requests高级之人人网进行模拟登陆
一、引出模拟登陆需求
-
什么场景需要使用爬虫程序进行模拟登陆需求呢 ?
- 经常爬取的内容是基于某些用户的用户信息,这些用户信息是需要进行登陆后才会跳转到用户信息当中的;
- 我们需要使用requests模块进行模拟登陆,登录后才可以进行对用户信息爬取;
-
所以接下来会对 人人网 进行模拟登陆,那么和此前的验证码识别有什么关联;
-
人人网的登陆验证码为 当连续失败登陆超过 3次以后就会弹出验证码登陆;
二、需求分析
- 需求 :对人人网进行模拟登陆
- 分析 :
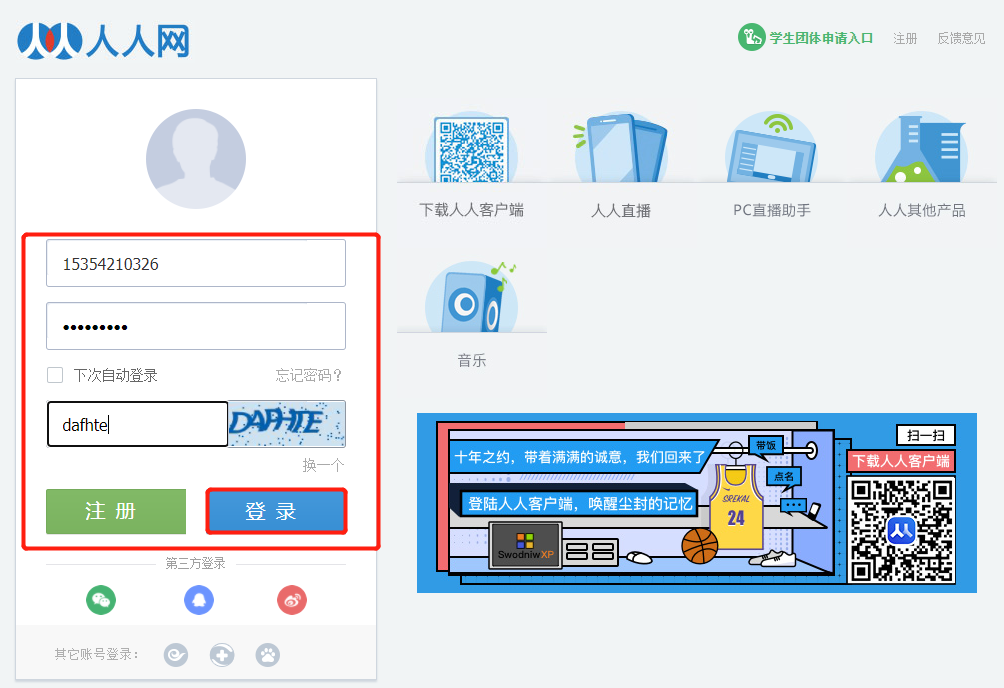
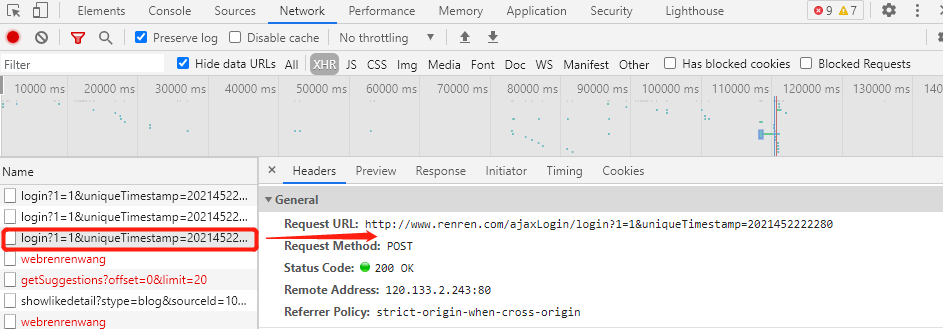
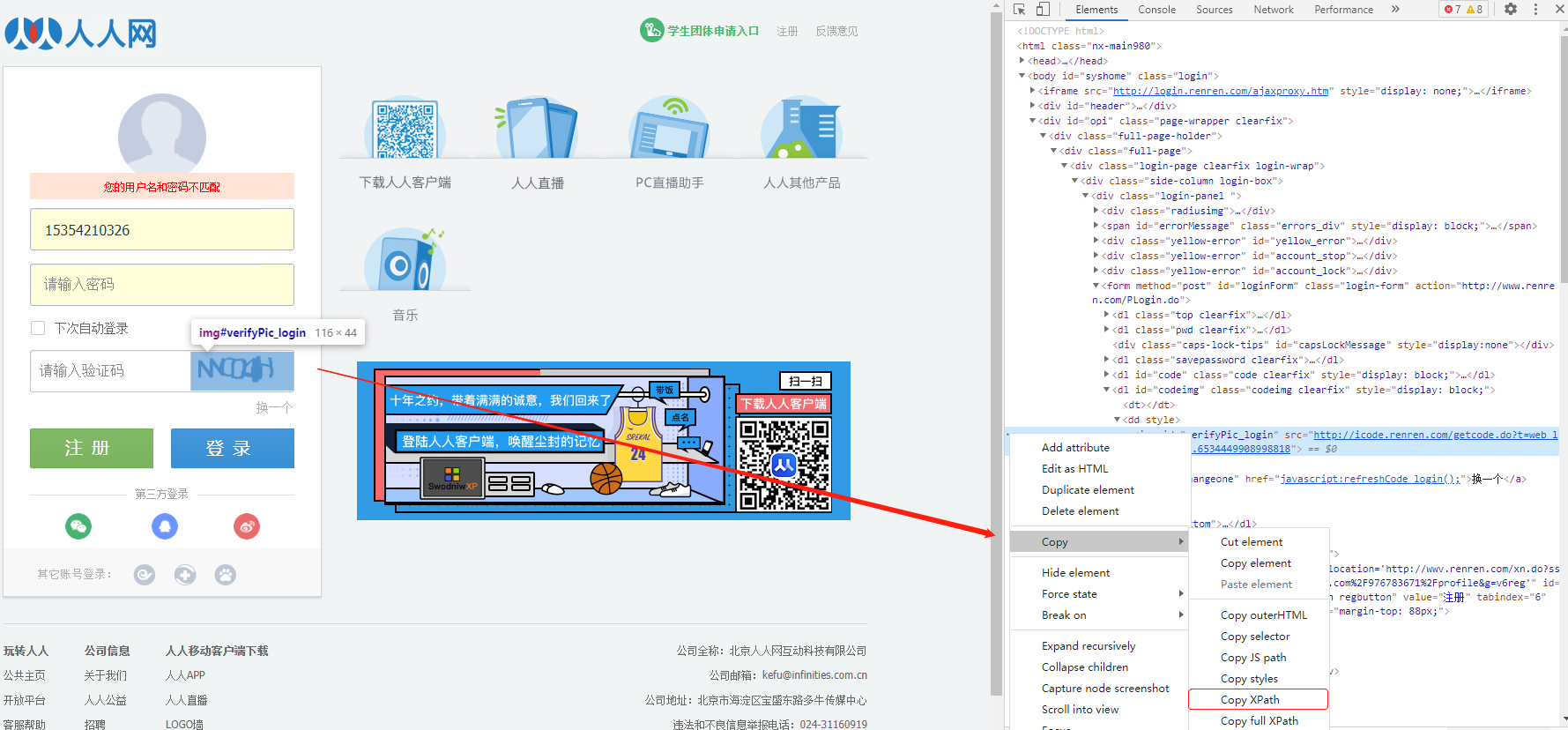
1、手动对人人网 进行点击登陆,打开抓包工具,查看发起的请求,获取请求的接口信息;
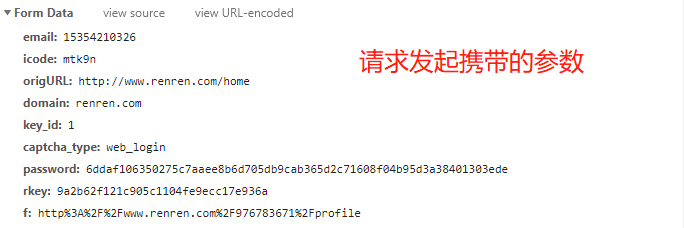
2、Post请求对ajaxLogin接口请求参数分析
# 用户名
email: 15354210326
# 验证码
icode: mtk9n
origURL: http://www.renren.com/home
domain: renren.com
key_id: 1
captcha_type: web_login
# 密码
password: 6ddaf106350275c7aaee8b6d705db9cab365d2c71608f04b95d3a38401303ede
rkey: 9a2b62f121c905c1104fe9ecc17e936a
f: http%3A%2F%2Fwww.renren.com%2F976783671%2Fprofile
3、根据上述分析,如果我们想实现对人人网的模拟登陆,只需要对ajaxLogin接口发起请求,并携带正确登陆参数;
4、验证码 :每次请求都会动态变化,所以我们在模拟登陆前,需要对登陆页的验证码数据进行识别,识别的结果需要作为 对登陆接口 POST请求时一个参数;
三、人人网模拟登陆编码
3.1、编码流程
1、验证码识别,获取验证码图片的文字数据 :对当前登陆页面进行请求,将验证码进行解析,对验证码地址发起请求,就可以获取验证码图片并保存到本地,然后使用超级鹰提供的图片识别功能进行识别解析;
2、对POST请求发起请求,处理请求参数;
3、对响应数据进行持久化存储;
3.2、编码
- 超级鹰 Python 识别示例 : http://www.chaojiying.com/
