数据解析基础之Xpath解析基础
一、Xpath
1.1、Xpath介绍
- XPath是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
- XML是和HTML格式类似的标记语言。拥有标签,节点等元素。但是HTML会被浏览器识别,并根据标签的含义生成对应的样式。xml则不会被识别,且他的标签是自定义的,HTML的标签则是固定的。所以xml常被用于数据传输。但是现在并不常用,我只在maven配置文件中看到使用这种文件。现在一般数据传输度使用的JSON文件。(如果有其他地方也在使用XML,欢迎指点下~)
- 提到XML,想到Ajax的XMLHttpRequest对象。Ajax能在不重新加载整个页面的情况下,异步加载页面。XMLHttpRequest 对象提供了对 HTTP 协议的完全的访问,包括做出 POST 和 HEAD 请求以及普通的 GET 请求的能力。可以同步或异步地返回 Web 服务器的响应,并且能够以文本或者一个 DOM 文档的形式返回内容。虽然XMLHttpRequest对象里面包含XML,但是并不局限于XML,它可以接收任何形式的文本文档。
- 由于xml的编写格式几乎与html一致,我们可以使用他的XPATH去寻找对应的标签和元素。
1.2、Xpath解析原理
- 实例化一个 etree 对象,且需要将被解析的页面源码数据加载到该对象中;
- 调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获;
二、xpath简单实用示例
2.1、xpath环境安装
# pip install lxml
2.2、实例化etree对象
# 1、首先导包
from lxml inport etree
# 2、实例化BeautifulSoup对象,数据加载到该对象中分为两种 :将本地的HTML文档数据加载到该对象中 / 将网络请求响应的页面源码加载到该对象中
# 将本地的html文档中的源码数据加载到etree对象中
etree.parse(filepath)
# 可以将从互联网上获取的源码数据加载到该对象中
etree.HTML('page_text')
2.3、xpath表达式 - 属性定位
- xpath表达式可以根据标签的层级关系进行定位
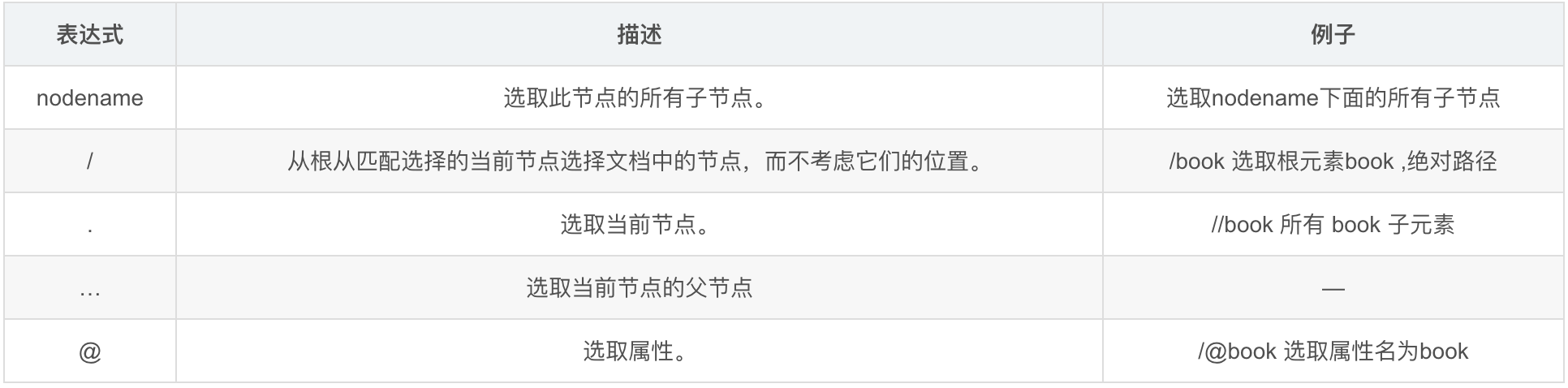
- 首先编写test.html文件,内容如下 : 用于将本地的HTML文档数据加载到该对象中;
// test.html
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>测试bs4</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com" title="赵匡胤" target="_self">
<span>this is span</span>
宋朝是强大的王朝,不是军队的强大,而是经济很强大。
</a>
<a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
<img src="http://www.baidu.com/meiny.jpg" alt="" />
</div>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂</a> </li>
<li><a href="http://www.163.com" title="qing">清明时节雨纷纷,路上行人欲断魂</a> </li>
<li><a href="http://www.126.com" title="qin">秦时明月汉时关,万里长征人未还</a> </li>
<li><a href="http://www.sina.com" title="qi">岐王宅里寻常见,崔九堂前几度闻</a> </li>
<li><a href="http://www.aaa.com" title="lu">杜甫</a> </li>
<li><b>leo</b> </li>
<li><i>风雨寒</i> </li>
<li><a href="http://www.baidu.com" title="feng">凤凰台上凤凰游,凤去台空江自流</a> </li>
</ul>
</div>
</body>
</html>
2.3.1、/ 用法
- / : 表示从根节点开始定位 (一个html的最外面就是一个根节点) 注意:一个 / 表示的是一个层级;
- //: 表示可跨层级使用,也可以从任意位置开始;
- 示例 :
// 定位的内容
<head>
<meta charset="UTF-8" />
<title>测试bs4</title>
</head>
# 三种的输出结果都是一样的
# 1、导入模块
from lxml import etree
# 2、实例化etree对象,且将被解析的源码加载到该对象中
selector = etree.parse('test.html')
# 3、常用的xpath表达式
title1 = selector.xpath('/html/head/title')
title2 = selector.xpath('/html//title') # 可跨越层级,即表示可以可跨多个标签
title3 = selector.xpath('//title')
print(title1)
print(title2)
print(title3)
- 执行结果
# 返回的是 Element对象,对象中存储的就是定位的标签的文本内容
[<Element title at 0x7ffedcc1a7c0>]
[<Element title at 0x7ffedcc1a7c0>]
[<Element title at 0x7ffedcc1a7c0>]
// 定位的内容
<html lang="en">
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
...
