合预期。
- job状态应该还包括running,pending状态,那么获取job的当前状态正确姿势如下:
job_name = '2019/get_node_list'
def get_jobs_status(job_name,server):
try:
server.assert_job_exists(job_name)
except Exception as e:
print(e)
job_statue = '1'
#判断job是否处于排队状态
inQueue = server.get_job_info(job_name)['inQueue']
if str(inQueue) == 'True':
job_statue = 'pending'
running_number = server.get_job_info(job_name)['nextBuildNumber']
else:
#先假设job处于running状态,则running_number = nextBuildNumber -1 ,执行中的job的nextBuildNumber已经更新
running_number = server.get_job_info(job_name)['nextBuildNumber'] -1
try:
running_status = server.get_build_info(job_name,running_number)['building']
if str(running_status) == 'True':
job_statue = 'running'
else:
#若running_status不是True说明job执行完成
job_statue = server.get_build_info(job_name,running_number)['result']
except Exception as e:
#上面假设job处于running状态的假设不成立,则job的最新number应该是['lastCompletedBuild']['number']
lastCompletedBuild_number = server.get_job_info(job_name)['lastCompletedBuild']['number']
job_statue = server.get_build_info(job_name,lastCompletedBuild_number)['result']
return job_statue,running_number
- 注意:
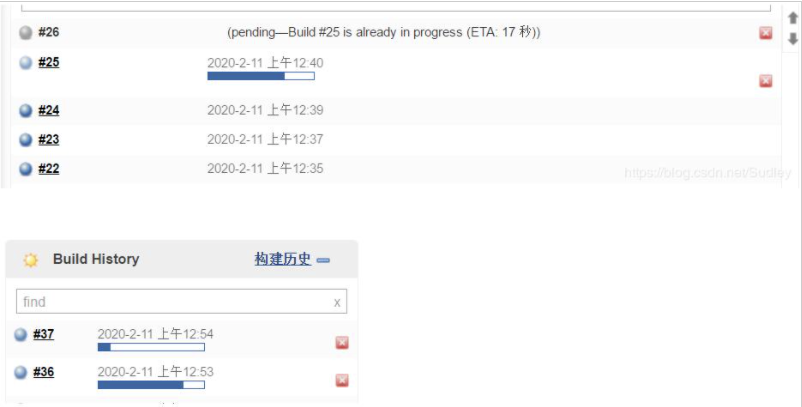
- 可能还存在下图的情况,这个时候获取的是26的状态,这时候也许你想获取25的状态,26是不小心误操作触发的,这个时候任务的最新状态也许就无法满足预期要求,或者是支持并发构建的job场景中就不适用了,关键还是需要结合应用场景制定对应的方案。
二、统计Jobs的执行成功率和平均执行时间
- 统计场景说明:
- 设计了一个统计job执行成功率的工程,主要从执行时间以及视图两个维度来划定需要统计的jobs及jobs对应的运行范围。
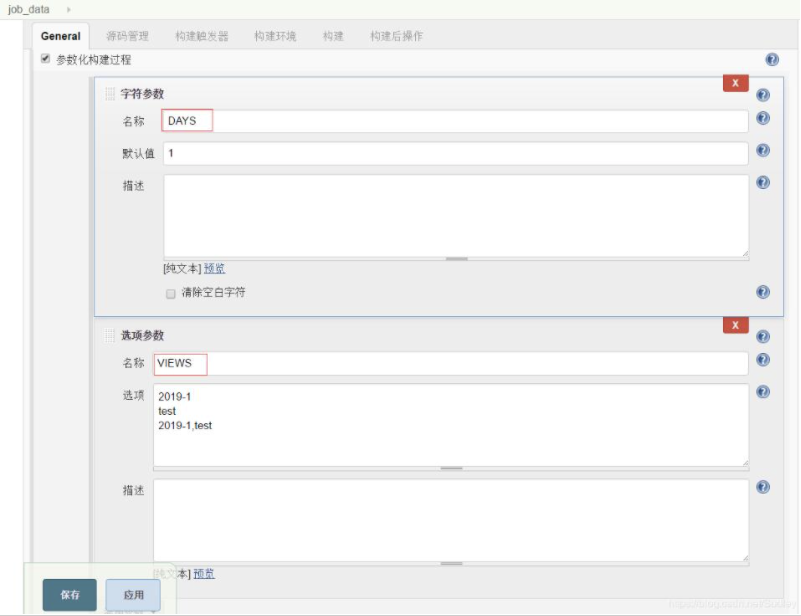
- 在这里我在job里面添加了DAYS和VIEWS两个参数:
- DAYS:默认统计最近一天的运行情况,如果执行的时候输入的是0则代表统计所有的运行情况。