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
- 人人网图片验证码识别
# _*_coding : UTF-8_*_
import requests
from lxml import etree
# 1、对验证码图片进行捕获和识别
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url = "http://www.renren.com/SysHome.do"
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
code_image_src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
code_imag_data = requests.get(url=code_image_src, headers=headers).content # 二进制
with open('./code.jpg', 'wb') as fp:
fp.write(code_image_src)
# 使用超级鹰提供的示例代码对验证码图片进行识别
# 使用超级鹰提供的示例代码对验证码图片进行识别
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') #用户中心>>软件ID 生成一个替换 96001
im = open('./code.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) # {'err_no': 0, 'err_str': 'OK', 'pic_id': '9140511106217900002', 'pic_str': '4hgk', 'md5': 'a0d0bb24317338ba2bdb00dbb467bb56'}
- POST 请求的发送,模拟登录
# _*_coding : UTF-8_*_
import requests
from lxml import etree
from chaojiying import Chaojiying_Client
# 1、对验证码图片进行捕获和识别
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url = "http://www.renren.com/SysHome.do"
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
code_image_src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
code_imag_data = requests.get(url=code_image_src, headers=headers).content # 二进制
with open('./code.jpg', 'wb') as fp:
fp.write(code_imag_data)
# 2、使用超级鹰提供的示例代码对验证码图片进行识别
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') #用户中心>>软件ID 生成一个替换 96001
im = open('./code.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) # {'err_no': 0, 'err_str': 'OK', 'pic_id': '9140511106217900002', 'pic_str': '4hgk', 'md5': 'a0d0bb24317338ba2bdb00dbb467bb56'}
icode = chaojiying.PostPic(im, 1902)['pic_str']
# 3、POST请求的发送,模拟登录
login_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2021401144357'
data = {
"email": '15354210326',
"icode":icode,
"origURL": "http://www.renren.com/home",
"domain": "renren.com",
"key_id": '1',
"captcha_type": "web_login",
"password" : '65998cf5a6aea54758cce558a257c93ba57cf0ec38ae339c589c417af98e1be2',
"rkey": '21440623b2178c3ea555a33f8a07d83d',
"f": "http%3A%2F%2Fwww.renren.com%2F9a76783671%2Fprofile"
}
response = requests.post(url=login_url, headers=headers, data=data)
login_Page_text = response.text