</div>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂</a> </li>
...
</ul>
</div>
</body>
</html>
# 1、导入模块
from lxml import etree
# 2、实例化etree对象,且将被解析的源码加载到该对象中
selector = etree.parse('test.html')
# 3、常用的xpath表达式
print(selector.xpath('/html/body/div'))
print(selector.xpath('/html//div'))
print(selector.xpath('//div'))
2.3.2、@ 属性定位
- 属性定位 :
tag[@attrName="attrValue"] - 示例 :
// 定位的内容
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com" title="赵匡胤" target="_self">
<span>this is span</span>
宋朝是强大的王朝,不是军队的强大,而是经济很强大。
</a>
<a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
<img src="http://www.baidu.com/meiny.jpg" alt="" />
</div>
- 编码
# 1、导入模块
from lxml import etree
# 2、实例化etree对象,且将被解析的源码加载到该对象中
selector = etree.parse('test.html')
# 3、常用的xpath表达式
# @ 属性定位 :直接定位到div标签下class=song那的写法
print(selector.xpath('//div[@class="song"]'))
- 执行结果
[<Element div at 0x7fc751c1a6c0>]
2.3.3、索引定位
- 示例
// 定位的内容
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p> // 定位这里
<p>柳宗元</p>
<a href="http://www.song.com" title="赵匡胤" target="_self">
<span>this is span</span>
宋朝是强大的王朝,不是军队的强大,而是经济很强大。
</a>
<a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
<img src="http://www.baidu.com/meiny.jpg" alt="" />
</div>
- 编码
# 1、导入模块
from lxml import etree
# 2、实例化etree对象,且将被解析的源码加载到该对象中
selector = etree.parse('test.html')
# 3、常用的xpath表达式
# 索引定位 :注意这里的索引是从1开始的
print(selector.xpath('//div[@class="song"]/p')) # 定位到了class='song' 下面的四个 p 标签
print(selector.xpath('//div[@class="song"]/p[3]')) # 定位到了class='song' 下面四三个 p 标签
- 执行结果
[<Element p at 0x7f8263c15740>, <Element p at 0x7f8263c15880>, <Element p at 0x7f8263c158c0>, <Element p at 0x7f8263c15900>]
[<Element p at 0x7f8263c15880>]
2.4、xpath表达式 - 定位后取的操作
2.4.1、取文本
-
/text() : 获取的是标签中直系的内容
-
//text() : 获取的是非直系的文本内容(即该标签下的所有的文本内容)
-
示例:
/text() : 获取的是标签中直系的内容
// 取的数据内容
// 取 杜甫
<li><a href="http://www.aaa.com" title="lu">杜甫</a> </li>
- 编码
# 1、导入模块
from lxml import etree
# 2、实例化etree对象,且将被解析的源码加载到该对象中
selector = etree.parse('test.html')
# 3、常用的xpath表达式
print(selector.xpath('//div[@class="tang"]/ul/li[5]/a/text()')) # 列表
print(selector.xpath('//div[@class="tang"]//li[5]/a/text()')[0])
- 示例:
//text() : 获取的是非直系的文本内容(即该标签下的所有的文本内容)
// 取的数据内容
<li><i>风雨寒</i> </li>
- 编码
# 1、导入模块
from lxml import etree
# 2、实例化etree对象,且将被解析的源码加载到该对象中
selector = etree.parse('test.html')
# 3、常用的xpath表达式
print(selector.xpath('//li[7]//text()')) # 列表
print(selector.xpath('//li[7]//text()')[0])
2.4.2、取属性
-
/@attrName 即标签内一个属性名的内容
-
使用属性取值时要固定使用@
-
示例 :
// 取的数据内容
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com" title="赵匡胤" target="_self">
<span>this is span</span>
宋朝是强大的王朝,不是军队的强大,而是经济很强大。
</a>
<a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
// 取这个属性值
<img src="http://www.baidu.com/meiny.jpg" alt="" />
</div>
- 编码
# 1、导入模块
from lxml import etree
# 2、实例化etree对象,且将被解析的源码加载到该对象中
selector = etree.parse('test.html')
# 3、常用的xpath表达式
print(selector.xpath('//div[@class="song"]/img'))
print(selector.xpath('//div[@class="song"]/img/@src')) # 列表
- 执行结果
[<Element img at 0x7fecff415600>]
['http://www.baidu.com/meiny.jpg']
向往的地方很远,喜欢的东西很贵,这就是我努力的目标。