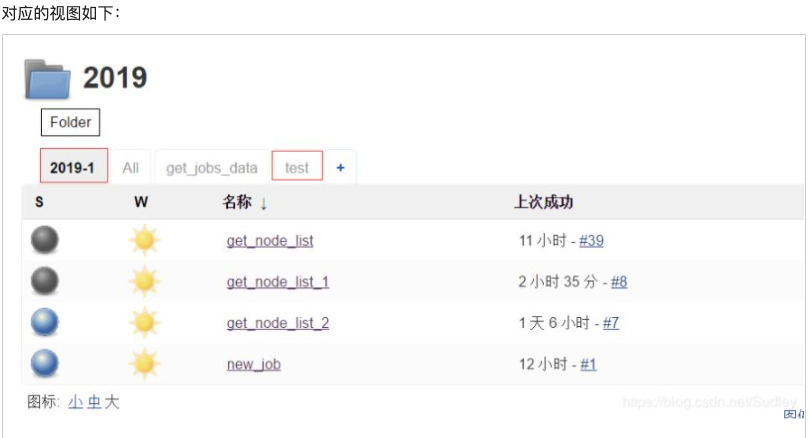
- VIEWS:对应的是视图名称,“2019-1,test”代表统计这两个视图的运行情况
-
执行成功后以表格形式列出统计的数据,表头如下 :

-
列出了序号、视图名称、job名称、job执行成功的平均执行时间、job执行成功次数、总的执行时间、job执行成功率
-
job执行演示:
-
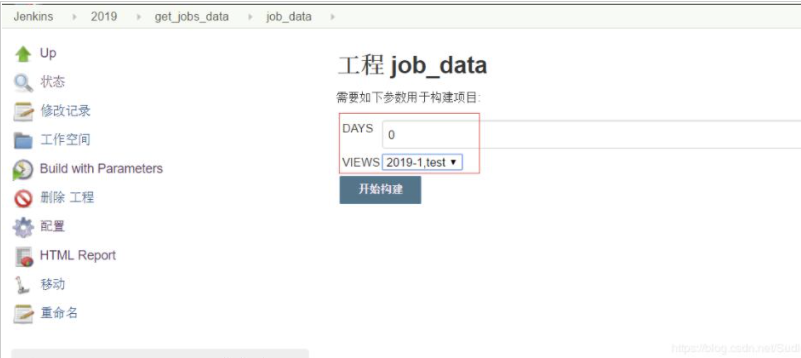
执行构建时配置的参数如下 :
- job_data任务的主要执行内容如下:
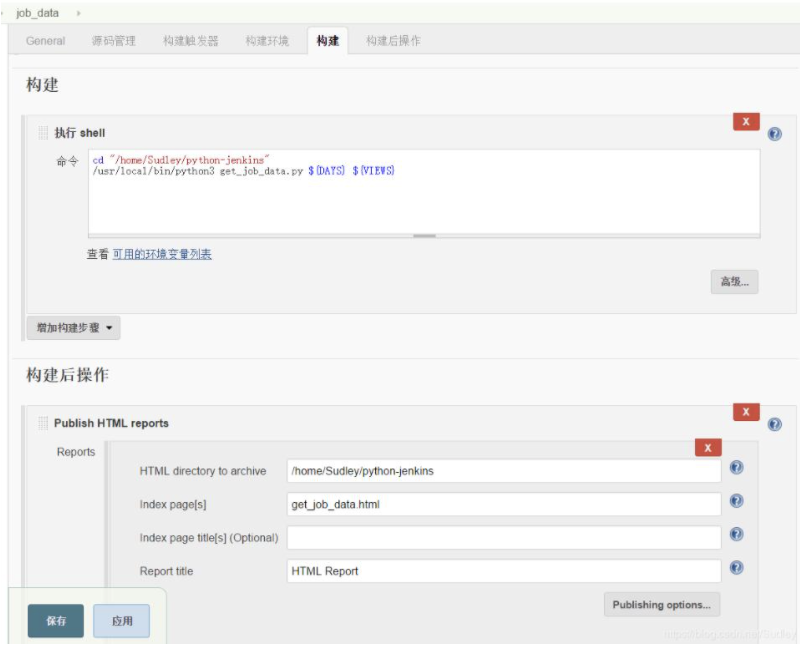
-
执行成功后查看HTML_Report统计的数据如下:
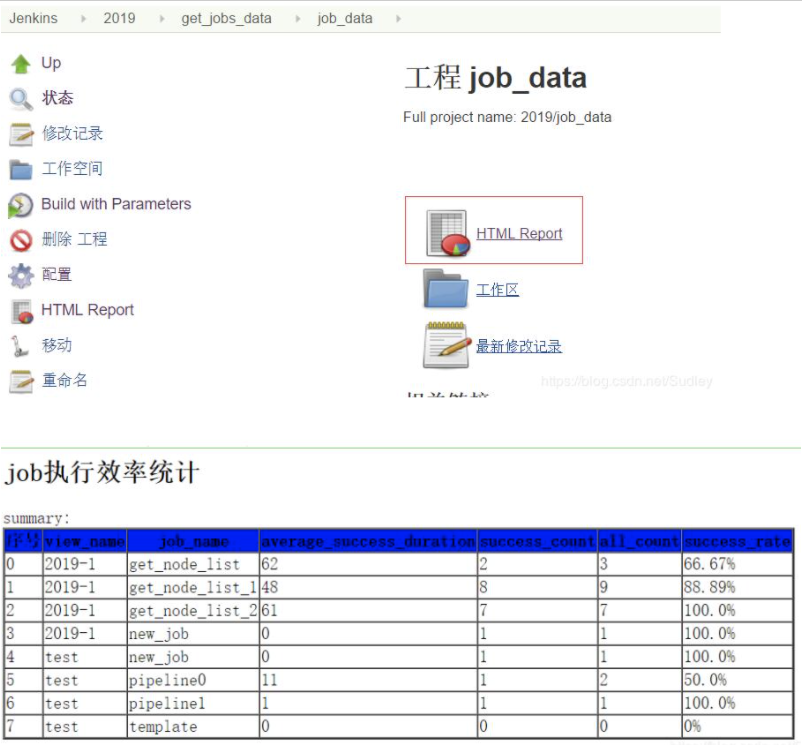
-
get_job_data.py源码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: Sudley
# ctime: 2020/02/12
import sys
import jenkins
import time
from dominate.tags import *
def Count_the_success_rate_of_jobs(days,views):
username = 'sudley'
password = '******'
with open('//home/Sudley/python-jenkins/get_job_data.txt','w') as f:
print('create a new file //home/Sudley/python-jenkins/get_job_data.txt')
serial_number = 0 #统计任务的累计序号
for view in views.split(','):
#根据视图名称拼接视图的URL,多个视图间用','分隔
URL = ('http://%s:%s@192.168.37.134:8081/job/2019/view/%s/')%(username, password, view)
server = jenkins.Jenkins(URL)
#依次获取当前view视图中jobs的信息
for num in range(0,len(server.get_all_jobs())):
job_name = server.get_all_jobs()[num]['fullname']
#获取最后一次完成构建的编号,用于划定时间范围(如果需要的话)
try:
lastCompletedBuild_num = server.get_job_info(job_name)['lastCompletedBuild']['number']
except:
#假如job下面一个构建记录都没有则补0
print('There is not build number in',job_name)
average_success_duration = success_count = all_count = success_rate = 0
line = str(serial_number) + ' ' + view + ' ' + job_name + ' ' + str(int(average_success_duration)) + ' ' + str(success_count) + ' ' + str(all_count) + ' ' + str(success_rate) + '%'