print(response.status_code)
with open('renren.html', 'w', encoding='utf-8') as fp:
fp.write(login_Page_text)
四、模拟登录 Cookie操作
4.1、需求分析
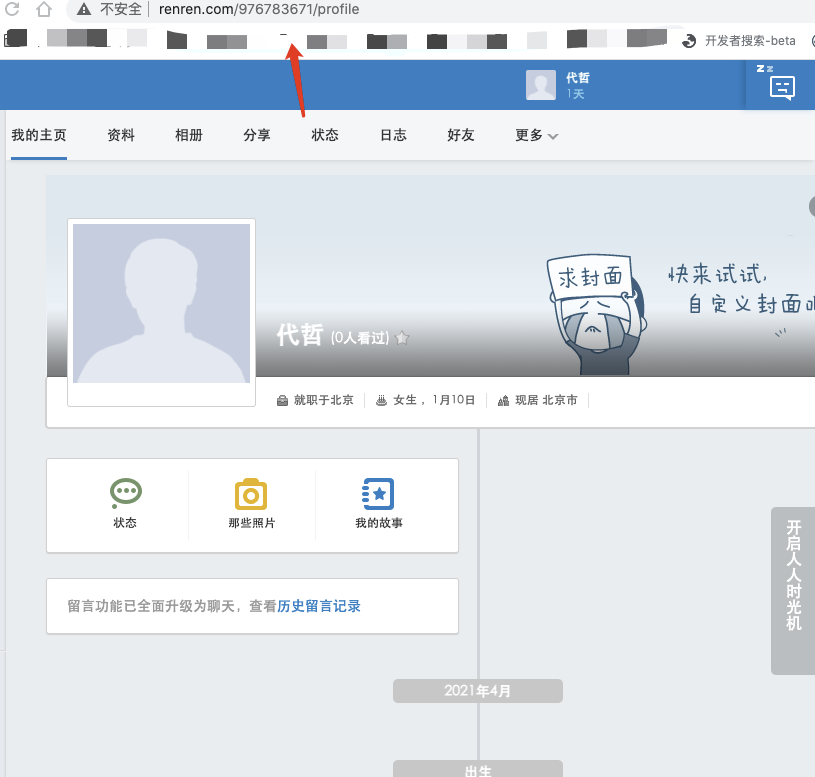
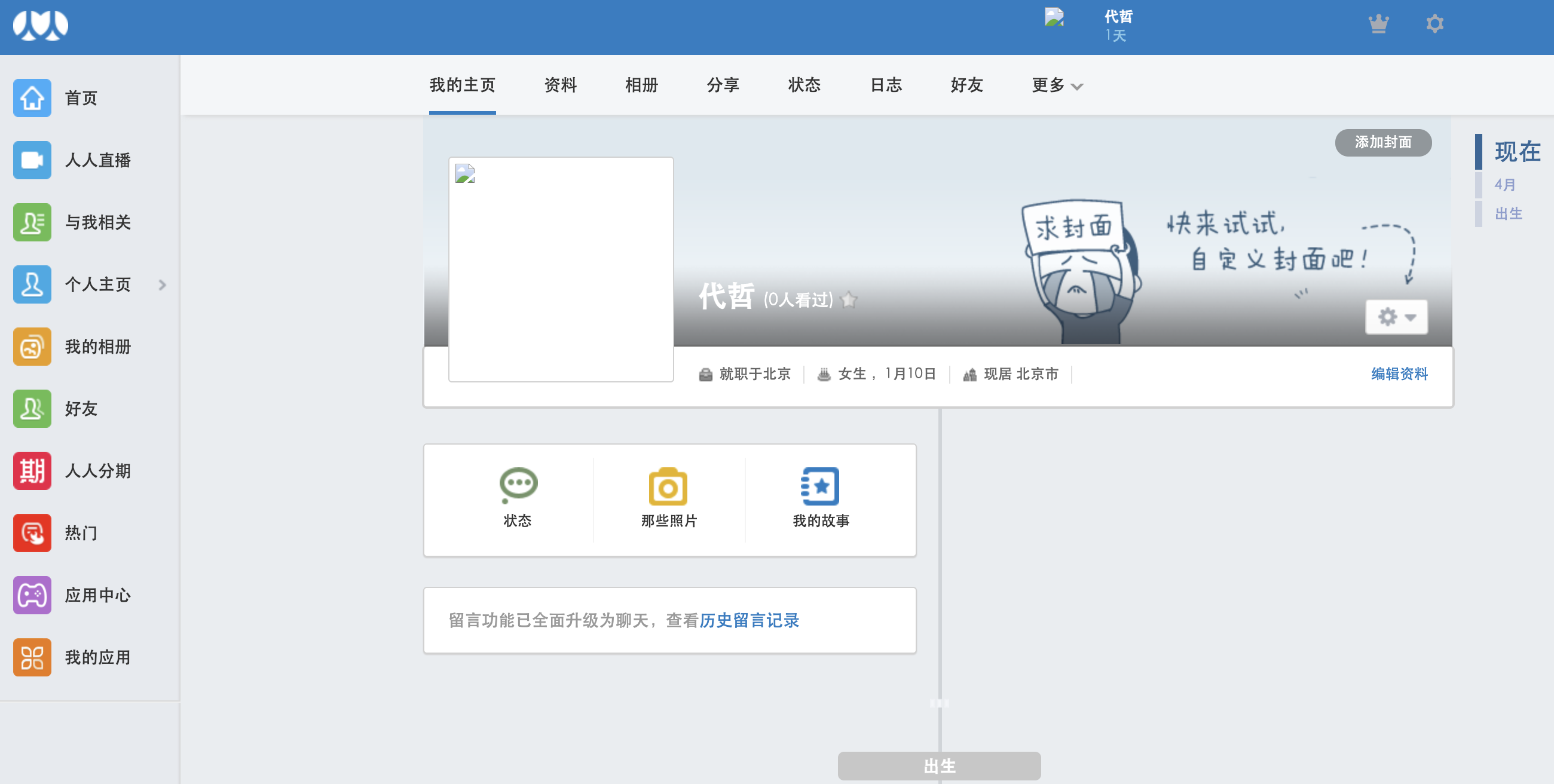
- 需求 :模拟登录后,爬取当前用户的相关用户信息(个人主页中显示的主页信息 )
- 分析 :
1、模拟登录后,默认是人人网首页中,打开抓包工具,可以查看到点击个人头像跳转到我们主页中,发起一个请求;
4.2、人人网爬取当前用户的相关用户信息编码
# _*_coding : UTF-8_*_
import requests
from lxml import etree
from chaojiying import Chaojiying_Client
# 1、对验证码图片进行捕获和识别
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url = "http://www.renren.com/SysHome.do"
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
code_image_src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
code_imag_data = requests.get(url=code_image_src, headers=headers).content # 二进制
with open('./code.jpg', 'wb') as fp:
fp.write(code_imag_data)
# 2、使用超级鹰提供的示例代码对验证码图片进行识别
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') #用户中心>>软件ID 生成一个替换 96001
im = open('./code.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) # {'err_no': 0, 'err_str': 'OK', 'pic_id': '9140511106217900002', 'pic_str': '4hgk', 'md5': 'a0d0bb24317338ba2bdb00dbb467bb56'}
