异步爬虫-线程池方式对梨视频的视频数据爬取
一、需求分析
- 需求 :爬取梨视频的视频的视频数据
- 分析:
1、对生活分类的数据进行发起请求 :https://www.pearvideo.com/category_5
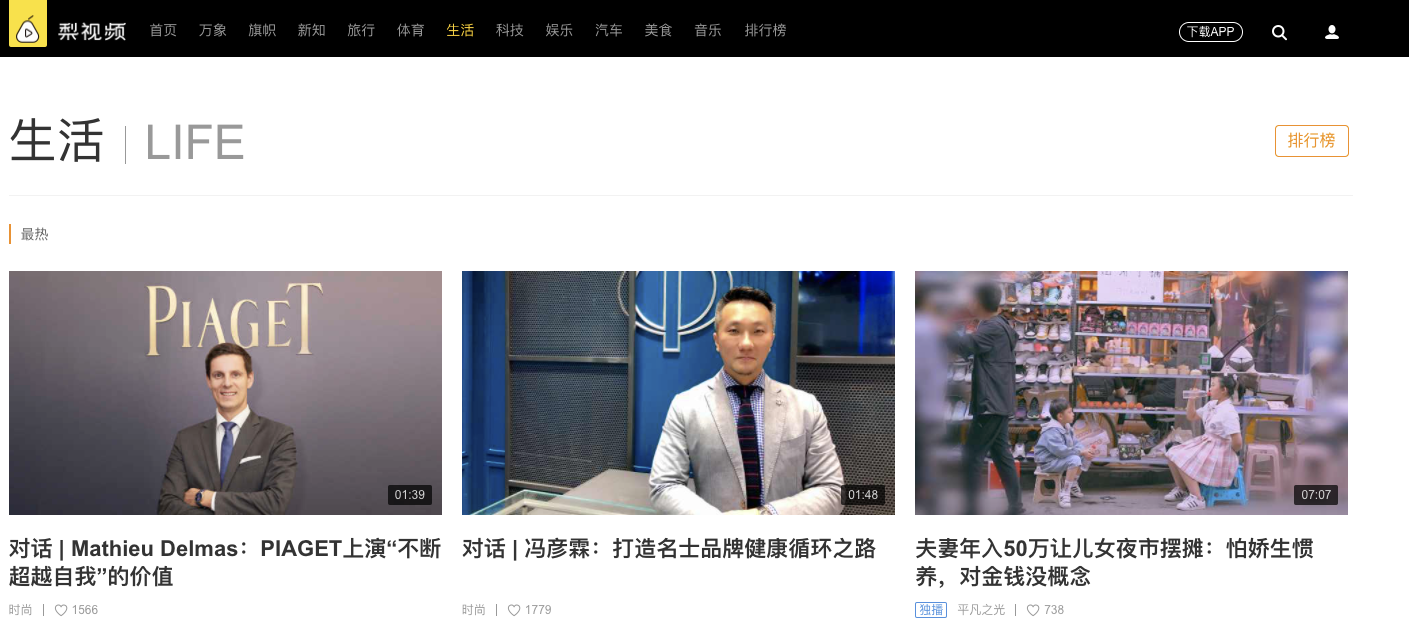
2、解析出视频详情页面的url和视频的名称
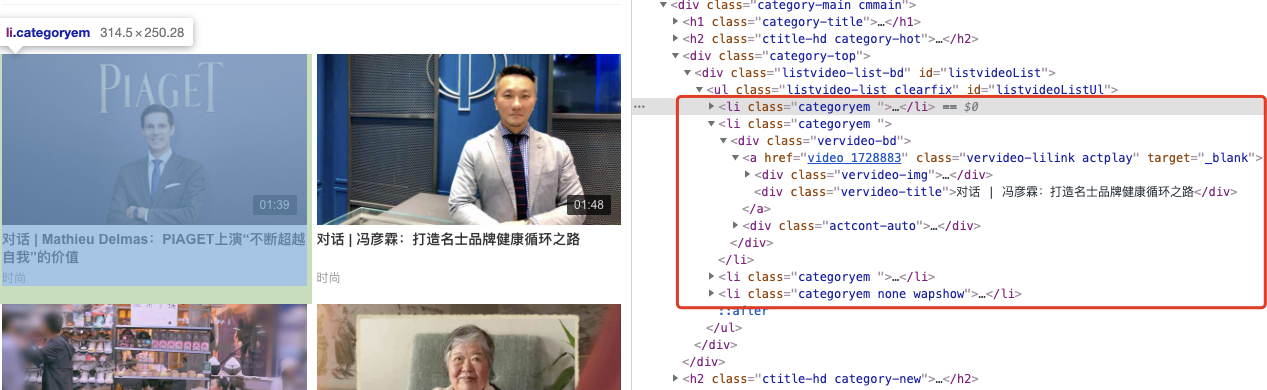
二、梨视频的视频数据爬取编码
# 原则:线程池处理的是阻塞并且比较耗时的操作
#爬取梨视频的视频数据
import requests
from lxml import etree
import re
from multiprocessing.dummy import Pool
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
#对网站发起请求,解析出视频的名称和视频详情页的url
url = 'https://www.pearvideo.com/category_5'
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@id="listvideoListUl"]/li')
urls = [] #存储所有视频的链接和名字
for li in li_list:
detail_url = 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name = li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
print(detail_url,name)
#对视频详情页的url发起请求
detail_page_text = requests.get(url=detail_url,headers=headers).text
#从视频详情页中解析出视频的url
ex = 'srcUrl="(.*?)",vdoUrl'
video_url = re.findall(ex,detail_page_text)[0]
dic = {
'name':name,
'url':video_url
}
urls.append(dic)
def get_video_data(dic):
url = dic['url']
print(dic['name'],'正在下载......')
data = requests.get(url=url,headers=headers).content
#持久化存储操作
with open(dic['name'],'wb') as fp:
fp.write(data)
print(dic['name'],'下载成功!')
#使用线程池对视频数据进行请求(比较耗时的阻塞操作)
pool = Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
向往的地方很远,喜欢的东西很贵,这就是我努力的目标。