with open('//home/Sudley/python-jenkins/get_job_data.txt','a') as f:
f.write(str(line))
f.write('\n')
serial_number = serial_number + 1
continue
#获取最后一次完成构建的时间戳,单位由毫秒转换为秒
lastCompletedBuild_timestamp = server.get_build_info(job_name,lastCompletedBuild_num)['timestamp'] / 1000
#将时间先由秒转化为元组在转化为字符串并取到天数
lastCompletedBuild_date = time.strftime("%Y%m%d",time.localtime(lastCompletedBuild_timestamp))
#print(lastCompletedBuild_date)
#根据变量days和lastCompletedBuild_timestamp计算出days天前的日期,若days为0则没有日期限制,统计之前运行的所有任务
if str(days) == '0':
end_date = 'false'
else:
end_timestamp = float(lastCompletedBuild_timestamp) - float(days) * 24 * 3600
end_date = time.strftime("%Y%m%d",time.localtime(end_timestamp))
#print(end_date)
#获取days天内job的执行情况
success_count = 0 #job执行成功的总数
success_duration = 0 #执行成功的job执行时间之和,单位是s
for number in range(0,len(server.get_job_info(job_name)['builds'])):
job_build_number = server.get_job_info(job_name)['builds'][number]['number']
job_build_timestamp = server.get_build_info(job_name,job_build_number)['timestamp'] / 1000
job_build_date = time.strftime("%Y%m%d",time.localtime(job_build_timestamp))
#如果日期和end_date相同则终止此job数据的累计
if job_build_date == end_date:
number = number - 1
break
#累计执行成功的次数和duration执行时间
job_build_result = server.get_build_info(job_name,job_build_number)['result']
if str(job_build_result) == 'SUCCESS':
job_build_duration = server.get_build_info(job_name,job_build_number)['duration']