icode = chaojiying.PostPic(im, 1902)['pic_str']
# 3、POST请求的发送,模拟登录
login_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2021401144357'
data = {
"email": '15354210326',
"icode":icode,
"origURL": "http://www.renren.com/home",
"domain": "renren.com",
"key_id": '1',
"captcha_type": "web_login",
"password" : '65998cf5a6aea54758cce558a257c93ba57cf0ec38ae339c589c417af98e1be2',
"rkey": '21440623b2178c3ea555a33f8a07d83d',
"f": "http%3A%2F%2Fwww.renren.com%2F9a76783671%2Fprofile"
}
response = requests.post(url=login_url, headers=headers, data=data)
login_Page_text = response.text
print(response.status_code)
# 4、爬取当前用户的个人主页对用的页面数据
detail_url = 'http://www.renren.com/976783671/profile'
detail_page_text = requests.get(url=detail_url, headers=headers).text
with open('daizhe.html', 'w', encoding='utf-8') as fp:
fp.write(detail_page_text)
- 查看爬取的页面,发现并不是个人主页信息,而是登录时的页面,这里就需要考虑到
Cookie的操作了;
没有请求到对应页面数据的原因 :
- http、https协议特性 :无状态;
- 发起的第二次请求基于个人主页页面请求的时候,服务端并不知道该次请求是基于登录状态下的请求;
- cookie :用来让服务器端记录客户端的相关状态 ;
- 手动处理 cookie :通过抓包工具获取 cookie值,将该值封装到 headers中;
- 自动处理 cookie :
- cookie 值的来源哪里 ?
- 通过首次模拟登录的 POST请求后,服务器端创建的,可以通过Response Headers中获取 cookie;
- session会话对象 :
- 作用 :
- 1、可以进行请求的发送;
- 2、如果请求过程中产生了cookie,则该cookie会被自动存储、携带在该session对象中;
- 作用 :
- cookie 值的来源哪里 ?
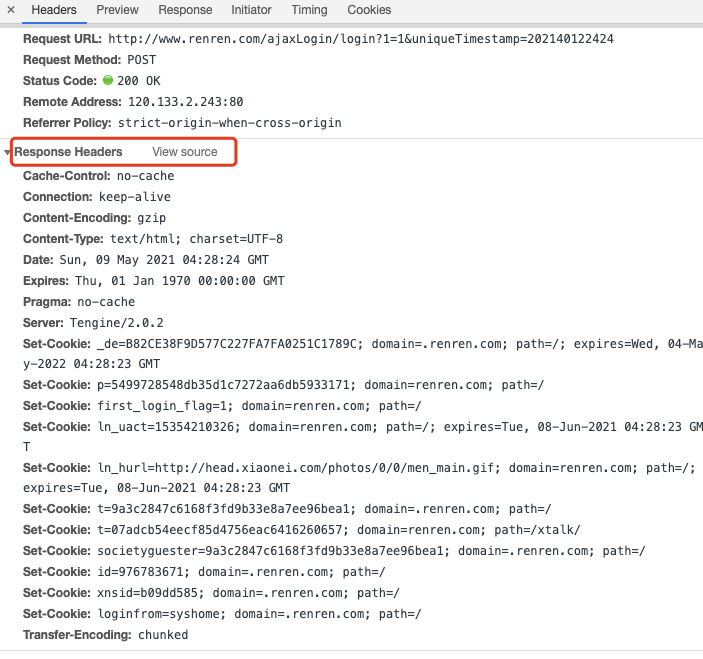
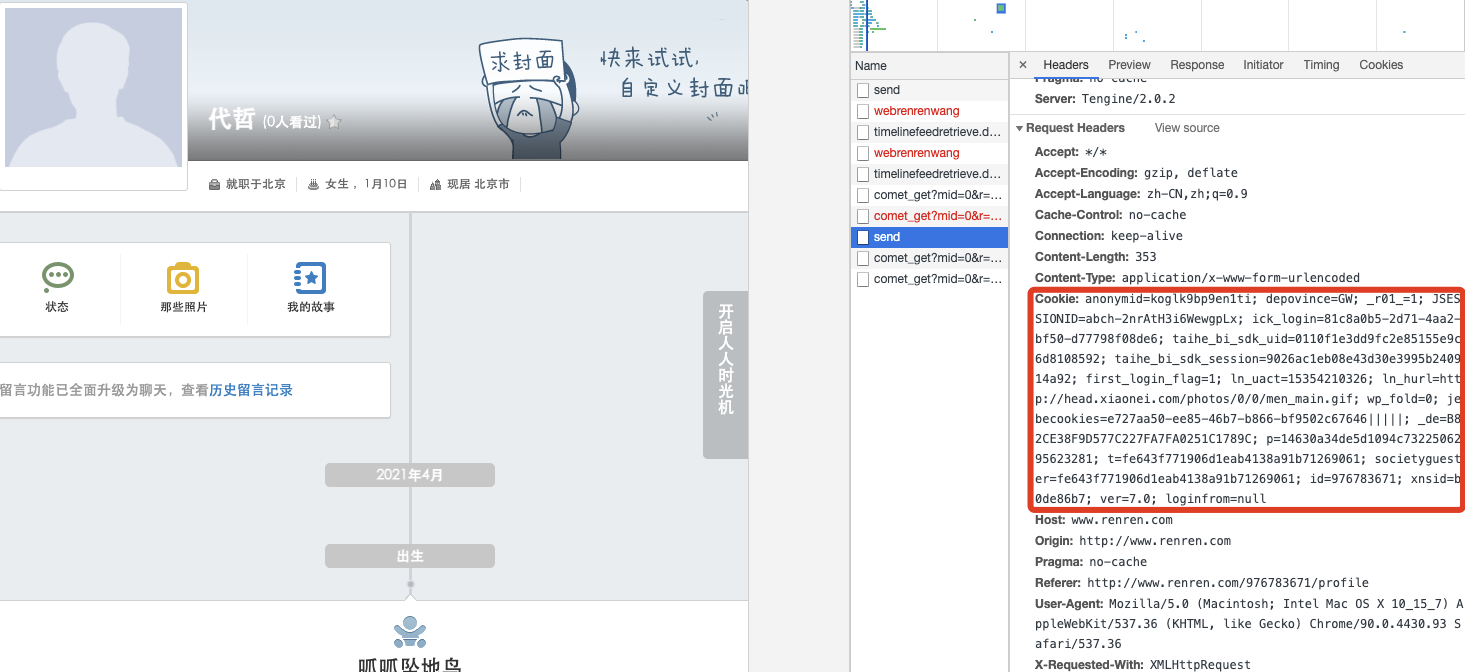
- 携带Cookie 重新发起请求 : 第二次发起请求,服务器端就会知道客户端是在登录状态发起的请求,服务器端就会返回登录后的相应数据;
1、创建一个session对象;session = requests.Session()
2、使用session对象进行模拟登录POST请求的发送,cookie就会被存储到session中;
3、session对个人主页对应的GET请求进行发送,就会携带了 cookie;
- 编码
# _*_coding : UTF-8_*_
import requests
from lxml import etree
from chaojiying import Chaojiying_Client
# 常见session对象
session = requests.Session()
# 1、对验证码图片进行捕获和识别
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url = "http://www.renren.com/SysHome.do"
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
code_image_src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
code_imag_data = requests.get(url=code_image_src, headers=headers).content # 二进制
with open('./code.jpg', 'wb') as fp:
fp.write(code_imag_data)
# 2、使用超级鹰提供的示例代码对验证码图片进行识别
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') #用户中心>>软件ID 生成一个替换 96001