success_duration = success_duration + job_build_duration / 1000
success_count = success_count + 1
#计算执行成功的平均执行时间和成功率,打印关键信息
all_count = number + 1
success_rate = success_count * 1.0 / all_count * 100
if success_count == 0:
average_success_duration = success_duration
else:
average_success_duration = success_duration * 1.0 / success_count
#将关心的数据按照一定的格式写到/home/Sudley/python-jenkins/get_job_data.txt文件中
line = str(serial_number) + ' ' + view + ' ' + job_name + ' ' + str(int(average_success_duration)) + ' ' + str(success_count) + ' ' + str(all_count) + ' ' + str(round(success_rate,2)) + '%'
with open('//home/Sudley/python-jenkins/get_job_data.txt','a') as f:
f.write(str(line))
f.write('\n')
serial_number = serial_number + 1
def txt2xml():
h = html()
with h.add(body()):
h2('job执行效率统计')
caption('summary:')
with table(border="2",cellspacing="0"):
l = tr(bgcolor="#0000FF")
l += th('序号')
l += th('view_name')
l += th('job_name')
l += th('average_success_duration')
l += th('success_count')
l += th('all_count')
l += th('success_rate')
file=open('/home/Sudley/python-jenkins/get_job_data.txt')
for line in file.readlines():
curLine=line.strip().split(" ")
l = tr()
for i in range(0,len(curLine)):
l += td(curLine[i])
with open('/home/Sudley/python-jenkins/get_job_data.html','w') as f:
f.write(h.render())
if __name__ == '__main__' :
days = sys.argv[1]
views = sys.argv[2]
Count_the_success_rate_of_jobs(days,views)
txt2xml()
向往的地方很远,喜欢的东西很贵,这就是我努力的目标。