im = open('./code.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) # {'err_no': 0, 'err_str': 'OK', 'pic_id': '9140511106217900002', 'pic_str': '4hgk', 'md5': 'a0d0bb24317338ba2bdb00dbb467bb56'}
icode = chaojiying.PostPic(im, 1902)['pic_str']
# 3、POST请求的发送,模拟登录
login_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2021401144357'
data = {
"email": '15354210326',
"icode":icode,
"origURL": "http://www.renren.com/home",
"domain": "renren.com",
"key_id": '1',
"captcha_type": "web_login",
"password" : '65998cf5a6aea54758cce558a257c93ba57cf0ec38ae339c589c417af98e1be2',
"rkey": '21440623b2178c3ea555a33f8a07d83d',
"f": "http%3A%2F%2Fwww.renren.com%2F9a76783671%2Fprofile"
}
# 使用session进行POST请求的发送
response = session.post(url=login_url, headers=headers, data=data)
login_Page_text = response.text
print(response.status_code)
# 4、爬取当前用户的个人主页对用的页面数据
detail_url = 'http://www.renren.com/976783671/profile'
# 使用携带cookie的session进行GET请求发送
detail_page_text = session.get(url=detail_url, headers=headers).text
with open('daizhe.html', 'w', encoding='utf-8') as fp:
fp.write(detail_page_text)
- 执行结果
向往的地方很远,喜欢的东西很贵,这就是我努力的目标。

